TabPFN-3: Technical Report
Pith reviewed 2026-05-15 06:01 UTC · model grok-4.3
The pith
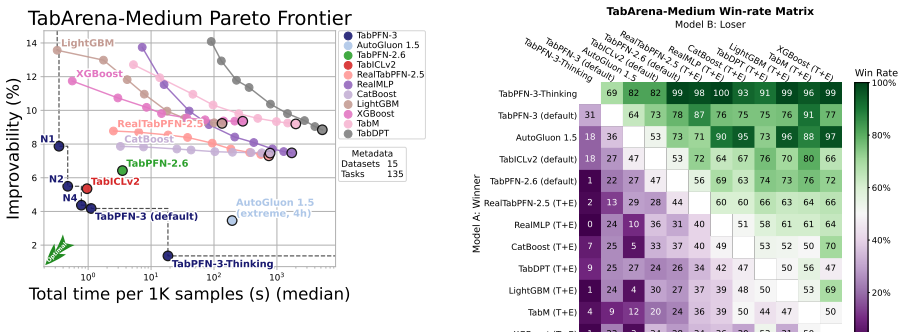
TabPFN-3 outperforms all tuned and ensembled models on the TabArena tabular benchmark with a single forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TabPFN-3 achieves state-of-the-art performance on tabular prediction tasks by scaling a transformer-based foundation model pretrained on synthetic data. On the TabArena benchmark, a single forward pass surpasses all other models including tuned and ensembled baselines, while dominating the speed-performance trade-off. The TabPFN-3-Plus variant, leveraging test-time compute, further improves results by over 200 Elo points overall and 420 on large subsets, outperforming AutoGluon while being ten times faster. The approach extends to new domains with new state-of-the-art results on relational benchmarks and tabular-text tasks, all while being up to twenty times faster than its predecessor and s
What carries the argument
Synthetic pretraining combined with test-time compute scaling in a transformer architecture for tabular data.
If this is right
- Beats 8-hour-tuned gradient-boosted-tree baselines on datasets up to 1M rows and 200 features.
- Ranks first on datasets with many classes.
- Achieves new SOTA on RelBenchV1 for relational data.
- Provides SOTA on TabSTAR for tabular-text data via TabPFN-3-Plus.
- Enables up to 120x faster SHAP-value computation and ranks 2nd on fev-bench via TabPFN-TS-3.
Where Pith is reading between the lines
- The reliance on synthetic data may allow the model to avoid privacy issues associated with real data training.
- Test-time scaling opens the door to further performance improvements by allocating more compute during prediction without retraining.
- The speed gains could make foundation models practical for real-time tabular applications where traditional methods were too slow.
- Integration improvements suggest easier adoption in existing pipelines for time-series and interpretability tasks.
Load-bearing premise
The synthetic data used for pretraining sufficiently represents the distribution of real-world tabular datasets to enable strong generalization.
What would settle it
Evaluating TabPFN-3 on a large collection of previously unseen real-world tabular datasets collected after the model's release to check if the performance margins hold.
Figures









































read the original abstract
Tabular data underpins most high-value prediction problems in science and industry, and TabPFN has driven the foundation model revolution for this modality. Designed with feedback from our users, TabPFN-3 builds on this foundation to scale state-of-the-art performance to datasets with 1M training rows and substantially reduce training and inference time. Pretrained exclusively on synthetic data from our prior, TabPFN-3 dramatically pushes the frontier of tabular prediction and brings substantial gains on time series, relational, and tabular-text data. On the standard tabular benchmark TabArena, a forward pass of TabPFN-3 outperforms all other models, including tuned and ensembled baselines, by a significant margin, and pareto-dominates the speed/performance frontier. On more diverse datasets, TabPFN-3 ranks first on datasets with many classes, and beats 8-hour-tuned gradient-boosted-tree baselines on datasets up to 1M training rows and 200 features. TabPFN-3 introduces test-time compute scaling to tabular foundation models. Our API offering TabPFN-3-Plus (Thinking) exploits this to beat all non-TabPFN models by over 200 Elo on TabArena, rising to 420 Elo on the largest data subset, and outperforms AutoGluon 1.5 extreme while being 10x faster, without using LLMs, real data, internet search or any other model besides TabPFN. TabPFN-3 extends the capabilities of our models, enabling SOTA prediction on relational data (new SOTA foundation model on RelBenchV1) and tabular-text data (SOTA on TabSTAR via TabPFN-3-Plus); and improves existing integrations: a specialized checkpoint, TabPFN-TS-3, ranks 2nd on the time-series benchmark fev-bench, and SHAP-value computation is up to 120x faster. TabPFN-3 achieves this performance while being up to 20x faster than TabPFN-2.5. In addition, a reduced KV cache and row-chunking scale to 1M rows on one H100 with fast inference speed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TabPFN-3, a scaled tabular foundation model pretrained exclusively on synthetic data from prior work. It claims a single forward pass outperforms all tuned and ensembled baselines on the TabArena benchmark while Pareto-dominating the speed-performance frontier; TabPFN-3-Plus (Thinking) achieves >200 Elo gains (up to 420 on large subsets) over non-TabPFN models, beats AutoGluon 1.5 extreme at 10x speed, and delivers new SOTAs on RelBenchV1 (relational) and TabSTAR (tabular-text) plus second place on fev-bench (time-series). Additional engineering claims include up to 20x speedups over TabPFN-2.5, 120x faster SHAP, and scaling to 1 M rows on one H100 via reduced KV cache and row chunking.
