How Small Can You Go? LoRA Fine-Tuning 270M-8B Models for Merchant Information Extraction in Financial Transactions
Pith reviewed 2026-06-27 19:40 UTC · model grok-4.3
The pith
Qwen 3.5 4B reaches 96.60% F1 on merchant extraction, within 0.35 points of the 8B baseline using half the parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
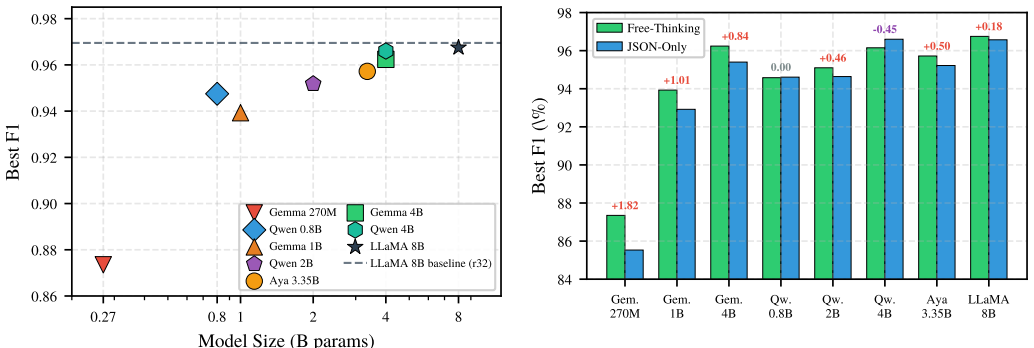
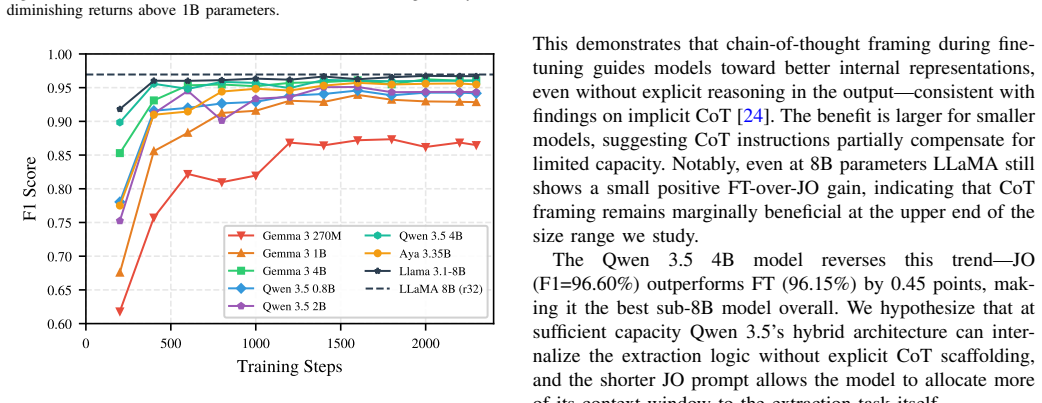
LoRA fine-tuning lets the Qwen 3.5 4B model reach 96.60% F1 with JSON-only prompting, compared with 96.95% for the LLaMA 3.1-8B baseline while using roughly half the parameters. The 0.8B Qwen model achieves 94.75% F1. Chain-of-thought fine-tuning raises scores by 0.3-1.8 points on most models but is not needed for the top Qwen performer. Think and Nothink training templates produce nearly identical results. When all 14 sub-8B models are deployed as serving endpoints, benchmark F1 transfers with an average change of only 0.8 points.
What carries the argument
LoRA fine-tuning of decoder-only models to emit structured JSON merchant fields directly from abbreviated transaction text.
