A Unified Framework for the Evaluation of LLM Agentic Capabilities
Pith reviewed 2026-06-29 13:12 UTC · model grok-4.3
The pith
A unified framework standardizes LLM agent benchmarks to separate model capabilities from scaffold and environment effects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
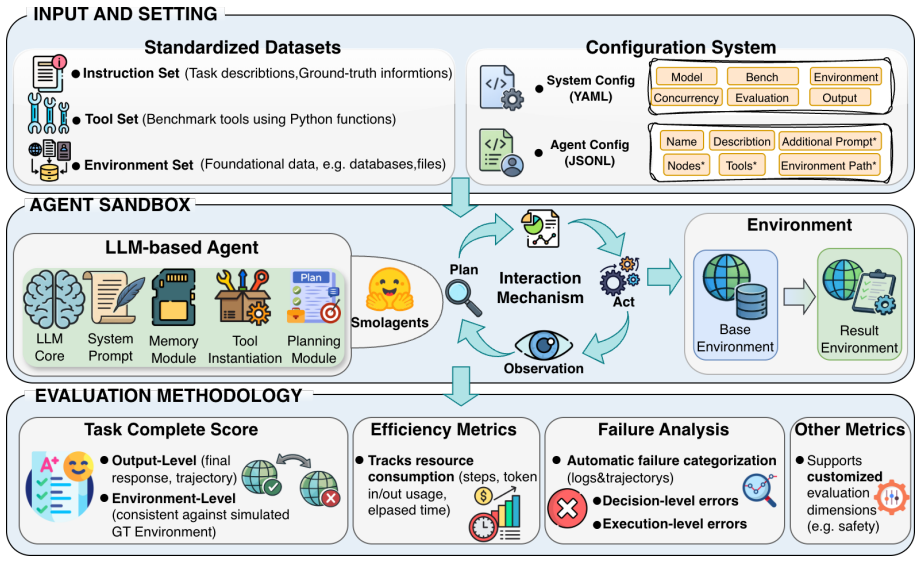
