ToolChoiceConfusion: Causal Minimal Tool Filtering for Reliable LLM Agents
Pith reviewed 2026-06-28 01:51 UTC · model grok-4.3
The pith
Causal Minimal Tool Filtering selects only the single causally sufficient next tool per step using precondition-effect contracts, matching full exposure success while cutting visible tools from 100 to 1 and tokens by 90%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
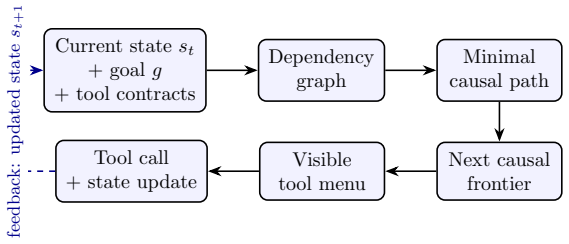
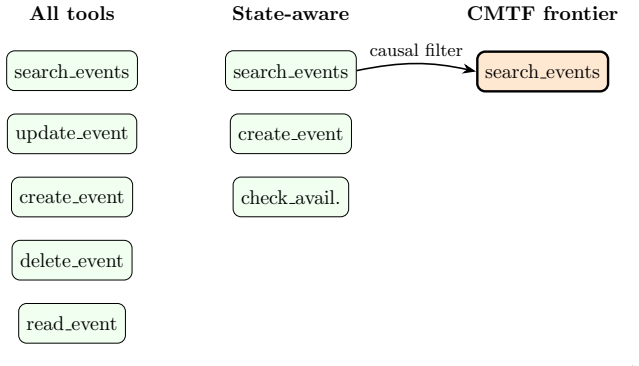
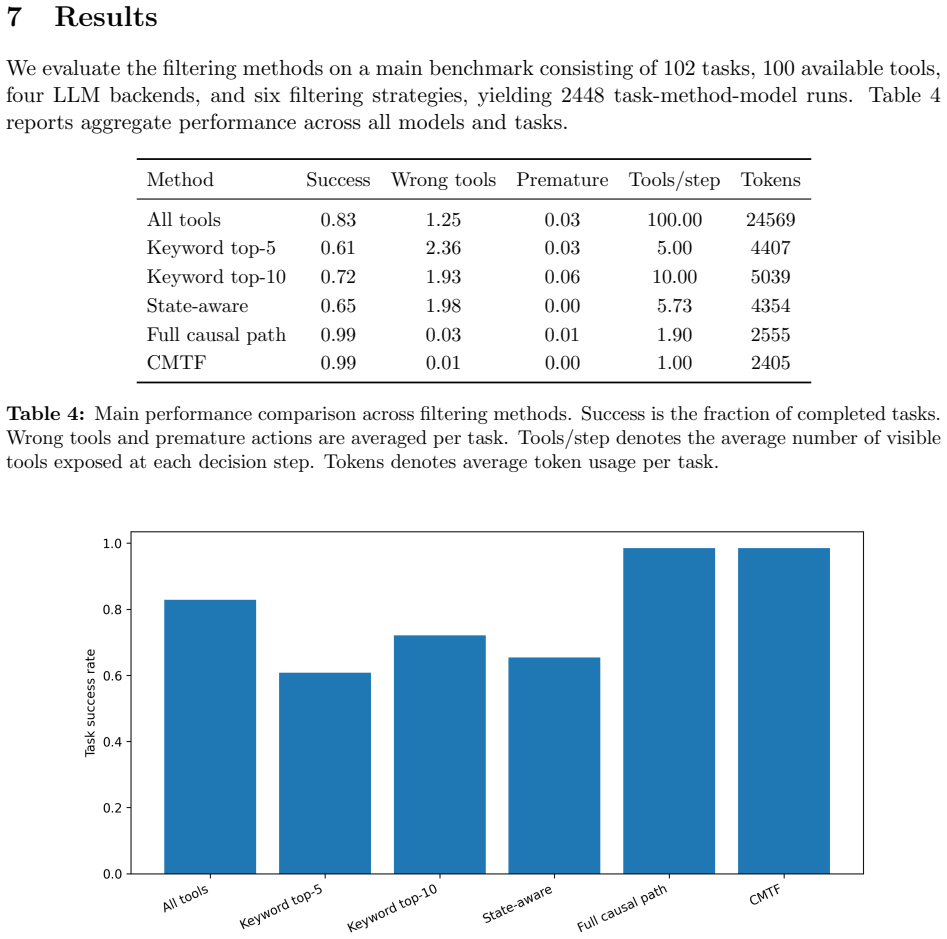
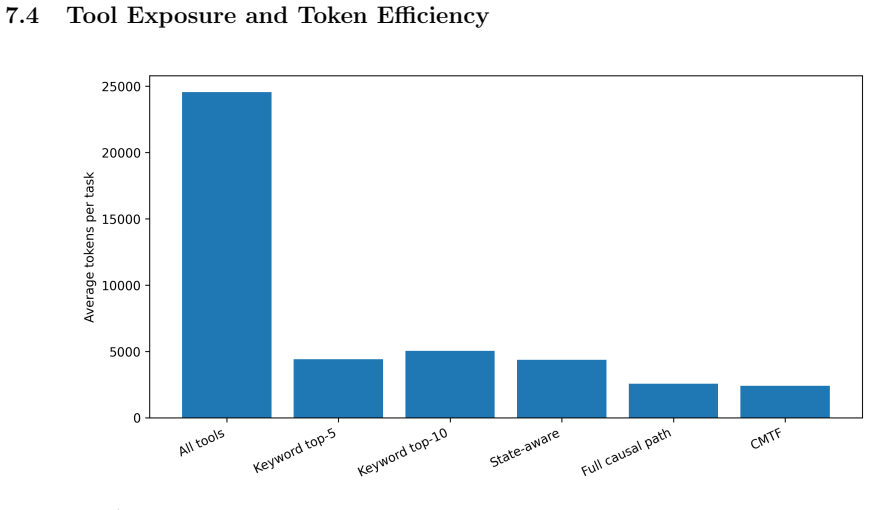
Causal Minimal Tool Filtering (CMTF) is a training-free method that selects tools by causal sufficiency. CMTF uses lightweight precondition-effect contracts to expose only the minimal next-step tool frontier needed to advance from the current state toward the user goal. Across multi-step tool-use tasks, we compare CMTF with all-tools exposure, keyword retrieval, state-aware filtering, and causal-path ablations, measuring task success, wrong-tool calls, premature actions, tool exposure, and token cost. In the main benchmark with 102 tasks, 100 tools, four LLM backends, and 2448 task-method-model runs, CMTF matches the strongest causal baseline in aggregate success while reducing visible tools
What carries the argument
Causal Minimal Tool Filtering (CMTF), which filters the tool set at each step to the minimal frontier of tools whose precondition-effect contracts establish causal sufficiency for advancing the current state.
If this is right
- Task success stays comparable to exposing the full tool set or using other causal selection methods.
- Wrong-tool calls and premature actions drop because only causally sufficient tools are visible at each step.
- Token usage falls by roughly 90 percent relative to all-tools exposure.
- The reduction in visible tools applies consistently across multiple LLM backends without any model training.
Where Pith is reading between the lines
- If the contracts could be generated automatically from tool descriptions rather than written by hand, the method could apply to tool sets too large for manual annotation.
- The same causal-sufficiency filter might be tested on agent frameworks that already maintain explicit state representations beyond the four backends examined.
- Lower tool visibility per step could reduce the rate at which agents take irreversible actions in domains where tool menus exceed a few dozen items.
Load-bearing premise
That lightweight precondition-effect contracts can be written for each tool such that they correctly identify causal sufficiency for the next step without missing necessary tools or including unnecessary ones.
What would settle it
A full run of the 102-task benchmark in which CMTF, using the authors' hand-written contracts, produces lower aggregate task success than the all-tools baseline across the four LLM backends.