If this is right
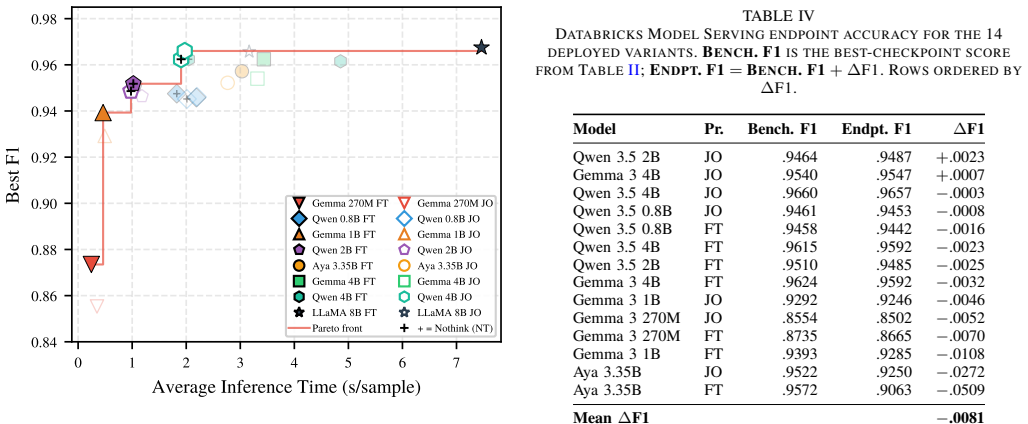
- Reproducing the 8B fine-tune at LoRA rank 8 yields 96.75% F1, only 0.20 points below the rank-32 baseline.
- The 0.8B Qwen model matches the accuracy of models 2.5-4 times larger while offering a better latency trade-off.
- Chain-of-thought fine-tuning improves most models but Qwen 3.5 4B performs best with direct JSON prompting.
- Qwen 3.5 Think and Nothink templates produce F1 differences below 0.004, showing explicit reasoning supervision is unnecessary.
- All deployed sub-8B models except Aya 3.35B maintain performance with an average 0.8-point change under serving conditions.
Where Pith is reading between the lines
- The same size-reduction pattern may apply to other fixed-output structured extraction tasks in finance or adjacent domains.
- Teams facing similar accuracy-versus-cost constraints could begin testing at the 4B scale rather than defaulting to 8B or larger.
- The negligible benefit from reasoning supervision suggests that for highly constrained output formats, simpler training objectives suffice.
Load-bearing premise
The dataset used to compute the reported F1 scores has the same distribution as live production transaction traffic.
What would settle it
A production deployment run on fresh live traffic that shows an average F1 drop larger than 2 points compared with the benchmark would falsify the transfer claim.
Figures
read the original abstract
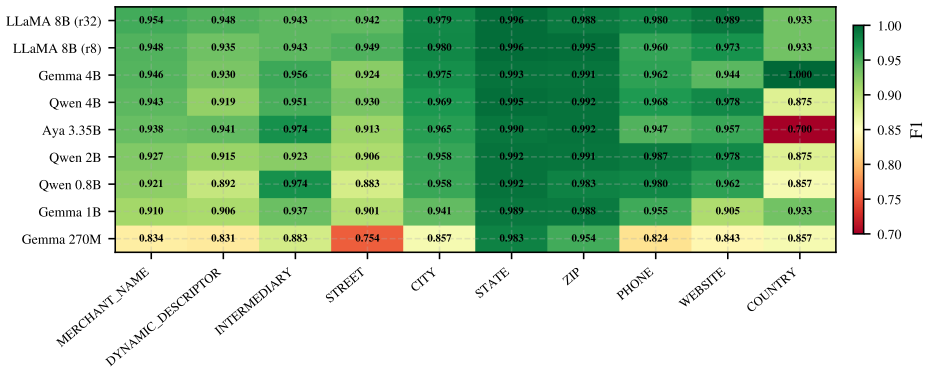
Financial transaction processing requires extracting structured merchant information from noisy, abbreviated bank transaction strings at scale. Our current production system, a LoRA-fine-tuned LLaMA 3.1-8B, achieves 96.95% F1 on this task, but deploying 8-billion-parameter models imposes prohibitive memory, latency, and cost constraints. To identify more efficient alternatives, we conduct a deployment-focused study of 24 model variants spanning four model families: Gemma 3 (270M, 1B, 4B), Qwen 3.5 (0.8B, 2B, 4B), Aya (3.35B), and LLaMA 3.1-8B, systematically evaluating accuracy, inference throughput, training cost, and hardware behavior to assess production suitability. Our findings show that: (1) reproducing the LLaMA 3.1-8B fine-tune with a LoRA rank of 8 achieves 96.75% F1, only 0.20 points below the rank-32 baseline; (2) Qwen 3.5 4B with JSON-only prompting reaches 96.60% F1, within 0.35 points of the 8B baseline while using roughly half the parameters; (3) the 0.8B Qwen 3.5 model achieves 94.75% F1, matching models 2.5-4x larger and offering an attractive latency-accuracy trade-off; (4) chain-of-thought fine-tuning generally improves F1 by 0.3-1.8 points across most models, although Qwen 3.5 4B performs best with direct JSON-only prompting; and (5) Qwen 3.5 Think and Nothink training templates produce nearly identical results (F1 differences <0.004), indicating that explicit reasoning supervision is unnecessary for structured extraction tasks. We further deploy all 14 fine-tuned sub-8B models as Databricks Model Serving endpoints and observe that benchmark performance transfers reliably to production, with an average F1 change of only 0.8 points. Aya 3.35B, based on the Cohere2 architecture, is the sole exception, exhibiting a 3-5 point decline under serving conditions. Based on these results, we provide deployment recommendations across accuracy and latency requirements, ...
