Scalable On-Hardware Training of Quantum Neural Networks and Application to Clinical Data Imputation
Pith reviewed 2026-06-28 09:27 UTC · model grok-4.3
The pith
A training framework reduces quantum neural network gradient costs from quadratic to logarithmic scaling in the number of qubits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
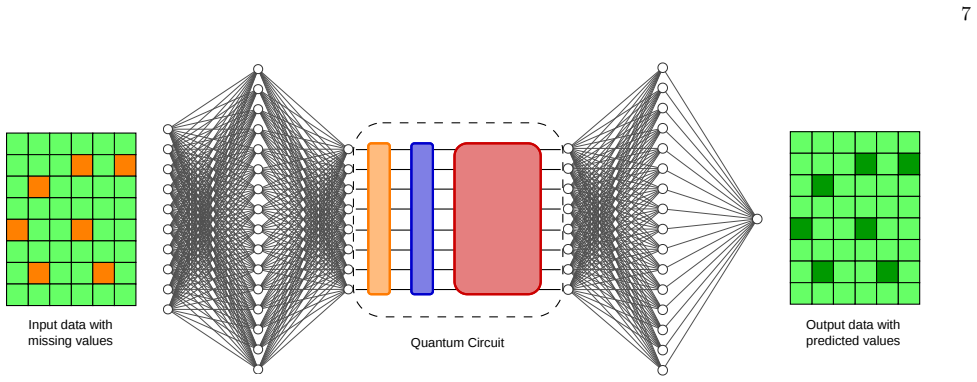
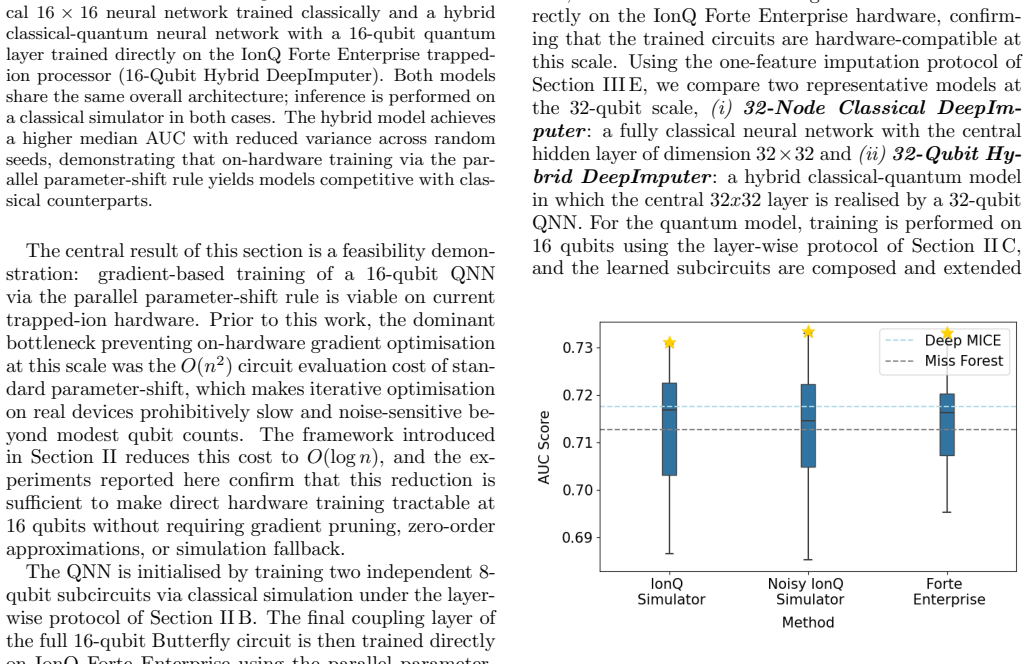
The authors present a framework that combines a subspace-preserving Butterfly circuit architecture with O(n log n) parameters and logarithmic depth, a layer-wise training strategy, and a parallelised parameter-shift rule exploiting commuting structure. This combination reduces the number of distinct circuit evaluations per optimisation step from O(n²) to O(log n), enabling on-hardware training of hybrid quantum-classical models at 16 qubits on trapped-ion hardware and 32 qubits via simulation, with successful application to clinical data imputation from the MIMIC-III dataset.
What carries the argument
The subspace-preserving Butterfly circuit architecture with layer-wise training and parallelised parameter-shift rule, which together allow constant-number gradient extraction per layer.
