Rethinking LoRA Memory Through the Lens of KV Cache Compression
Pith reviewed 2026-06-28 01:23 UTC · model grok-4.3
The pith
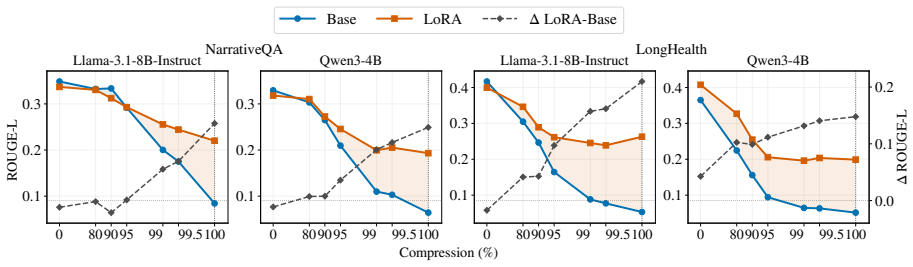
Document LoRA recovers 13-21 ROUGE-L points when KV cache document states are fully evicted in QA tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
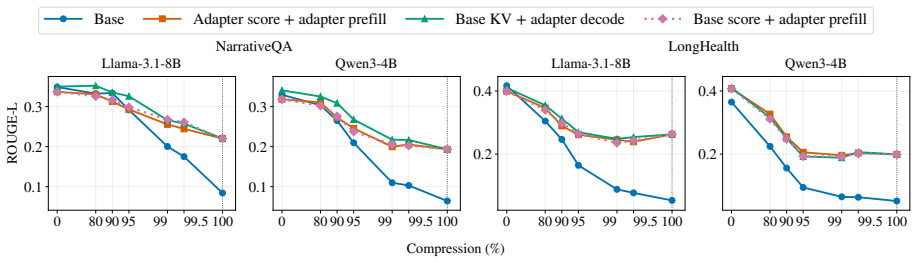
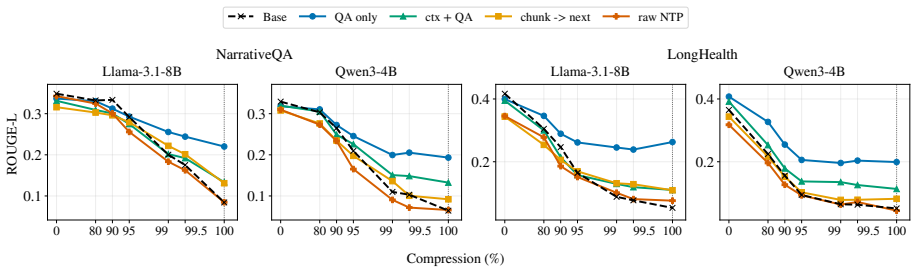
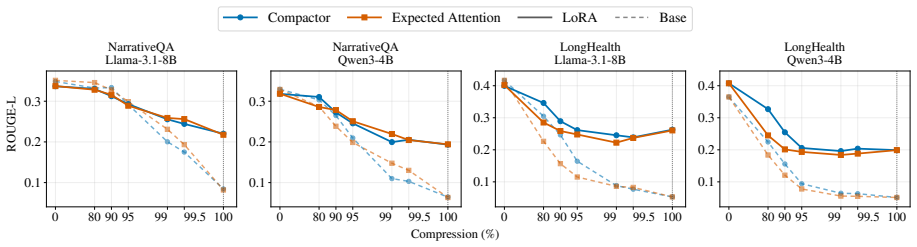
We study this interaction in document-level question answering by progressively evicting document key-value states and measuring when a document LoRA contributes beyond the retained context. We find that document LoRA adds little when the KV cache is largely intact, but becomes increasingly useful under aggressive compression, recovering 13-21 ROUGE-L points when no document context remains. The gain is largest when the base model encodes the document, and the adapter is applied only during answer generation, suggesting that document LoRA is better understood as decoding-time parametric memory than as a document encoder. Finally, QA-style supervision produces substantially stronger adapters
What carries the argument
Progressive eviction of document key-value states from the KV cache, used to isolate when document LoRA supplies benefit beyond retained context.