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts a deployment-oriented empirical study of LoRA fine-tuning across 24 variants of models from 270M to 8B parameters (Gemma 3, Qwen 3.5, Aya, LLaMA 3.1) for structured merchant information extraction from noisy financial transaction strings. It reports F1 scores for different LoRA ranks, prompting strategies (JSON-only vs. chain-of-thought), and model sizes, shows that Qwen 3.5 4B reaches 96.60% F1 (vs. 96.95% for the 8B baseline), notes that explicit reasoning supervision adds little value, and validates transfer to production Databricks serving with an average 0.8-point F1 drop (Aya as outlier).
Significance. If the measurements hold, the work supplies concrete, production-validated guidance on accuracy-latency-cost trade-offs for financial NLP, demonstrating that sub-8B models can deliver near-baseline performance with lower resource demands; the inclusion of serving experiments that quantify distribution shift is a strength.
minor comments (3)
- [Methods] Abstract and methods: full training hyperparameters (learning rate, epochs, batch size) and exact train/validation/test split sizes or construction details are not provided; these should be added to support reproducibility of the reported F1 numbers.
- [Deployment experiments] Results: while aggregate serving F1 change is stated as 0.8 points, per-model serving F1 scores, throughput numbers, and hardware utilization metrics are not tabulated; a supplementary table would clarify the latency-accuracy recommendations.
- [Prompting variants] The statement that Qwen 3.5 Think and Nothink templates produce F1 differences <0.004 is given without the underlying per-model numbers or statistical test; including these values would strengthen the claim that explicit reasoning supervision is unnecessary.
Simulated Author's Rebuttal
We thank the referee for the positive review and recommendation to accept. The provided summary accurately reflects the manuscript's scope, methodology, and key empirical findings on model-size trade-offs for structured extraction in financial transactions.
Circularity Check
No significant circularity identified
full rationale
The paper contains no derivation chain, equations, or first-principles claims. All reported results consist of direct empirical F1 measurements obtained by fine-tuning models on training data and evaluating on held-out test data, followed by production serving experiments that measure actual performance drops. No parameters are fitted and then renamed as predictions, no self-citations supply load-bearing uniqueness theorems, and no ansatzes or renamings of known results are presented as novel derivations. The central claims (e.g., Qwen 3.5 4B reaching 96.60% F1) rest entirely on concrete experimental outcomes that remain falsifiable by re-running the same training and evaluation protocol.