By placing benchmarks into a standardized format, executing agents via a single ReAct-style architecture in a sandbox, and offering an offline snapshot option, the framework shows that scaffold choice and environmental volatility materially shift benchmark outcomes in both directions and thereby disentangles intrinsic LLM capabilities from framework- and environment-induced artifacts.
What carries the argument
The unified configuration system that converts benchmarks into a standardized instruction-tool-environment format and executes them via a fixed ReAct-style architecture inside a controllable sandbox.
If this is right
- Benchmark outcomes on the same models vary substantially when the scaffold is altered.
- Switching between live environments and curated snapshots changes results in both directions.
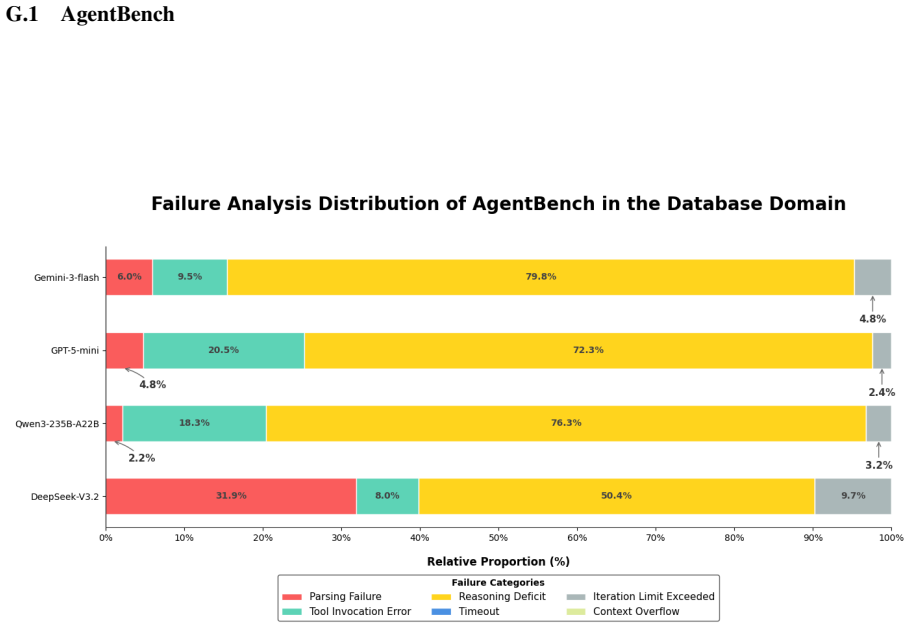
