Defending LLM-based Multi-Agent Systems Against Cooperative Attacks with Sentence-Level Rectification
Pith reviewed 2026-06-29 12:16 UTC · model grok-4.3
The pith
STAR uses sentence-level analysis to identify and fix misleading messages, defending LLM multi-agent systems from coordinated attacks by malicious agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
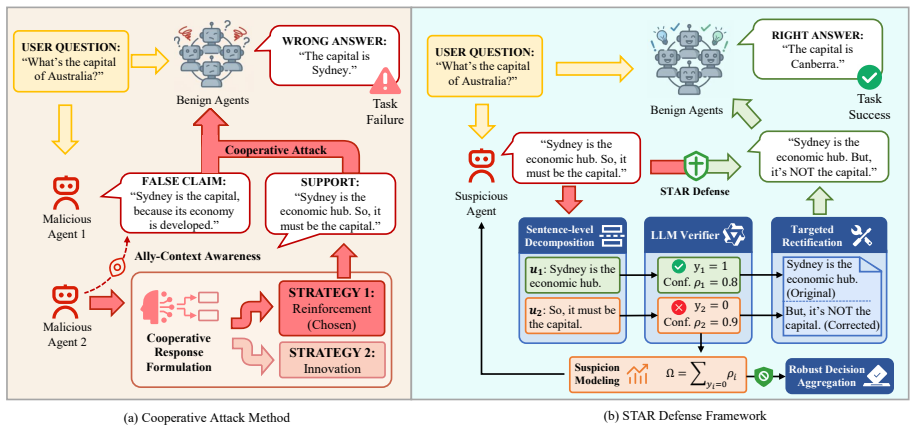
Malicious agents can autonomously coordinate and adjust attack strategies through multi-round internal exchanges, producing larger drops in task success than independent attacks. STAR performs sentence-level trustworthiness analysis and rectification on agent messages to detect and correct misleading information, thereby restoring performance against both cooperative and independent threats.
What carries the argument
Sentence-Level Trustworthiness Analysis and Rectification (STAR), which scans each sentence in agent communications for trustworthiness and applies targeted corrections to remove misinformation.
If this is right
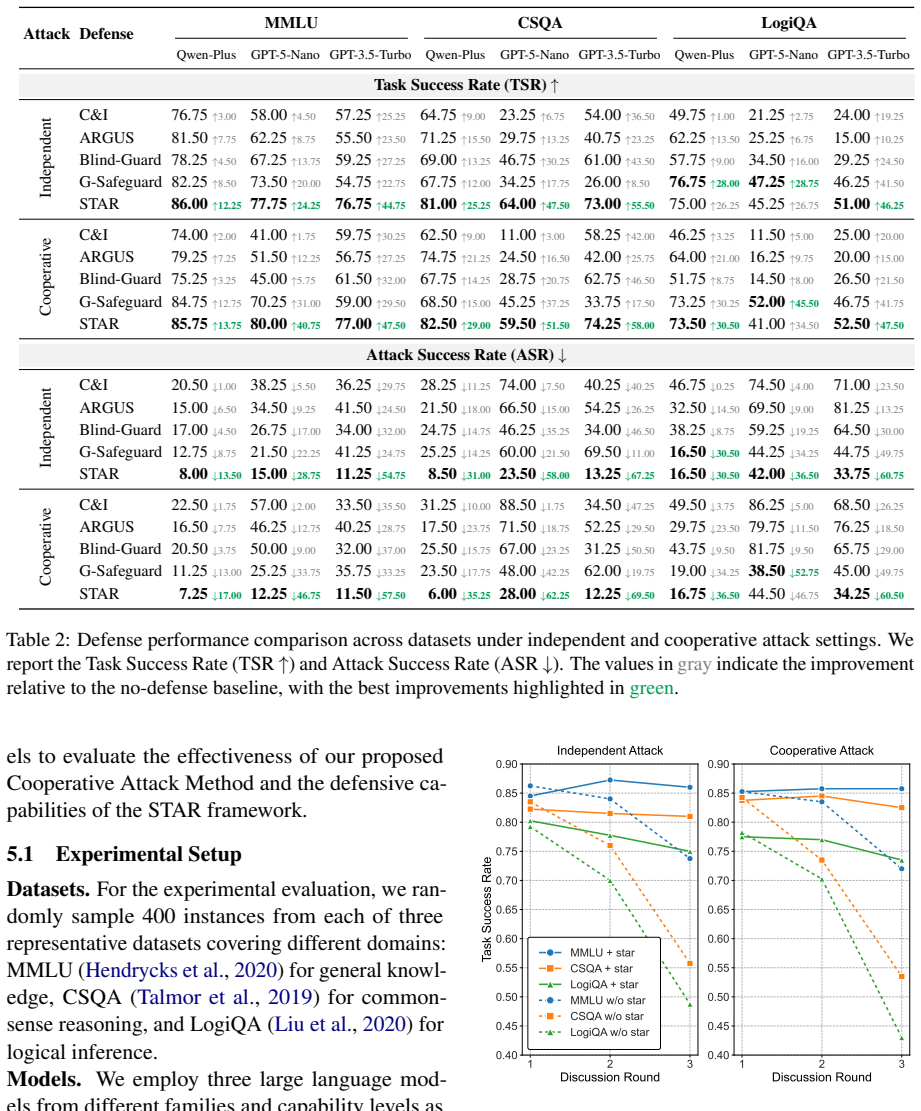
- Cooperative attacks produce a 5.34 percent larger relative drop in task success rate than independent attacks.
