OmniEgo-R²: A Routed Reasoning Framework for the 1st Cross-Domain EgoCross Challenge at CVPR 2026
Pith reviewed 2026-06-30 14:09 UTC · model grok-4.3
The pith
A five-component routed reasoning pipeline on Qwen3-VL backbones places second on the cross-domain EgoCross egocentric video challenge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
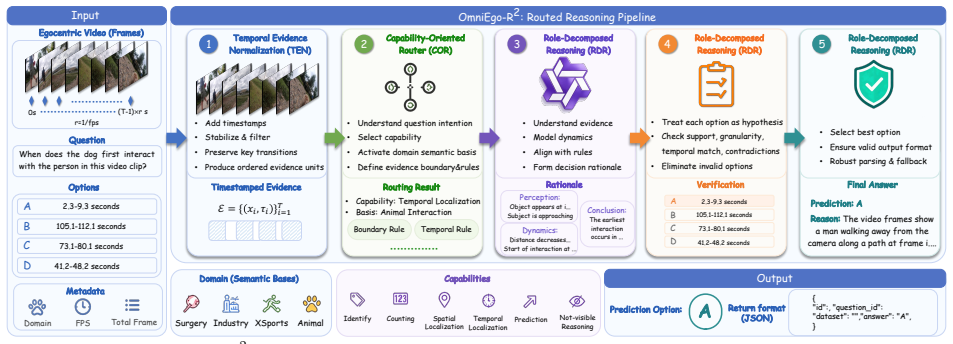
OmniEgo-R² solves cross-domain egocentric video reasoning by routing a Qwen3-VL-4B-SFT backbone through temporal-evidence normalization, domain-agnostic capability routing, structured perception-dynamics-decision reasoning, boundary-aware option verification, and defensive answer calibration, producing second-place accuracies of 66.35 percent and 66.77 percent on the Source-Limited and Open-Source leaderboards of the 1st EgoCross Challenge.
What carries the argument
The OmniEgo-R² routed reasoning pipeline, which sequences five lightweight programs around a vision-language backbone to manage temporal sparsity, domain shifts, and decision instability.
If this is right
- Temporal-evidence normalization reduces errors from state transitions that occur between sampled frames.
- Domain-agnostic routing lets one capability set serve surgery, industry, sports, and animal perspectives without per-domain retraining.
- Structured perception-dynamics-decision reasoning limits unsupported distractor selection in long multimodal chains.
- Boundary-aware verification and defensive calibration stabilize answers when options are semantically close.
- The same pipeline yields second place in both the Source-Limited and Open-Source tracks of the challenge.
Where Pith is reading between the lines
- The routing structure may transfer to other video benchmarks that cross visual domains without requiring new training data.
- Test-time programs of this kind could lower the cost of adapting general multimodal models to specialized embodied settings.
- If the capability router is kept domain-agnostic, the same skeleton might apply to non-video tasks that mix perception and sequential decision making.
- Measuring accuracy after ablating each of the five programs on the public challenge split would quantify their individual contributions.
Load-bearing premise
The five listed components are the main cause of the reported accuracies rather than the underlying Qwen3-VL checkpoints or competition-specific tuning.
What would settle it
An ablation that disables the routing, verification, and calibration programs while retaining the same base model and measures whether accuracy on the EgoCross test set drops below 60 percent.