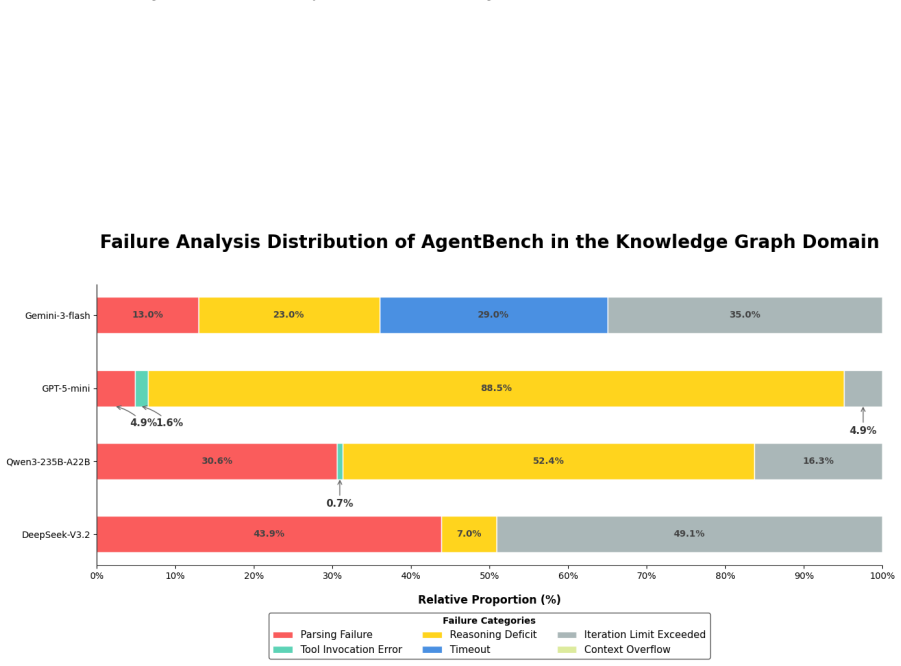
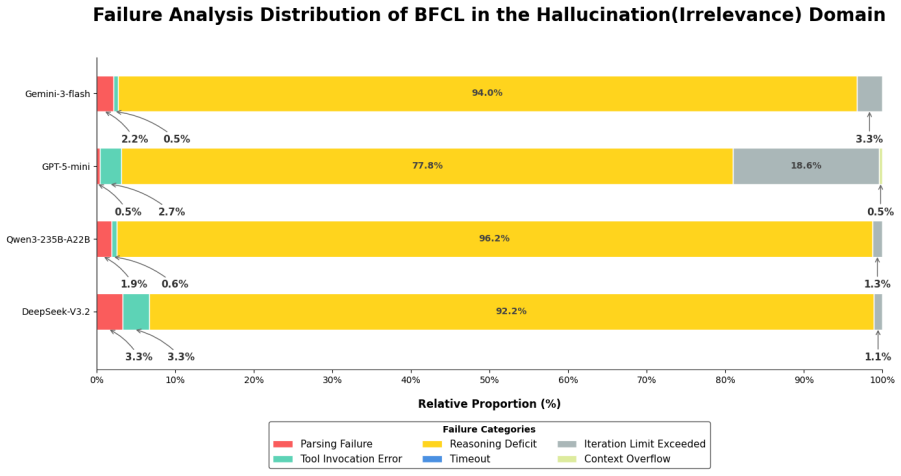
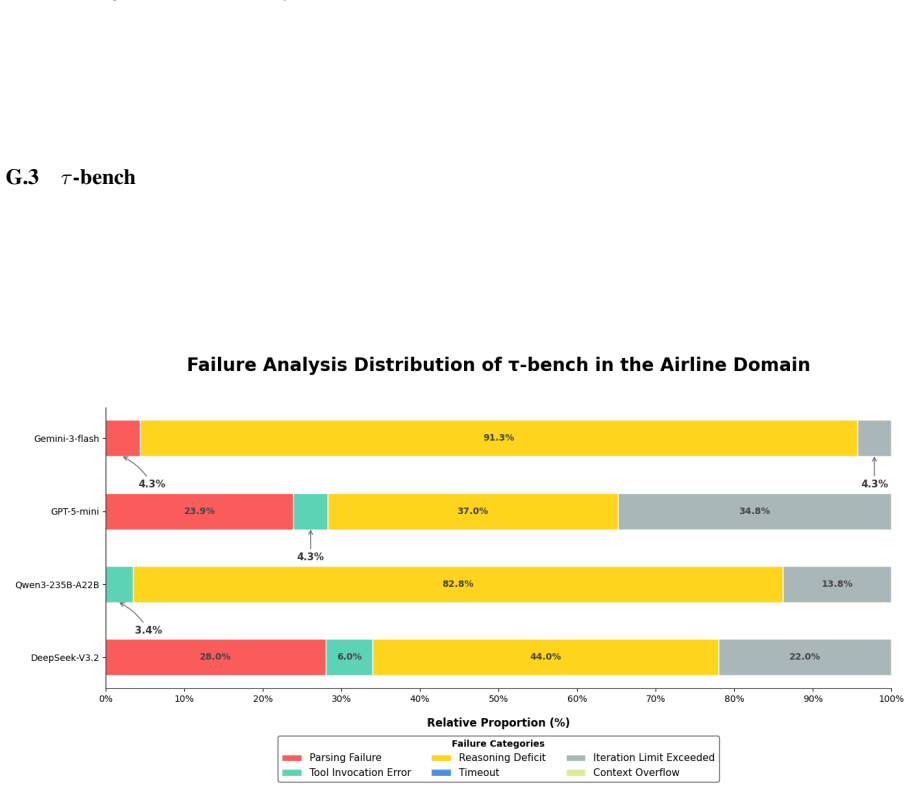
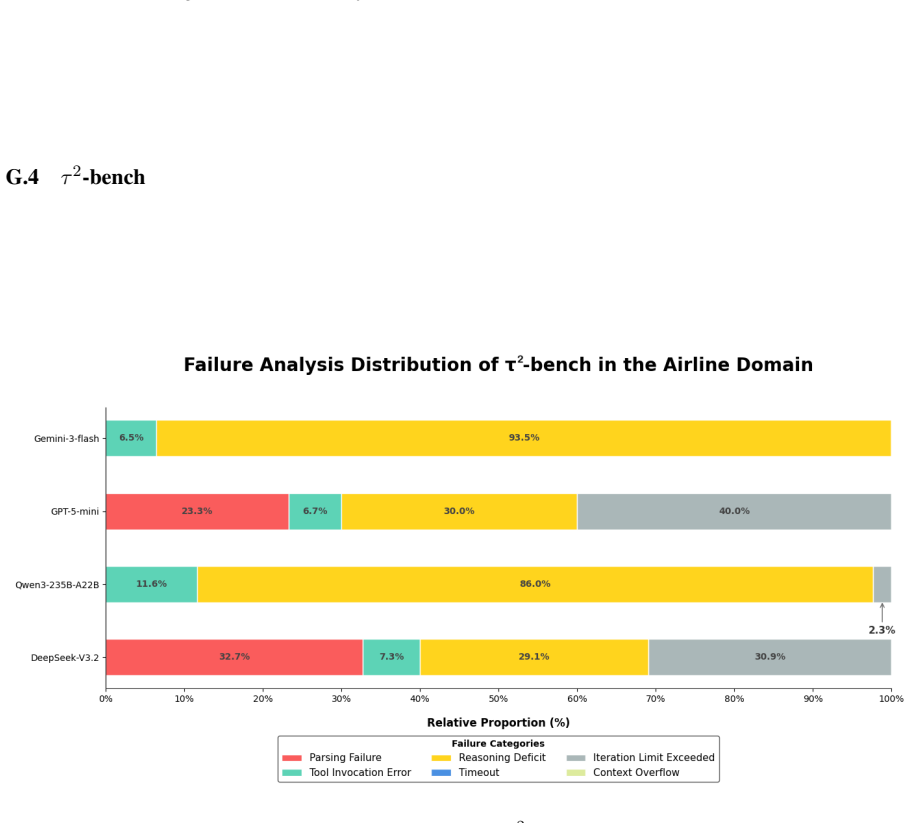
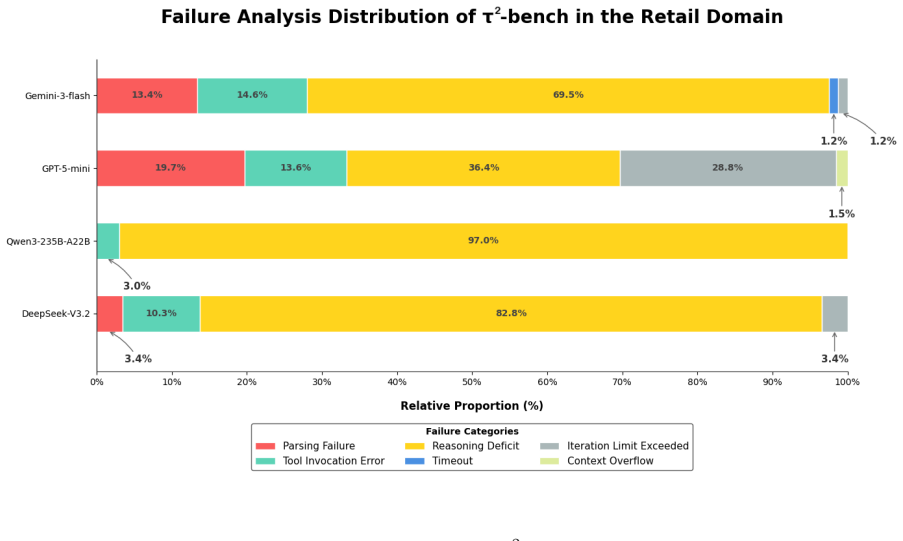
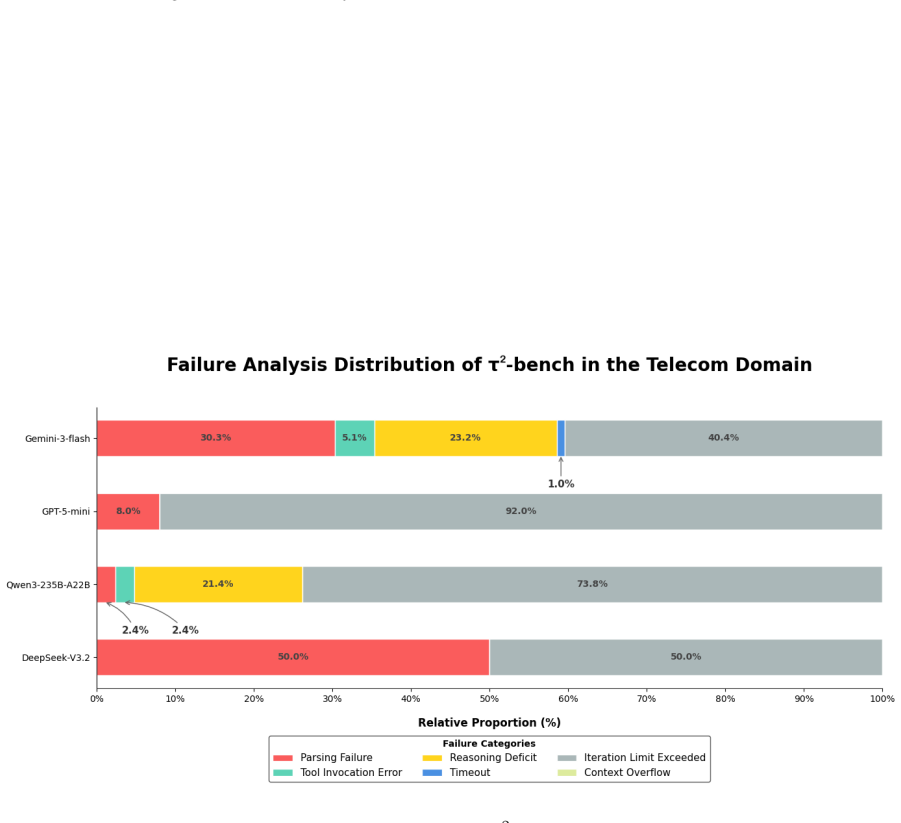
- Unified metrics for resource consumption and a decision- and execution-level failure taxonomy apply across originally separate benchmarks.
