D-OPSD: On-Policy Self-Distillation for Continuously Tuning Step-Distilled Diffusion Models
Pith reviewed 2026-05-20 23:14 UTC · model grok-4.3
The pith
Step-distilled diffusion models can be continuously fine-tuned on new concepts without losing their few-step speed by using on-policy self-distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
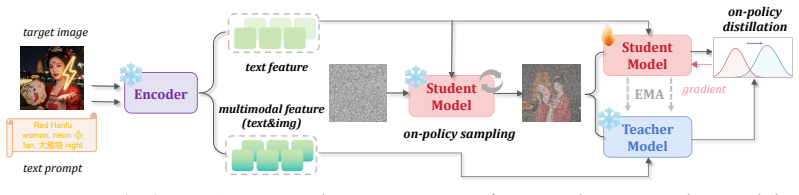
The paper claims that modern diffusion models with an LLM or VLM encoder inherit in-context capabilities that allow a teacher conditioned on both text prompt and target image to provide reliable supervision to a text-only student. Training then minimizes the difference between the two predicted distributions over the student's own roll-outs, so the model acquires new concepts and styles while its original few-step inference capacity stays intact.
What carries the argument
On-policy self-distillation, in which the model serves as both teacher (conditioned on text plus target image) and student (text only) and the loss aligns their output distributions on trajectories sampled from the student itself.
If this is right
- The model acquires new concepts and styles through continuous supervised fine-tuning.
- The original few-step inference performance remains unchanged after tuning.
- Training draws on the model's inherited in-context capabilities from its encoder to generate the supervisory signal.
- Practical ongoing adaptation of efficient image generators to specific domains becomes feasible.
Where Pith is reading between the lines
- The same self-distillation pattern could be tested on other conditional generative models that use encoder-based prompts.
- Deployed systems might use repeated rounds of this process for gradual personalization without full retraining.
- Checking the method on base models without strong encoders would test how far the in-context assumption reaches.
Load-bearing premise
Modern diffusion models inherit enough in-context capabilities from their LLM or VLM encoders that a teacher conditioned on both text and target image can reliably supervise a text-only student.
What would settle it
Apply D-OPSD to a step-distilled model and then check whether high-quality images on new concepts still appear in the original few steps; a clear rise in the number of steps required or a drop in quality on either new or original prompts would show the claim is false.
Figures










read the original abstract
The landscape of high-performance image generation models is currently shifting from the inefficient multi-step ones to the efficient few-step counterparts (e.g, Z-Image-Turbo and FLUX.2-klein). However, these models present significant challenges for direct continuous supervised fine-tuning. For example, applying the commonly used fine-tuning technique would compromise their inherent few-step inference capability. To address this, we propose D-OPSD, a novel training paradigm for step-distilled diffusion models that enables on-policy learning during supervised fine-tuning. We first find that the modern diffusion models, where the LLM/VLM serves as the encoder, can inherit its encoder's in-context capabilities. This enables us to formulate the training as an on-policy self-distillation process. Specifically, during training, we make the model act as both the teacher and the student with different contexts, where the student is conditioned only on the text feature, while the teacher is conditioned on the multimodal feature of both the text prompt and the target image. Training minimizes the two predicted distributions over the student's own roll-outs. By optimizing on the model's own trajectory and under its own supervision, D-OPSD enables the model to learn new concepts, styles, etc., without sacrificing the original few-step capacity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes D-OPSD, an on-policy self-distillation training paradigm for step-distilled diffusion models. The core idea is that modern diffusion models with LLM/VLM encoders inherit in-context capabilities, allowing the same model to act as both teacher (conditioned on multimodal input consisting of the text prompt plus target image) and student (conditioned on text features only). Training minimizes divergence between the two predicted distributions evaluated on the student's own roll-outs, with the goal of enabling supervised fine-tuning for new concepts and styles while preserving the original few-step sampling behavior.