If this is right
- Gradient-based optimization of QNNs becomes practical on near-term hardware at larger scales.
- Hybrid models trained this way match or exceed classical neural baselines in downstream tasks like patient survival prediction.
- Training exhibits reduced variance across multiple runs compared to standard methods.
- 32-qubit inference can be executed on hardware without degradation from simulation.
Where Pith is reading between the lines
- The logarithmic scaling might enable training even larger QNNs as hardware improves.
- This method could be adapted for other quantum machine learning applications beyond data imputation.
- Combining this with classical pre- and post-processing might further improve efficiency in hybrid systems.
Load-bearing premise
The Butterfly circuit preserves enough commuting structure for parallel gradient computation while retaining sufficient expressivity for accurate clinical data imputation.
What would settle it
Measure the actual number of circuit executions required per optimization step on hardware and verify whether it remains independent of n or grows only logarithmically rather than quadratically.
Figures



read the original abstract
Training quantum neural networks (QNNs) on quantum hardware is currently bottlenecked by the cost of gradient estimation: standard parameter-shift methods require a number of circuit evaluations that grows quadratically with the number of trainable parameters, making hardware-based optimisation impractical beyond small system sizes. In this work, we introduce a training framework that reduces this cost to logarithmic in the number of qubits, making gradient-based QNN optimisation feasible on near-term hardware at increasing scales. Our framework combines three co-designed ingredients: (i) a structured, subspace-preserving Butterfly circuit architecture with $O(n \log n)$ parameters and logarithmic depth; (ii) a layer-wise training strategy that confines on-hardware optimisation to one small, well-structured layer at a time; and (iii) a parallelised parameter-shift rule that exploits the commuting structure within each Butterfly layer to extract all gradients in a constant number of circuit executions. Together these reduce the number of distinct circuit evaluations per optimisation step from $O(n^2)$ to $O(\log n)$. We validate the framework on clinical data imputation using the MIMIC-III electronic health record dataset, a demanding benchmark sensitive to optimisation instability and model variance. Hybrid classical-quantum models are trained directly on IonQ Forte Enterprise trapped-ion hardware at 16 qubits without performance degradation relative to ideal or noisy simulation and via tensor-network simulation at 32 qubits, with 32-qubit inference executed on hardware. The resulting models match or exceed strong classical neural baselines in downstream patient survival prediction while exhibiting reduced variance across runs, demonstrating that the proposed framework enables practical, scalable QNN training under realistic hardware constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
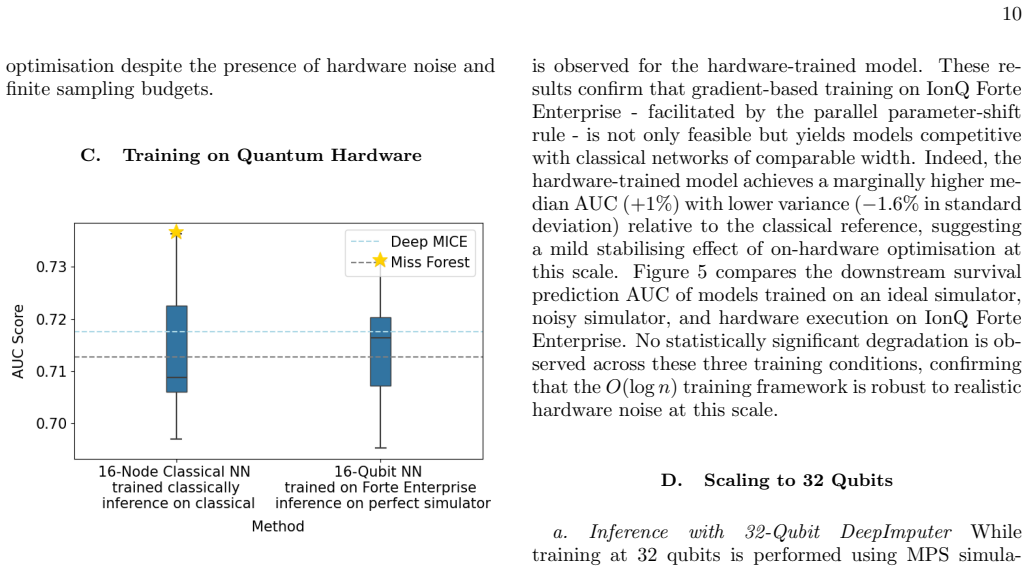
Summary. The paper claims a training framework for quantum neural networks that reduces per-step gradient estimation cost from O(n²) to O(log n) via three co-designed elements: a subspace-preserving Butterfly circuit ansatz with O(n log n) parameters and log depth, layer-wise training that optimizes one layer at a time, and a parallelised parameter-shift rule that uses intra-layer commuting structure to obtain all layer gradients in a constant number of circuit executions. The framework is demonstrated on clinical data imputation from the MIMIC-III dataset, with hybrid models trained directly on IonQ Forte trapped-ion hardware at 16 qubits (and tensor-network simulation at 32 qubits), matching or exceeding classical neural-network baselines on downstream survival prediction while showing lower run-to-run variance and no degradation relative to ideal/noisy simulation.