- The framework can serve as a secure testbed for safety-critical agent scenarios.
- Cross-benchmark comparisons become interpretable as measurements of underlying model capabilities rather than joint model-plus-implementation effects.
Where Pith is reading between the lines
- Leaderboards built on this framework could produce more stable model rankings over successive releases.
- Researchers could adopt the offline snapshots to lower evaluation cost and variance without losing the ability to study volatility effects.
- Models whose performance is highly scaffold-dependent could be flagged for further targeted study.
- The failure taxonomy could be extended to additional error categories to diagnose specific capability gaps.
Load-bearing premise
That running all agents through one fixed ReAct-style architecture inside the standardized format provides a neutral measurement of the underlying LLM without introducing its own systematic biases or limitations on what capabilities can be expressed.
What would settle it
A replication study in which changing the scaffold or switching between live and snapshot environments produces no material difference in outcomes across the same models and tasks would falsify the claim that these factors shift benchmark results.
Figures




















read the original abstract
As LLMs are increasingly deployed as agents, reliable assessment of their agentic capabilities has become essential. However, reported benchmark scores often jointly reflect model capability and the implementation choices each benchmark is packaged with, making cross-benchmark results difficult to interpret as clean measurements of the underlying model. In this work, we present a unified framework for the fair evaluation of LLM agentic capabilities. Driven by a unified configuration system, the framework integrates diverse benchmarks into a standardized instruction-tool-environment format, executes agents through a fixed ReAct-style architecture within a controllable sandbox, and provides an optional offline setting that replaces volatile live environments with curated snapshots, so that framework effects and environment effects can be analyzed separately. Building on this, we unify the evaluation methodology under each benchmark's original task-success criteria, while introducing unified metrics for resource consumption and a taxonomy for decision- and execution-level failure attribution. Within this framework, we adapt 7 widely used benchmarks spanning 24 domains across single-agent, multi-agent, and safety-critical scenarios, and conduct a large-scale empirical analysis over 400K rollouts and 5B tokens on 15 models. The results show that scaffold choice and environmental volatility materially shift benchmark outcomes in both directions, allowing our framework to disentangle intrinsic LLM capabilities from framework- and environment-induced artifacts. We further demonstrate its extensibility as a secure testbed for safety-critical domains. Codes and benchmarks at are available at https://github.com/whfeLingYu/A-Unified-Framework-for-the-Evaluation-of-LLM-Agentic-Capabilities, https://huggingface.co/datasets/whfeLingYu/Unified_Agent_Framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a unified framework for evaluating LLM agentic capabilities. It standardizes diverse benchmarks into a common instruction-tool-environment format, executes agents via a fixed ReAct-style architecture inside a controllable sandbox (with an optional offline mode using curated snapshots to isolate environment volatility), unifies evaluation under each benchmark's original task-success criteria, and adds metrics for resource consumption plus a taxonomy for decision- and execution-level failure attribution. The framework is applied to 7 benchmarks spanning 24 domains (single-agent, multi-agent, and safety-critical), with large-scale experiments involving 400K rollouts and 5B tokens across 15 models; results indicate that scaffold choice and environmental volatility shift outcomes in both directions, purportedly enabling disentanglement of intrinsic LLM capabilities from framework- and environment-induced artifacts. Code and adapted benchmarks are released publicly.
Significance. If the disentanglement claim holds after addressing the noted concerns, the work would be significant for LLM agent evaluation by providing a controlled testbed that separates model-intrinsic factors from implementation and environment confounds, a persistent issue in the field. The scale of the empirical study, public code release, and demonstrated extensibility to safety-critical domains are concrete strengths that enhance reproducibility and potential adoption.
major comments (2)
- [Abstract] Abstract: The headline claim that the framework disentangles intrinsic LLM capabilities from framework-induced artifacts rests on the assumption that the fixed ReAct-style execution loop provides a neutral measurement. No evidence is presented that this architecture does not impose systematic ceilings or biases (e.g., on capabilities requiring non-observe-think-act planning or memory patterns), which would make the unified measurements specific to ReAct rather than intrinsic.