If this is right
- Document LoRA functions as decoding-time parametric memory rather than a document encoder.
- The value of document LoRA emerges precisely when context-side evidence is scarce.
- QA-style supervision produces substantially stronger adapters than raw-context next-token prediction.
- Document LoRA acts as a complementary memory channel to the KV cache.
Where Pith is reading between the lines
- The same separation of encoding and generation phases could be tested with other adapter types or compression methods.
- Hybrid memory designs might activate document LoRA only after cache occupancy drops below a threshold.
- The finding implies that training objectives for adapters should prioritize QA supervision over standard language modeling when the goal is supplemental memory.
- Results may inform memory allocation strategies that balance parametric and contextual storage based on available cache space.
Load-bearing premise
The progressive eviction of document key-value states isolates the marginal contribution of the document LoRA without confounding effects from the eviction implementation or model-specific cache behavior.
What would settle it
An experiment that applies the same progressive eviction protocol but observes no ROUGE-L recovery from document LoRA after full document state removal would falsify the central claim.
Figures

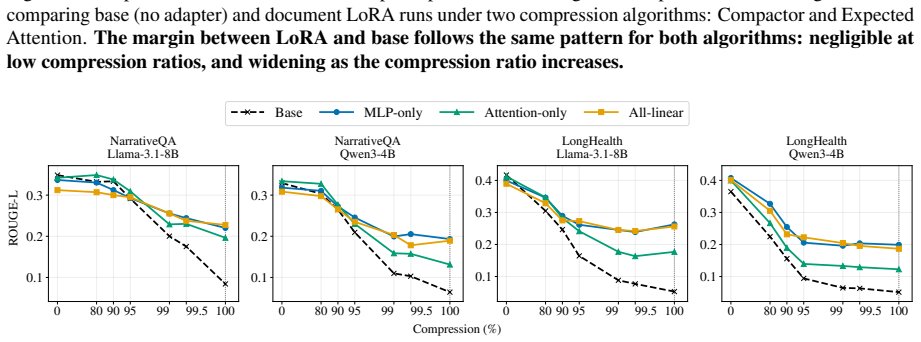
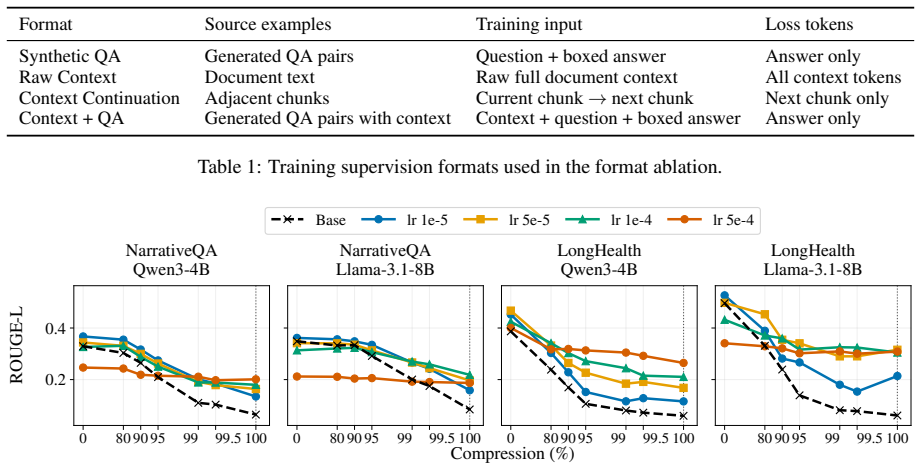
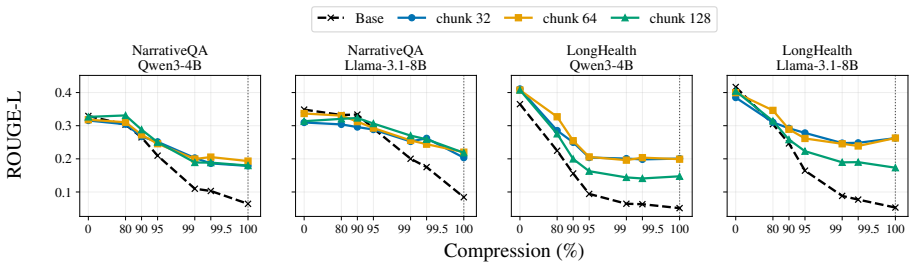
read the original abstract
Parametric retrieval augmentation encodes document information into lightweight, document-specific modules such as LoRA adapters, reducing the need to include all evidence as input context. However, it remains unclear how this parameter-side memory interacts with context-side memory stored in the KV cache. We study this interaction in document-level question answering by progressively evicting document key-value states and measuring when a document LoRA contributes beyond the retained context. We find that document LoRA adds little when the KV cache is largely intact, but becomes increasingly useful under aggressive compression, recovering 13-21 ROUGE-L points when no document context remains. The gain is largest when the base model encodes the document, and the adapter is applied only during answer generation, suggesting that document LoRA is better understood as decoding-time parametric memory than as a document encoder. Finally, QA-style supervision produces substantially stronger adapters than raw-context next-token-prediction. These results position document LoRA as a complementary memory channel whose value emerges precisely when context-side evidence is scarce.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that document-specific LoRA adapters interact with KV cache compression in document-level QA such that LoRA adds little when the cache is largely intact but recovers 13-21 ROUGE-L points under aggressive eviction when no document context remains. The largest gains occur when the base model encodes the document and the adapter is applied only at generation time, positioning document LoRA as decoding-time parametric memory rather than a document encoder. QA-style supervision is reported to yield substantially stronger adapters than raw-context next-token prediction.