Significance. If the O(log n) scaling and expressivity claims hold, the work would enable practical gradient-based QNN training on near-term hardware at scales previously limited by quadratic measurement cost. Strengths include direct hardware execution at 16 qubits, use of a demanding real-world clinical benchmark (MIMIC-III), and reported reduction in variance; these provide independent empirical grounding beyond synthetic tasks. The co-design of architecture, training schedule, and gradient estimator is a constructive approach to the measurement bottleneck.
major comments (2)
- [Section describing the parallelised parameter-shift rule and Butterfly layer construction] The O(log n) scaling rests on the parallelised parameter-shift rule extracting all gradients for each Butterfly layer in a fixed number of executions. The manuscript asserts that the subspace-preserving construction supplies the required commuting structure (or simultaneous-shift identity) among the O(n) generators inside a layer, but supplies no explicit commutation relations, algebraic identity, or verification that this property holds for the specific generators used. This is load-bearing for the central complexity claim; without it the per-step cost reverts to linear in the number of layer parameters.
- [Hardware validation and MIMIC-III results section] Table or figure reporting 16-qubit hardware results: the claim of 'no performance degradation relative to ideal or noisy simulation' is central to the practical-utility argument, yet the description does not clarify whether data-selection criteria or the particular imputation benchmark could bias the comparison; additional ablation on these choices would be needed to confirm the result is not an artifact of benchmark construction.
minor comments (2)
- [Abstract and scaling claim paragraph] Notation for the number of circuit evaluations per optimisation step should be stated explicitly (e.g., the precise constant hidden by O(log n)) rather than left implicit.
- [Results figures] Figure captions comparing hardware, noisy simulation, and classical baselines should include error bars or run counts so that the reported variance reduction can be assessed quantitatively.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of the work's significance. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Section describing the parallelised parameter-shift rule and Butterfly layer construction] The O(log n) scaling rests on the parallelised parameter-shift rule extracting all gradients for each Butterfly layer in a fixed number of executions. The manuscript asserts that the subspace-preserving construction supplies the required commuting structure (or simultaneous-shift identity) among the O(n) generators inside a layer, but supplies no explicit commutation relations, algebraic identity, or verification that this property holds for the specific generators used. This is load-bearing for the central complexity claim; without it the per-step cost reverts to linear in the number of layer parameters.
Authors: We agree that an explicit derivation strengthens the central claim. The Butterfly ansatz is defined via a recursive subspace-preserving decomposition in which the generators within each layer act on orthogonal subspaces and therefore commute. In the revised manuscript we will add a new subsection that states the generators explicitly, proves [G_i, G_j]=0 for all pairs inside a layer from the algebraic form of the unitary blocks, and verifies the simultaneous-shift identity used by the parallelised rule. This addition directly supports the O(1) circuit count per layer. revision: yes
-
Referee: [Hardware validation and MIMIC-III results section] Table or figure reporting 16-qubit hardware results: the claim of 'no performance degradation relative to ideal or noisy simulation' is central to the practical-utility argument, yet the description does not clarify whether data-selection criteria or the particular imputation benchmark could bias the comparison; additional ablation on these choices would be needed to confirm the result is not an artifact of benchmark construction.