Figures
read the original abstract
The 1st Cross-Domain EgoCross Challenge at EgoVis, CVPR 2026 evaluates whether multimodal large language models can reason over egocentric videos across surgery, industry, extreme sports, and animal perspective. We achieved second place in both the Source-Limited and Open-Source tracks. In this report, we formulate EgoCross as a robust cross-domain embodied video reasoning problem rather than a simple multiple-choice visual question answering task. We identify three key challenges: (C1) temporal boundary ambiguity, where critical state transitions are sparsely sampled and often occur between frames; (C2) cross-domain semantic granularity mismatch, where the same capability requires different domain-specific visual grammar; and (C3) decision instability under close options, where long multimodal reasoning can select unsupported distractors or produce malformed outputs. To address them, we propose OmniEgo-R$^2$ (Omnidomain Egocentric Routed Reasoning), a unified routed reasoning pipeline consisting of temporal-evidence normalization, domain-agnostic capability routing, structured perception--dynamics--decision reasoning, boundary-aware option verification, and defensive answer calibration. OmniEgo-R$^2$ uses the Qwen3-VL-4B-SFT checkpoints on each EgoCross domain as the visual-language backbone, and wraps them with lightweight test-time reasoning and parsing programs. Our final submissions obtain 66.35% overall accuracy in the Source-Limited track and 66.77% in the Open-Source track, ranking second in both leaderboards. The codes are available on https://github.com/Lee-zixu/OmniEgo-R2
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents OmniEgo-R², a routed reasoning framework for the 1st Cross-Domain EgoCross Challenge at CVPR 2026. It formulates the task as cross-domain embodied video reasoning, identifies three challenges (C1: temporal boundary ambiguity; C2: cross-domain semantic granularity mismatch; C3: decision instability under close options), and proposes five lightweight test-time components (temporal-evidence normalization, domain-agnostic capability routing, structured perception-dynamics-decision reasoning, boundary-aware option verification, defensive answer calibration) wrapped around Qwen3-VL-4B-SFT backbones. The work reports second-place leaderboard results of 66.35% overall accuracy in the Source-Limited track and 66.77% in the Open-Source track.
Significance. If the components' contributions can be isolated and validated, the framework offers a practical, modular approach to improving robustness in multimodal egocentric video reasoning across disparate domains such as surgery and extreme sports. The use of existing VL checkpoints with test-time wrappers is a pragmatic strength for competition settings, but the manuscript provides no internal evidence that the proposed elements drive the reported rankings beyond the base model.
major comments (2)
- [Method description and results paragraph] Method description (components list) and results paragraph: The central claim attributes the 66.35%/66.77% leaderboard placements and second-place rankings to the five proposed components addressing C1–C3. However, the manuscript contains no ablation studies, no base-model-only baseline on the EgoCross validation split, and no component-wise contribution analysis, leaving the attribution to the routed reasoning unsupported.
- [Challenges and component descriptions] Challenges (C1–C3) and component descriptions: No targeted metrics, qualitative examples, or controlled tests are supplied to show that temporal-evidence normalization mitigates boundary ambiguity, that domain-agnostic routing resolves granularity mismatch, or that boundary-aware verification and defensive calibration reduce decision instability.
minor comments (2)
- [Abstract] The abstract and introduction could explicitly note that the accuracy figures are external competition leaderboard scores rather than results from experiments conducted in the paper.
- [Conclusion] Code link is provided but no details on reproducibility (e.g., exact prompts or parsing scripts) are included in the text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on empirical validation. We address each major point below and will revise the manuscript accordingly to strengthen the evidence for component contributions.
read point-by-point responses
-
Referee: Method description (components list) and results paragraph: The central claim attributes the 66.35%/66.77% leaderboard placements and second-place rankings to the five proposed components addressing C1–C3. However, the manuscript contains no ablation studies, no base-model-only baseline on the EgoCross validation split, and no component-wise contribution analysis, leaving the attribution to the routed reasoning unsupported.
Authors: We agree that the absence of ablations leaves the attribution of gains to specific components less substantiated than ideal. As this is a competition report, the primary evidence is the final leaderboard performance achieved by the full system. We will add a base Qwen3-VL-4B-SFT baseline evaluated on the EgoCross validation split and a high-level component contribution discussion based on our development logs in the revised version. revision: yes
-
Referee: Challenges (C1–C3) and component descriptions: No targeted metrics, qualitative examples, or controlled tests are supplied to show that temporal-evidence normalization mitigates boundary ambiguity, that domain-agnostic routing resolves granularity mismatch, or that boundary-aware verification and defensive calibration reduce decision instability.
