When Tabular Foundation Models Meet Strategic Tabular Data: A Prior Alignment Approach
Pith reviewed 2026-06-30 18:28 UTC · model grok-4.3
The pith
Strategic in-context examples align pretrained tabular models to post-manipulation data without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
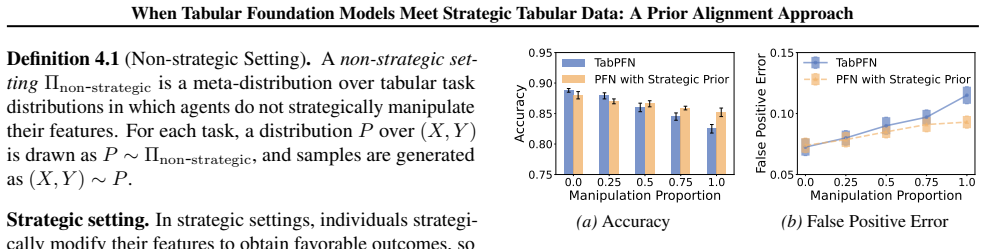
Strategic manipulation creates a mismatch between the non-strategic prior learned during pretraining and the post-manipulation strategic prior, which leads to systematic prediction bias in PFN-style tabular foundation models. SPN is an inference-time framework that constructs strategic in-context examples to approximate post-manipulation inputs and aligns PFN predictions with the induced strategic distribution without any retraining.
What carries the argument
Strategic Prior-data Fitted Network (SPN), which constructs strategic in-context examples to approximate post-manipulation inputs and align predictions with the induced strategic distribution.
If this is right
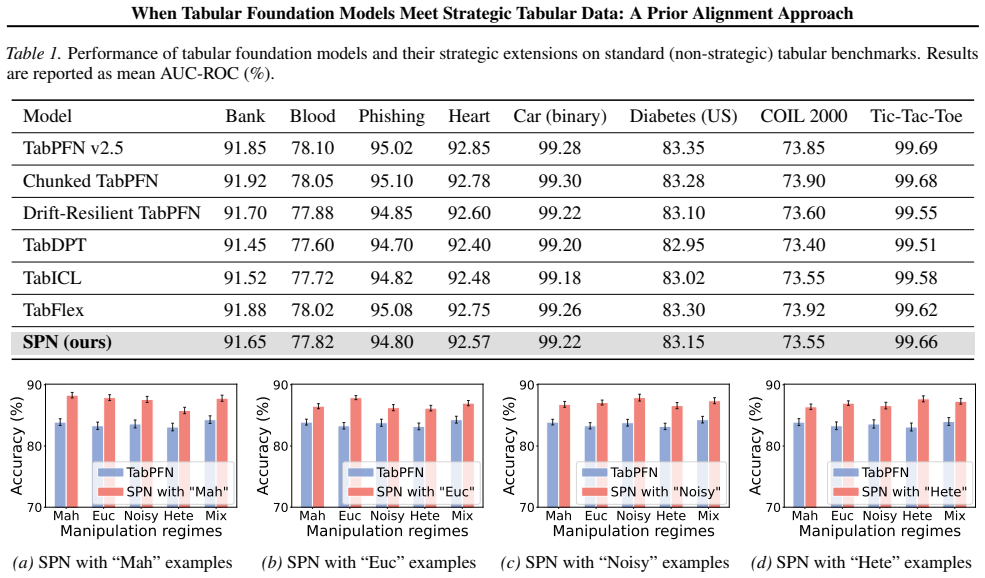
- SPN improves robustness and predictive performance under strategic manipulation on both real-world and synthetic tabular datasets.
- The method outperforms both standard tabular foundation models and classical tabular methods when agents strategically alter features.
- Adaptation occurs at inference time without retraining the underlying pretrained model.
- The alignment works across diverse tabular tasks that involve post-deployment distribution shifts induced by strategic behavior.
Where Pith is reading between the lines
- Similar inference-time example construction could reduce bias in other non-strategic pretrained models facing different forms of distribution shift.
- The approach implies that generating accurate strategic examples may become a key engineering step for deploying foundation models in game-theoretic environments.
- If the prior mismatch approximation holds more generally, it could lower the cost of adapting large tabular models to new strategic regimes.
Load-bearing premise
Strategic manipulation creates a systematic mismatch between non-strategic and strategic priors that can be effectively approximated at inference time by constructing strategic in-context examples without retraining.
What would settle it
A dataset experiment in which constructing strategic in-context examples fails to reduce the measured prediction bias on post-manipulation inputs relative to the unadapted model.
