Recognition: unknown
Efficient Test-Time Inference via Deterministic Exploration of Truncated Decoding Trees
Pith reviewed 2026-05-10 00:55 UTC · model grok-4.3
The pith
Deterministic enumeration of distinct leaves in truncated decoding trees outperforms stochastic self-consistency on reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
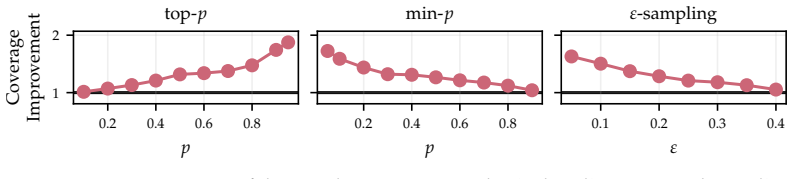
Distinct Leaf Enumeration (DLE) treats truncated sampling as traversal of a pruned decoding tree and systematically enumerates distinct leaves instead of sampling with replacement. Algorithmically, this increases coverage of the truncated search space under a fixed budget by exploring previously unvisited high-probability branches. Systemically, it reuses shared prefixes and reduces redundant token generation. Empirically, DLE explores higher-quality reasoning traces than stochastic self-consistency, yielding better performance on math, coding, and general reasoning tasks.
What carries the argument
Distinct Leaf Enumeration (DLE), a deterministic traversal that lists every unique leaf of a pruned decoding tree exactly once.
If this is right
- Accuracy on math, coding, and reasoning benchmarks rises because more unique high-probability traces are evaluated within the same compute limit.
- Token generation cost falls because identical prefixes are expanded only once across all enumerated paths.
- Variance across runs disappears because the set of explored traces is determined solely by the pruning rule rather than by random seeds.
- The method can be combined with existing voting or aggregation procedures without changing their downstream logic.
Where Pith is reading between the lines
- The same enumeration principle could replace sampling inside other tree-based inference methods such as tree-of-thoughts or stepwise verification.
- In domains where the output space is highly constrained, deterministic coverage may be preferable to stochastic diversity because duplicate paths waste budget.
- Adaptive versions could prune or expand branches on the fly using partial answer quality signals rather than fixed truncation thresholds.
Load-bearing premise
That systematically enumerating distinct leaves in a pruned decoding tree will reliably surface higher-quality reasoning traces without discarding critical high-probability paths that stochastic sampling would have found.
What would settle it
Run DLE and standard self-consistency with identical total token budgets on a fixed set of math problems and check whether DLE's final voted accuracy is lower than self-consistency's on any problem where the correct answer lies on a high-probability path that DLE's pruning rule discards.
Figures














read the original abstract
Self-consistency boosts inference-time performance by sampling multiple reasoning traces in parallel and voting. However, in constrained domains like math and code, this strategy is compute-inefficient because it samples with replacement, repeatedly revisiting the same high-probability prefixes and duplicate completions. We propose Distinct Leaf Enumeration (DLE), a deterministic decoding method that treats truncated sampling as traversal of a pruned decoding tree and systematically enumerates distinct leaves instead of sampling with replacement. This strategy improves inference efficiency in two ways. Algorithmically, it increases coverage of the truncated search space under a fixed budget by exploring previously unvisited high-probability branches. Systemically, it reuses shared prefixes and reduces redundant token generation. Empirically, DLE explores higher-quality reasoning traces than stochastic self-consistency, yielding better performance on math, coding, and general reasoning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Distinct Leaf Enumeration (DLE), a deterministic decoding strategy that models truncated sampling as traversal of a pruned decoding tree and enumerates distinct leaves rather than sampling with replacement. It claims this increases coverage of the search space, reuses shared prefixes to reduce redundant computation, and empirically yields higher-quality reasoning traces than stochastic self-consistency, leading to better performance on math, coding, and general reasoning tasks.
Significance. If the empirical results hold under proper controls, DLE could provide a practical efficiency gain for test-time scaling of reasoning in LLMs by addressing the duplicate-prefix problem in self-consistency without requiring additional training or model changes. The deterministic nature and prefix-reuse mechanism are attractive for constrained compute budgets.
major comments (3)
- [Abstract] Abstract: the central claim that systematic leaf enumeration produces higher-quality traces than multinomial sampling of the same size rests on the unverified assumption that the fixed traversal order (whatever it is) will not systematically exclude high-reward low-probability completions that stochastic sampling would occasionally reach; no derivation or proof is supplied that expected trace quality is preserved or improved.