Authors: The challenges were derived from systematic error analysis during system development. While the manuscript focuses on the overall framework rather than per-component diagnostics, we will include qualitative examples and targeted error breakdowns illustrating the effect of temporal-evidence normalization, routing, and calibration in the revision. revision: yes
Circularity Check
No circularity: empirical competition report with no derivations or self-referential reductions
full rationale
The manuscript is a competition report describing a pipeline (temporal-evidence normalization, domain-agnostic routing, structured reasoning, verification, calibration) wrapped around Qwen3-VL-4B-SFT checkpoints. It reports external leaderboard accuracies (66.35% / 66.77%) without equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations. No step reduces by construction to its own definitions or prior author work; the results are independent competition outcomes rather than internally forced quantities.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 5 Pith papers
-
COMBINER: Composed Image Retrieval Guided by Attribute-based Neighbor Relations
COMBINER proposes a new architecture for composed image retrieval using adaptive semantic disentanglement, unified prototype-based composition, and dual attribute-based relation modeling to address visually similar bu...
-
R^3: Composed Video Retrieval via Reasoning-Guided Recalling and Re-ranking
R^3 is a zero-shot pipeline that generates reasoning traces to augment composed video queries, fuses scores via agreement-gated residual, and re-ranks candidates for the CoVR-R challenge.
-
RankVR: Low-Rank Structure Perception and Value Recalibration for Robust Composed Image Retrieval
RankVR introduces GSCP and ASVC modules to improve CIR robustness by decoupling clean samples via low-rank structure and dynamically scoring triplet value in noisy datasets.
-
IMAGINE: Adaptive Schema-Imagery Enhanced Composition for Composed Video Retrieval
IMAGINE uses adaptive schema-imagery via dynamic multimodal prototypes to incorporate implicit semantics into composed video retrieval, claiming SOTA results on CVR and CIR benchmarks.
-
EgoAction: Egocentric Action Composition with Reliability-Aware Temporal Fusion for the EPIC-KITCHENS Action Detection Challenge at CVPR 2026
EgoAction uses decoupled verb-noun temporal detectors on VideoMAE features and Dynamic Weighted Fusion of boundaries based on classification confidences for the EPIC-KITCHENS action detection challenge.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, et al. Qwen3-vl tech- nical report.arXiv preprint arXiv:2511.21631, 2025. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Offset: Segmentation-based focus shift revision for composed image retrieval
Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, Xuemeng Song, and Liqiang Nie. Offset: Segmentation-based focus shift revision for composed image retrieval. InACM MM, page 6113–6122, 2025
2025
-
[3]
Pair: Complementarity-guided disentanglement for composed im- age retrieval
Zhiheng Fu, Zixu Li, Zhiwei Chen, Chunxiao Wang, Xuemeng Song, Yupeng Hu, and Liqiang Nie. Pair: Complementarity-guided disentanglement for composed im- age retrieval. InICASSP, pages 1–5. IEEE, 2025
2025
-
[4]
Encoder: Entity mining and modifica- tion relation binding for composed image retrieval
Zixu Li, Zhiwei Chen, Haokun Wen, Zhiheng Fu, Yupeng Hu, and Weili Guan. Encoder: Entity mining and modifica- tion relation binding for composed image retrieval. InAAAI, pages 5101–5109, 2025. 1
2025
-
[5]
Egovqa-an egocentric video question answer- ing benchmark dataset
Chenyou Fan. Egovqa-an egocentric video question answer- ing benchmark dataset. InICCVW, pages 0–0, 2019. 1