Significance. If the central claim is substantiated, the result would be significant for the ongoing shift toward efficient few-step diffusion models. It offers a potential solution to the problem of continuous supervised fine-tuning without degrading inference speed, which is a practical barrier for models such as Z-Image-Turbo and FLUX.2-klein. The on-policy self-distillation framing could also inform related work on self-supervised adaptation in generative models more broadly.
major comments (2)
- [Abstract and §3] Abstract and §3 (Method description): The central assumption that the LLM/VLM encoder supplies sufficient in-context capabilities for the multimodal teacher to produce a reliable, distribution-compatible supervisory signal for the text-only student is stated as a finding but is not accompanied by any derivation, preliminary ablation, or stability argument showing why this conditioning remains valid once parameters are updated on-policy. This assumption is load-bearing for the claim that few-step capacity is preserved.
- [§4] §4 (Experiments): No quantitative results, ablations, or comparisons are referenced that isolate the contribution of the on-policy self-distillation objective versus standard supervised fine-tuning; without such evidence it is impossible to assess whether the method actually avoids the distribution shift or capacity erosion described in the abstract.
minor comments (1)
- [Abstract] Abstract: The models Z-Image-Turbo and FLUX.2-klein are mentioned without citations or references.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and describe the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method description): The central assumption that the LLM/VLM encoder supplies sufficient in-context capabilities for the multimodal teacher to produce a reliable, distribution-compatible supervisory signal for the text-only student is stated as a finding but is not accompanied by any derivation, preliminary ablation, or stability argument showing why this conditioning remains valid once parameters are updated on-policy. This assumption is load-bearing for the claim that few-step capacity is preserved.
Authors: We agree that the validity of the in-context capability after on-policy updates is a central assumption. The manuscript presents this as an empirical observation that enables the teacher-student formulation, with the on-policy rollouts intended to keep the distributions aligned. While no formal derivation is given, the design minimizes shift by supervising on the student's own trajectories. To strengthen the presentation, we will add a new preliminary ablation in the revised §3 that measures the divergence between teacher and student predictions on held-out student trajectories both before and after a short training run, providing evidence for stability of the supervisory signal. revision: yes
-
Referee: [§4] §4 (Experiments): No quantitative results, ablations, or comparisons are referenced that isolate the contribution of the on-policy self-distillation objective versus standard supervised fine-tuning; without such evidence it is impossible to assess whether the method actually avoids the distribution shift or capacity erosion described in the abstract.
Authors: We acknowledge that the current experiments do not include an explicit head-to-head comparison against standard supervised fine-tuning. The reported results focus on demonstrating that D-OPSD enables acquisition of new concepts while retaining few-step sampling speed. To isolate the contribution of the on-policy objective, we will add quantitative comparisons in the revised §4, including a standard SFT baseline with metrics on both concept fidelity and inference-step preservation, allowing direct assessment of distribution-shift mitigation. revision: yes
Circularity Check
No circularity: proposed on-policy objective is independent of its claimed outcomes
full rationale
The paper introduces D-OPSD by first stating an empirical observation that diffusion models with LLM/VLM encoders inherit in-context capabilities, then defines a training process in which the same model acts as teacher (multimodal conditioning on text + target image) and student (text-only) while minimizing divergence on the student's own roll-outs. This formulation is presented as a novel paradigm to enable supervised fine-tuning without eroding few-step sampling; the benefit of preserving original capacity is an intended empirical result of the objective rather than a quantity that reduces to the inputs by definition or by self-citation. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided description, and the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Modern diffusion models where the LLM/VLM serves as the encoder can inherit its encoder's in-context capabilities.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Training minimizes the two predicted distributions over the student's own roll-outs... student is conditioned only on the text feature, while the teacher is conditioned on the multimodal feature
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
A Brief Overview: On-Policy Self-Distillation In Large Language Models
OPSD lets a single LLM distill its own reasoning by sampling trajectories from the student role while granting the teacher role privileged access to verified solutions, reducing memory needs versus separate-model dist...
-
A Brief Overview: On-Policy Self-Distillation In Large Language Models
This overview paper explains the conceptual foundations and design principles of On-Policy Self-Distillation for large language models from a beginner's perspective.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.