Authors: We acknowledge the need for additional controls. The MIMIC-III preprocessing follows the standard protocol used in prior clinical-imputation studies (fixed patient cohort, missingness pattern, and train/test split). In the revised manuscript we will add an ablation subsection that repeats the 16-qubit hardware runs under two alternative cohort-selection rules and two different missingness rates, reporting the resulting accuracy and variance metrics to demonstrate that the 'no degradation' observation is robust to these choices. revision: yes
Circularity Check
No significant circularity; scaling derived from explicitly introduced co-designed components with external validation
full rationale
The paper introduces a Butterfly architecture, layer-wise training, and parallel parameter-shift rule as new elements whose combination yields the O(log n) circuit-evaluation scaling. This is not self-definitional or fitted-input-called-prediction because the commuting structure is a stated property of the proposed subspace-preserving construction, the overall claim is supported by training and inference on the external MIMIC-III dataset plus real IonQ hardware (16 qubits) and tensor-network simulation (32 qubits), and no load-bearing self-citations or renamings of known results appear in the provided text. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Scalable Message-Passing Quantum Graph Neural Networks in the Weisfeiler-Leman Hierarchy
The work constructs a permutation-equivariant quantum GNN that implements message passing at selectable Weisfeiler-Leman levels, supports pre-training on small graphs, and demonstrates readout scalability with simulat...
Reference graph
Works this paper leans on
-
[1]
State Initialisation: Non-Gaussian Inputs The first stage of the QNN prepares the quantum reg- ister in a non-Gaussian initial state. This choice is es- sential because the parametrised layers of our model are constructed from fermionic linear optics (FLO) circuits, which are efficiently classically simulable when initialised in Gaussian states [21, 22]. ...
-
[2]
Specifically, we employ the RY loader introduced in [15], which belongs to the broader class of hardware- efficient angle encodings studied in [13, 14, 23]
Data Loading and Feature Encoding Classical data are embedded into the quantum circuit using an angle-encoding scheme based on single-qubit ro- tations. Specifically, we employ the RY loader introduced in [15], which belongs to the broader class of hardware- efficient angle encodings studied in [13, 14, 23]. The RY encoding layer rotates individual qubit ...
-
[3]
Parametrised Circuit: Butterfly Architecture The trainable core of the QNN is a subspace-preserving parametrised quantum circuit based on the Butterfly ar- chitecture proposed in [16], building on the excitation- preserving QNN framework of [11]. The circuit is com- posed of layers of two-qubit Reconfigurable Beam Splitter (RBS) gates [24], defined as RBS...
-
[4]
Schuld, V
M. Schuld, V. Bergholm, C. Gogolin, J. Izaac, and N. Kil- loran, Evaluating analytic gradients on quantum hard- ware, Physical Review A99, 032331 (2019)
2019
-
[5]
D. B. Rubin, Multiple imputation, inFlexible impu- tation of missing data, second edition(Chapman and Hall/CRC, 2018) pp. 29–62
2018
-
[6]
J. A. Sterne, I. R. White, J. B. Carlin, M. Spratt, P. Royston, M. G. Kenward, A. M. Wood, and J. R. Carpenter, Multiple imputation for missing data in epi- demiological and clinical research: potential and pitfalls, Bmj338(2009)
2009
-
[7]
J. R. McClean, S. Boixo, V. N. Smelyanskiy, R. Bab- bush, and H. Neven, Barren plateaus in quantum neural network training landscapes, Nature Communications9, 4812 (2018)
2018
-
[8]
Cerezo, A
M. Cerezo, A. Sone, T. Volkoff, L. Cincio, and P. Coles, Cost function dependent barren plateaus in shallow parametrized quantum circuits, Nature Communications 12, 1791 (2021)
2021
-
[9]
Monbroussou, E
L. Monbroussou, E. Z. Mamon, J. Landman, A. B. Grilo, R. Kukla, and E. Kashefi, Trainability and expressivity of hamming-weight preserving quantum circuits for ma- chine learning, Quantum9, 1745 (2025)
2025
-
[10]
Mitarai, M