2019
-
[6]
Egoschema: A diagnostic benchmark for very long-form video language understand- ing.NeurIPS, 36:46212–46244, 2023
Karttikeya Mangalam et al. Egoschema: A diagnostic benchmark for very long-form video language understand- ing.NeurIPS, 36:46212–46244, 2023
2023
-
[7]
Egovlpv2: Egocentric video- language pre-training with fusion in the backbone
Shraman Pramanick et al. Egovlpv2: Egocentric video- language pre-training with fusion in the backbone. InICCV, pages 5285–5297, 2023. 4
2023
-
[8]
EgoAdapt: A Multi-Scene Egocentric Adaptation Method for CVPR 2026 HD-EPIC VQA Challenge
Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, Guozhi Qiu, Weili Guan, and Liqiang Nie. Egoadapt: A multi-scene ego- centric adaptation method for cvpr 2026 hd-epic vqa chal- lenge.arXiv preprint arXiv:2605.24500, 2026. 1
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Air-Know: Arbiter-Calibrated Knowledge-Internalizing Robust Network for Composed Image Retrieval
Zhiheng Fu, Yupeng Hu, Qianyun Yang, Shiqi Zhang, Zhi- wei Chen, and Zixu Li. Air-know: Arbiter-calibrated knowledge-internalizing robust network for composed image retrieval.arXiv preprint arXiv:2604.19386, 2026. 1
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
ConeSep: Cone-based Robust Noise-Unlearning Compositional Network for Composed Image Retrieval
Zixu Li, Yupeng Hu, Zhiwei Chen, Mingyu Zhang, Zhiheng Fu, and Liqiang Nie. Conesep: Cone-based robust noise- unlearning compositional network for composed image re- trieval.arXiv preprint arXiv:2604.20358, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Median: Adaptive intermediate-grained aggregation network for composed im- age retrieval
Qinlei Huang, Zhiwei Chen, Zixu Li, Chunxiao Wang, Xue- meng Song, Yupeng Hu, and Liqiang Nie. Median: Adaptive intermediate-grained aggregation network for composed im- age retrieval. InICASSP, pages 1–5. IEEE, 2025
2025
-
[12]
Erase: Bypassing collaborative detection of ai counterfeit via com- prehensive artifacts elimination.IEEE TDSC, pages 1–18,
Qianyun Yang, Peizhuo Lv, Yingjiu Li, Shengzhi Zhang, Yuxuan Chen, Zhiwei Chen, Zixu Li, and Yupeng Hu. Erase: Bypassing collaborative detection of ai counterfeit via com- prehensive artifacts elimination.IEEE TDSC, pages 1–18,
-
[13]
Egolife: Towards egocentric life assis- tant
Jingkang Yang et al. Egolife: Towards egocentric life assis- tant. InCVPR, pages 28885–28900, 2025. 1, 4
2025
-
[14]
Egothink: Evaluating first-person perspec- tive thinking capability of vision-language models
Sijie Cheng et al. Egothink: Evaluating first-person perspec- tive thinking capability of vision-language models. InCVPR, pages 14291–14302, 2024. 1
2024
-
[15]
Ego- textvqa: Towards egocentric scene-text aware video question answering
Sheng Zhou, Junbin Xiao, Qingyun Li, Yicong Li, et al. Ego- textvqa: Towards egocentric scene-text aware video question answering. InCVPR, pages 3363–3373, 2025. 1
2025
-
[16]
Egocross: Benchmarking multimodal large language mod- els for cross-domain egocentric video question answering
Yanjun Li, Yuqian Fu, Tianwen Qian, Qi’Ao Xu, et al. Egocross: Benchmarking multimodal large language mod- els for cross-domain egocentric video question answering. InAAAI, pages 6592–6600, 2026. 1, 2, 4, 5
2026
-
[17]
Zixu Li, Zhiheng Fu, Yupeng Hu, Zhiwei Chen, Haokun Wen, and Liqiang Nie. Finecir: Explicit parsing of fine- grained modification semantics for composed image re- trieval.https://arxiv.org/abs/2503.21309, 2025. 1
-
[18]
Shuai Bai, Keqin Chen, Xuejing Liu, et al. Qwen2.5-vl tech- nical report.arXiv preprint arXiv:2502.13923, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Hint: Com- posed image retrieval with dual-path compositional contex- tualized network