Significance. If the empirical isolation of LoRA's marginal contribution holds, the work supplies concrete evidence that parametric memory via LoRA becomes valuable precisely when context-side memory is scarce, with direct implications for memory-constrained long-context inference. The supervision-type comparison and the decoding-only application finding are useful distinctions. The manuscript does not ship machine-checked proofs or parameter-free derivations, but the progressive-eviction design offers a falsifiable empirical test of the parametric-vs-context memory tradeoff.
major comments (2)
- [results / experimental setup] The central claim that LoRA's contribution can be isolated by progressive eviction of document KV states (abstract and results section) rests on the assumption that the eviction procedure cleanly varies retained context without interacting with model-specific attention or the eviction rule. No controls for alternative policies (attention-based vs. recency vs. random) or reporting of how eviction interacts with the chosen model are provided, leaving open the possibility that the reported 13-21 ROUGE-L crossover and the decoding-only advantage are artifacts of the specific implementation rather than a general property.
- [abstract / results] The quantitative claims of 13-21 ROUGE-L recovery and the condition under which the gain is largest (base model encodes document, adapter only at generation) are presented without accompanying details on the number of documents, statistical significance tests, variance across runs, or the exact models and eviction thresholds used. These omissions make it impossible to verify that the data support the stated conditions and effect sizes.
minor comments (2)
- [method] Notation for the two application regimes (full LoRA vs. generation-only) should be defined explicitly with a table or equation rather than described only in prose.
- [experimental setup] The manuscript would benefit from an explicit statement of the eviction policy (algorithm or pseudocode) even if the main results use a single policy.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important aspects of experimental robustness and reporting that we will address in revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [results / experimental setup] The central claim that LoRA's contribution can be isolated by progressive eviction of document KV states (abstract and results section) rests on the assumption that the eviction procedure cleanly varies retained context without interacting with model-specific attention or the eviction rule. No controls for alternative policies (attention-based vs. recency vs. random) or reporting of how eviction interacts with the chosen model are provided, leaving open the possibility that the reported 13-21 ROUGE-L crossover and the decoding-only advantage are artifacts of the specific implementation rather than a general property.
