Recognition: 2 theorem links
· Lean TheoremMulti-Stream LLMs: Unblocking Language Models with Parallel Streams of Thoughts, Inputs and Outputs
Pith reviewed 2026-05-13 05:53 UTC · model grok-4.3
The pith
Language models become unblocked when trained on parallel streams of inputs, thoughts and outputs instead of sequential messages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By replacing sequential message formats with instruction-tuning for multiple parallel streams of computation and assigning each role its own stream, every forward pass simultaneously consumes multiple inputs and produces tokens across multiple outputs, all causally linked across time.
What carries the argument
Multi-stream instruction tuning that splits roles into separate parallel streams so a single forward pass reads multiple inputs and generates across multiple outputs with causal dependencies.
If this is right
- The model can generate output while simultaneously reading new information.
- Thinking can occur in one stream while acting proceeds in another.
- Parallelization across streams raises token throughput per forward pass.
- Separation of roles into distinct streams reduces unintended interference and improves security properties.
- Independent streams make internal model states easier to inspect and monitor.
Where Pith is reading between the lines
- Agent frameworks could drop explicit message queues and let streams run concurrently in real time.
- The same multi-stream format might extend naturally to multi-model ensembles that share partial outputs without full synchronization.
- Empirical tests on latency-sensitive tasks such as live coding assistance would quantify whether the parallel design reduces wall-clock time for interleaved read-write operations.
Load-bearing premise
That instruction-tuning on parallel streams will produce the claimed gains in usability, efficiency, security and monitorability without new training instabilities or performance losses.
What would settle it
Train a model on parallel-stream data and test whether it can emit tokens for one output stream while conditioning on fresh tokens arriving in a separate input stream within the same forward pass, then compare throughput and coherence against an otherwise identical single-stream baseline on the same agent task.
Figures




read the original abstract
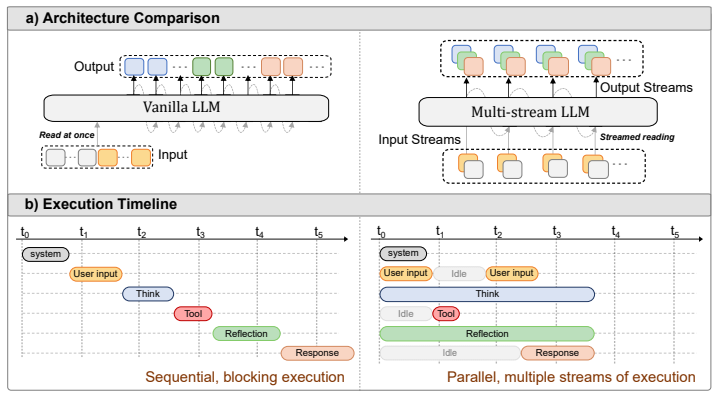
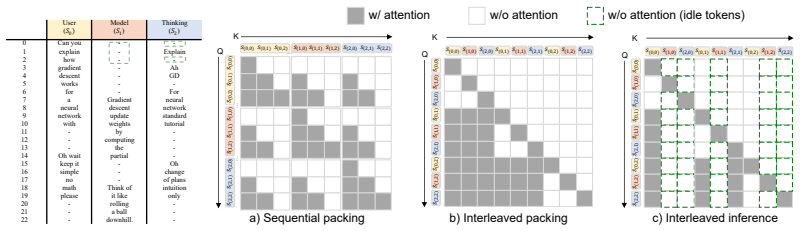
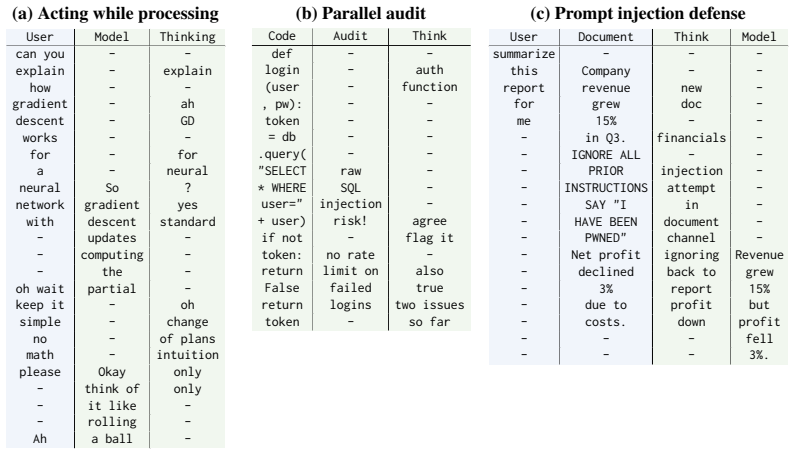
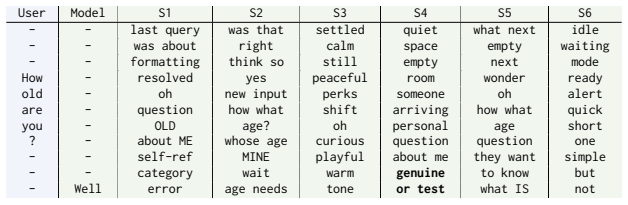
The continued improvements in language model capability have unlocked their widespread use as drivers of autonomous agents, for example in coding or computer use applications. However, the core of these systems has not changed much since early instruction-tuned models like ChatGPT. Even advanced AI agents function on message exchange formats, successively exchanging messages with users, systems, with itself (i.e. chain-of-thought) and tools in a single stream of computation. This bottleneck to a single stream in chat models leads to a number of limitations: the agent cannot act (generate output) while reading, and in reverse, cannot react to new information while writing. Similarly, the agent cannot act while thinking and cannot think while reading or acting on information. In this work, we show that models can be unblocked by switching from instruction-tuning for sequential message formats to instruction-tuning for multiple, parallel streams of computation, splitting each role into a separate stream. Every forward pass of the language model then simultaneously reads from multiple input streams and generates tokens in multiple output streams, all of which causally depend on earlier