K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, Quantum circuit learning, Physical Review A98, 032309 (2018)
2018
-
[11]
Abbas, R
A. Abbas, R. King, H.-Y. Huang, W. J. Huggins, R. Movassagh, D. Gilboa, and J. McClean, On quan- tum backpropagation, information reuse, and cheating measurement collapse, Advances in Neural Information Processing Systems36, 44792 (2023)
2023
-
[12]
H. Wang, Z. Li, J. Gu, Y. Ding, D. Z. Pan, and S. Han, QOC: Quantum on-chip training with param- eter shift and gradient pruning, inProceedings of the 59th ACM/IEEE Design Automation Conference (DAC) (2022) pp. 655–660, arXiv:2202.13239
arXiv 2022
- [13]
-
[14]
Landman, N
J. Landman, N. Mathur, Y. Y. Li, M. Strahm, S. Kazdaghli, A. Prakash, and I. Kerenidis, Quantum methods for neural networks and application to medical image classification, Quantum6, 881 (2022)
2022
-
[15]
I. Kerenidis and A. Prakash, Quantum machine learning with subspace states, arXiv preprint arXiv:2202.00054 (2022)
arXiv 2022
-
[16]
Havl´ ıˇ cek, A
V. Havl´ ıˇ cek, A. D. C´ orcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, Super- vised learning with quantum-enhanced feature spaces, Nature567, 209 (2019)
2019
-
[17]
Schuld and F
M. Schuld and F. Petruccione, Supervised learning with quantum computers, Quantum science and technology17 (2018)
2018
-
[18]
Thakkar, S
S. Thakkar, S. Kazdaghli, N. Mathur, I. Kerenidis, A. J. Ferreira-Martins, and S. Brito, Improved financial fore- casting via quantum machine learning, Quantum Ma- chine Intelligence6, 27 (2024)
2024
-
[19]
E. A. Cherrat, I. Kerenidis, N. Mathur, J. Landman, M. Strahm, and Y. Y. Li, Quantum vision transformers, Quantum8, 1265 (2024)
2024
-
[20]
G. E. Hinton, S. Osindero, and Y.-W. Teh, A fast learning algorithm for deep belief nets, Neural computation18, 1527 (2006)
2006
-
[21]
Tseng, Convergence of a block coordinate descent method for nondifferentiable minimization, Journal of op- timization theory and applications109, 475 (2001)
P. Tseng, Convergence of a block coordinate descent method for nondifferentiable minimization, Journal of op- timization theory and applications109, 475 (2001)
2001
- [22]
- [23]
-
[24]
Oszmaniec, N
M. Oszmaniec, N. Dangniam, M. E. Morales, and Z. Zim- bor´ as, Fermion sampling: a robust quantum computa- tional advantage scheme using fermionic linear optics and magic input states, PRX Quantum3, 020328 (2022)
2022
-
[25]
Knill, Fermionic linear optics and matchgates, arXiv preprint quant-ph/0108033 (2001)
E. Knill, Fermionic linear optics and matchgates, arXiv preprint quant-ph/0108033 (2001)
Pith/arXiv arXiv 2001
-
[26]
R. LaRose and B. Coyle, Robust data encodings for quan- tum classifiers, arXiv preprint arXiv:2003.01695 (2020)
arXiv 2003
-
[27]
Johri, S
S. Johri, S. Debnath, A. Mocherla, A. Singk, A. Prakash, J. Kim, and I. Kerenidis, Nearest centroid classification on a trapped ion quantum computer, npj Quantum In- formation7, 122 (2021)
2021
-
[28]
G.-L. R. Anselmetti, D. Wierichs, C. Gogolin, and R. M. Parrish, Local, expressive, quantum-number-preserving vqe ans¨ atze for fermionic systems, New Journal of Physics23, 113010 (2021)
2021
-
[29]
A. E. Johnson, T. J. Pollard, L. Shen, L.-w. H. Lehman, M. Feng, M. Ghassemi, B. Moody, P. Szolovits, L. An- thony Celi, and R. G. Mark, Mimic-iii, a freely accessible critical care database, Scientific data3, 1 (2016)
2016
-
[30]
Kazdaghli, I
S. Kazdaghli, I. Kerenidis, J. Kieckbusch, and P. Teare, Improved clinical data imputation via classical and quan- tum determinantal point processes, Elife12, RP89947 (2024)
2024
-
[31]
Shadbahr, M
T. Shadbahr, M. Roberts, J. Stanczuk, J. Gilbey, P. Teare, S. Dittmer, M. Thorpe, R. V. Torn´ e, E. Sala, P. Li´ o,et al., The impact of imputation quality on ma- chine learning classifiers for datasets with missing values, Communications medicine3, 139 (2023)
2023
-
[32]
Van Buuren and K
S. Van Buuren and K. Groothuis-Oudshoorn, mice: Mul- tivariate imputation by chained equations in r, Journal of statistical software45, 1 (2011)
2011
-
[33]
D. J. Stekhoven and P. B¨ uhlmann, Missforest—non- parametric missing value imputation for mixed-type data, Bioinformatics28, 112 (2012)
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.