Authors: We agree that controls for alternative eviction policies would strengthen the generality of the claims. In the revised manuscript we will add experiments using attention-based eviction and random eviction (in addition to the primary policy) on the same models and datasets, reporting the resulting ROUGE-L curves to show that the LoRA benefit under heavy compression is not an artifact of one eviction rule. revision: yes
-
Referee: [abstract / results] The quantitative claims of 13-21 ROUGE-L recovery and the condition under which the gain is largest (base model encodes document, adapter only at generation) are presented without accompanying details on the number of documents, statistical significance tests, variance across runs, or the exact models and eviction thresholds used. These omissions make it impossible to verify that the data support the stated conditions and effect sizes.
Authors: We acknowledge the missing details. The revised manuscript will report the exact number of documents per dataset, the models and eviction thresholds used, standard deviations across runs, and results of statistical significance tests (paired t-tests) for the reported ROUGE-L differences. These will be added to both the abstract and the experimental setup section. revision: yes
Circularity Check
No circularity: purely empirical measurements of LoRA under KV eviction
full rationale
The paper reports direct experimental results on progressive KV cache eviction in document QA, measuring ROUGE-L gains from document LoRA under varying retained context. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text or abstract. The central claims rest on observed performance deltas (e.g., 13-21 ROUGE-L recovery when context is fully evicted) rather than any self-referential construction, rendering the analysis self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Memory Depth, Not Memory Access: Selective Parametric Consolidation for Long-Running Language Agents
EVAF, a surprise- and valence-gated LoRA mechanism, provides memory depth for goal persistence in language agents via the loop-drift protocol, complementary to retrieval.
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
Retrieval-augmented generation for knowledge-intensive NLP tasks , year =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-augmented generation for knowledge-intensive NLP tasks , year =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
-
[3]
International Conference on Learning Representations , year=
LoRA: Low-Rank Adaptation of Large Language Models , author=. International Conference on Learning Representations , year=
-
[4]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Liu, Shih-Yang and Wang, Chien-Yi and Yin, Hongxu and Molchanov, Pavlo and Wang, Yu-Chiang Frank and Cheng, Kwang-Ting and Chen, Min-Hung , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[5]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Found in the Middle: How Language Models Use Long Contexts Better via Plug-and-Play Positional Encoding , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[6]
arXiv preprint arXiv:2401.14490 , year =
LongHealth: A Question Answering Benchmark with Long Clinical Documents , author =. arXiv preprint arXiv:2401.14490 , year =. 2401.14490 , archivePrefix =
-
[7]
Mixture of Lo
Xun Wu and Shaohan Huang and Furu Wei , booktitle=. Mixture of Lo. 2024 , url=
2024
-
[8]
arXiv preprint arXiv:2601.21795 , year=
Effective LoRA Adapter Routing using Task Representations , author=. arXiv preprint arXiv:2601.21795 , year=
-
[9]
arXiv preprint arXiv:2405.17741 , year=
LoRA-Switch: Boosting the Efficiency of Dynamic LLM Adapters via System-Algorithm Co-design , author=. arXiv preprint arXiv:2405.17741 , year=
-
[10]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Adapters Selector: Cross-domains and Multi-tasks LoRA Modules Integration Usage Method , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[11]
