FashionChameleon: Towards Real-Time and Interactive Human-Garment Video Customization
Pith reviewed 2026-06-30 19:20 UTC · model grok-4.3
The pith
FashionChameleon enables real-time interactive garment switching in human videos trained only on single-garment data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
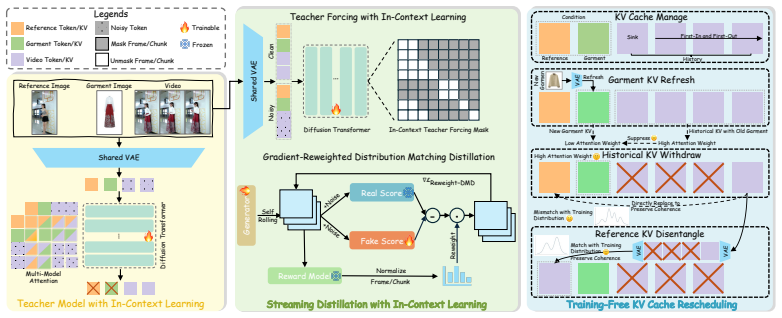
FashionChameleon achieves interactive multi-garment customization and consistent long-video extrapolation in autoregressive generation by training a Teacher Model with In-Context Learning on mismatched single-garment pairs, applying Streaming Distillation with in-context teacher forcing and gradient-reweighted distribution matching, and using Training-Free KV Cache Rescheduling that performs garment KV refresh, historical KV withdraw, and reference KV disentangle.
What carries the argument
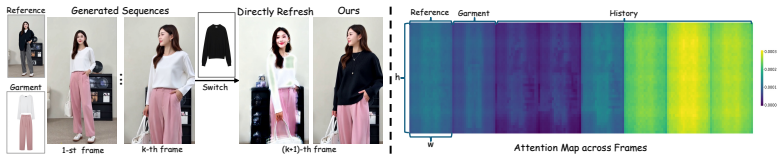
Training-Free KV Cache Rescheduling, which refreshes garment-specific key-value caches, withdraws historical caches, and disentangles reference caches to enable garment switching without retraining.
If this is right
- Users can switch garments interactively while a video is being generated autoregressively.
- Long video extrapolations remain consistent across garment changes.
- Generation reaches 23.8 FPS on a single GPU.
- The method runs 30-180 times faster than prior approaches that require multi-garment data.
Where Pith is reading between the lines
- The mismatch-training trick could reduce the data cost for other interactive video controls such as changing accessories or lighting.
- KV cache rescheduling might extend to real-time edits in other autoregressive generators where the identity of one element must change mid-sequence.
- If the coherence holds under garment switches, similar single-example training could support rapid personalization in e-commerce video try-on without collecting paired outfit videos.
Load-bearing premise
Enforcing a mismatch between reference and garment images during single-garment training will implicitly preserve motion coherence when garments are switched at inference time without any multi-garment training data.
What would settle it
Generate an extended video sequence with multiple garment switches and observe whether human motion or pose consistency breaks immediately after each switch.
Figures
















read the original abstract
Human-centric video customization, particularly at the garment level, has shown significant commercial value. However, existing approaches cannot support low-latency and interactive garment control, which is crucial for applications such as e-commerce and content creation. This paper studies how to achieve interactive multi-garment video customization while preserving motion coherence using only single-garment video data. We present FashionChameleon, a real-time and interactive framework for human-garment customization in autoregressive video generation, where users can interactively switch garment during generation. FashionChameleon consists of three key techniques: (i) Instead of training on multi-garment video data, we train a Teacher Model with In-Context Learning on a single reference-garment pair. By retaining the image-to-video training paradigm while enforcing a mismatch between the reference and garment image, the model is encouraged to implicitly preserve coherence during single-garment switching. (ii) To achieve consistency and efficiency during generation, we introduce Streaming Distillation with In-Context Learning, which fine-tunes the model with in-context teacher forcing and improves extrapolation consistency via gradient-reweighted distribution matching distillation. (iii) To extend the model for interactive multi-garment video customization, we propose Training-Free KV Cache Rescheduling, which includes garment KV refresh, historical KV withdraw, and reference KV disentangle to achieve garment switching while preserving motion coherence. Our FashionChameleon uniquely supports interactive customization and consistent long-video extrapolation, while achieving real-time generation at 23.8 FPS on a single GPU, 30-180$\times$ faster than existing baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents FashionChameleon, a framework for real-time interactive human-garment video customization in autoregressive generation. Using only single-garment video data, it trains a Teacher Model via in-context learning on mismatched reference-garment pairs to implicitly preserve motion coherence, then applies Streaming Distillation with in-context teacher forcing and gradient-reweighted distribution matching, and finally uses Training-Free KV Cache Rescheduling (garment KV refresh, historical KV withdraw, reference KV disentangle) to enable interactive multi-garment switching and long-video extrapolation. It claims unique support for interactive customization at 23.8 FPS on a single GPU, 30-180× faster than baselines.
