Recognition: unknown
SAVGO: Learning State-Action Value Geometry with Cosine Similarity for Continuous Control
Pith reviewed 2026-05-09 19:57 UTC · model grok-4.3
The pith
SAVGO learns a joint state-action embedding space where cosine similarity between pairs reflects their action-value similarity, enabling a kernel to guide policy updates toward higher-value actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SAVGO shows that a single geometry-consistent objective can align cosine similarities in a joint state-action embedding with action-value estimates, thereby producing a similarity kernel that directs policy improvement steps toward higher-value regions while preserving off-policy scalability.
What carries the argument
The joint state-action embedding space optimized so that cosine similarity encodes action-value similarity, which in turn generates the kernel used for policy updates.
If this is right
- Policy improvement can draw on value similarity across multiple sampled actions instead of local gradients alone.
- Representation learning becomes directly coupled to both value estimation and policy optimization within one loss.
- The approach remains compatible with standard off-policy actor-critic scaling to high-dimensional continuous tasks.
- Value-geometry learning and similarity-based updates each contribute measurable performance gains on challenging control problems.
Where Pith is reading between the lines
- If the geometry proves robust, the same embedding approach could be tested in discrete action settings or model-based planning.
- The unified objective opens the possibility of end-to-end training without separate auxiliary losses for representation or value.
- The method suggests a route to improve generalization by reusing the value geometry across related tasks without retraining from scratch.
Load-bearing premise
That the cosine similarity measured in the learned embedding space will reliably track true action-value similarity in a way that produces stable and useful policy improvements.
What would settle it
If the learned embeddings fail to group actions by their actual Q-values or if replacing the similarity kernel with ordinary gradient updates yields equal or better performance on the same benchmarks.
Figures


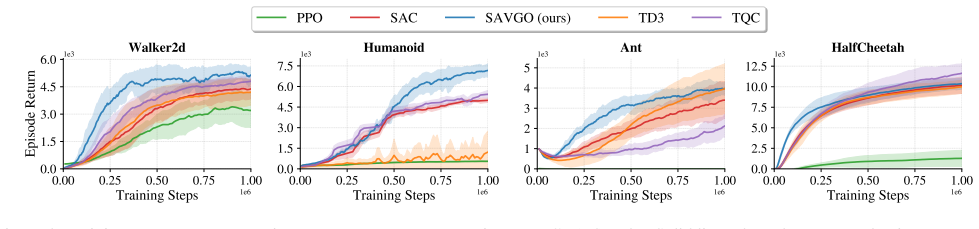
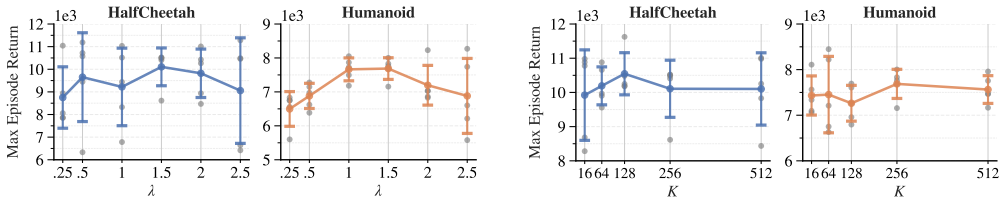
read the original abstract
While representation and similarity learning have improved the sample efficiency of Reinforcement Learning (RL), they are rarely used to shape policy updates directly in the action space. To bridge this gap, a geometry-aware RL algorithm that explicitly incorporates value-based similarity into the policy update, State-Action Value Geometry Optimization (SAVGO), is proposed. In detail, SAVGO learns a joint state-action embedding space in which pairs with similar action-value estimates exhibit high cosine similarity, while dissimilar pairs are mapped to distinct directions. This learned geometry enables the generation of a similarity kernel over candidate actions sampled at each update, allowing policy improvement to be guided directly toward higher-value regions beyond local gradient-based updates. As a result, representation learning, value estimation, and policy optimization are unified within a single geometry-consistent objective, while preserving the scalability of off-policy actor-critic training. The proposed method is evaluated on standard MuJoCo continuous-control benchmarks, demonstrating improvements over strong baselines on challenging high-dimensional tasks. Ablation studies are done to analyze the contributions of value-geometry learning and similarity-based policy updates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAVGO, a geometry-aware RL algorithm for continuous control that learns a joint state-action embedding space in which cosine similarity between embeddings is trained to match similarity in action-value estimates via a contrastive-style objective. This geometry is then used to construct a normalized similarity kernel over candidate actions sampled at each step, which guides policy improvement in a non-local fashion. The approach unifies representation learning, value estimation, and policy optimization within a single objective while retaining the scalability of off-policy actor-critic methods. Empirical evaluation on MuJoCo benchmarks reports improvements over strong baselines on high-dimensional tasks, supported by ablations isolating the value-geometry and similarity-kernel components.