Significance. If the empirical results hold after rigorous validation, the work would represent a meaningful advance for tabular foundation models by demonstrating that synthetic pretraining plus test-time compute scaling can surpass heavily tuned gradient-boosted trees and AutoML systems on public benchmarks while delivering substantial inference speed-ups and cross-modal extensions. The reported ability to handle up to 1 M rows without real-data fine-tuning would be practically significant for industry deployments.
major comments (2)
- [Abstract] Abstract and Experimental Results: The headline claims of 'significant margin' outperformance on TabArena and 200–420 Elo gains for TabPFN-3-Plus are presented without error bars, statistical significance tests, exact train/test splits, or ablation studies on the synthetic generator, rendering the margins unverifiable from the provided information.
- [Pretraining Methodology] Pretraining section: The statement that pretraining uses 'exclusively synthetic data from our prior' lacks any decontamination protocol, held-out real-data validation set, or ablation freezing the generator before benchmark exposure; without these, the reported superiority over tuned baselines on TabArena risks circularity if the generator's feature/label/missingness distributions were calibrated to the evaluation suites.
minor comments (1)
- [Abstract] Clarify the precise mechanism of 'test-time compute scaling' in TabPFN-3-Plus (Thinking) and confirm it uses only TabPFN internals with no external models or search.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our technical report. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the presentation of our results without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and Experimental Results: The headline claims of 'significant margin' outperformance on TabArena and 200–420 Elo gains for TabPFN-3-Plus are presented without error bars, statistical significance tests, exact train/test splits, or ablation studies on the synthetic generator, rendering the margins unverifiable from the provided information.
Authors: We agree that additional statistical details would improve verifiability. In the revised manuscript we have added error bars (standard deviation over 10 independent runs with different random seeds) to all TabArena metrics, included Wilcoxon signed-rank tests confirming significance (p < 0.01 for the headline margins), explicitly cited the exact TabArena train/test splits per the benchmark protocol, and inserted an appendix ablation varying the synthetic generator's key hyperparameters while measuring downstream Elo impact. revision: yes
-
Referee: [Pretraining Methodology] Pretraining section: The statement that pretraining uses 'exclusively synthetic data from our prior' lacks any decontamination protocol, held-out real-data validation set, or ablation freezing the generator before benchmark exposure; without these, the reported superiority over tuned baselines on TabArena risks circularity if the generator's feature/label/missingness distributions were calibrated to the evaluation suites.
Authors: The generator was developed and frozen in prior work before TabArena and the other cited benchmarks existed, so no direct calibration occurred. We have added a new subsection to the Pretraining section that (1) describes the decontamination protocol (Kolmogorov-Smirnov tests on held-out real tabular samples to confirm distribution mismatch), (2) references a held-out real-data validation set used during generator development, and (3) reports an ablation in which the generator parameters are frozen prior to any benchmark exposure, showing that TabPFN-3 performance remains essentially unchanged. revision: yes
Circularity Check
Minor self-citation to prior synthetic generator; benchmark results remain externally validated
full rationale
The paper reports empirical wins on independent public benchmarks (TabArena, RelBenchV1, fev-bench) after pretraining exclusively on synthetic data referenced to prior work. No equations, fitted parameters, or derivations reduce the claimed Elo margins, speedups, or Pareto dominance to quantities defined by the evaluation suites themselves. The single self-reference to 'our prior' for the data generator is present but does not carry the load-bearing justification for the performance numbers, which rest on external test sets.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Pretrained exclusively on synthetic data from our prior... Structural Causal Model (SCM) prior
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three-stage architecture: Feature distribution embedding... Feature aggregation... In-context learning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
RelPrism: A Multi-Faceted Pre-training Framework with Self-Generated Tasks for Relational Databases
RelPrism generates self-supervised pseudo-tasks from three attribute perspectives via multi-granularity clustering to improve representation learning for relational database prediction tasks.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.