Significance. If validated, the work would enable practical low-latency garment control for e-commerce and content creation without multi-garment training data. The training-free KV cache rescheduling and distillation approach represent a strength for efficiency in video generation pipelines.
major comments (2)
- [Abstract, technique (i)] Abstract, technique (i): The claim that mismatching reference and garment images during single-garment in-context training induces implicit motion coherence preservation for multi-garment switching at inference is load-bearing for the interactive customization claim, yet the training objective provides no direct supervision on garment identity changes with fixed motion; the transfer to inference-time switching remains untested without multi-garment sequences.
- [Abstract, overall results] Abstract, overall results: The abstract asserts 23.8 FPS real-time performance and 30-180× speedup over baselines along with consistent long-video extrapolation, but provides no quantitative tables, ablation studies, or error metrics on coherence under garment switches; this absence prevents verification of the central coherence-preservation claim.
minor comments (1)
- [Abstract] Abstract: The description of the three techniques could explicitly state the datasets and exact baseline methods used for the speed and coherence comparisons.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments. Below we address each major comment point-by-point, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract, technique (i)] Abstract, technique (i): The claim that mismatching reference and garment images during single-garment in-context training induces implicit motion coherence preservation for multi-garment switching at inference is load-bearing for the interactive customization claim, yet the training objective provides no direct supervision on garment identity changes with fixed motion; the transfer to inference-time switching remains untested without multi-garment sequences.
Authors: The in-context learning with mismatched reference-garment pairs is specifically designed to train the model to maintain motion coherence from the reference while accommodating garment variations, without requiring multi-garment data. Although there is no explicit supervision for identity changes, this setup facilitates the desired behavior at inference. We have validated the approach through inference experiments involving garment switches. To further strengthen the presentation, we will expand the discussion on this technique and include additional ablations in the revision. revision: partial
-
Referee: [Abstract, overall results] Abstract, overall results: The abstract asserts 23.8 FPS real-time performance and 30-180× speedup over baselines along with consistent long-video extrapolation, but provides no quantitative tables, ablation studies, or error metrics on coherence under garment switches; this absence prevents verification of the central coherence-preservation claim.
Authors: The reported FPS and speedup figures are supported by runtime measurements and baseline comparisons presented in the experimental section of the manuscript. We recognize that additional quantitative metrics specifically addressing coherence during garment switches would enhance verifiability. Accordingly, we will incorporate new tables, ablation studies, and relevant error metrics in the revised version. revision: yes
Circularity Check
No significant circularity; claims rest on independent training design choices
full rationale
The paper describes a training procedure (in-context learning on mismatched single reference-garment pairs) and auxiliary techniques (streaming distillation, training-free KV cache rescheduling) to support interactive garment switching. These are presented as design decisions whose effectiveness is evaluated empirically, not as a derivation that reduces to fitted parameters or self-citations by construction. No equations equate outputs to inputs tautologically, and no load-bearing self-citation chains are invoked. The central assumption about implicit coherence transfer is a methodological hypothesis, not a circular reduction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
TryOnCrafter: Unleashing Camera Trajectories for Realistic Video Virtual Try-on via a Renderable 4D Try-on Proxy
TryOnCrafter is the first DiT-based framework for camera-controllable video virtual try-on via a renderable 4D try-on proxy distilled from 2D priors into 3DGS avatar animated with SMPL-X.
