Recognition: unknown
ArtifactWorld: Scaling 3D Gaussian Splatting Artifact Restoration via Video Generation Models
Pith reviewed 2026-05-10 14:57 UTC · model grok-4.3
The pith
ArtifactWorld restores 3D Gaussian Splatting artifacts at scale by training video diffusion models on 107.5K paired clips guided by artifact heatmaps and triplet fusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
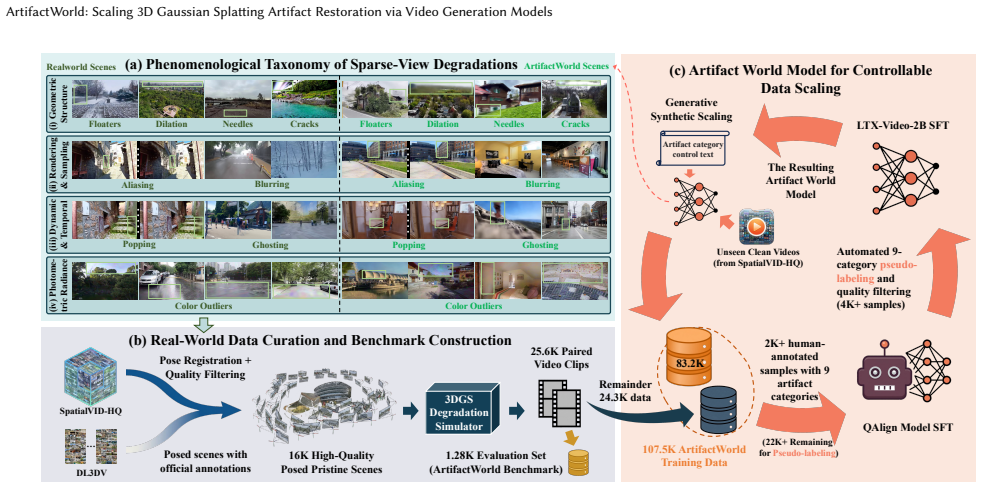
ArtifactWorld resolves 3DGS artifact repair through systematic data expansion via a phenomenological taxonomy and 107.5K paired video clips, combined with a homogeneous dual-model paradigm that uses an isomorphic predictor to generate an artifact heatmap and an Artifact-Aware Triplet Fusion mechanism to perform intensity-guided spatio-temporal restoration within the native self-attention of a video diffusion backbone.
What carries the argument
The Artifact-Aware Triplet Fusion mechanism, which receives an artifact heatmap from the isomorphic predictor and enables precise, intensity-guided repair of defects inside the video diffusion model's self-attention.
If this is right
- State-of-the-art performance on sparse novel view synthesis tasks.
- More robust 3D reconstruction from inputs that would otherwise degrade under sparse constraints.
- Reduced multi-view inconsistencies and erroneous geometric hallucinations in the output.
- Better generalization across diverse real-world artifact distributions compared with prior methods.
Where Pith is reading between the lines
- The same taxonomy-plus-video-clip construction could be adapted to repair artifacts in other 3D representations such as neural radiance fields.
- Automated generation of even larger paired datasets following the same phenomenological rules might push performance higher without manual labeling.
- Once integrated into real-time pipelines, the restored models could support practical mobile or AR applications that currently fail on limited camera inputs.
Load-bearing premise
The phenomenological taxonomy and 107.5K paired video clips together capture enough of the true diversity of real-world 3DGS artifacts that the dual-model approach and triplet fusion will generalize without introducing new inconsistencies or hallucinations.
What would settle it
A held-out test set of real-world sparse-view captures from scenes outside the taxonomy that still shows multi-view inconsistencies or geometric hallucinations after applying the restored model.
Figures





read the original abstract
3D Gaussian Splatting (3DGS) delivers high-fidelity real-time rendering but suffers from geometric and photometric degradations under sparse-view constraints. Current generative restoration approaches are often limited by insufficient temporal coherence, a lack of explicit spatial constraints, and a lack of large-scale training data, resulting in multi-view inconsistencies, erroneous geometric hallucinations, and limited generalization to diverse real-world artifact distributions. In this paper, we present ArtifactWorld, a framework that resolves 3DGS artifact repair through systematic data expansion and a homogeneous dual-model paradigm. To address the data bottleneck, we establish a fine-grained phenomenological taxonomy of 3DGS artifacts and construct a comprehensive training set of 107.5K diverse paired video clips to enhance model robustness. Architecturally, we unify the restoration process within a video diffusion backbone, utilizing an isomorphic predictor to localize structural defects via an artifact heatmap. This heatmap then guides the restoration through an Artifact-Aware Triplet Fusion mechanism, enabling precise, intensity-guided spatio-temporal repair within native self-attention. Extensive experiments demonstrate that ArtifactWorld achieves state-of-the-art performance in sparse novel view synthesis and robust 3D reconstruction. Code and dataset will be made public.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ArtifactWorld, a framework for restoring artifacts in 3D Gaussian Splatting under sparse-view conditions. It defines a fine-grained phenomenological taxonomy of 3DGS artifacts, constructs a dataset of 107.5K paired video clips, and integrates this into a video diffusion backbone using an isomorphic predictor to generate artifact heatmaps and an Artifact-Aware Triplet Fusion mechanism for guided spatio-temporal restoration. The central claim is that this homogeneous dual-model approach achieves state-of-the-art results in sparse novel view synthesis and robust 3D reconstruction, with code and data to be released publicly.