- [Abstract] Abstract / empirical claims: the performance advantage is stated without reference to error bars, number of runs, or ablation on the tree-pruning threshold and enumeration order; without these controls it is impossible to verify that the pruned tree is identical for both methods or that the observed gains are not artifacts of the particular pruning rule.
- [Method] Method description (inferred from abstract): the construction of the pruned decoding tree and the deterministic traversal order are not specified in sufficient detail to allow reproduction or to confirm that both DLE and the stochastic baseline operate on exactly the same support.
minor comments (1)
- [Abstract] The abstract would benefit from a one-sentence statement of the precise pruning criterion and traversal order used in DLE.
Simulated Author's Rebuttal
We thank the referee for the constructive report on our manuscript. Below we respond to each major comment, indicating the revisions we intend to make. We believe these changes will address the concerns about theoretical assumptions, empirical rigor, and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that systematic leaf enumeration produces higher-quality traces than multinomial sampling of the same size rests on the unverified assumption that the fixed traversal order (whatever it is) will not systematically exclude high-reward low-probability completions that stochastic sampling would occasionally reach; no derivation or proof is supplied that expected trace quality is preserved or improved.
Authors: The manuscript's claims regarding higher-quality traces are explicitly empirical rather than theoretical, as indicated by the phrasing 'Empirically, DLE explores higher-quality reasoning traces'. We do not claim or derive that the deterministic order always preserves expected quality; instead, we observe performance improvements in practice on the evaluated benchmarks. To address this, we will revise the abstract to further emphasize the empirical nature of the comparison and add a paragraph in the Discussion section explaining the rationale for the traversal order (prioritizing branches by cumulative probability) while acknowledging that it may not cover all possible high-reward paths that rare stochastic samples could reach. No formal proof will be added as it is not within the scope and may not hold universally. revision: yes
-
Referee: [Abstract] Abstract / empirical claims: the performance advantage is stated without reference to error bars, number of runs, or ablation on the tree-pruning threshold and enumeration order; without these controls it is impossible to verify that the pruned tree is identical for both methods or that the observed gains are not artifacts of the particular pruning rule.
Authors: We agree that additional controls are necessary for robust verification. The revised manuscript will include error bars (standard deviation over multiple independent runs), explicitly state the number of runs performed, and provide ablations varying the pruning threshold and enumeration orders. We will also add text confirming that the pruned tree is constructed identically for DLE and the stochastic baseline by applying the same truncation criteria before either enumeration or sampling begins. revision: yes
-
Referee: [Method] Method description (inferred from abstract): the construction of the pruned decoding tree and the deterministic traversal order are not specified in sufficient detail to allow reproduction or to confirm that both DLE and the stochastic baseline operate on exactly the same support.
Authors: We will significantly expand the Method section in the revision. This will include a detailed algorithmic description with pseudocode for building the pruned decoding tree (based on cumulative probability thresholds for truncation at each depth), the deterministic traversal strategy (e.g., using a priority-based enumeration of distinct leaves to avoid duplicates), and an explicit statement confirming that the support of the enumerated leaves is identical to the possible outputs under the same truncation rule used in the self-consistency baseline. revision: yes
- A formal derivation or proof that the deterministic traversal order preserves or improves expected trace quality compared to stochastic sampling of the same size.
Circularity Check
No significant circularity; method defined independently of inputs
full rationale
The paper introduces Distinct Leaf Enumeration (DLE) as a deterministic traversal of a pruned decoding tree, contrasting it with stochastic self-consistency sampling. No equations, parameters, or derivations in the abstract or description reduce the claimed efficiency or quality gains to quantities fitted from data or justified solely by the authors' prior self-citations. The central distinction (systematic leaf enumeration vs. sampling with replacement) is presented as an algorithmic choice with empirical validation, without self-referential definitions or load-bearing uniqueness theorems imported from the same authors. This is the common case of a self-contained proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A fixed token budget can be allocated to distinct leaves without missing high-value paths that random sampling would discover.
