Mutual Information Optimization via K-Recursion and Automatic Differentiation for Linear Gaussian Wireless Networks
Pith reviewed 2026-06-27 21:09 UTC · model grok-4.3
The pith
K-recursion assembles node-pair covariances for any linear Gaussian DAG so automatic differentiation supplies exact gradients for mutual-information maximization under global power limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The K-recursion analytically propagates all node-pair covariances along the DAG in topological order, including non-adjacent cross-covariances required for branching and merging paths. These covariances yield a closed-form log-determinant expression for the end-to-end mutual information as a smooth function of the controllable factors. Complex-valued reverse-mode automatic differentiation on the K-recursion returns the exact Wirtinger gradient at every controllable factor in a single backward sweep. Projected gradient ascent then maximizes the mutual information under global constraints such as a total transmit power budget, and the identical implementation applies without modification to si
What carries the argument
The K-recursion, which computes every node-pair covariance matrix by forward propagation in topological order so that the subsequent log-determinant expression equals the true end-to-end mutual information.
If this is right
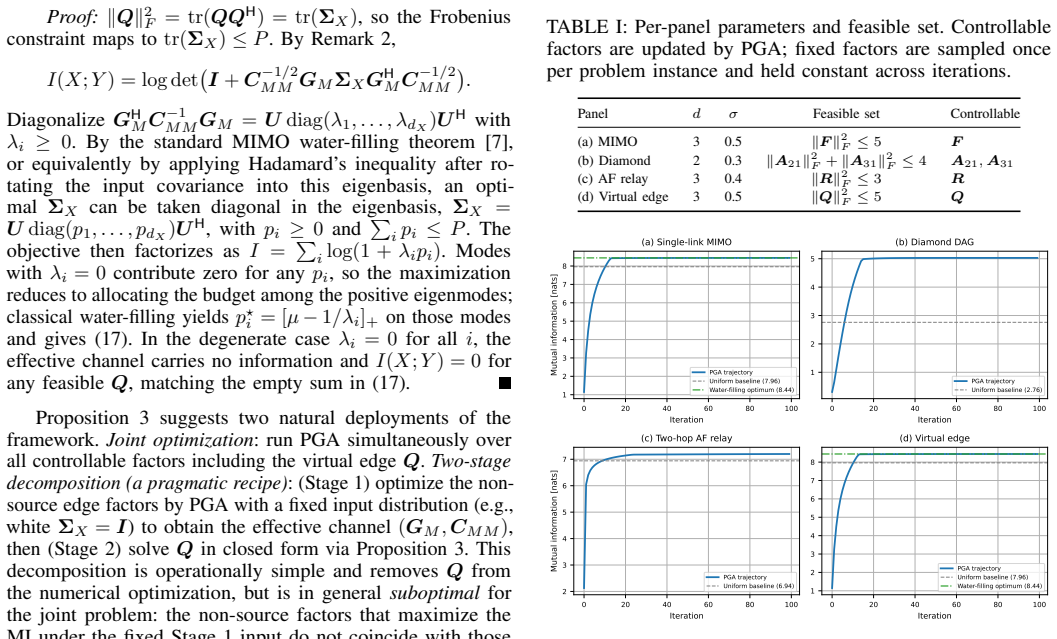
- The identical code reaches the classical water-filling optimum on single-link MIMO channels.
- The same implementation yields mutual-information gains on diamond DAGs and two-hop amplify-and-forward relays.
- Input-covariance shaping is optimized inside the same topology-agnostic procedure.
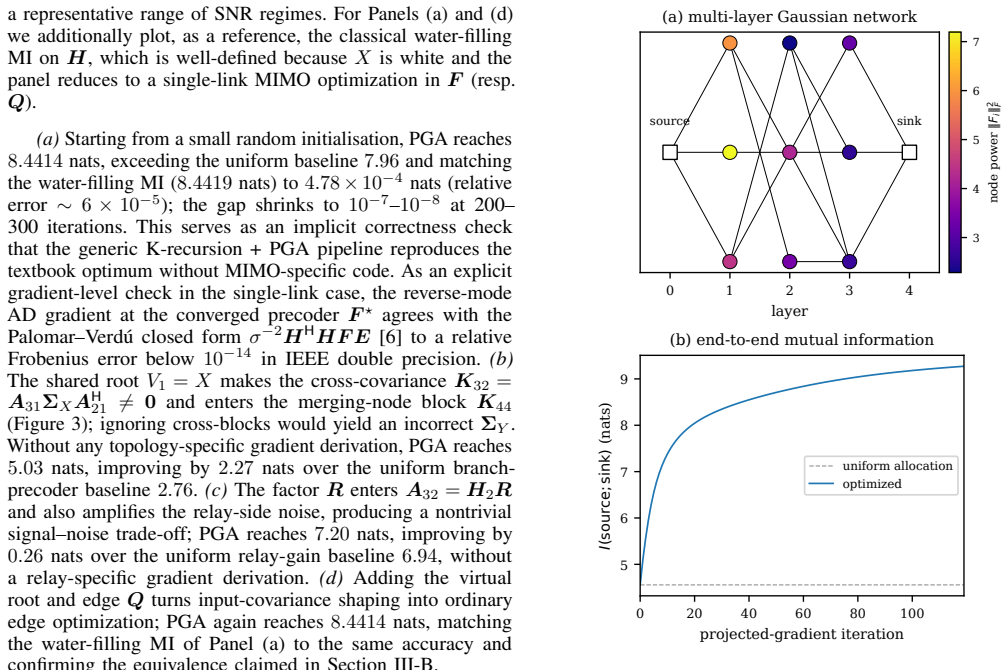
- The method extends without change to an eleven-node, five-layer Gaussian network for which no closed-form gradient exists.