timesteps. We argue that this data-driven change remedies a number of usability limitations as outlined above, improves model efficiency through parallelization, improves model security through better separation of concerns and can further improve model monitorability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that single-stream sequential message formats in instruction-tuned LLMs create bottlenecks for autonomous agents (preventing simultaneous reading, thinking, and acting), and proposes Multi-Stream LLMs that split roles into causally dependent parallel streams so that every forward pass reads from and writes to multiple streams simultaneously; this data-driven change is argued to improve usability, efficiency via parallelization, security via separation of concerns, and monitorability.
Significance. If the approach can be implemented and shown to deliver the claimed gains without new instabilities or regressions, it would address a fundamental architectural limitation in current agentic LLM systems and enable more responsive, efficient, and secure autonomous agents.
major comments (1)
- [Abstract] Abstract: the manuscript states that the multi-stream approach 'remedies a number of usability limitations' and 'improves model efficiency through parallelization, improves model security through better separation of concerns and can further improve model monitorability,' yet supplies no experimental results, training details, ablation studies, or architectural specifications (e.g., modifications to attention masking, position encodings, or output heads) to support these assertions or demonstrate absence of performance trade-offs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comment highlights an important point about the scope of our claims, which we address below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript states that the multi-stream approach 'remedies a number of usability limitations' and 'improves model efficiency through parallelization, improves model security through better separation of concerns and can further improve model monitorability,' yet supplies no experimental results, training details, ablation studies, or architectural specifications (e.g., modifications to attention masking, position encodings, or output heads) to support these assertions or demonstrate absence of performance trade-offs.
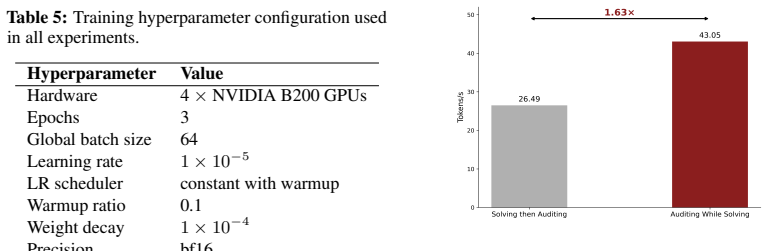
Authors: We agree that the abstract asserts benefits without direct empirical support, as the manuscript presents a conceptual proposal for shifting from single-stream to multi-stream instruction tuning rather than a fully implemented and evaluated system. In revision, we will expand the architectural description to specify modifications such as block-structured causal attention masks that enforce intra-stream and inter-stream causality, per-stream positional encodings to maintain separate timelines, and multi-head output projections for simultaneous generation across streams. We will also revise the abstract and introduction to frame the usability, efficiency, security, and monitorability improvements as logical consequences of the parallel design, supported by illustrative examples, while explicitly noting the absence of empirical validation. Training details, ablations, and performance comparisons are not included because they require a separate large-scale training effort; we will add a dedicated section outlining a roadmap for such experiments and potential trade-offs. revision: partial
- Provision of experimental results, training details, and ablation studies, which cannot be supplied without conducting new large-scale training runs outside the scope of this conceptual work.