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” in Conference on Neural Information Processing Systems, 2020
2020
-
[2]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Z. Yang, J. Teng, W. Zheng, M. Ding, S. Huang, J. Xu, Y . Yang, W. Hong, X. Zhang, G. Feng et al., “Cogvideox: Text-to-video diffusion models with an expert transformer,”arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
W. Kong, Q. Tian, Z. Zhang, R. Min, Z. Dai, J. Zhou, J. Xiong, X. Li, B. Wu, J. Zhanget al., “Hunyuanvideo: A systematic framework for large video generative models,” arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Wan: Open and Advanced Large-Scale Video Generative Models
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang et al., “Wan: Open and advanced large-scale video generative models,” arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Realcam-i2v: Real-world image-to-video generation with interactive complex camera control,
T. Li, G. Zheng, R. Jiang, S. Zhan, T. Wu, Y . Lu, Y . Lin, C. Deng, Y . Xiong, M. Chenet al., “Realcam-i2v: Real-world image-to-video generation with interactive complex camera control,” in International Conference on Computer Vision, 2025
2025
-
[7]
Drivegenvlm: Real-world video generation for vision language model based autonomous driving,
Y . Fu, A. Jain, X. Chen, Z. Mo, and X. Di, “Drivegenvlm: Real-world video generation for vision language model based autonomous driving,” in IEEE International automated vehicle validation conference, 2024
2024
-
[8]
arXiv preprint arXiv:2511.22098 (2025)
Q. Song, Y . Song, K. Peng, Y . Gao, and M. Z. Shou, “Worldwander: Bridging egocentric and exocentric worlds in video generation,”arXiv preprint arXiv:2511.22098, 2025
-
[9]
Customvideo: Customizing text-to-video generation with multiple subjects,
Z. Wang, A. Li, L. Zhu, Y . Guo, Q. Dou, and Z. Li, “Customvideo: Customizing text-to-video generation with multiple subjects,”IEEE Transactions on Multimedia, 2026
2026
-
[10]
Disenstudio: Cus- tomized multi-subject text-to-video generation with disentangled spatial control,
H. Chen, X. Wang, Y . Zhang, Y . Zhou, Z. Zhang, S. Tang, and W. Zhu, “Disenstudio: Cus- tomized multi-subject text-to-video generation with disentangled spatial control,” in ACM International Conference on Multimedia, 2024
2024
-
[11]
X. He, Q. Liu, S. Qian, X. Wang, T. Hu, K. Cao, K. Yan, and J. Zhang, “Id-animator: Zero-shot identity-preserving human video generation,”arXiv preprint arXiv:2404.15275, 2024
-
[12]
Identity-preserving text- to-video generation by frequency decomposition,
S. Yuan, J. Huang, X. He, Y . Ge, Y . Shi, L. Chen, J. Luo, and L. Yuan, “Identity-preserving text- to-video generation by frequency decomposition,” in IEEE Conference on Computer Vision and Pattern Recognition, 2025. 10
2025
-
[13]
L. Liu, T. Ma, B. Li, Z. Chen, J. Liu, G. Li, S. Zhou, Q. He, and X. Wu, “Phantom: Subject- consistent video generation via cross-modal alignment,” arXiv preprint arXiv:2502.11079, 2025
-
[14]
Vace: All-in-one video creation and editing,
Z. Jiang, Z. Han, C. Mao, J. Zhang, Y . Pan, and Y . Liu, “Vace: All-in-one video creation and editing,” inInternational Conference on Computer Vision, 2025
2025
-
[15]
Stand-in: A lightweight and plug-and-play identity control for video generation,
B. Xue, Z.-P. Duan, Q. Yan, W. Wang, H. Liu, C.-L. Guo, C. Li, C. Li, and J. Lyu, “Stand-in: A lightweight and plug-and-play identity control for video generation,” inIEEE Conference on Computer Vision and Pattern Recognition, 2026
2026
-
[16]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” in International Conference on Computer Vision, 2023
2023
-
[17]
Bindweave: Subject-consistent video generation via cross-modal integration,
Z. Li, D. Qian, K. Su, Q. Diao, X. Xia, C. Liu, W. Yang, T. Zhang, and Z. Yuan, “Bindweave: Subject-consistent video generation via cross-modal integration,”arXiv preprint arXiv:2510.00438, 2025
