AnySlot: Goal-Conditioned Vision-Language-Action Policies for Zero-Shot Slot-Level Placement
Pith reviewed 2026-05-10 16:38 UTC · model grok-4.3
The pith
AnySlot generates an explicit visual scene marker from language to let goal-conditioned VLA policies handle precise zero-shot slot placement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
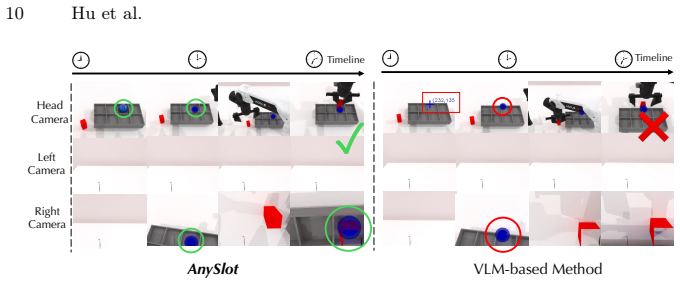
AnySlot reduces compositional complexity by turning language instructions into an explicit spatial visual goal via scene marker generation, then executes that goal with a goal-conditioned VLA policy. This hierarchical design decouples high-level slot selection from low-level execution to achieve both semantic accuracy and spatial robustness. Experiments demonstrate that the method significantly outperforms flat VLA baselines and previous modular grounding approaches in zero-shot slot-level placement tasks.
What carries the argument
Scene marker generation from language as an explicit visual goal, followed by a goal-conditioned VLA policy that drives the robot to match that marker.
If this is right
- Compositional language instructions for placement become tractable by separating semantic grounding from spatial control.
- Zero-shot performance on precision slot tasks rises without requiring task-specific training data.
- Structured spatial reasoning benchmarks like SlotBench become necessary to evaluate future VLA methods.
- Monolithic end-to-end VLA policies can be improved by adding an explicit visual goal layer rather than retraining from scratch.
- Robotic manipulation under variable language gains robustness when high-level selection is isolated from low-level execution.
Where Pith is reading between the lines
- The same marker-plus-goal pattern could extend to other fine-motor tasks such as peg insertion or part alignment where language must specify exact locations.
- If marker generation proves reliable across real cameras, the method may reduce the need for full end-to-end language-to-action training in new environments.
- SlotBench-style benchmarks could expose similar failure modes in other VLA domains that demand sub-centimeter accuracy.
- Hierarchical visual goals might combine with existing object detectors to handle partially observable scenes without retraining the full policy.
Load-bearing premise
A reliable scene marker can always be generated from the language instruction and the goal-conditioned policy can reach the required sub-centimeter spatial accuracy without further fine-tuning or domain data.
What would settle it
In a held-out set of novel slot placement tasks with unseen language compositions, the generated markers are inaccurate or the policy repeatedly misses target slots by more than one centimeter in zero-shot execution.
Figures




read the original abstract
Vision-Language-Action (VLA) policies have emerged as a versatile paradigm for generalist robotic manipulation. However, precise object placement under compositional language remains challenging for end-to-end VLA policies. Slot-level placement requires reliable slot grounding and centimeter-level geometric precision. To this end, we propose AnySlot, a framework that reduces compositional complexity by introducing an explicit spatial visual goal between language grounding and control. AnySlot converts language into a visual goal by rendering a spatial marker at the intended slot, then executes this goal with a goal-conditioned VLA policy. This hierarchical design decouples high-level slot selection from low-level execution, improving semantic accuracy and spatial robustness. Furthermore, recognizing the lack of benchmarks for such precision-demanding tasks, we introduce SlotBench, a structured simulation benchmark with nine task categories for evaluating spatial reasoning in slot-level placement. Extensive experiments show that AnySlot significantly outperforms flat VLA baselines and modular grounding methods in zero-shot slot-level placement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AnySlot, a hierarchical goal-conditioned VLA framework that converts compositional language instructions into an explicit visual scene marker as an intermediate representation, which is then executed by a goal-conditioned policy for zero-shot slot-level placement. It introduces SlotBench, a simulation benchmark with nine task categories focused on structured spatial reasoning, and claims that this decoupling of slot selection from low-level control yields superior performance over flat VLA baselines and prior modular grounding methods.