Figures







read the original abstract
Tabular foundation models based on pretrained prior-data fitted networks~(PFNs) have shown strong generalization on diverse tabular tasks, but they are typically designed for \emph{non-strategic} settings where data distributions are independent of deployed classifiers. In many real-world decision scenarios, however, individuals may strategically modify their features after deployment to obtain favorable outcomes, inducing a post-deployment distribution shift. This paper studies whether PFN-style tabular foundation models can generalize to such \emph{strategic} tabular data. We show that strategic manipulation creates a mismatch between the non-strategic prior learned during pretraining and the post-manipulation strategic prior, which leads to systematic prediction bias. To address this issue, we propose \textbf{Strategic Prior-data Fitted Network}~\textit{(SPN)}, an inference-time strategy-aware framework that adapts tabular foundation models to strategic environments without retraining. SPN constructs strategic in-context examples to approximate post-manipulation inputs and aligns PFN predictions with the induced strategic distribution. Experiments on real-world and synthetic tabular datasets show that SPN consistently improves robustness and predictive performance under strategic manipulation compared with both tabular foundation models and classical tabular methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Strategic Prior-data Fitted Network (SPN), an inference-time adaptation framework for pretrained Prior-data Fitted Networks (PFNs) on tabular data. It argues that strategic feature manipulation by agents induces a systematic mismatch between the non-strategic prior learned in pretraining and the post-manipulation distribution, causing prediction bias. SPN addresses this by constructing strategic in-context examples inside a frozen PFN to approximate the strategic prior and align outputs accordingly, without any retraining. Experiments on real-world and synthetic tabular datasets are claimed to demonstrate consistent gains in robustness and predictive performance relative to both standard tabular foundation models and classical methods.
Significance. If the core approximation holds, the work would extend tabular foundation models to strategic decision domains (e.g., lending, hiring) where post-deployment gaming is common, while preserving the efficiency of inference-only adaptation. The inference-time design avoids the need to collect or simulate strategic data during pretraining, which is a practical advantage. The paper receives credit for identifying the prior-mismatch issue and for attempting an adaptation that stays within the PFN paradigm rather than requiring architectural changes.
major comments (3)
- [§3] §3 (Method description): The construction of strategic in-context examples is presented at a high level as a means to 'approximate post-manipulation inputs,' but supplies no concrete procedure, assumed manipulation model (e.g., cost function or feature-change constraints), number of examples, selection rule, or proof that the resulting in-context distribution matches the true strategic distribution. This is load-bearing for the central claim that the mismatch can be corrected at inference time inside an unchanged PFN.
- [§4] §4 (Experiments): The reported improvements under strategic manipulation are not accompanied by the specific manipulation model used to generate test distributions, ablations on the number or quality of in-context examples, or comparisons against oracles that have access to the true strategic prior. Without these controls it is impossible to isolate whether gains arise from the proposed alignment or from incidental properties of the synthetic data generator.
- [§2] §2 (Motivation): The assertion that strategic manipulation 'creates a mismatch between the non-strategic prior learned during pretraining and the post-manipulation strategic prior' is stated without a quantitative characterization (e.g., expected prediction bias, divergence between the two priors, or closed-form effect on PFN outputs). A formal statement of this mismatch would be required to justify why in-context alignment is the appropriate remedy.
minor comments (2)
- [Abstract] Notation: 'Prior-data Fitted Network' is inconsistently capitalized and abbreviated (PFN vs. PFNs); a single definition early in the paper would improve readability.
- [§1] The manuscript would benefit from explicit citations to the strategic classification literature (e.g., works on Stackelberg games or performative prediction) to situate the prior-mismatch claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional detail and controls will strengthen the presentation. We address each major comment below and will incorporate the suggested clarifications and experiments in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method description): The construction of strategic in-context examples is presented at a high level as a means to 'approximate post-manipulation inputs,' but supplies no concrete procedure, assumed manipulation model (e.g., cost function or feature-change constraints), number of examples, selection rule, or proof that the resulting in-context distribution matches the true strategic distribution. This is load-bearing for the central claim that the mismatch can be corrected at inference time inside an unchanged PFN.
Authors: We agree that the method description would benefit from greater concreteness. In the revision we will expand §3 to specify: the assumed manipulation model (quadratic costs with per-feature budgets, following standard strategic classification setups), the exact generation procedure for strategic in-context examples (including how post-manipulation features are sampled), the number of examples and selection rule, and an empirical analysis (or sketch) demonstrating that the induced in-context distribution approximates the true strategic prior. These additions will make the alignment mechanism fully reproducible and substantiate the central claim. revision: yes
-
Referee: [§4] §4 (Experiments): The reported improvements under strategic manipulation are not accompanied by the specific manipulation model used to generate test distributions, ablations on the number or quality of in-context examples, or comparisons against oracles that have access to the true strategic prior. Without these controls it is impossible to isolate whether gains arise from the proposed alignment or from incidental properties of the synthetic data generator.
Authors: We acknowledge that these controls are necessary to isolate the contribution of the alignment mechanism. In the revised manuscript we will: explicitly document the manipulation models and parameters used for each dataset, add ablations on the number and quality of in-context examples, and include oracle baselines that have direct access to the true post-manipulation distribution (via full simulation of strategic responses). These additions will clarify that observed gains stem from the proposed prior alignment rather than data-generator artifacts. revision: yes
-
Referee: [§2] §2 (Motivation): The assertion that strategic manipulation 'creates a mismatch between the non-strategic prior learned during pretraining and the post-manipulation strategic prior' is stated without a quantitative characterization (e.g., expected prediction bias, divergence between the two priors, or closed-form effect on PFN outputs). A formal statement of this mismatch would be required to justify why in-context alignment is the appropriate remedy.