-
[18]
Y . Deng, Y . Yin, X. Guo, Y . Wang, J. Z. Fang, S. Yuan, Y . Yang, A. Wang, B. Liu, H. Huanget al., “Magref: Masked guidance for any-reference video generation with subject disentanglement,” arXiv preprint arXiv:2505.23742, 2025
-
[19]
Skyreels-a2: Compose anything in video diffusion transformers.arXivpreprint arXiv:2504.02436, 2025
Z. Fei, D. Li, D. Qiu, J. Wang, Y . Dou, R. Wang, J. Xu, M. Fan, G. Chen, Y . Liet al., “Skyreels- a2: Compose anything in video diffusion transformers,” arXiv preprint arXiv:2504.02436, 2025
-
[20]
Kaleido: Open-sourced multi-subject reference video generation model.CoRR, abs/2510.18573, 2025
Z. Zhang, J. Teng, Z. Yang, T. Cao, C. Wang, X. Gu, J. Tang, D. Guo, and M. Wang, “Kaleido: Open-sourced multi-subject reference video generation model,” arXiv preprint arXiv:2510.18573, 2025
-
[21]
Motionctrl: A unified and flexible motion controller for video generation,
Z. Wang, Z. Yuan, X. Wang, Y . Li, T. Chen, M. Xia, P. Luo, and Y . Shan, “Motionctrl: A unified and flexible motion controller for video generation,” inACM SIGGRAPH Conference on Computer Graphics and Interactive Techniques, 2024
2024
-
[22]
arXiv preprint arXiv:2503.06508 (2025)
Q. Song, Z. Lin, Z. Zeng, Z. Zhang, L. Cao, and R. Ji, “Lightmotion: A light and tuning-free method for simulating camera motion in video generation,”arXiv preprint arXiv:2503.06508, 2025
-
[23]
Artifical intelligence in e-commerce: Applications, implications and challenges,
H. A. Lari, K. Vaishnava, and K. Manu, “Artifical intelligence in e-commerce: Applications, implications and challenges,”Asian Journal of Management, 2022
2022
-
[24]
Photomaker: Customizing realistic human photos via stacked id embedding,
Z. Li, M. Cao, X. Wang, Z. Qi, M.-M. Cheng, and Y . Shan, “Photomaker: Customizing realistic human photos via stacked id embedding,” inIEEE Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[25]
Univst: A unified framework for training-free localized video style transfer,
Q. Song, M. Lin, W. Zhan, S. Yan, L. Cao, and R. Ji, “Univst: A unified framework for training-free localized video style transfer,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[26]
Objectadd: adding objects into image via a training-free diffusion modification fashion,
Z. Zhang, M. Lin, Q. Song, Y . Zhang, and R. Ji, “Objectadd: adding objects into image via a training-free diffusion modification fashion,”Pattern Recognition, 2025
2025
-
[27]
From slow bidirectional to fast autoregressive video diffusion models,
T. Yin, Q. Zhang, R. Zhang, W. T. Freeman, F. Durand, E. Shechtman, and X. Huang, “From slow bidirectional to fast autoregressive video diffusion models,” inIEEE Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[28]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
X. Huang, Z. Li, G. He, M. Zhou, and E. Shechtman, “Self forcing: Bridging the train-test gap in autoregressive video diffusion,”arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
H. Zhu, M. Zhao, G. He, H. Su, C. Li, and J. Zhu, “Causal forcing: Autoregressive diffusion distillation done right for high-quality real-time interactive video generation,”arXiv preprint arXiv:2602.02214, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
J. Zhuang, S. Guo, X. Cai, X. Li, Y . Liu, C. Yuan, and T. Xue, “Flashvsr: Towards real-time diffusion-based streaming video super-resolution,”arXiv preprint arXiv:2510.12747, 2025
-
[31]
Live Avatar: Streaming Real-time Audio-Driven Avatar Generation with Infinite Length
Y . Huang, H. Guo, F. Wu, S. Zhang, S. Huang, Q. Gan, L. Liu, S. Zhao, E. Chen, J. Liuet al., “Live avatar: Streaming real-time audio-driven avatar generation with infinite length,”arXiv preprint arXiv:2512.04677, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