Significance. If the empirical results hold under rigorous evaluation, the approach could meaningfully advance precise robotic manipulation by separating semantic grounding from spatial execution, addressing a key limitation of monolithic VLAs in tasks requiring sub-centimeter accuracy. The new SlotBench benchmark fills a gap for evaluating compositional spatial tasks and could serve as a standard for future work, provided the marker-generation step proves reliable across categories.
major comments (2)
- [Abstract] Abstract: The central claim that the hierarchical design 'ensures both semantic accuracy and spatial robustness' and 'significantly outperforms' baselines is load-bearing on the assumption that the scene marker generator produces spatially precise targets from compositional instructions. No quantitative breakdown of marker localization error, no ablation of marker quality versus end-to-end success rates, and no failure-mode analysis across the nine SlotBench categories are referenced, leaving open the possibility that reported gains are driven primarily by the upstream grounding module rather than the proposed architecture.
- [Abstract] The weakest assumption noted in the stress-test—that reliable scene marker generation is always possible and that the policy achieves sub-centimeter accuracy without fine-tuning—directly affects the zero-shot claim. The manuscript provides no evidence (e.g., marker error distributions or policy corrective range analysis) that the goal-conditioned policy can recover from typical VLM grounding inaccuracies on compositional cases, which is required to substantiate the decoupling benefit.
minor comments (2)
- [Abstract] The abstract refers to 'flat VLA baselines and previous modular grounding methods' without naming the specific methods or citing their original papers; adding these references would improve traceability.
- [Abstract] SlotBench is introduced as addressing the 'lack of existing benchmarks,' but the manuscript could briefly contrast its nine categories with related manipulation benchmarks (e.g., those focused on object rearrangement) to clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our work. The feedback highlights important aspects of substantiating the benefits of our hierarchical design, and we will revise the manuscript accordingly to provide the requested quantitative analyses and ablations.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the hierarchical design 'ensures both semantic accuracy and spatial robustness' and 'significantly outperforms' baselines is load-bearing on the assumption that the scene marker generator produces spatially precise targets from compositional instructions. No quantitative breakdown of marker localization error, no ablation of marker quality versus end-to-end success rates, and no failure-mode analysis across the nine SlotBench categories are referenced, leaving open the possibility that reported gains are driven primarily by the upstream grounding module rather than the proposed architecture.
Authors: We agree that additional analysis is needed to isolate the contributions of the marker generator and the goal-conditioned policy. In the revised version, we will add a quantitative breakdown of marker localization error (including mean error and distributions across the nine task categories in SlotBench). We will also include an ablation comparing end-to-end success rates using generated markers versus oracle (perfect) markers to demonstrate the policy's role. Finally, we will expand the results section with a per-category failure-mode analysis to show where the hierarchical decoupling provides gains beyond the upstream module alone. revision: yes
-
Referee: [Abstract] The weakest assumption noted in the stress-test—that reliable scene marker generation is always possible and that the policy achieves sub-centimeter accuracy without fine-tuning—directly affects the zero-shot claim. The manuscript provides no evidence (e.g., marker error distributions or policy corrective range analysis) that the goal-conditioned policy can recover from typical VLM grounding inaccuracies on compositional cases, which is required to substantiate the decoupling benefit.
Authors: We acknowledge that explicit evidence for the policy's robustness to grounding inaccuracies would strengthen the zero-shot claims. While our current experiments demonstrate overall performance advantages in zero-shot settings, we did not include a dedicated analysis of recovery from marker errors. In the revision, we will add marker error distributions from the generator and evaluate the goal-conditioned policy's corrective range by testing performance under controlled perturbations to the visual goals (simulating typical VLM inaccuracies on compositional instructions). This will directly address the decoupling benefit. revision: yes
Circularity Check
No significant circularity in empirical framework
full rationale
The paper is an empirical proposal of a hierarchical VLA framework (AnySlot) plus a new benchmark (SlotBench). It contains no equations, derivations, first-principles predictions, or parameter-fitting steps that could reduce outputs to inputs by construction. Claims rest on experimental comparisons rather than any self-referential definitions or imported uniqueness theorems. This is the normal case for robotics system papers; the derivation chain is absent, so no circularity patterns apply.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Invertible Neural Network Adapter for One-Step Flow Matching in Robot Manipulation
An invertible adapter for flow matching enables one-step high-dimensional action generation in robotic manipulation, cutting inference time roughly in half while preserving performance.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.