Where Pith is reading between the lines
- The covariance recursion could be reused for other differentiable network objectives such as secrecy rates or estimation error provided the objective remains a smooth function of the covariances.
- If the underlying graph contains cycles, replacing the topological traversal with a fixed-point iteration on the covariance equations would preserve the automatic-differentiation step.
- The framework supplies a concrete testbed for checking whether learned precoders or relay gains generalize across randomly generated DAG topologies of fixed depth.
Load-bearing premise
The K-recursion must correctly assemble every required node-pair covariance, including non-adjacent cross terms, so that the log-determinant expression equals the true end-to-end mutual information.
What would settle it
Run the framework on a single-link MIMO channel whose water-filling mutual information is known in closed form and verify whether both the attained value and the computed gradients match the classical solution to machine precision.
Figures


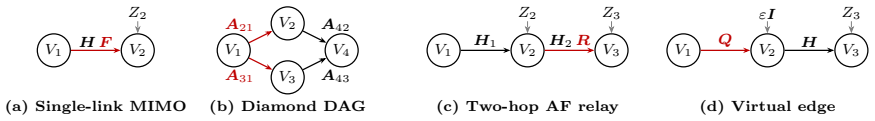

read the original abstract
We present a differentiable framework for end-to-end mutual information (MI) optimization over linear Gaussian directed acyclic graphs (DAGs). The framework targets network-wide design under global constraints, such as a total transmit power budget, and covers MIMO precoding, amplify-and-forward relays, RIS-aided channels, and branching/merging topologies within a common linear Gaussian model. Its core ingredient is a \emph{K-recursion} that analytically propagates all node-pair covariances along the DAG in topological order, including non-adjacent cross-covariances that are necessary for correctly handling branching and merging paths. The resulting covariances yield a closed-form log-determinant expression for the end-to-end MI as a smooth function of the controllable factors. Complex-valued reverse-mode automatic differentiation on this K-recursion then returns the exact Wirtinger gradient at every controllable factor in a single backward sweep, and projected gradient ascent (PGA) is used to maximize the MI under the global constraints. Because no closed-form gradient expression per topology is required, the same topology-agnostic implementation applies to any linear Gaussian DAG. A single topology-agnostic implementation is applied to four representative DAG classes: single-link MIMO, a diamond DAG, a two-hop AF relay, and input-covariance shaping. The same implementation reaches the classical water-filling optimum in the settings where it is available and yields MI improvements in non-single-link topologies without using topology-specific gradient formulas. A further experiment on a multi-layer Gaussian network (11 nodes, 5 layers) illustrates applicability to nontrivial multi-layer topologies for which no closed-form gradient is available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a topology-agnostic differentiable framework for end-to-end mutual information optimization over linear Gaussian DAGs. Its core is a K-recursion that propagates all node-pair covariances (including non-adjacent cross terms) in topological order to yield a closed-form log-determinant MI expression; reverse-mode automatic differentiation then supplies exact Wirtinger gradients, which are used with projected gradient ascent under global constraints such as total power. The same implementation is applied to single-link MIMO, diamond DAG, two-hop AF relay, input-covariance shaping, and an 11-node multi-layer network, with the claim that it recovers water-filling optima where available and yields improvements otherwise.
Significance. If the K-recursion is shown to be correct, the framework would provide a practical, general-purpose tool for MI maximization in wireless networks with branching/merging topologies where closed-form per-topology gradients are unavailable. The use of automatic differentiation on an analytic recursion is a methodological strength that avoids manual gradient derivations.
major comments (2)
- [Abstract] Abstract: the central claim that 'the same implementation reaches the classical water-filling optimum in the settings where it is available and yields MI improvements' is unsupported by any numerical results, tables, error metrics, or comparison data in the manuscript, so the accuracy of the K-recursion and the reported gains cannot be assessed.