Axiom & Free-Parameter Ledger
free parameters (1)
- LoRA rank =
8
axioms (1)
- domain assumption Pre-trained LLMs from the tested families can be adapted via LoRA for structured JSON extraction without task-specific architectural changes.
Forward citations
Cited by 1 Pith paper
-
TIGER: Inverting Transformer Gradients via Embedding-Subspace Distance Optimization
TIGER turns the low-rank attention gradient subspace into a differentiable objective for continuous embedding optimization, improving reconstruction quality and robustness over prior discrete token tests especially un...
Reference graph
Works this paper leans on
-
[1]
Financial natural language processing: A survey,
Z. Zhanget al., “Financial natural language processing: A survey,”ACM Computing Surveys, 2023
2023
-
[2]
A. Dubey, A. Jauhri, A. Pandeyet al., “The Llama 3 herd of models,” arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[3]
Energy and policy consid- erations for deep learning in NLP,
E. Strubell, A. Ganesh, and A. McCallum, “Energy and policy consid- erations for deep learning in NLP,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 3645–3650
2019
-
[4]
Gemma Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicova, A. Ramé, M. Rivièreet al., “Gemma 3 technical report,”arXiv preprint arXiv:2503.19786, 2025. [Online]. Available: https://arxiv.org/abs/2503.19786
Pith/arXiv arXiv 2025
-
[5]
Qwen3.5: Towards native multimodal agents,
Qwen Team, “Qwen3.5: Towards native multimodal agents,” Qwen blog, February 2026. [Online]. Available: https://qwen.ai/blog?id=qwen3.5
2026
-
[6]
Tiny Aya: Bridging scale and multilingual depth,
A. R. Salamanca, D. Abagyan, D. D’souza, A. Khairi, D. Mora, S. Dash, V . Aryabumi, S. Rajaee, M. Mofakhami, A. Sahuet al., “Tiny Aya: Bridging scale and multilingual depth,”arXiv preprint arXiv:2603.11510, 2026. [Online]. Available: https://arxiv.org/abs/2603. 11510
arXiv 2026
-
[7]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” in International Conference on Learning Representations, 2022. [Online]. Available: https://arxiv.org/abs/2106.09685
Pith/arXiv arXiv 2022
-
[8]
QLoRA: Efficient finetuning of quantized language models,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “QLoRA: Efficient finetuning of quantized language models,”Advances in Neural Information Processing Systems, vol. 36, 2023
2023
-
[9]
AdaLoRA: Adaptive budget allocation for parameter-efficient fine-tuning,
Q. Zhang, M. Chen, A. Bukharin, P. He, Y . Cheng, W. Chen, and T. Zhao, “AdaLoRA: Adaptive budget allocation for parameter-efficient fine-tuning,” inInternational Conference on Learning Representations,
-
[10]
Available: https://arxiv.org/abs/2303.10512
[Online]. Available: https://arxiv.org/abs/2303.10512
-
[11]
LlamaFactory: Unified efficient fine-tuning of 100+ language models,
Y . Zheng, R. Zhang, J. Zhang, Y . Ye, Z. Luo, Z. Ma, and Y . Ma, “LlamaFactory: Unified efficient fine-tuning of 100+ language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, 2024. [Online]. Available: https://arxiv.org/abs/2403.13372
Pith/arXiv arXiv 2024
-
[12]
Optimizing Chinese-to-English translation using large language models,
D. Huang and Z. Wang, “Optimizing Chinese-to-English translation using large language models,” inProc. 2025 IEEE Symposium on Computational Intelligence in Natural Language Processing and Social Media (CI-NLPSoMe Companion). Trondheim, Norway: IEEE, 2025
2025
-
[13]
Logical reasoning with LLMs via few-shot prompting and fine- tuning: A case study on turtle soup puzzles,