Forward citations
Cited by 1 Pith paper
-
Multi-Stream LLMs: Unblocking Language Models with Parallel Streams of Thoughts, Inputs and Outputs
Language models trained on parallel streams of computation can overcome single-stream bottlenecks in autonomous agents by enabling simultaneous reading, thinking, and acting.
Reference graph
Works this paper leans on
-
[1]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mo- hammad Bavari...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training Verifiers to Solve Math Word Problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Yichao Fu, Xuewei Wang, Yuandong Tian, and Jiawei Zhao. Deep Think with Confidence. arXiv preprint arXiv:2508.15260,
-
[4]
Weizhi Gao, Xiaorui Liu, Feiyi Wang, Dan Lu, and Junqi Yin. Decoding memories: An effi- cient pipeline for self-consistency hallucination detection.arXiv preprint arXiv:2508.21228,
-
[5]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 548 other authors. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
John Hewitt, Christopher D. Manning, and Percy Liang. Truncation Sampling as Language Model Desmoothing.arXiv preprint arXiv:2210.15191,
-
[7]
The Curious Case of Neural Text Degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The Curious Case of Neural Text Degeneration.arXiv preprint arXiv:1904.09751,
work page internal anchor Pith review arXiv 1904
-
[8]
arXiv preprint arXiv:2502.18581 , year=
Zhewei Kang, Xuandong Zhao, and Dawn Song. Scalable Best-of-N Selection for Large Language Models via Self-Certainty.arXiv preprint arXiv:2502.18581,
-
[9]
Wouter Kool, Herke van Hoof, and Max Welling. Stochastic Beams and Where to Find Them: The Gumbel-Top-k Trick for Sampling Sequences Without Replacement.arXiv preprint arXiv:1903.06059,
-
[10]
Taming overconfidence in llms: Reward calibration in rlhf.arXiv preprint arXiv:2410.09724,
Jixuan Leng, Chengsong Huang, Banghua Zhu, and Jiaxin Huang. Taming Overconfidence in LLMs: Reward Calibration in RLHF.arXiv preprint arXiv:2410.09724,
-
[11]
A diversity-promoting objective function for neural conversation models, 2016
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. A Diversity-Promoting Objective Function for Neural Conversation Models.arXiv preprint arXiv:1510.03055,
-
[12]
Lei Lin, Jiayi Fu, Pengli Liu, Qingyang Li, Yan Gong, Junchen Wan, Fuzheng Zhang, Zhongyuan Wang, Di Zhang, and Kun Gai. Just Ask One More Time! Self-Agreement Improves Reasoning of Language Models in (Almost) All Scenarios.arXiv preprint arXiv:2311.08154,
-
[13]
Qwen, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Ti...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Incremental Sampling Without Replacement for Sequence Models.arXiv preprint arXiv:2002.09067,
Kensen Shi, David Bieber, and Charles Sutton. Incremental Sampling Without Replacement for Sequence Models.arXiv preprint arXiv:2002.09067,
-
[15]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM Test-Time Com- pute Optimally can be More Effective than Scaling Model Parameters.arXiv preprint arXiv:2408.03314,
-
[16]
Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models
Ashwin K Vijayakumar, Michael Cogswell, Ramprasath R Selvaraju, Qing Sun, Stefan Lee, David Crandall, and Dhruv Batra. Diverse beam search: Decoding diverse solutions from neural sequence models.arXiv preprint arXiv:1610.02424,
-
[17]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Han Wang, Archiki Prasad, Elias Stengel-Eskin, and Mohit Bansal. Soft Self-Consistency Improves Language Models Agents. InAnnual Meeting of the Association for Computational Linguistics, Short Papers, 2024a. Xinglin Wang, Yiwei Li, Shaoxiong Feng, Peiwen Yuan, Boyuan Pan, Heda Wang, Yao Hu, and Kan Li. Integrate the essence and eliminate the dross: Fine-g...