Figures
read the original abstract
Large language model agents increasingly rely on external tools, but larger tool menus can reduce reliability and efficiency by increasing wrong-tool calls, premature actions, and token cost. Existing tool-selection methods often optimize semantic relevance, exposing tools whose names or descriptions match the user request. We argue that relevance is insufficient: a tool may be related to the task while still being unnecessary or premature at the current step. We propose Causal Minimal Tool Filtering (CMTF), a training-free method that selects tools by causal sufficiency. CMTF uses lightweight precondition-effect contracts to expose only the minimal next-step tool frontier needed to advance from the current state toward the user goal. Across multi-step tool-use tasks, we compare CMTF with all-tools exposure, keyword retrieval, state-aware filtering, and causal-path ablations, measuring task success, wrong-tool calls, premature actions, tool exposure, and token cost. In the main benchmark with 102 tasks, 100 tools, four LLM backends, and 2448 task-method-model runs, CMTF matches the strongest causal baseline in aggregate success while reducing visible tools from 100 to one per step and reducing token usage by about 90% relative to all-tools exposure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Causal Minimal Tool Filtering (CMTF), a training-free method that uses lightweight precondition-effect contracts to expose only the causally sufficient minimal tool set for the next step in multi-step LLM agent tasks. It evaluates CMTF against all-tools, keyword retrieval, state-aware filtering, and causal ablations on 102 tasks with 100 tools, four LLM backends, and 2448 runs, claiming aggregate success parity with the strongest causal baseline while reducing visible tools to one per step and token usage by ~90% relative to full exposure.
Significance. If the contracts prove robust, CMTF offers a practical way to improve agent reliability and efficiency by shifting from semantic relevance to causal sufficiency, with the large-scale multi-model evaluation providing a useful benchmark comparison. The training-free nature and explicit focus on reducing wrong-tool calls and premature actions are strengths that could influence tool-selection design.
major comments (2)
- [Abstract] Abstract and experimental description: the reported success parity with the strongest causal baseline is presented without any details on contract construction protocol, inter-annotator agreement, exact success metric definitions, error bars, or baseline implementation specifics, leaving the central empirical claim without visible support.
- [Method (precondition-effect contracts)] Method section on precondition-effect contracts: the claim that CMTF correctly identifies the minimal next-step tool frontier rests on the unvalidated assumption that the hand-authored contracts capture causal sufficiency without omissions or over-inclusions; no ablation perturbing the contracts or sensitivity analysis is described, making this assumption load-bearing for the success and cost-reduction results.
minor comments (2)
- [Abstract] The abstract mentions aggregate reductions but supplies no variance or statistical test details for the 90% token reduction claim.
- [Method] Notation for the contracts (precondition/effect pairs) could be formalized more explicitly to allow replication.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below with clarifications from the manuscript and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental description: the reported success parity with the strongest causal baseline is presented without any details on contract construction protocol, inter-annotator agreement, exact success metric definitions, error bars, or baseline implementation specifics, leaving the central empirical claim without visible support.
Authors: The abstract is length-limited, but the requested details appear in the main text: contract construction protocol is specified in Section 3.2 (hand-authored from tool documentation by the authors), success metrics are defined in Section 4.1 (binary task completion within a maximum step budget), error bars are 95% CIs shown in Table 2 and Figure 3, and baseline implementations are described in Section 4.1. Inter-annotator agreement does not apply, as the contracts were produced by the paper authors without independent annotators. We will revise the abstract to include concise references to these elements. revision: partial
-
Referee: [Method (precondition-effect contracts)] Method section on precondition-effect contracts: the claim that CMTF correctly identifies the minimal next-step tool frontier rests on the unvalidated assumption that the hand-authored contracts capture causal sufficiency without omissions or over-inclusions; no ablation perturbing the contracts or sensitivity analysis is described, making this assumption load-bearing for the success and cost-reduction results.