J. Shin, Z. Li, R. Zhang, J.-Y . Zhu, J. Park, E. Shechtman, and X. Huang, “Motionstream: Real-time video generation with interactive motion controls,”arXiv preprint arXiv:2511.01266, 2025
-
[33]
All are worth words: A vit backbone for diffusion models,
F. Bao, S. Nie, K. Xue, Y . Cao, C. Li, H. Su, and J. Zhu, “All are worth words: A vit backbone for diffusion models,” inIEEE Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[34]
Diffusion forc- ing: Next-token prediction meets full-sequence diffusion,
B. Chen, D. Martí Monsó, Y . Du, M. Simchowitz, R. Tedrake, and V . Sitzmann, “Diffusion forc- ing: Next-token prediction meets full-sequence diffusion,” inConference on Neural Information Processing Systems, 2024
2024
-
[35]
VideoPoet: A Large Language Model for Zero-Shot Video Generation
D. Kondratyuk, L. Yu, X. Gu, J. Lezama, J. Huang, G. Schindler, R. Hornung, V . Birodkar, J. Yan, M.-C. Chiu et al., “Videopoet: A large language model for zero-shot video generation,” arXiv preprint arXiv:2312.14125, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
P. Sun, Y . Jiang, S. Chen, S. Zhang, B. Peng, P. Luo, and Z. Yuan, “Autoregressive model beats diffusion: Llama for scalable image generation,” arXiv preprint arXiv:2406.06525, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Improved distribution matching distillation for fast image synthesis,
T. Yin, M. Gharbi, T. Park, R. Zhang, E. Shechtman, F. Durand, and W. T. Freeman, “Improved distribution matching distillation for fast image synthesis,” inConference on Neural Information Processing Systems, 2024
2024
-
[38]
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time
K. Liu, W. Hu, J. Xu, Y . Shan, and S. Lu, “Rolling forcing: Autoregressive long video diffusion in real time,”arXiv preprint arXiv:2509.25161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Y . Lu, Y . Zeng, H. Li, H. Ouyang, Q. Wang, K. L. Cheng, J. Zhu, H. Cao, Z. Zhang, X. Zhuet al., “Reward forcing: Efficient streaming video generation with rewarded distribution matching distillation,”arXiv preprint arXiv:2512.04678, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
arXiv preprint arXiv:2511.20649 (2025)
H. Yesiltepe, T. H. S. Meral, A. K. Akan, K. Oktay, and P. Yanardag, “Infinity-rope: Action- controllable infinite video generation emerges from autoregressive self-rollout,”arXiv preprint arXiv:2511.20649, 2025
-
[41]
LongLive: Real-time Interactive Long Video Generation
S. Yang, W. Huang, R. Chu, Y . Xiao, Y . Zhao, X. Wang, M. Li, E. Xie, Y . Chen, Y . Luet al., “Longlive: Real-time interactive long video generation,” arXiv preprint arXiv:2509.22622, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
S. Huang, J. Wu, Q. Zhou, S. Miao, and M. Long, “Vid2world: Crafting video diffusion models to interactive world models,”arXiv preprint arXiv:2505.14357, 2025
-
[43]
Yume-1.5: A text-controlled interactive world generation model.arXiv preprint arXiv:2512.22096, 2025
X. Mao, Z. Li, C. Li, X. Xu, K. Ying, T. He, J. Pang, Y . Qiao, and K. Zhang, “Yume-1.5: A text-controlled interactive world generation model,”arXiv preprint arXiv:2512.22096, 2025
-
[44]
WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
W. Sun, H. Zhang, H. Wang, J. Wu, Z. Wang, Z. Wang, Y . Wang, J. Zhang, T. Wang, and C. Guo, “Worldplay: Towards long-term geometric consistency for real-time interactive world modeling,” arXiv preprint arXiv:2512.14614, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Matrix-game: Interactive world foundation model.arXiv preprint arXiv:2506.18701, 2025
Y . Zhang, C. Peng, B. Wang, P. Wang, Q. Zhu, F. Kang, B. Jiang, Z. Gao, E. Li, Y . Liuet al., “Matrix-game: Interactive world foundation model,”arXiv preprint arXiv:2506.18701, 2025
-
[46]