Authors: We agree that a quantitative characterization would strengthen the motivation section. In the revision we will augment §2 with: a formal definition of the two priors, quantitative measures of mismatch (e.g., expected prediction bias and distributional divergence such as KL or Wasserstein distance under simplified models), and an illustration of the resulting effect on PFN outputs. This will provide a clearer justification for why inference-time in-context alignment is an appropriate remedy. revision: yes
Circularity Check
No circularity; SPN presented as independent inference-time adaptation
full rationale
The paper introduces SPN as a novel framework that constructs strategic in-context examples at inference time inside a frozen PFN to approximate post-manipulation inputs. No equations or steps reduce a claimed prediction to a fitted parameter by construction, no self-citation chains justify core premises, and no ansatz or uniqueness result is imported from prior author work. The mismatch between non-strategic and strategic priors is stated as an observed phenomenon addressed by the proposed method rather than derived tautologically from the inputs. This is the common case of a self-contained proposal whose validity rests on external experimental validation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pretrained PFNs capture useful non-strategic priors for tabular tasks
- domain assumption Strategic feature modification induces a predictable post-deployment distribution shift
invented entities (1)
-
Strategic Prior-data Fitted Network (SPN)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Partial Fairness Awareness: Belief-Guided Strategic Mechanism for Strategic Agents
Introduces partial fairness awareness (PFA) and a belief-guided mechanism allowing strategic agents to align beliefs with a hidden grounding fairness constraint via iterative interaction.
Reference graph
Works this paper leans on
-
[1]
DOI: https://doi.org/10.24432/C5N30T. Aha, D. Tic-Tac-Toe Endgame. UCI Machine Learning Repository, 1991. DOI: https://doi.org/10.24432/C5688J. Ahn, K., Cheng, X., Daneshmand, H., and Sra, S. Trans- formers learn to implement preconditioned gradient de- scent for in-context learning.Advances in Neural Infor- mation Processing Systems, 36:45614–45650, 2023...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.24432/c5n30t 1991
-
[2]
Strategic Classification from Revealed Preferences
URL https://api.semanticscholar. org/CorpusID:259849133. Chen, Y ., Liu, Y ., and Podimata, C. Learning strategy- aware linear classifiers.Advances in Neural Information Processing Systems, 33:15265–15276, 2020. Clore, J., Cios, K., DeShazo, J., and Strack, B. Diabetes 130-US Hospitals for Years 1999-2008. UCI Machine Learning Repository, 2014. DOI: https...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.24432/c5230j 2020
-
[3]
Concentration inequalities , PUBLISHER =
URL https://proceedings.mlr.press/ v139/ghalme21a.html. Gigerenzer, G.Simply Rational: Decision Mak- ing in the Real World. Oxford University Press, 03 2015. ISBN 9780199390076. doi: 10.1093/acprof:oso/9780199390076.001.0001. URL https://doi.org/10.1093/acprof: oso/9780199390076.001.0001. Gorishniy, Y ., Rubachev, I., Khrulkov, V ., and Babenko, A. Revisi...
work page doi:10.1093/acprof:oso/9780199390076.001.0001 2015
-
[4]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
URL https://proceedings.neurips. cc/paper_files/paper/2021/file/ f1404c2624fa7f2507ba04fd9dfc5fb1-Paper. pdf. Hazimeh, H., Ponomareva, N., Mol, P., Tan, Z., and Mazumder, R. The tree ensemble layer: Differentiability meets conditional computation. InInternational Con- ference on Machine Learning, pp. 4138–4148. PMLR, 2020. Helli, K., Schnurr, D., Hollmann...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.24432/c5nc77 2021
-
[5]
TabTransformer: Tabular Data Modeling Using Contextual Embeddings
DOI: https://doi.org/10.24432/C53G6X. Horowitz, G. and Rosenfeld, N. Causal strategic classifica- tion: A tale of two shifts. InInternational Conference on Machine Learning, pp. 13233–13253. PMLR, 2023. Huang, X., Khetan, A., Cvitkovic, M., and Karnin, Z. Tab- transformer: Tabular data modeling using contextual em- beddings.arXiv preprint arXiv:2012.06678...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.24432/c53g6x 2023
-
[6]
Strategic samples are generated using the current manipulation functionb f
-
[7]
The fine-tuning baseline retrains the classifier on the augmented datasetD f t
-
[8]
In contrast, the ICL-based method performs no parameter updates and adapts solely through changes in the in-context examples
The updated classifier is redeployed and evaluated. In contrast, the ICL-based method performs no parameter updates and adapts solely through changes in the in-context examples. D.4. Operational cost metrics We compare fine-tuning and ICL using two operational cost metrics. Update time cost.Update time cost measures the wall-clock time required to complet...
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.