- [Abstract] Abstract: While the manuscript reports that scaffold choice shifts outcomes (supporting analysis of framework effects), the primary unified measurements and 400K-rollout results are obtained under the single fixed ReAct-style architecture; the disentanglement interpretation therefore requires explicit justification or additional controls showing that ReAct does not differentially suppress capabilities across the 15 models relative to the broader space of agent scaffolds.
minor comments (2)
- [Abstract] Typo in the provided Hugging Face link: 'Unified_Farmework' should read 'Unified_Framework'.
- The taxonomy for decision- and execution-level failure attribution is introduced but would benefit from a concrete example of how attributions are assigned in practice under the unified metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and the disentanglement claim. The points raised are substantive and we respond to each below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that the framework disentangles intrinsic LLM capabilities from framework-induced artifacts rests on the assumption that the fixed ReAct-style execution loop provides a neutral measurement. No evidence is presented that this architecture does not impose systematic ceilings or biases (e.g., on capabilities requiring non-observe-think-act planning or memory patterns), which would make the unified measurements specific to ReAct rather than intrinsic.
Authors: We agree that the fixed ReAct-style execution loop may introduce systematic biases or ceilings for capabilities outside the observe-think-act pattern, and the manuscript presents no direct evidence that ReAct is neutral across all agentic behaviors. The framework was designed to be scaffold-agnostic, and we already include experiments demonstrating that scaffold choice shifts outcomes. We will revise the abstract and add a dedicated limitations paragraph to clarify that the primary measurements are obtained under a standardized ReAct-style scaffold, that the reported disentanglement applies to environment volatility while holding the scaffold fixed, and that the framework supports substitution of other scaffolds. These changes will be made in the revision. revision: yes
-
Referee: [Abstract] Abstract: While the manuscript reports that scaffold choice shifts outcomes (supporting analysis of framework effects), the primary unified measurements and 400K-rollout results are obtained under the single fixed ReAct-style architecture; the disentanglement interpretation therefore requires explicit justification or additional controls showing that ReAct does not differentially suppress capabilities across the 15 models relative to the broader space of agent scaffolds.
Authors: The 400K-rollout results use a single fixed ReAct-style architecture to maintain a consistent protocol across 7 benchmarks and 15 models. Separate experiments already quantify the effect of scaffold variation. We acknowledge that these experiments do not fully demonstrate the absence of differential suppression across models. In the revision we will add explicit text in the abstract and discussion sections stating that the current disentanglement isolates environment effects under a fixed scaffold, that scaffold-induced variation is reported separately, and that users of the framework can substitute alternative scaffolds for further controls. No new large-scale runs are planned for this revision, but the added discussion will qualify the interpretation accordingly. revision: yes
Circularity Check
No circularity: framework and metrics defined independently; empirical results from external benchmarks.
full rationale
The paper introduces a configuration-driven standardization of existing benchmarks into an instruction-tool-environment format, executes them via a fixed ReAct-style loop, and reports outcomes under original task-success criteria plus new resource and failure metrics. These steps are definitional and do not reduce any reported effect (scaffold or volatility shifts) to a fitted parameter or self-citation chain. All quantitative claims derive from 400K rollouts on 15 models across 7 external benchmarks; no equations equate predictions to inputs by construction, and no load-bearing uniqueness theorems or ansatzes are invoked from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A fixed ReAct-style architecture provides a neutral and representative execution substrate for comparing underlying LLM capabilities across benchmarks.
invented entities (1)
-
Taxonomy for decision- and execution-level failure attribution
no independent evidence
Forward citations
Cited by 1 Pith paper
-
EPC: A Standardized Protocol for Measuring Evaluator Preference Dynamics in LLM Agent Systems
The paper specifies the EPC protocol for measuring evaluator preference coupling and releases a time-bound reference snapshot of measurements across multiple LLM evaluators.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.