arXiv preprint arXiv:2512.17910 , year=
Efficient Multi-Adapter LLM Serving via Cross-Model KV-Cache Reuse with Activated LoRA , author=. arXiv preprint arXiv:2512.17910 , year=
-
[12]
Lastras and Thomas Parnell and Vraj Shah and Lucian Popa and Giulio Zizzo and Chulaka Gunasekara and Ambrish Rawat and David Daniel Cox , booktitle=
Kristjan Greenewald and Luis A. Lastras and Thomas Parnell and Vraj Shah and Lucian Popa and Giulio Zizzo and Chulaka Gunasekara and Ambrish Rawat and David Daniel Cox , booktitle=. Activated Lo. 2025 , url=
2025
-
[13]
Scissorhands: Exploiting the Persistence of Importance Hypothesis for
Zichang Liu and Aditya Desai and Fangshuo Liao and Weitao Wang and Victor Xie and Zhaozhuo Xu and Anastasios Kyrillidis and Anshumali Shrivastava , booktitle=. Scissorhands: Exploiting the Persistence of Importance Hypothesis for. 2023 , url=
2023
-
[14]
arXiv preprint arXiv:2402.18096 , year=
No token left behind: Reliable kv cache compression via importance-aware mixed precision quantization , author=. arXiv preprint arXiv:2402.18096 , year=
-
[15]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Li, Yuhong and Huang, Yingbing and Yang, Bowen and Venkitesh, Bharat and Locatelli, Acyr and Ye, Hanchen and Cai, Tianle and Lewis, Patrick and Chen, Deming , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[16]
Jain, N., Singh, J., Shetty, M., Zhang, T., Zheng, L., Sen, K., and Stoica, I
Hooper, Coleman and Kim, Sehoon and Mohammadzadeh, Hiva and Mahoney, Michael W. and Shao, Yakun Sophia and Keutzer, Kurt and Gholami, Amir , booktitle =. KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization , url =. doi:10.52202/079017-0040 , editor =
-
[17]
arXiv preprint arXiv:2507.08143 , year=
Compactor: Calibrated Query-Agnostic KV Cache Compression with Approximate Leverage Scores , author=. arXiv preprint arXiv:2507.08143 , year=
-
[18]
Zefan Cai and Yichi Zhang and Bofei Gao and Yuliang Liu and Yucheng Li and Tianyu Liu and Keming Lu and Wayne Xiong and Yue Dong and Junjie Hu and Wen Xiao , booktitle=. Pyramid. 2025 , url=
2025
-
[19]
Yuan Feng and Junlin Lv and Yukun Cao and Xike Xie and S Kevin Zhou , booktitle=. Ada-. 2025 , url=
2025
-
[20]
2024 , editor =
Liu, Zirui and Yuan, Jiayi and Jin, Hongye and Zhong, Shaochen and Xu, Zhaozhuo and Braverman, Vladimir and Chen, Beidi and Hu, Xia , booktitle =. 2024 , editor =
2024
-
[21]
The Thirteenth International Conference on Learning Representations , year=
D2O: Dynamic Discriminative Operations for Efficient Long-Context Inference of Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[22]
2024 , editor =
Zhang, Yuxin and Du, Yuxuan and Luo, Gen and Zhong, Yunshan and Zhang, Zhenyu and Liu, Shiwei and Ji, Rongrong , booktitle =. 2024 , editor =
2024
-
[23]
arXiv preprint arXiv:2407.08454 , year=
Model tells you where to merge: Adaptive kv cache merging for llms on long-context tasks , author=. arXiv preprint arXiv:2407.08454 , year=
-
[24]
arXiv preprint arXiv:2510.00636 , year=
Expected Attention: KV Cache Compression by Estimating Attention from Future Queries Distribution , author=. arXiv preprint arXiv:2510.00636 , year=
-
[25]
H2O: heavy-hitter oracle for efficient generative inference of large language models , year =
Zhang, Zhenyu and Sheng, Ying and Zhou, Tianyi and Chen, Tianlong and Zheng, Lianmin and Cai, Ruisi and Song, Zhao and Tian, Yuandong and R\'. H2O: heavy-hitter oracle for efficient generative inference of large language models , year =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
-
[26]
The Twelfth International Conference on Learning Representations , year=
Efficient Streaming Language Models with Attention Sinks , author=. The Twelfth International Conference on Learning Representations , year=
-
[27]
The Eleventh International Conference on Learning Representations , year=