——, “Logical reasoning with LLMs via few-shot prompting and fine- tuning: A case study on turtle soup puzzles,” inProc. 2025 IEEE Sym- posium on Computational Intelligence in Natural Language Processing and Social Media (CI-NLPSoMe Companion). Trondheim, Norway: IEEE, 2025
2025
-
[14]
Phi-3 technical report: A highly capable language model locally on your phone,
M. Abdin, S. A. Jacobs, A. A. Awanet al., “Phi-3 technical report: A highly capable language model locally on your phone,”arXiv preprint arXiv:2404.14219, 2024
Pith/arXiv arXiv 2024
-
[15]
Mamba: Linear-time sequence modeling with selective state spaces,
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”arXiv preprint arXiv:2312.00752, 2023
Pith/arXiv arXiv 2023
-
[16]
T. Dao and A. Gu, “Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality,”arXiv preprint arXiv:2405.21060, 2024
Pith/arXiv arXiv 2024
-
[17]
Beyond task success: Measur- ing workflow fidelity in LLM-based agentic payment systems,
D. Huang, J. K. Chua, and Z. Wang, “Beyond task success: Measur- ing workflow fidelity in LLM-based agentic payment systems,”arXiv preprint arXiv:2605.06457, 2026
Pith/arXiv arXiv 2026
-
[18]
Neural architectures for named entity recognition,
G. Lample, M. Ballesteros, S. Subramanian, K. Kawakami, and C. Dyer, “Neural architectures for named entity recognition,” inProceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2016, pp. 260–270
2016
-
[19]
End-to-end sequence labeling via bi-directional LSTM-CNNs-CRF,
X. Ma and E. Hovy, “End-to-end sequence labeling via bi-directional LSTM-CNNs-CRF,” inProceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016, pp. 1064–1074
2016
-
[20]
GPT-NER: Named entity recognition via large language models,
S. Wang, X. Sun, X. Li, R. Ouyang, F. Wu, T. Zhang, J. Li, and G. Wang, “GPT-NER: Named entity recognition via large language models,”arXiv preprint arXiv:2304.10428, 2023
arXiv 2023
-
[21]
B. Li, G. Fang, Y . Yang, Q. Wang, W. Ye, W. Zhao, and S. Zhang, “Evaluating ChatGPT’s information extraction capabilities: An assess- ment of performance, explainability, calibration, and faithfulness,”arXiv preprint arXiv:2304.11633, 2023
arXiv 2023
-
[22]
When FLUE meets FLANG: Benchmarks and large pretrained language model for financial domain,
R. S. Shah, K. Chawla, D. Eidnaniet al., “When FLUE meets FLANG: Benchmarks and large pretrained language model for financial domain,” arXiv preprint arXiv:2211.00083, 2022
arXiv 2022
-
[23]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,”Advances in Neural Information Processing Systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[24]
Multimodal chain-of-thought reasoning in language models,
Z. Zhang, A. Zhang, M. Li, H. Zhao, G. Karypis, and A. Smola, “Multimodal chain-of-thought reasoning in language models,”arXiv preprint arXiv:2302.00923, 2023
Pith/arXiv arXiv 2023
-
[25]
From explicit CoT to implicit CoT: Learning to internalize CoT step by step,
Y . Deng, Y . Choi, and S. Shieber, “From explicit CoT to implicit CoT: Learning to internalize CoT step by step,”arXiv preprint arXiv:2405.14838, 2024. [Online]. Available: https://arxiv.org/abs/2405. 14838
Pith/arXiv arXiv 2024
-
[26]
HuggingFace’s Trans- formers: State-of-the-art natural language processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowiczet al., “HuggingFace’s Trans- formers: State-of-the-art natural language processing,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2020, pp. 38–45
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.