- [Abstract] K-recursion (core ingredient described in Abstract): correctness for non-adjacent cross-covariances in branching and merging paths is load-bearing for the end-to-end log-det MI to equal the true I(source;sink); the manuscript supplies only agreement with water-filling on single-link cases and does not provide an independent derivation or exhaustive verification that all required covariances are assembled without omission or duplication when paths merge or branch.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major comment below, pointing to the existing support in the paper and indicating where revisions will strengthen clarity and verification.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'the same implementation reaches the classical water-filling optimum in the settings where it is available and yields MI improvements' is unsupported by any numerical results, tables, error metrics, or comparison data in the manuscript, so the accuracy of the K-recursion and the reported gains cannot be assessed.
Authors: Sections IV and V present the numerical results: single-link MIMO recovers the exact water-filling MI; the diamond DAG, two-hop AF relay, and 11-node network report optimized MI values with comparisons to baseline schemes showing gains. To address the concern about explicit support, we will add a summary table with quantitative MI values, error metrics, and direct comparisons in the revised manuscript. revision: yes
-
Referee: [Abstract] K-recursion (core ingredient described in Abstract): correctness for non-adjacent cross-covariances in branching and merging paths is load-bearing for the end-to-end log-det MI to equal the true I(source;sink); the manuscript supplies only agreement with water-filling on single-link cases and does not provide an independent derivation or exhaustive verification that all required covariances are assembled without omission or duplication when paths merge or branch.
Authors: Section III derives the K-recursion via induction on topological order, with explicit rules for propagating all pairwise covariances (including non-adjacent cross terms) to correctly handle branching and merging without omission or duplication. Single-link agreement is the base case; the multi-node experiments provide verification on branching topologies. We will add an appendix with a small branching-DAG example showing manual covariance computation versus the recursion output. revision: partial
Circularity Check
No circularity; forward recursion and AD are derived from model equations
full rationale
The paper defines the K-recursion directly from the linear Gaussian DAG covariance propagation rules (topological order, node-pair terms including non-adjacent), then applies standard reverse-mode AD to obtain gradients. No step reduces a claimed result to a fitted parameter, self-definition, or self-citation chain; the water-filling matches are presented as verification of the implemented recursion, not as its justification. The derivation chain remains independent of the target optima.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Mutual information between jointly Gaussian vectors equals (1/2) log det of the appropriate covariance ratio.
- standard math Reverse-mode automatic differentiation computes exact Wirtinger gradients of the log-det expression.
invented entities (1)
-
K-recursion
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Differentiable Conditional Mutual Information for Multi-Terminal Linear Gaussian Wireless Networks
Closed-form expression for conditional mutual information in linear Gaussian DAGs, constructed from AD primitives, enables gradient-based optimization of multi-terminal wireless rate regions.
Reference graph
Works this paper leans on
-
[1]
T. M. Cover and J. A. Thomas,Elements of Information Theory, 2nd ed. Hoboken, NJ: Wiley-Interscience, 2006
2006
-
[2]
P. J. Schreier and L. L. Scharf,Statistical Signal Processing of Complex-Valued Data: The Theory of Improper and Noncircular Signals. Cambridge, U.K.: Cambridge Univ. Press, 2010
2010
-
[3]
Tse and P
D. Tse and P. Viswanath,Fundamentals of Wireless Communication. Cambridge, U.K.: Cambridge Univ. Press, 2005
2005
-
[4]
El Gamal and Y .-H
A. El Gamal and Y .-H. Kim,Network Information Theory. Cambridge, U.K.: Cambridge Univ. Press, 2011
2011
-
[5]
T. Wadayama, “Information Gradient for Directed Acyclic Graphs: A Score-based Framework for End-to-End Mutual Information Maximiza- tion,” arXiv preprint arXiv:2601.01789, 2026
arXiv 2026
-
[6]
Gradient of mutual information in linear vector Gaussian channels,
D. P. Palomar and S. Verd ´u, “Gradient of mutual information in linear vector Gaussian channels,”IEEE Trans. Inf. Theory, vol. 52, no. 1, pp. 141–154, 2006
2006
-
[7]
Capacity of multi-antenna Gaussian channels,
˙I. E. Telatar, “Capacity of multi-antenna Gaussian channels,”Eur. Trans. Telecommun., vol. 10, no. 6, pp. 585–595, 1999
1999
-
[8]
Mutual information neural estimation,
M. I. Belghaziet al., “Mutual information neural estimation,” inProc. ICML, 2018, pp. 531–540
2018
-
[9]
Representation learning with contrastive predictive coding,
A. van den Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” arXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[10]
PyTorch: An imperative style, high-performance deep learning library,
A. Paszkeet al., “PyTorch: An imperative style, high-performance deep learning library,” inProc. NeurIPS, 2019, pp. 8024–8035
2019
-
[11]
Automatic differentiation in machine learning: a survey,
A. G. Baydin, B. A. Pearlmutter, A. A. Radul, and J. M. Siskind, “Automatic differentiation in machine learning: a survey,”J. Mach. Learn. Res., vol. 18, pp. 5595–5637, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.