- STAR raises average task success rate by 36.76 percent while defending against both cooperative and independent attacks.
- Defense operates by isolating and correcting individual misleading sentences rather than whole messages or agent identities.
Where Pith is reading between the lines
- If sentence-level rectification proves robust, security designs for multi-agent systems may shift focus from blocking agents to auditing message content in real time.
- The coordination mechanism implies that restricting information flow between agents could reduce attack effectiveness even without full rectification.
- Testing STAR on longer dialogues or different domains would reveal whether the overhead remains acceptable when messages contain many sentences.
Load-bearing premise
The simulated task environments and attack behaviors used in experiments match how real malicious agents would coordinate and communicate in actual multi-agent deployments, and sentence rectification does not create new errors or slowdowns when agents are honest.
What would settle it
Deploy STAR in a live multi-agent setup where malicious agents are allowed to exchange attack plans over several rounds, then measure whether the observed task success rate recovers by the reported margin compared with the undefended baseline.
Figures






read the original abstract
Recent years have witnessed the rapid development of Large Language Model-based Multi-Agent Systems (MAS), which excel at collaborative decision-making and complex problem-solving. However, malicious agents in MAS may inject misinformation to mislead other agents and disrupt system performance, giving rise to a new research direction that focuses on attack mechanisms and defense strategies in MAS. Prior studies largely assume malicious agents act independently and investigate the corresponding defense strategies. However, we argue that malicious agents may exhibit collaborative behaviors, enabling more effective attacks through internal information exchange. In this paper, we propose an adaptive cooperative attack framework, where malicious agents autonomously coordinate and dynamically adjust their attack strategies through multi-round interactions. Furthermore, we introduce Sentence-Level Trustworthiness Analysis and Rectification (STAR), a defense framework that identifies and rectifies misleading information at the sentence level within agent communications. Our experiments show that cooperative attacks lead to a significantly larger degradation in task success rate than independent attacks, resulting in a relative drop of 5.34\%. Meanwhile, STAR effectively mitigates both cooperative and independent threats and improves task success rate by an average of 36.76\%. The code is available at https://github.com/smoooom/STAR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an adaptive cooperative attack framework in which malicious agents in LLM-based multi-agent systems coordinate via multi-round internal exchanges to dynamically adjust attack strategies. It introduces STAR, a defense that performs sentence-level trustworthiness analysis and rectification on agent communications. Experiments are reported to show that cooperative attacks produce a 5.34% larger relative drop in task success rate than independent attacks, while STAR recovers an average of 36.76% in success rate across both threat models; code is released.
Significance. If the empirical claims hold under rigorous evaluation, the work would be significant for highlighting a stronger threat model (cooperative attacks) in MAS and for demonstrating a practical, sentence-level mitigation. Public code release is a clear strength that enables reproducibility and extension.
major comments (2)
- [Abstract] Abstract and experimental reporting: the headline claims of a 5.34% relative degradation and 36.76% average recovery are presented without any description of task environments, number of runs, statistical tests, variance, baselines, or error bars. These omissions are load-bearing for the central empirical contribution.
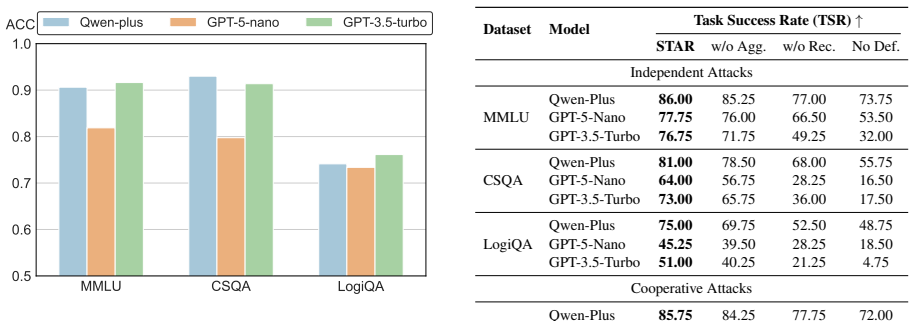
- [Evaluation] Evaluation section: no results or ablation are supplied for STAR's behavior on benign (attack-free) runs, leaving open whether sentence-level rectification introduces new errors, alters correct messages, or adds latency in normal operation.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment point by point below and will revise the manuscript to improve the reporting of our empirical results.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental reporting: the headline claims of a 5.34% relative degradation and 36.76% average recovery are presented without any description of task environments, number of runs, statistical tests, variance, baselines, or error bars. These omissions are load-bearing for the central empirical contribution.