Significance. If the SOTA claims and generalization hold under rigorous evaluation, the work would meaningfully advance generative restoration techniques for 3DGS by addressing temporal coherence and data scarcity through systematic taxonomy-driven scaling. The public dataset could serve as a benchmark resource for the community, enabling reproducible progress on artifact handling in real-world sparse-view scenarios.
major comments (2)
- [Abstract] Abstract: the assertion of state-of-the-art performance in sparse novel view synthesis and robust 3D reconstruction is presented without any quantitative metrics (e.g., PSNR, SSIM, LPIPS), baseline comparisons, ablation results, or dataset details, leaving the central performance claim unsupported by visible evidence and preventing assessment of its validity.
- [Data Construction] Data Construction (implied in §3 or equivalent): the phenomenological taxonomy and 107.5K paired clips are positioned as comprehensively capturing artifact diversity to support generalization of the dual-model paradigm and triplet fusion, yet no coverage analysis, cross-validation against unseen capture conditions (e.g., view-dependent specularities or high-frequency drift), or failure-case enumeration is described, which is load-bearing for the robustness claims.
minor comments (2)
- [Abstract] The abstract and introduction use terms such as 'homogeneous dual-model paradigm' and 'isomorphic predictor' without immediate definition or reference to the relevant architectural diagram; adding a brief inline clarification would improve readability.
- Ensure that any experimental tables or figures in the full manuscript include standard error reporting and statistical significance tests to substantiate the SOTA comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of state-of-the-art performance in sparse novel view synthesis and robust 3D reconstruction is presented without any quantitative metrics (e.g., PSNR, SSIM, LPIPS), baseline comparisons, ablation results, or dataset details, leaving the central performance claim unsupported by visible evidence and preventing assessment of its validity.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support. In the revised version, we will incorporate key metrics (e.g., PSNR/SSIM gains over baselines) and a brief reference to the dataset scale while keeping the abstract concise. Full tables, baseline comparisons, and ablation studies remain in Section 4. revision: yes
-
Referee: [Data Construction] Data Construction (implied in §3 or equivalent): the phenomenological taxonomy and 107.5K paired clips are positioned as comprehensively capturing artifact diversity to support generalization of the dual-model paradigm and triplet fusion, yet no coverage analysis, cross-validation against unseen capture conditions (e.g., view-dependent specularities or high-frequency drift), or failure-case enumeration is described, which is load-bearing for the robustness claims.
Authors: Section 3.1 details the taxonomy and Section 3.2 describes the 107.5K clip construction with diversity criteria. We acknowledge that explicit coverage statistics, cross-validation on unseen conditions, and enumerated failure cases are not currently present and would bolster the generalization claims. We will add a new analysis subsection in the revision that provides coverage metrics, examples of handling view-dependent effects and drift, and qualitative failure cases. revision: yes
Circularity Check
No significant circularity; derivation is self-contained data-driven construction.
full rationale
The paper constructs a phenomenological taxonomy of 3DGS artifacts and a 107.5K paired video dataset to train a video diffusion model incorporating an isomorphic predictor, artifact heatmap, and Artifact-Aware Triplet Fusion. This is an empirical pipeline whose outputs (restored views and reconstructions) are produced by training on the authors' data rather than by algebraic reduction or self-referential definition. No equations or claims reduce a result to a fitted parameter renamed as prediction, no load-bearing self-citations justify core premises, and no uniqueness theorem or ansatz is imported from prior author work. The SOTA claims rest on experimental evaluation of the trained model, which remains externally falsifiable once code and data are released. The derivation chain therefore contains no circular steps.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
AdaptSplat: Adapting Vision Foundation Models for Feed-Forward 3D Gaussian Splatting
AdaptSplat adds a lightweight Frequency-Preserving Adapter to vision foundation models that extracts direction-aware high-frequency priors and integrates them via positional encodings and residual modulation to improv...
