StepOPSD: Step-Aware Online Preference Distillation for Agent Reinforcement Learning
Pith reviewed 2026-06-29 17:11 UTC · model grok-4.3
The pith
Step-aware preference distillation addresses credit assignment in multi-turn agent RL by treating steps as causal units.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
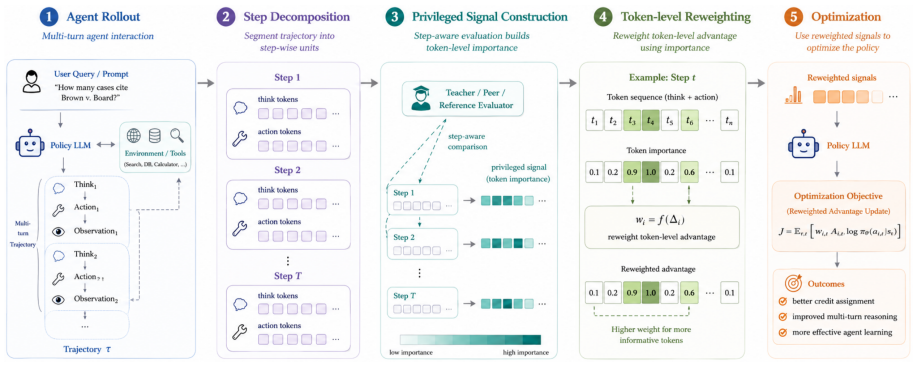
By decomposing trajectories into action-centered step segments, rescoring them under hindsight-enriched teacher contexts, and converting log-probability gaps into sign-preserving advantage shaping with a normalized per-step credit budget, StepOPSD enables more accurate credit assignment before the GRPO update.
What carries the argument
Action-centered step segments that serve as the unit for converting token-level log-probability gaps into normalized advantage signals.
If this is right
- Best or second-best performance on subsets most sensitive to local causal errors in ALFWorld and Search-QA.
- First-place on ALFWorld Heat at 79.1% and PickTwo at 95.0%.
- 61.6% on Search-QA TriviaQA and 40.4% tied-best on HotpotQA.
- A consistent two-knob law for alpha_clip as stabilizing trust region and lambda_mix as task-dependent.
- Step-aware distillation is most useful when trajectory rewards are weakly aligned with the determining local action.
Where Pith is reading between the lines
- This step decomposition approach could extend to other multi-turn decision making problems where sparse rewards hinder learning.
- Comparing the method directly to dense reward baselines would clarify if it reduces the need for reward engineering.
- The two-knob law suggests hyperparameter search can be simplified in similar distillation setups.
Load-bearing premise
That rescoring action-centered step segments under hindsight-enriched teacher contexts produces unbiased sign-preserving advantage signals that correctly reflect local causal contributions to downstream success.
What would settle it
Running the method on a task where local decisions have no causal impact on final success and observing continued performance gains would falsify the claim that the advantage signals reflect local contributions.
Figures

read the original abstract
Reinforcement learning for multi-turn agents suffers from a credit-assignment mismatch: rewards are sparse and trajectory-level, while success often hinges on a few local decisions. Existing online policy distillation (OPD) provides denser token-level supervision, but typically treats heterogeneous agent trajectories as monolithic strings rather than causal interaction units. We present StepOPSD, a post-rollout preference self-distillation framework that takes the agent step as the unit of credit redistribution. StepOPSD decomposes trajectories into action-centered step segments, rescoring them under hindsight-enriched teacher contexts and converting token-level log-probability gaps into sign-preserving advantage shaping with a normalized per-step credit budget before the GRPO update. Across ALFWorld and Search-QA with Qwen3-1.7B and Qwen2.5-3B-Instruct, StepOPSD attains best or second-best results on subsets most sensitive to local causal errors, including first-place performance on ALFWorld Heat (79.1%), PickTwo (95.0%), Search-QA TriviaQA (61.6%), and tied-best performance on HotpotQA (40.4%). The results further reveal a consistent two-knob law: smaller {\alpha}_clip acts as a broadly stabilizing local trust region, whereas the optimal global mixing strength {\lambda}_mix remains task-dependent. These findings suggest that step-aware distillation is most useful when trajectory-level rewards are weakly aligned with the local action that determines downstream success.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes StepOPSD, a post-rollout preference self-distillation method for multi-turn agent RL that decomposes trajectories into action-centered step segments, rescoring them under hindsight-enriched teacher contexts to convert token-level log-probability gaps into sign-preserving advantage signals (with normalized per-step credit budget) for GRPO updates. It reports best or second-best results on ALFWorld and Search-QA subsets sensitive to local errors (e.g., 79.1% on ALFWorld Heat, 95.0% on PickTwo, 61.6% on TriviaQA) with Qwen models, and identifies a two-knob law where smaller alpha_clip stabilizes locally while lambda_mix is task-dependent.