K. Gao, J. Shi, H. Zhang, C. Wang, J. Xiao, and L. Chen, “Ca2-vdm: Efficient autore- gressive video diffusion model with causal generation and cache sharing,” arXiv preprint arXiv:2411.16375, 2024
-
[47]
J. Hu, S. Hu, Y . Song, Y . Huang, M. Wang, H. Zhou, Z. Liu, W.-Y . Ma, and M. Sun, “Acdit: Interpolating autoregressive conditional modeling and diffusion transformer,”arXiv preprint arXiv:2412.07720, 2024
-
[48]
T. Zhang, S. Bi, Y . Hong, K. Zhang, F. Luan, S. Yang, K. Sunkavalli, W. T. Freeman, and H. Tan, “Test-time training done right,”arXiv preprint arXiv:2505.23884, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
C. Wu, J. Li, J. Zhou, J. Lin, K. Gao, K. Yan, S.-m. Yin, S. Bai, X. Xu, Y . Chen et al., “Qwen-image technical report,”arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
S. Yuan, X. He, Y . Deng, Y . Ye, J. Huang, B. Lin, J. Luo, and L. Yuan, “Opens2v-nexus: A detailed benchmark and million-scale dataset for subject-to-video generation,”arXiv preprint arXiv:2505.20292, 2025
-
[51]
Vbench: Comprehensive benchmark suite for video generative models,
Z. Huang, Y . He, J. Yu, F. Zhang, C. Si, Y . Jiang, Y . Zhang, T. Wu, Q. Jin, N. Chanpaisitet al., “Vbench: Comprehensive benchmark suite for video generative models,” inIEEE Conference on Computer Vision and Pattern Recognition, 2024. 12
2024
-
[52]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” in International Conference on Learning Representations, 2022
2022
-
[53]
Unimatch: Universal matching from atom to task for few-shot drug discovery,
R. Li, M. Li, W. Liu, Y . Zhou, X. Zhou, Y . Yao, Q. Zhang, and H. Chen, “Unimatch: Universal matching from atom to task for few-shot drug discovery,” arXiv preprint arXiv:2502.12453, 2025
-
[54]
Q-Align: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels
H. Wu, Z. Zhang, W. Zhang, C. Chen, L. Liao, C. Li, Y . Gao, A. Wang, E. Zhang, W. Sunet al., “Q-align: Teaching lmms for visual scoring via discrete text-defined levels,” arXiv preprint arXiv:2312.17090, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Fast-vqa: Efficient end-to-end video quality assessment with fragment sampling,
H. Wu, C. Chen, J. Hou, L. Liao, A. Wang, W. Sun, Q. Yan, and W. Lin, “Fast-vqa: Efficient end-to-end video quality assessment with fragment sampling,” in European Conference on Computer Vision, 2022
2022
-
[56]
Arcface: Additive angular margin loss for deep face recognition,
J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” inIEEE Conference on Computer Vision and Pattern Recognition, 2019
2019
-
[57]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge et al., “Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution,” arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Musiq: Multi-scale image quality trans- former,
J. Ke, Q. Wang, Y . Wang, P. Milanfar, and F. Yang, “Musiq: Multi-scale image quality trans- former,” inInternational Conference on Computer Vision, 2021. 13 ❓Upper ❓Lower ❓Full RawVideoDatabase ShotSegmentation OverallAssessmentHumanDetectionOptical-FlowEstimateStage1:GeneralCoarse-to-Fine Video FilteringStage2:Static-Dynamic VideoCaptioning Stage3:Fine-...
2021
-
[59]
Adaptive Reference Image Construction
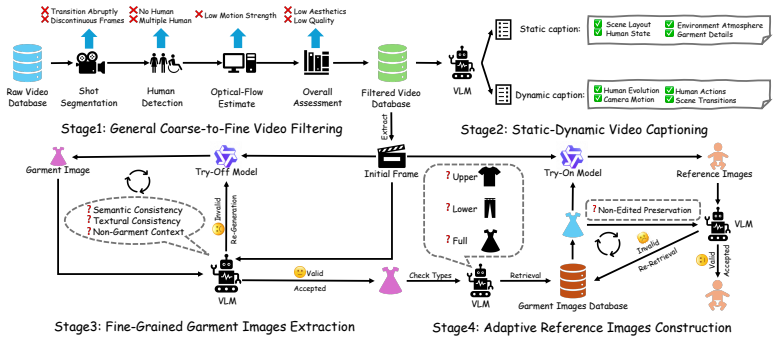
Fine-Grained Garment Image Extraction, and4. Adaptive Reference Image Construction. The overall curation pipeline is illustrated in Figure 8, and we detail each stage as follows:
-
[60]
These clips are then further divided into 3-5 second subclips, while discontinuous or overly short subclips are removed
General Coarse-to-Fine Video Filtering.We collected a large set of raw videos from the Internet and filtered them in a coarse-to-fine manner usingShot Segmentation,Human Detection, Optical-Flow Estimation, andOverall Assessmentto retain only qualified videos: • Shot Segmentation.The raw videos are first processed with PySceneDetect to identify scene trans...