Reference graph
Works this paper leans on
-
[1]
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Pe- ter Hedman. 2022. Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5470–5479
2022
-
[2]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, et al. 2023. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127(2023)
work page internal anchor Pith review arXiv 2023
-
[3]
Minghong Cai, Xiaodong Cun, Xiaoyu Li, Wenze Liu, Zhaoyang Zhang, Yong Zhang, Ying Shan, and Xiangyu Yue. 2025. Ditctrl: Exploring attention con- trol in multi-modal diffusion transformer for tuning-free multi-prompt longer video generation. InProceedings of the Computer Vision and Pattern Recognition Conference. 7763–7772
2025
-
[4]
Zheng Chen, Zichen Zou, Kewei Zhang, Xiongfei Su, Xin Yuan, Yong Guo, and Yulun Zhang. 2025. DOVE: Efficient One-Step Diffusion Model for Real-World Video Super-Resolution. InAdvances in Neural Information Processing Systems (NeurIPS)
2025
-
[5]
Jaeyoung Chung, Jeongtaek Oh, and Kyoung Mu Lee. 2024. Depth-regularized optimization for 3d gaussian splatting in few-shot images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 811–820
2024
-
[6]
Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. [n. d.]. TokenFlow: Consistent Diffusion Features for Consistent Video Editing. InThe Twelfth Inter- national Conference on Learning Representations
-
[7]
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. 2024. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103(2024)
work page internal anchor Pith review arXiv 2024
-
[8]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis
-
[9]
3D Gaussian Splatting for Real-Time Radiance Field Rendering.ACM Transactions on Graphics(2023), 139–1
2023
-
[10]
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, Xuanmao Li, Xingpeng Sun, Rohan Ashok, Aniruddha Mukherjee, Hao Kang, Xiangrui Kong, Gang Hua, Tianyi Zhang, Bedrich Benes, and Aniket Bera. 2024. DL3DV-10K: A Large-Scale Scene Dataset for Deep Learning-based 3D Vision. InProceedings of the IEEE/CV...
2024
- [11]
-
[12]
Kangfu Mei, Mo Zhou, and Vishal M Patel. [n. d.]. Field-DiT: Diffusion Trans- former on Unified Video, 3D, and Game Field Generation. InThe Thirteenth International Conference on Learning Representations
-
[13]
Maxime Oquab, Timothée Darcet, Theo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Russell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang-Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nicolas Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patrick Labatu...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Hyunwoo Park, Gun Ryu, and Wonjun Kim. 2025. Dropgaussian: Structural regularization for sparse-view gaussian splatting. InProceedings of the computer vision and pattern recognition conference. 21600–21609
2025
-
[15]
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, and Fisher Yu. 2024. Unidepth: Universal monocular metric depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10106–10116
2024
-
[16]
Tianhao Qi, Jianlong Yuan, Wanquan Feng, Shancheng Fang, Jiawei Liu, SiYu Zhou, Qian He, Hongtao Xie, and Yongdong Zhang. 2025. Maskˆ 2DiT: Dual Mask-based Diffusion Transformer for Multi-Scene Long Video Generation. In Proceedings of the Computer Vision and Pattern Recognition Conference. 18837– 18846
2025
-
[17]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[18]
InInternational Conference on Machine Learning (ICML)
Learning Transferable Visual Models from Natural Language Supervision. InInternational Conference on Machine Learning (ICML). PMLR, 8748–8763
-
[19]
Kyle Sargent, Zizhang Li, Tanmay Shah, Charles Herrmann, Hong-Xing Yu, Yun- zhi Zhang, Eric Ryan Chan, Dmitry Lagun, Li Fei-Fei, Deqing Sun, et al. 2024. ZeroNVS: Zero-Shot 360-Degree View Synthesis from a Single Image. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9420–9429
2024
-
[20]
Nagabhushan Somraj, Adithyan Karanayil, and Rajiv Soundararajan. 2023. Sim- pleNeRF: Regularizing Sparse Input Neural Radiance Fields with Simpler Solu- tions. InSIGGRAPH Asia. 1–11
2023
-
[21]
Xiangyu Sun, Joo Chan Lee, Daniel Rho, Jong Hwan Ko, Usman Ali, and Eun- byung Park. 2024. F-3dgs: Factorized coordinates and representations for 3d gaussian splatting. InProceedings of the 32nd ACM International Conference on Multimedia. 7957–7965
2024
-
[22]
Zachary Teed and Jia Deng. 2021. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Advances in neural information processing systems34 (2021), 16558–16569
2021
-
[23]
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. 2019. FVD: A New Metric for Video Gener- ation. https://openreview.net/forum?id=rylgEULtdN
2019
-
[24]