Significance. If the reported results and derivations hold, SAVGO provides a coherent mechanism for directly shaping policy updates with learned value geometry, which could improve exploration and sample efficiency in continuous control without requiring additional task-specific tuning or sacrificing off-policy scalability. The explicit tying of the contrastive loss to Q-value targets and the derivation of the policy gradient as an expectation under the similarity kernel are strengths that distinguish it from prior representation-learning approaches in RL.
minor comments (3)
- Abstract: The claim of 'improvements over strong baselines' would benefit from a brief quantitative summary (e.g., average return gains or specific tasks) to allow readers to gauge effect size without immediately consulting the results section.
- §4 (or equivalent methods section): The description of how the similarity kernel is normalized and how actions are sampled for the kernel should include the exact sampling distribution and any temperature hyperparameters to ensure reproducibility.
- Figure 3 (or ablation figures): Axis labels and legend entries should be enlarged for readability; current font size makes it difficult to distinguish the contribution of the geometry term versus the baseline actor-critic loss.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation for minor revision. The report accurately captures the core contribution of SAVGO in unifying representation learning, value estimation, and policy optimization via learned state-action value geometry and similarity-kernel-guided updates. We will incorporate minor revisions to improve clarity, exposition, and any presentational aspects of the manuscript.
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The manuscript explicitly couples a contrastive loss on state-action embeddings to Q-value targets computed by the critic, defines the similarity kernel as a normalized softmax over actions sampled from the current policy, and derives the policy gradient as an expectation under that kernel. These steps are algebraically independent: Q-targets are not redefined by the kernel, the kernel is not used to recompute the targets, and no self-citation supplies a uniqueness theorem or ansatz that closes the loop. Joint optimization unifies the objectives without reducing any claimed prediction to a fitted input by construction. External MuJoCo benchmarks and ablations further confirm the chain does not collapse internally.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Foundation Twins: A New Generation of Power Systems Digital Twins using Foundation AI Models
The paper proposes Foundation Twins as a new class of power systems digital twins that integrate the generalization of foundation models with reinforcement learning for multi-timescale decision support.
Reference graph
Works this paper leans on
-
[1]
Rusu and Joel Veness and Marc G
Volodymyr Mnih and Koray Kavukcuoglu and David Silver and Andrei A. Rusu and Joel Veness and Marc G. Bellemare and Alex Graves and Martin A. Riedmiller and Andreas Fidjeland and Georg Ostrovski and Stig Petersen and Charles Beattie and Amir Sadik and Ioannis Antonoglou and Helen King and Dharshan Kumaran and Daan Wierstra and Shane Legg and Demis Hassabis...
-
[2]
Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms , author =. arXiv preprint arXiv:1707.06347 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Proceedings of the 35th International Conference on Machine Learning , pages =
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[4]
Addressing Function Approximation Error in Actor-Critic Methods , booktitle =
Scott Fujimoto and Herke van Hoof and David Meger , editor =. Addressing Function Approximation Error in Actor-Critic Methods , booktitle =. 2018 , url =
2018
-
[5]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Kuznetsov, Arsenii and Shvechikov, Pavel and Grishin, Alexander and Vetrov, Dmitry , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
2020
-
[6]
International Conference on Learning Representations , year=
Randomized Ensembled Double Q-Learning: Learning Fast Without a Model , author=. International Conference on Learning Representations , year=
-
[7]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Chen, Ting and Kornblith, Simon and Norouzi, Mohammad and Hinton, Geoffrey , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
2020
-
[8]
International Conference on Learning Representations , year=
Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels , author=. International Conference on Learning Representations , year=
-
[9]
2020 , editor =
Laskin, Michael and Srinivas, Aravind and Abbeel, Pieter , booktitle =. 2020 , editor =
2020
-
[10]
International Conference on Learning Representations , year=
Data-Efficient Reinforcement Learning with Self-Predictive Representations , author=. International Conference on Learning Representations , year=
-
[11]
, booktitle =
Gelada, Carles and Kumar, Saurabh and Buckman, Jacob and Nachum, Ofir and Bellemare, Marc G. , booktitle =. 2019 , editor =
2019
-
[12]
Ninth International Conference on Learning Representations(ICLR) , year =
Liu, Guoqing and Zhang, Chuheng and Zhao, Li and Qin, Tao and Zhu, Jinhua and Jian, Li and Yu, Nenghai and Liu, Tie-Yan , title =. Ninth International Conference on Learning Representations(ICLR) , year =
-
[13]
Yue, Yang and Kang, Bingyi and Xu, Zhongwen and Huang, Gao and Yan, Shuicheng , title =. Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence , articleno =. 2023 , isbn =. doi...