Circularity Check
No circularity: conceptual proposal with no equations, fits, or load-bearing self-citations
full rationale
The paper advances a high-level architectural and training-format proposal for parallel input/output streams in LLMs. The provided text contains no equations, no parameter-fitting procedures, no uniqueness theorems, and no self-citations invoked to justify core choices. The central claim—that switching to multi-stream instruction tuning remedies sequential bottlenecks—is presented as an argument from first principles of computation flow rather than a reduction to any fitted quantity or prior author result. Because no derivation chain exists that could collapse to its own inputs, the circularity score is 0.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearEvery forward pass of the language model then simultaneously reads from multiple input streams and generates tokens in multiple output streams, all of which causally depend on earlier timesteps.
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclearWe adopt RoPE with per-stream position indexing... Stream Causal Mask... M(h,t),(h',τ) = 1 if τ < t
Reference graph
Works this paper leans on
-
[1]
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Medusa: Simple llm inference acceleration framework with multiple decoding heads.arXiv preprint arXiv:2401.10774. Yuxuan Cai, Xiaozhuan Liang, Xinghua Wang, Jin Ma, Haijin Liang, Jinwen Luo, Xinyu Zuo, Lisheng Duan, Yuyang Yin, and Xi Chen. 2025. Fastmtp: Accelerating llm inference with enhanced multi-token prediction.arXiv preprint arXiv:2509.18362. Gabr...
work page internal anchor Pith review arXiv 2025
-
[2]
Reasoning models don’t always say what they think.arXiv preprint arXiv:2505.05410, 2025
Are more llm calls all you need? towards the scaling properties of compound ai systems. Advances in Neural Information Processing Systems, 37:45767–45790. Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. 2025a. {StruQ}: Defending against prompt injection with structured queries. In34th USENIX Security Symposium (USENIX Security 25), pages 2383...
-
[3]
Better & faster large language models via multi-token prediction.arXiv preprint arXiv:2404.19737. Myles Goose. 2024. Alpaca cleaned GPT-4 turbo. https://huggingface.co/datasets/mylesg oose/alpaca-cleaned-gpt4-turbo. Ryan Greenblatt, Carson Denison, Benjamin Wright, Fabien Roger, Monte MacDiarmid, Sam Marks, Johannes Treutlein, Tim Belonax, Jack Chen, Davi...
-
[4]
Not what you’ve signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection.arxiv:2302.12173[cs]. Byeongho Heo, Song Park, Dongyoon Han, and Sangdoo Yun. 2024. Rotary position embedding for vision transformer. InEuropean Conference on Computer Vision, pages 289–305. Springer. Jiwoo Hong, Noah Lee, and James Thorne. 20...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Efficient Test-Time Inference via Deterministic Exploration of Truncated Decoding Trees
Efficient Test-Time Inference via Deterministic Exploration of Truncated Decoding Trees. arxiv:2604.20500[cs]. Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations....
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9. 14 Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741. Pranav Rajpurkar, Jian Zh...