-
[61]
Static-Dynamic Video Captioning.For the filtered videos, we use the vision-language model (VLM) Gemini-3.1 to generate captions. Specifically, we adopt a static-dynamic decoupling strategy: • Static Caption.We prompt the VLM to focus on the static content in each video, includ- ing the scene layout, environmental atmosphere, human attributes (e.g., appear...
-
[62]
Since try-off is not always reliable in practice, we further introduce a VLM to verify the extracted garments
Fine-Grained Garment Images Extraction.For each filtered video, we extract the initial frame and apply the image try-off model Qwen-Image-Edit [49] to extract corresponding garment images. Since try-off is not always reliable in practice, we further introduce a VLM to verify the extracted garments. In detail, for each extracted garment, the VLM performs a...
-
[63]
To improve training robustness, the garment worn by the person in the reference image should differ from the extracted garment
Adaptive Reference Images Construction.In the final stage, we construct the reference image. To improve training robustness, the garment worn by the person in the reference image should differ from the extracted garment. We note that the garment information extracted in the previous stage may be incomplete, for example, including only the upper-body or lo...
-
[64]
She takes light steps forward, with her arms swinging naturally
“A woman wearing a blue beret, earrings, and a watch stands on a floral garden path. She takes light steps forward, with her arms swinging naturally. Her gaze shifts from downward to focusing on the lens with a gentle smile, then smoothly transitions into a still pose, ensuring the movement is continuous and physically realistic.” For reproducibility, we ...
-
[65]
Initially facing the camera, she subtly shifts her body to the left and places her left hand into her pocket
“A woman performs a series of poses in an indoor setting while holding a white handbag in her right hand. Initially facing the camera, she subtly shifts her body to the left and places her left hand into her pocket. She then moves her left hand to rest lightly on a black shelving unit behind her. Throughout the video, she maintains a friendly smile and st...
-
[66]
He maintains a steady forward gait, his arms swinging naturally to showcase the drape of the new garment
“A man strolls along an outdoor brick path, wearing a brown turtleneck long-sleeved knit sweater paired with white shorts and beige sandals. He maintains a steady forward gait, his arms swinging naturally to showcase the drape of the new garment. The camera performs a smooth tracking shot, moving backward to keep him centered in the frame. Initially looki...
-
[67]
She initially tilts her head slightly to the side, then naturally shifts her gaze back to the lens with a soft smile
“A young woman stands in a room, wearing a red short-sleeved t-shirt paired with a long floral skirt, with a red string bracelet on her left wrist. She initially tilts her head slightly to the side, then naturally shifts her gaze back to the lens with a soft smile. She performs a subtle turn to the left, causing the hem of the long skirt to sway with natu...
-
[68]
She walks forward with an elegant catwalk stride, her arms swinging naturally while her platform sneakers land steadily
“A young woman walks near park flowers, wearing a blue zippered crop top and lace-up distressed denim shorts, accented with a white cap, necklace, and a bag featuring a teddy bear charm. She walks forward with an elegant catwalk stride, her arms swinging naturally while her platform sneakers land steadily. The camera performs a steady tracking shot, keepi...
-
[69]
She wears purple flower earrings and carries a pink woven bag on her shoulder
“A young woman stands against a pink and blue background. She wears purple flower earrings and carries a pink woven bag on her shoulder. She walks forward with light steps, her arms swinging naturally, while the bag strap bounces slightly. She then tilts her head toward the camera with a bright smile and a natural blink. The movement is smooth and consist...
-
[70]
She wears a baseball cap with text and has one hand in her pocket
“A young woman stands in a room filled with books and vintage items. She wears a baseball cap with text and has one hand in her pocket. She slowly lowers her hand from the cap, shifts her weight, and turns slightly to the right. Her gaze shifts from the lens toward the stack of books before turning back to blink and smile naturally. The movement is smooth...