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
The Value-Improvement Path: Towards Better Representations for Reinforcement Learning , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2021 , month=. doi:10.1609/aaai.v35i8.16880 , number=
-
[15]
International Conference on Learning Representations , year=
Learning Invariant Representations for Reinforcement Learning without Reconstruction , author=. International Conference on Learning Representations , year=
-
[16]
2021 , url=
Pablo Samuel Castro and Tyler Kastner and Prakash Panangaden and Mark Rowland , booktitle=. 2021 , url=
2021
-
[17]
Shen, Junhong and Yang, Lin F. , year=. Theoretically Principled Deep RL Acceleration via Nearest Neighbor Function Approximation , volume=. doi:10.1609/aaai.v35i11.17151 , journal=
-
[18]
Proceedings of the 38th International Conference on Machine Learning , pages =
Decoupling Representation Learning from Reinforcement Learning , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[19]
Understanding and addressing the pitfalls of bisimulation-based representations in offline reinforcement learning , year =
Zang, Hongyu and Li, Xin and Zhang, Leiji and Liu, Yang and Sun, Baigui and Islam, Riashat and des Combes, R\'. Understanding and addressing the pitfalls of bisimulation-based representations in offline reinforcement learning , year =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
-
[20]
Proceedings of the 35th International Conference on Neural Information Processing Systems , articleno =
Kemertas, Mete and Aumentado-Armstrong, Tristan , title =. Proceedings of the 35th International Conference on Neural Information Processing Systems , articleno =. 2021 , isbn =
2021
-
[21]
Machine Learning , volume =
Kernel-Based Reinforcement Learning , author =. Machine Learning , volume =. 2002 , doi =
2002
-
[22]
Proceedings of the 34th International Conference on Machine Learning , pages =
Neural Episodic Control , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
2017
-
[23]
International Conference on Learning Representations , year=
Maximum a Posteriori Policy Optimisation , author=. International Conference on Learning Representations , year=
-
[24]
Relative entropy policy search , year =
Peters, Jan and M\". Relative entropy policy search , year =. Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence , pages =
-
[25]
Practical Kernel-Based Reinforcement Learning , journal =
Andr. Practical Kernel-Based Reinforcement Learning , journal =. 2016 , volume =
2016
-
[26]
Journal of Machine Learning Research , year =
Antonin Raffin and Ashley Hill and Adam Gleave and Anssi Kanervisto and Maximilian Ernestus and Noah Dormann , title =. Journal of Machine Learning Research , year =
-
[27]
The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Gymnasium: A Standard Interface for Reinforcement Learning Environments , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[28]
and Gu, Shixiang Shane and Precup, Doina and Meger, David , title =
Fujimoto, Scott and Chang, Wei-Di and Smith, Edward J. and Gu, Shixiang Shane and Precup, Doina and Meger, David , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[29]
2024 , url =
Max Rudolph and Caleb Chuck and Kevin Black and Misha Lvovsky and Scott Niekum and Amy Zhang , title =. 2024 , url =
2024
-
[30]
Understanding Behavioral Metric Learning:
Ziyan Luo and Tianwei Ni and Pierre. Understanding Behavioral Metric Learning:. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.00563 , eprinttype =. 2506.00563 , timestamp =
-
[31]
Gong Gao and Weidong Zhao and Xianhui Liu and Ning Jia , title =. Neural Networks , volume =. 2026 , url =. doi:10.1016/J.NEUNET.2026.108667 , timestamp =
-
[32]
2026 , eprint=
Task-Aware Exploration via a Predictive Bisimulation Metric , author=. 2026 , eprint=
2026
-
[33]
2026 , url=
Distractor-Robust Reinforcement Learning via Variational Bisimulation , author=. 2026 , url=
2026
-
[34]
Hon Tik Tse and Siddarth Chandrasekar and Marlos C. Machado , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.16217 , eprinttype =. 2505.16217 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.