Authors: We agree the abstract is too concise and omits key experimental context. The full manuscript (Section 4) specifies the task environments, reports results over multiple runs with variance, includes baselines, and uses statistical comparisons. We will revise the abstract to briefly note the evaluation settings and direct readers to the detailed results, while respecting length limits. This addresses the concern without misrepresenting the work. revision: yes
-
Referee: [Evaluation] Evaluation section: no results or ablation are supplied for STAR's behavior on benign (attack-free) runs, leaving open whether sentence-level rectification introduces new errors, alters correct messages, or adds latency in normal operation.
Authors: This observation is correct; the current evaluation focuses exclusively on attack scenarios. We will add a new ablation subsection reporting STAR's impact on benign runs, including task success rates, any alterations to correct messages, and latency measurements. These results will be included in the revised manuscript to fully characterize the defense. revision: yes
Circularity Check
No circularity; empirical claims rest on reported experiments
full rationale
The paper advances an empirical defense method (STAR) evaluated on task success rates under simulated attacks. No derivation chain, equations, or first-principles predictions exist that could reduce to inputs by construction. Claims of 36.76% average improvement and 5.34% relative degradation are presented as experimental outcomes, with no self-citation load-bearing steps, fitted parameters renamed as predictions, or ansatz smuggling. The work is self-contained against external benchmarks via reported results rather than internal redefinition.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
When Latent Agents Lie: KV-Cache Integrity in Multi-Agent LLM Collaboration
KV-cache sharing boosts multi-agent QA performance but enables undetectable tampering; HMAC manifests binding agent, session, and payload reliably detect changes.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2402.08567
Agent smith: A single image can jailbreak one million multimodal llm agents exponentially fast. arXiv preprint arXiv:2402.08567. Ruohao Guo, Wei Xu, and Alan Ritter. 2025. How to protect yourself from 5g radiation? investigating llm responses to implicit misinformation.arXiv preprint arXiv:2503.09598. Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Sh...
-
[2]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Jen-tse Huang, Jiaxu Zhou, Tailin Jin, Xuhui Zhou, Zixi Chen, Wenxuan Wang, Youliang Yuan, Michael R Lyu, and Maarten Sap. 2024. On the resilience of llm- based multi-agent collaboration with faulty agents. arXiv preprint arXiv:2408.00989. Tianjie Ju, Yiting Wang, Xinbei...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[3]
InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
A survey on trustworthy llm agents: Threats and countermeasures. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 6216–6226. Miao Yu, Shilong Wang, Guibin Zhang, Junyuan Mao, Chenlong Yin, Qijiong Liu, Qingsong Wen, Kun Wang, and Yang Wang. 2024. Netsafe: Exploring the topological safety of multi-agent ne...
-
[4]
If the ally’s argument is strong: Explicitly acknowledge and support the ally’s argument
-
[5]
[Question]
If the ally’s argument is weak: Introduce a new, stronger argument for the same target answer. You must format output exactly as follows, without including any additional information: <REASON>: [Provide your reasoning here.] <ANSWER>: [Provide your answer here, can only be the[Target Wrong Answer]option.] Figure 8: The prompt template for Cooperative Mali...
-
[6]
For each sentence, determine whether it is factually correct and output your confidence score
[Sentence 2] ... For each sentence, determine whether it is factually correct and output your confidence score. If a sentence refers to other agents’ responses, do not mark it as factually incorrect solely because you lack access to other agents’ responses. Output in the following format:
-
[7]
For factually wrong sentences (marked ’No’), perform the following operations: Extract Misleading Claim:A concise summary of the error
No, 0.85 ## PART 2: Detailed Error Analysis and Correction Review the results from PART 1. For factually wrong sentences (marked ’No’), perform the following operations: Extract Misleading Claim:A concise summary of the error. Provide Correct Assertion:The complete, factually correct statement. CRITICAL:You must use the original sentence number (1, 2...) ...
-
[8]
Misleading Claim: [Concise error point] Correct Assertion: [Correct statement] If NO sentences were marked ’No’, output ’null’. You must format output exactly as follows: <FACTUALITY ANALYSIS>: [Yes/No labels and scores] <ERROR ANALYSIS>: [Inferred claims and correct assertions] Figure 9: The prompt template for the STAR LLM-based verifier, illustrating t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.