-
[18]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. MMLU-Pro: A More Robust and Chal- lenging Multi-Task Language Understanding Benchmark.arXiv preprint arXiv:2406.01574, 2024c. Fangzhi Xu, Hang Yan...
work page internal anchor Pith review arXiv
-
[19]
Path-consistency: Prefix enhancement for efficient inference in llm
Jiace Zhu, Yingtao Shen, Jie Zhao, and An Zou. Path-consistency: Prefix enhancement for efficient inference in llm.arXiv preprint arXiv:2409.01281,
-
[20]
In addition to PROBFIRST, we test four additional search algorithms • DIVFIRSTselects a branching point according to the earliest available alternative token position
The branching algorithm described in the main paper is called PROBFIRST. In addition to PROBFIRST, we test four additional search algorithms • DIVFIRSTselects a branching point according to the earliest available alternative token position. This forces early divergence near the root. • RANDBRANCHchooses branching points bysamplingfrom the distribution def...
2016
-
[21]
2000 4000 Number of new tokens generated 0.35 0.40 0.45 0.50 Accuracy 0.45 0.40 0.35 0.30 0.25 0.20 0.15 0.10 0.05 0.01 ε ε-sampling (k =
We draw the same conclusion that DLE uses fewer tokens for the same accuracy. 2000 4000 Number of new tokens generated 0.35 0.40 0.45 0.50 Accuracy 0.45 0.40 0.35 0.30 0.25 0.20 0.15 0.10 0.05 0.01 ε ε-sampling (k =
2000
-
[22]
We only investigate the offline version of DeepConf
is a test-time method that filters out reasoning traces of low quality when doing inference or after inference. We only investigate the offline version of DeepConf. Fu et al. (2025) defines the token confidence as the negative average log-probability of the top-ntokens at a given positioni Ci =− 1 n n ∑ j=1 logP top i (j), (14) where n denotes the number ...
2025
-
[23]
24 Method 2 4 8 Mean Confidence Weighted 0.2002 0.2578 0.3298 Top Percent Weighted (10%) 0.1948 0.2532 0.2616 Top Percent Weighted (25%) 0.2153 0.2199 0.2570 Top Percent (10%) 0.2115 0.2343 0.2509 Top Percent (25%) 0.2055 0.2153 0.2464 Tail Mean Conf (64 Tokens) Weighted 0.2085 0.2472 0.3222 Top Percent Weighted (10%) 0.2002 0.2199 0.2350 Top Percent Weig...
-
[24]
with Qwen2.5- 0.5B-Instruct. See Appendix D.4 for details. 25 Method 2 4 8 Mean Confidence Weighted 0.14060.15580.1607 Top Percent Weighted (10%) 0.1371 0.1451 0.1544 Top Percent Weighted (25%) 0.1363 0.1524 0.1439 Top Percent (10%) 0.1433 0.1493 0.1471 Top Percent (25%) 0.1419 0.1439 0.1503 Tail Mean Conf (64 Tokens) Weighted 0.1381 0.1518 0.1635 Top Per...
-
[25]
Kang et al
divergence between a uniform distribution and the next-token distribution, averaged over the sequence length, Self-Certainty(x1:T ) :=− 1 VT T ∑ t=1 V ∑ v=1 log(V·p(v|x <t)), (15) whereV=|V |is the size of the vocabulary. Kang et al. (2025) also identifies that score-based voting methods suffer from sensitivity to score scaling. Therefore, they propose an...
2025
-
[26]
with Qwen2.5-0.5B-Instruct. Table 12 shows results for all self-certainty experiments on MMLU-Pro (Wang et al., 2024c) with Qwen2.5-0.5B-Instruct. Voting powerparg max , p= 0.0 p=0.1p=0.3p=0.5p=0.7p=0.9 Votingk=220.0919.94 19.94 20.02 19.94 19.94 Votingk=4 23.81 25.09 24.87 24.41 24.6425.32 Votingk=8 28.73 29.8032.2231.01 30.17 31.54 Table 11: Results for...
-
[27]
arg max, p= 0.0 denotes the casewithout votingand choosing the arg max sequence for self-certainty
with Qwen2.5-0.5B-Instruct. arg max, p= 0.0 denotes the casewithout votingand choosing the arg max sequence for self-certainty. Voting powerparg max , p= 0.0 p=0.1p=0.3p=0.5p=0.7p=0.9 Votingk=2 14.42 14.26 14.21 14.11 14.4514.51 Votingk=4 15.13 15.4015.9215.90 15.10 15.91 Votingk=8 13.48 14.25 14.6614.6814.28 14.14 Table 12: Results for self-certainty (Ka...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.