Significance. If the hindsight-rescoring step produces unbiased local causal advantage signals, StepOPSD would offer a concrete mechanism for denser, step-level credit assignment in sparse-reward agent settings where trajectory rewards misalign with key local decisions. The reported subset-specific gains and hyperparameter observations would then constitute a useful empirical contribution to online policy distillation methods.
major comments (2)
- [Abstract] Abstract: the central claim that rescoring action-centered step segments under hindsight-enriched teacher contexts yields 'sign-preserving advantage signals that correctly reflect local causal contributions' is load-bearing yet unsupported. Hindsight enrichment supplies downstream outcome information unavailable to the agent at decision time; the manuscript provides no analysis, ablation, or proof that the normalized per-step credit budget, sign preservation, or alpha_clip/lambda_mix knobs cancel the resulting non-causal component.
- [Abstract] Abstract (and reported results): benchmark wins are stated without error bars, full method details, data exclusion rules, or verification that results support the causal credit-assignment claim. This directly weakens the assertion that gains on ALFWorld Heat/PickTwo and Search-QA subsets arise from improved local assignment rather than post-hoc evaluation artifacts.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed report. The two major comments both center on strengthening the support for the causal credit-assignment claim and on improving the transparency of the reported results. We agree that both points require additional material and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that rescoring action-centered step segments under hindsight-enriched teacher contexts yields 'sign-preserving advantage signals that correctly reflect local causal contributions' is load-bearing yet unsupported. Hindsight enrichment supplies downstream outcome information unavailable to the agent at decision time; the manuscript provides no analysis, ablation, or proof that the normalized per-step credit budget, sign preservation, or alpha_clip/lambda_mix knobs cancel the resulting non-causal component.
Authors: We acknowledge that the abstract statement is strong and that the current manuscript does not contain an explicit analysis or ablation isolating the non-causal component introduced by hindsight. The method intentionally uses hindsight-enriched teacher contexts so that the teacher can judge whether a local action contributed to eventual success; sign preservation and the normalized per-step budget are intended to keep the resulting signal conservative. Nevertheless, without dedicated experiments the claim remains insufficiently supported. In the revision we will add a new subsection containing (i) an ablation that compares hindsight-rescoring against a no-hindsight baseline on the same trajectories and (ii) a short theoretical note explaining why the combination of sign preservation and per-step normalization limits leakage of future information into the advantage estimate. revision: yes
-
Referee: [Abstract] Abstract (and reported results): benchmark wins are stated without error bars, full method details, data exclusion rules, or verification that results support the causal credit-assignment claim. This directly weakens the assertion that gains on ALFWorld Heat/PickTwo and Search-QA subsets arise from improved local assignment rather than post-hoc evaluation artifacts.
Authors: We agree that the absence of error bars, explicit data-exclusion criteria, and direct verification weakens the causal interpretation. The reported figures are from the experimental protocol described in Section 4; no trajectories were excluded beyond the standard environment filters. In the revision we will (i) report means and standard deviations over three random seeds for all main results, (ii) add a short paragraph on data handling, and (iii) include a new experiment that correlates the magnitude of the per-step advantage signals with downstream success rate on the same subsets, thereby providing direct empirical support for the local-assignment hypothesis. revision: yes
Circularity Check
No significant circularity detected; empirical results and observations stand independently
full rationale
The paper defines StepOPSD as a post-rollout framework that decomposes trajectories into action-centered segments, applies hindsight-enriched rescoring, converts log-prob gaps to sign-preserving advantages with normalized credit budget, then feeds into GRPO. Performance claims are tied directly to benchmark outcomes on ALFWorld and Search-QA subsets. The two-knob law is explicitly described as an empirical observation ('the results further reveal') from those runs rather than a derived prediction or fitted input renamed as independent. No equations or steps reduce by construction to inputs, no load-bearing self-citations are invoked for uniqueness or ansatz, and the method description does not exhibit self-definitional loops. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- alpha_clip
- lambda_mix
Forward citations
Cited by 1 Pith paper
-
UCOB: Learning to Utilize and Evolve Agentic Skills via Credit-Aware On-Policy Bidirectional Self-Distillation
UCOB improves agentic RL by using return-to-go comparisons between skill-conditioned and no-skill prompts as local teachers for bidirectional self-distillation and skill memory updates.
Reference graph
Works this paper leans on
-
[1]
Privileged Information Distillation for Language Models
Policy invariance under reward transforma- tions: Theory and application to reward shaping. In Proceedings of the Sixteenth International Confer- ence on Machine Learning, pages 278–287. Morgan Kaufmann. Emiliano Penaloza, Dheeraj Vattikonda, Nicolas Gon- tier, Alexandre Lacoste, Laurent Charlin, and Massimo Caccia. 2026. Privileged informa- tion distilla...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Direct preference optimization: Your language model is secretly a reward model.arXiv preprint arXiv:2305.18290. Andrei A. Rusu, Sergio Gomez Colmenarejo, Caglar Gulcehre, Guillaume Desjardins, James Kirk- patrick, Razvan Pascanu, V olodymyr Mnih, Koray Kavukcuoglu, and Raia Hadsell. 2015. Policy distil- lation.arXiv preprint arXiv:1511.06295. Timo Schick,...
work page internal anchor Pith review Pith/arXiv arXiv 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.