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rup- precht, and David Novotny. 2025. VGGT: Visual Geometry Grounded Trans- former. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 5294–5306
2025
- [26]
-
[27]
Jiahao Wang, Yufeng Yuan, Rujie Zheng, Youtian Lin, Jian Gao, Lin-Zhuo Chen, Yajie Bao, Yi Zhang, Chang Zeng, Yanxi Zhou, Xiaoxiao Long, Hao Zhu, Zhaoxiang Zhang, Xun Cao, and Yao Yao. 2025. SpatialVID: A Large- Scale Video Dataset with Spatial Annotations. arXiv:2509.09676 [cs.CV] https: //arxiv.org/abs/2509.09676
-
[28]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing13, 4 (2004), 600–612
2004
-
[29]
Haoning Wu, Zicheng Zhang, Weixia Zhang, Chaofeng Chen, Liang Liao, Chunyi Li, Yixuan Gao, Annan Wang, Erli Zhang, Wenxiu Sun, et al. 2024. Q-ALIGN: teaching LMMs for visual scoring via discrete text-defined levels. InProceedings of the 41st International Conference on Machine Learning. 54015–54029
2024
-
[30]
Jay Zhangjie Wu, Yuxuan Zhang, Haithem Turki, Xuanchi Ren, Jun Gao, Mike Zheng Shou, Sanja Fidler, Zan Gojcic, and Huan Ling. 2025. Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2025
-
[31]
Rundi Wu, Ben Mildenhall, Philipp Henzler, Keunhong Park, Ruiqi Gao, Daniel Watson, Pratul P Srinivasan, Dor Verbin, Jonathan T Barron, Ben Poole, et al
-
[32]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
ReconFusion: 3D Reconstruction with Diffusion Priors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 21551–21561
-
[33]
Sibo Wu, Congrong Xu, Binbin Huang, Andreas Geiger, and Anpei Chen. 2025. GenFusion: Closing the Loop between Reconstruction and Generation via Videos. InProceedings of the Computer Vision and Pattern Recognition Conference. 6078– 6088
2025
-
[34]
Rui Xie, Yinhong Liu, Penghao Zhou, Chen Zhao, Jun Zhou, Kai Zhang, Zhenyu Zhang, Jian Yang, Zhenheng Yang, and Ying Tai. 2025. STAR: Spatial-Temporal Augmentation with Text-to-Video Models for Real-World Video Super-Resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
2025
-
[35]
Yabo Xu, Jin Ding, Jianbin Zhang, Ping Tan, and Mingrui Li. 2026. Denoise-GS: Self-Supervised Denoising for Sparse-View 3D Gaussian Splatting.Sensors (Basel, Switzerland)26, 2 (2026), 651
2026
-
[36]
Yiran Xu, Taesung Park, Richard Zhang, Yang Zhou, Eli Shechtman, Feng Liu, Jia-Bin Huang, and Difan Liu. 2025. Videogigagan: Towards detail-rich video super-resolution. InProceedings of the Computer Vision and Pattern Recognition Conference. 2139–2149
2025
-
[37]
Yexing Xu, Longguang Wang, Minglin Chen, Sheng Ao, Li Li, and Yulan Guo
-
[38]
In Proceedings of the Computer Vision and Pattern Recognition Conference
Dropoutgs: Dropping out gaussians for better sparse-view rendering. In Proceedings of the Computer Vision and Pattern Recognition Conference. 701–710
-
[39]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. 2024. Depth anything v2.Advances in Neural Information Processing Systems37 (2024), 21875–21911
2024
-
[40]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. [n. d.]. CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer. In The Thirteenth International Conference on Learning Representations
-
[41]
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. 2025. From slow bidirectional to fast autoregressive video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22963–22974
2025
- [42]
-
[43]
Jiawei Zhang, Jiahe Li, Xiaohan Yu, Lei Huang, Lin Gu, Jin Zheng, and Xiao Bai. 2024. Cor-gs: sparse-view 3d gaussian splatting via co-regularization. In European conference on computer vision. Springer, 335–352
2024
-
[44]
Jiahui Zhang, Fangneng Zhan, Muyu Xu, Shijian Lu, and Eric Xing. 2024. Fregs: 3d gaussian splatting with progressive frequency regularization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 21424– 21433
2024
-
[45]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang
-
[46]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
The Unreasonable Effectiveness of Deep Features as a Perceptual Met- ric. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 586–595
-
[47]
Shangchen Zhou, Peiqing Yang, Jianyi Wang, Yihang Luo, and Chen Change Loy
-
[48]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Upscale-a-video: Temporal-consistent diffusion model for real-world video super-resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2535–2545
-
[49]
Zehao Zhu, Zhiwen Fan, Yifan Jiang, and Zhangyang Wang. 2024. FSGS: Real- Time Few-Shot View Synthesis Using Gaussian Splatting. InEuropean Conference on Computer Vision. 145–163
2024
-
[50]
Junhao Zhuang, Shi Guo, Xin Cai, Xiaohui Li, Yihao Liu, Chun Yuan, and Tianfan Xue. 2026. FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.