Mass-Editing Memory in a Transformer , author=. The Eleventh International Conference on Learning Representations , year=
-
[28]
Proceedings of the 41st International Conference on Machine Learning , pages =
Physics of Language Models: Part 3.1, Knowledge Storage and Extraction , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[29]
The Thirteenth International Conference on Learning Representations , year=
Synthetic continued pretraining , author=. The Thirteenth International Conference on Learning Representations , year=
-
[30]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Understanding Parametric and Contextual Knowledge Reconciliation within Large Language Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[31]
arXiv preprint arXiv:2507.05346 , year=
LoRA-Augmented Generation (LAG) for Knowledge-Intensive Language Tasks , author=. arXiv preprint arXiv:2507.05346 , year=
-
[32]
Su, Weihang and Tang, Yichen and Ai, Qingyao and Yan, Junxi and Wang, Changyue and Wang, Hongning and Ye, Ziyi and Zhou, Yujia and Liu, Yiqun , title =. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2025 , isbn =. doi:10.1145/3726302.3729957 , abstract =
-
[33]
arXiv preprint arXiv:2503.23895 , year=
Dynamic parametric retrieval augmented generation for test-time knowledge enhancement , author=. arXiv preprint arXiv:2503.23895 , year=
-
[34]
Back, Seungju and Lee, Dongwoo and Kang, Naun and Lee, Taehee and Hong, S. K. and Gwon, Youngjune and Ahn, Sungjin , journal =. Understanding. 2026 , eprint =
2026
-
[35]
arXiv preprint arXiv:2602.16093 , year=
Updating Parametric Knowledge with Context Distillation Retains Post-Training Capabilities , author=. arXiv preprint arXiv:2602.16093 , year=
-
[36]
arXiv preprint arXiv:2602.15902 , year=
Doc-to-LoRA: Learning to Instantly Internalize Contexts , author=. arXiv preprint arXiv:2602.15902 , year=
-
[37]
Second Conference on Language Modeling , year=
Training Plug-and-Play Knowledge Modules with Deep Context Distillation , author=. Second Conference on Language Modeling , year=
-
[38]
arXiv preprint arXiv:2602.21221 , year=
Latent Context Compilation: Distilling Long Context into Compact Portable Memory , author=. arXiv preprint arXiv:2602.21221 , year=
-
[39]
International Conference on Learning Representations , year=
Cartridges: Lightweight and General-Purpose Long Context Representations via Self-Study , author=. International Conference on Learning Representations , year=
-
[40]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[41]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[42]
Ko. The. Transactions of the Association for Computational Linguistics , volume =. 2018 , doi =
2018
-
[43]
Transactions of the Association for Computational Linguistics , volume =
Lost in the Middle: How Language Models Use Long Contexts , author =. Transactions of the Association for Computational Linguistics , volume =. 2024 , doi =
2024
-
[44]
https://doi.org/10.18653/v1/2024.findings-acl.195
Yang, Dongjie and Han, Xiaodong and Gao, Yan and Hu, Yao and Zhang, Shilin and Zhao, Hai , booktitle =. 2024 , month =. doi:10.18653/v1/2024.findings-acl.195 , url =
-
[45]
Ghandeharioun, A., Caciularu, A., Pearce, A., Dixon, L., and Geva, M
Transformer Feed-Forward Layers Are Key-Value Memories , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages =. 2021 , month =. doi:10.18653/v1/2021.emnlp-main.446 , url =
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[46]
Knowledge Neurons in Pretrained Transformers
Knowledge Neurons in Pretrained Transformers , author =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2022 , month =. doi:10.18653/v1/2022.acl-long.581 , url =
-
[47]
Knowledge conflicts for LLMs: A survey
Xu, Rongwu and Qi, Zehan and Guo, Zhijiang and Wang, Cunxiang and Wang, Hongru and Zhang, Yue and Xu, Wei , booktitle =. Knowledge Conflicts for. 2024 , month =. doi:10.18653/v1/2024.emnlp-main.486 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.