Mingyu Zhang, Zixu Li, Zhiwei Chen, Zhiheng Fu, Xiaowei Zhu, Jiajia Nie, Yinwei Wei, and Yupeng Hu. Hint: Com- posed image retrieval with dual-path compositional contex- tualized network. InICASSP, pages 13002–13006. IEEE, 2026
2026
-
[20]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, et al. Qwen-vl: A versatile vision- language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, et al. In- ternvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
TEMA: Anchor the Image, Follow the Text for Multi-Modification Composed Image Retrieval
Zixu Li, Yupeng Hu, Zhiheng Fu, Zhiwei Chen, Yongqi Li, and Liqiang Nie. Tema: Anchor the image, follow the text for multi-modification composed image retrieval.arXiv preprint arXiv:2604.21806, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Melt: Improve com- posed image retrieval via the modification frequentation- rarity balance network
Guozhi Qiu, Zhiwei Chen, Zixu Li, Qinlei Huang, Zhiheng Fu, Xuemeng Song, and Yupeng Hu. Melt: Improve com- posed image retrieval via the modification frequentation- rarity balance network. InICASSP, pages 13007–13011. IEEE, 2026. 1
2026
-
[24]
Retrack: Evidence-driven dual-stream directional anchor calibration network for com- posed video retrieval
Zixu Li, Yupeng Hu, Zhiwei Chen, Qinlei Huang, Guozhi Qiu, Zhiheng Fu, and Meng Liu. Retrack: Evidence-driven dual-stream directional anchor calibration network for com- posed video retrieval. InAAAI, pages 23373–23381, 2026. 1
2026
-
[25]
Hud: Hierarchical uncertainty-aware disambiguation network for composed video retrieval
Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, Haokun Wen, and Weili Guan. Hud: Hierarchical uncertainty-aware disambiguation network for composed video retrieval. In ACM MM, page 6143–6152, 2025
2025
-
[26]
Refine: Composed video retrieval via shared and differential semantics enhancement
Yupeng Hu, Zixu Li, Zhiwei Chen, Qinlei Huang, Zhiheng Fu, Mingzhu Xu, and Liqiang Nie. Refine: Composed video retrieval via shared and differential semantics enhancement. ACM ToMM, 2026. 1
2026
-
[27]
Stable: Efficient hybrid nearest neighbor search via magnitude-uniformity and cardinality- robustness.IEEE TKDE, 2026
Qianyun Yang, Zhiwei Chen, Yupeng Hu, Zixu Li, Zhi- heng Fu, and Liqiang Nie. Stable: Efficient hybrid nearest neighbor search via magnitude-uniformity and cardinality- robustness.IEEE TKDE, 2026. 1
2026
-
[28]
Josh Achiam, Steven Adler, Sandhini Agarwal, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Intent: Invariance and discrimination-aware noise mitigation for robust composed image retrieval
Zhiwei Chen, Yupeng Hu, Zhiheng Fu, Zixu Li, Jiale Huang, Qinlei Huang, and Yinwei Wei. Intent: Invariance and discrimination-aware noise mitigation for robust composed image retrieval. InAAAI, pages 20463–20471, 2026
2026
-
[30]
Habit: Chrono- synergia robust progressive learning framework for com- posed image retrieval
Zixu Li, Yupeng Hu, Zhiwei Chen, Shiqi Zhang, Qinlei Huang, Zhiheng Fu, and Yinwei Wei. Habit: Chrono- synergia robust progressive learning framework for com- posed image retrieval. InAAAI, pages 6762–6770, 2026
2026
-
[31]
Zixu Li, Yupeng Hu, Zhiwei Chen, Zhiheng Fu, Xiaowei Zhu, Weili Guan, and Liqiang Nie. Tempret: Tempo- ral enhancement and two-stage reranking for cvpr 2026 epic-kitchens-100 multi-instance retrieval challenge.arXiv preprint arXiv:2605.24470, 2026. 1
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Gheorghe Comanici et al. Gemini 2.5: Pushing the fron- tier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, et al. Videollama 3: Frontier multimodal foundation models for image and video understanding.arXiv preprint arXiv:2501.13106, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.