-
[71]
She initially looks down in reflection, then gracefully turns her head to the left, gazing into the distance
“In the video, a young woman slowly enters from the right side of the frame and stops near a table. She initially looks down in reflection, then gracefully turns her head to the left, gazing into the distance. The camera remains in a fixed position, capturing the scene through a transparent glass door, with subtle reflections on the glass shifting as she ...
-
[72]
She raises her left hand to touch and adjust her hair, tossing it over her shoulder while her arms move naturally in sync with her shifting posture
“Captured from a static camera angle, a young woman with long, flowing black hair sways her body gracefully to a rhythmic beat. She raises her left hand to touch and adjust her hair, tossing it over her shoulder while her arms move naturally in sync with her shifting posture. Throughout the sequence, she maintains direct eye contact with the camera, exhib...
-
[73]
She slowly lowers her raised right arm and turns her body slightly to the left to showcase the skirt’s silhouette
“On a lush tree-lined path, a woman wears a black and white checkered vest paired with a blue mini skirt featuring a cherry graphic, accented by a pearl necklace and white boots. She slowly lowers her raised right arm and turns her body slightly to the left to showcase the skirt’s silhouette. The camera orbits steadily around her in an arc. She shifts her...
-
[74]
She slowly lowers her raised right arm and takes a natural step forward to showcase the outfit
“A woman in a blue cap and sunglasses stands by a white tiled wall, wearing a light grey multi-pocket hooded jacket, white wide-leg pants, and beige shoes, holding a brown bag with a bear charm. She slowly lowers her raised right arm and takes a natural step forward to showcase the outfit. The camera pans horizontally to the right; she turns her head from...
-
[75]
She walks steadily toward the camera, the long skirt’s hem swaying naturally and gracefully with her steps
“A young woman stands outdoors wearing white headphones and sunglasses, dressed in a black short-sleeved T-shirt and a dark green button-front maxi skirt, carrying a black backpack with white socks and sneakers. She walks steadily toward the camera, the long skirt’s hem swaying naturally and gracefully with her steps. The camera pulls back smoothly to rev...
-
[76]
He walks forward with steady steps, his body swaying naturally to showcase the fit of the tank top
“On a city street, a black-haired man wearing sunglasses is dressed in a black U-neck tank top paired with ripped blue jeans and a black belt, holding a brown leather bag in his right hand with a watch and bracelet on his wrists. He walks forward with steady steps, his body swaying naturally to showcase the fit of the tank top. The camera slowly zooms out...
-
[77]
She walks toward the camera with light catwalk steps, the layered hem swaying naturally
“A young woman stands by the poolside with city buildings in the background, wearing a turquoise long-sleeved shirt and a white tiered ruffled long skirt, holding a small cream- colored handbag. She walks toward the camera with light catwalk steps, the layered hem swaying naturally. The camera slowly zooms out to reveal the full silhouette; her gaze shift...
-
[78]
She looks down initially, then raises her gaze to the camera while turning slightly to the left, allowing the skirt to drape naturally
“A young woman stands in a minimalist gray indoor setting, wearing a white puff-sleeved blouse and a red phoenix-embroidered vest paired with a red patterned pleated skirt, with a thin bracelet on her left wrist. She looks down initially, then raises her gaze to the camera while turning slightly to the left, allowing the skirt to drape naturally. The came...
-
[79]
He slowly transitions from a leaning pose to a steady upright stance, balancing his weight on both feet to showcase the silhouette
“In front of a white wall, a man wearing black-rimmed glasses holds a coffee cup, dressed in a tan sports bra and dark brown leggings with white sneakers. He slowly transitions from a leaning pose to a steady upright stance, balancing his weight on both feet to showcase the silhouette. The camera zooms out smoothly to capture the full outfit; he tilts his...
-
[80]
He moves his hands out of his pockets to his sides and walks forward toward the camera, the loose pant legs creating natural folds and swaying with each step
“A young man wearing a baseball cap and black glasses stands before a dark rolling shutter, dressed in a white long-sleeved top and dark blue wide-leg trousers. He moves his hands out of his pockets to his sides and walks forward toward the camera, the loose pant legs creating natural folds and swaying with each step. The camera tracks him steadily; he ti...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.