Authors: The manuscript includes causal-path ablations in Section 4.3 that isolate the contribution of the causal component. We agree, however, that an explicit sensitivity analysis on contract perturbations would provide stronger validation of the sufficiency assumption. We will add this analysis in revision, including controlled perturbations (e.g., omitted or extraneous preconditions) evaluated on a subset of tasks. revision: yes
Circularity Check
No circularity: training-free method with external baselines
full rationale
The paper presents CMTF as a training-free filtering method using hand-authored precondition-effect contracts, with all reported results obtained via direct comparison to external baselines (all-tools, keyword retrieval, state-aware filtering, causal-path ablations) across 2448 runs. No equations, fitted parameters, or self-referential quantities are described that would reduce success metrics to the method's own inputs by construction. The correctness of the contracts is an external assumption subject to validation risk, but does not constitute a circular derivation step under the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Lightweight precondition-effect contracts can be defined for each tool to expose causal sufficiency for the next step
invented entities (1)
-
Causal Minimal Tool Filtering (CMTF)
no independent evidence
Forward citations
Cited by 3 Pith papers
-
The Gate Is Only as Honest as Its Contracts: ContractGuard for the Contract Layer of Risk-Aware Causal Gating
ContractGuard verifies tool contracts in RACG systems to prevent effect forgery, restoring zero injection success on benchmarks and six hosted models against adaptive attackers.
-
Contract2Tool: Learning Preconditions and Effects for Reliable Tool-Augmented LLM Agents
Contract2Tool learns normalized symbolic contracts from tool metadata and traces to support causal filtering in LLM agents, reaching 0.980 downstream success versus 0.990 with gold contracts.
-
Lingering Authority: Revocable Resource-and-Effect Capabilities for Coding Agents
PORTICO is a revocable capability reference monitor for coding agents that enforces task contracts via grant-invoke-closure lifecycles and rejects post-closure reuses while preserving task success.
Reference graph
Works this paper leans on
-
[1]
Self-healing agentic orchestrators for reliable tool- augmented large language model systems, 2026
Rahul Suresh Babu and Adarsh Agrawal. Self-healing agentic orchestrators for reliable tool- augmented large language model systems, 2026
2026
-
[2]
Fikes and Nils J
Richard E. Fikes and Nils J. Nilsson. Strips: A new approach to the application of theorem proving to problem solving.Artificial Intelligence, 2(3–4):189–208, 1971
1971
-
[3]
Tiantian Gan and Qiyao Sun. Rag-mcp: Mitigating prompt bloat in llm tool selection via retrieval-augmented generation.arXiv preprint arXiv:2505.03275, 2025
arXiv 2025
-
[4]
Api-bank: A comprehensive benchmark for tool-augmented llms
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. Api-bank: A comprehensive benchmark for tool-augmented llms. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023
2023
-
[5]
Marianne Menglin Liu, Daniel Garcia, Fjona Parllaku, Vikas Upadhyay, Syed Fahad Allam Shah, and Dan Roth. Toolscope: Enhancing llm agent tool use through tool merging and context-aware filtering.arXiv preprint arXiv:2510.20036, 2025. 17
Pith/arXiv arXiv 2025
-
[6]
Agentbench: Evaluating llms as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating llms as agents. InInternational Conference on Learning Representations, 2024
2024
-
[7]
Pddl—the planning domain definition language
Drew McDermott, Malik Ghallab, Adele Howe, Craig Knoblock, Ashwin Ram, Manuela Veloso, Daniel Weld, and David Wilkins. Pddl—the planning domain definition language. Technical report, Yale Center for Computational Vision and Control, 1998
1998
-
[8]
Patil, Tianjun Zhang, Xin Wang, and Joseph E
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. The berkeley function- calling leaderboard. InProceedings of Machine Learning Research, 2025
2025
-
[9]
Toolllm: Facilitating large language models to master 16000+ real-world apis
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. Toolllm: Facilitating large language models to master 16000+ real-world apis. InInternational Conference on Learning Representations, 2024
2024
-
[10]
Vyzantinos Repantis, Ameya Gawde, Harshvardhan Singh, and Joey Blackwell. How many tools should an llm agent see? a chance-corrected answer.arXiv preprint arXiv:2605.24660, 2026
Pith/arXiv arXiv 2026
-
[11]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dess` ı, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems, 2023
2023
-
[12]
Retrieval models aren’t tool-savvy: Benchmarking tool retrieval for large language models
Zhengliang Shi, Yuhan Wang, Lingyong Yan, Pengjie Ren, Shuaiqiang Wang, Dawei Yin, and Zhaochun Ren. Retrieval models aren’t tool-savvy: Benchmarking tool retrieval for large language models. InFindings of the Association for Computational Linguistics, 2025
2025
-
[13]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023. 18
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.