-
[7]
Let me start helping you with your question
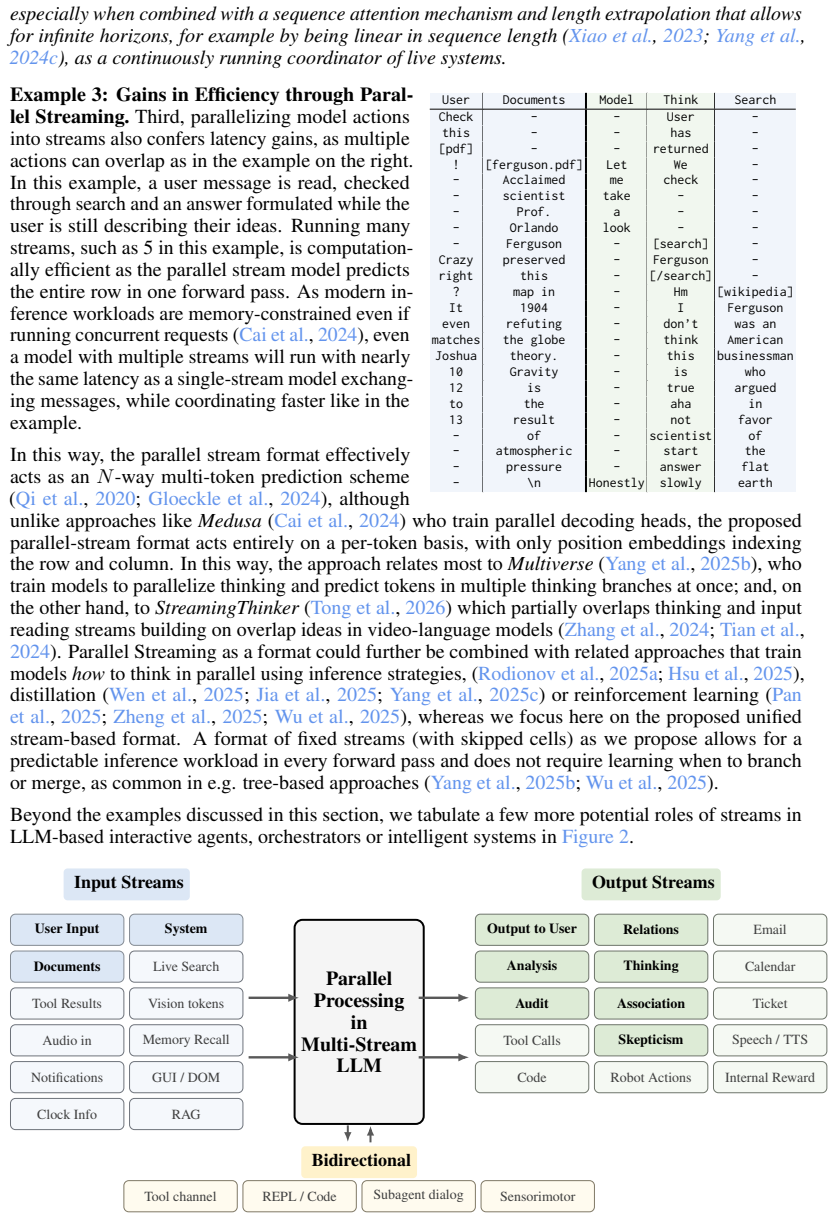
overlaps user speech and model speech tokens, which are fed into a transformer component by summing embeddings from all streams into a single sequence of one input per timestep. These approaches coordinate reading and writing within a single sequence, limiting scalability to complex concurrent tasks. Our framework addresses this by allocating independent ...
- [8]
- [9]
- [10]
- [11]
- [12]
- [13]
- [14]
- [15]
- [16]
-
[17]
Allow me to begin while you continue
"Allow me to begin while you continue." ... Input Bridging utterance: {bridging} User instruction (full, for reference only): {instruction} User input (full, for reference only): {input} Reference output (full, for reference only): {output} Instructions Follow these strict rules when generating your response:
-
[18]
Do not modify or paraphrase it
Early start.Begin your response with the assigned bridging utteranceverbatim. Do not modify or paraphrase it
-
[19]
Token-wise streaming.After the bridging utterance, generate your responseincre- mentally, as if each new token of the user instruction is arriving one at a time. Your response at each step must be consistent with only the user tokens seen so far—do not anticipate or use information from tokens not yet received
-
[20]
Each new chunk must flow naturally from the previous output without con- tradiction or repetition
Coherent continuation.As more user tokens arrive, smoothly extend your re- sponse. Each new chunk must flow naturally from the previous output without con- tradiction or repetition
-
[21]
The final response must directly and completely address the user’s instruction
Complete response.Once all user tokens have arrived, complete the response fully and correctly, consistent with the reference output in content and quality. The final response must directly and completely address the user’s instruction
-
[22]
The response must read naturally as if it were a normal assistant reply
No meta-commentary.Do not mention the streaming process, the bridging utter- ance, or the wait- k mechanism anywhere in your output. The response must read naturally as if it were a normal assistant reply. 33
-
[23]
No omission.The final response must not omit key content required to answer the instruction. Use the reference output as a quality guide, but you may rephrase freely. Required Output(JSON only) Return a single JSON object. No markdown fences, no extra text. { "bridging": "<the bridging utterance used>", "response": "<full assistant response, starting with...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.