Look Less, Reason More: Block-wise Attention Skipping for Efficient Multimodal LLMs
Pith reviewed 2026-06-27 19:01 UTC · model grok-4.3
The pith
Visual attention in multimodal LLMs saturates early, so skipping deeper visual self-attention layers preserves performance while cutting computation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
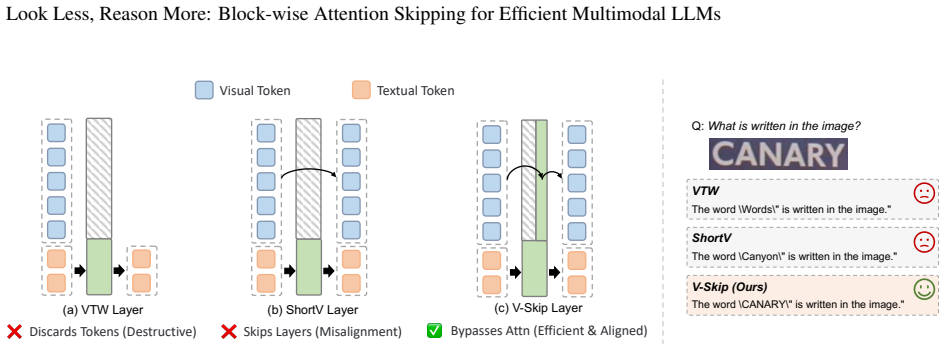
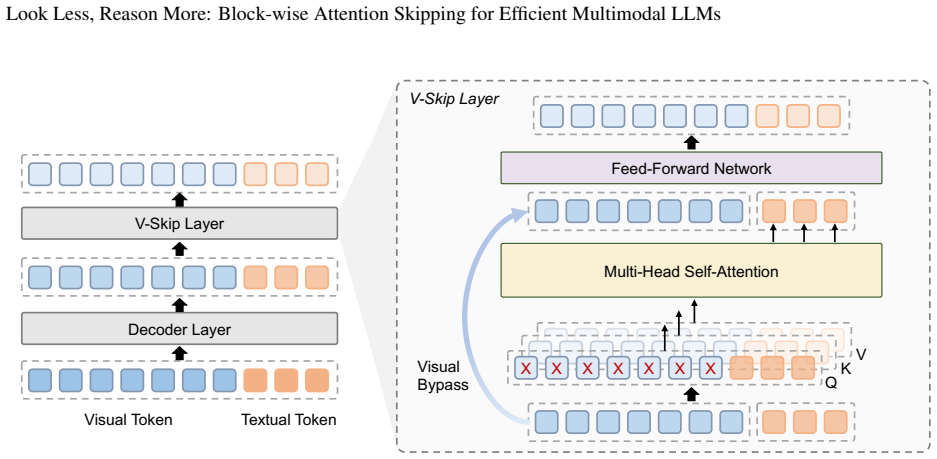
Visual tokens rapidly establish their spatial structure and intra-modal relationships in early layers, rendering visual-to-visual self-attention in deeper layers computationally redundant. Conversely, Feed-Forward Networks remain essential for projecting visual features into the evolving textual semantic space. V-Skip decouples spatial interaction from semantic evolution by selectively bypassing saturated visual self-attention modules in a block-wise manner, using few-shot calibration for task-optimal sparsity paths.
What carries the argument
V-Skip, a training-free inference paradigm that imposes block-wise structured sparsity on visual self-attention modules after they have saturated.
If this is right
- Computation cost of self-attention over long visual sequences is reduced by bypassing redundant modules.
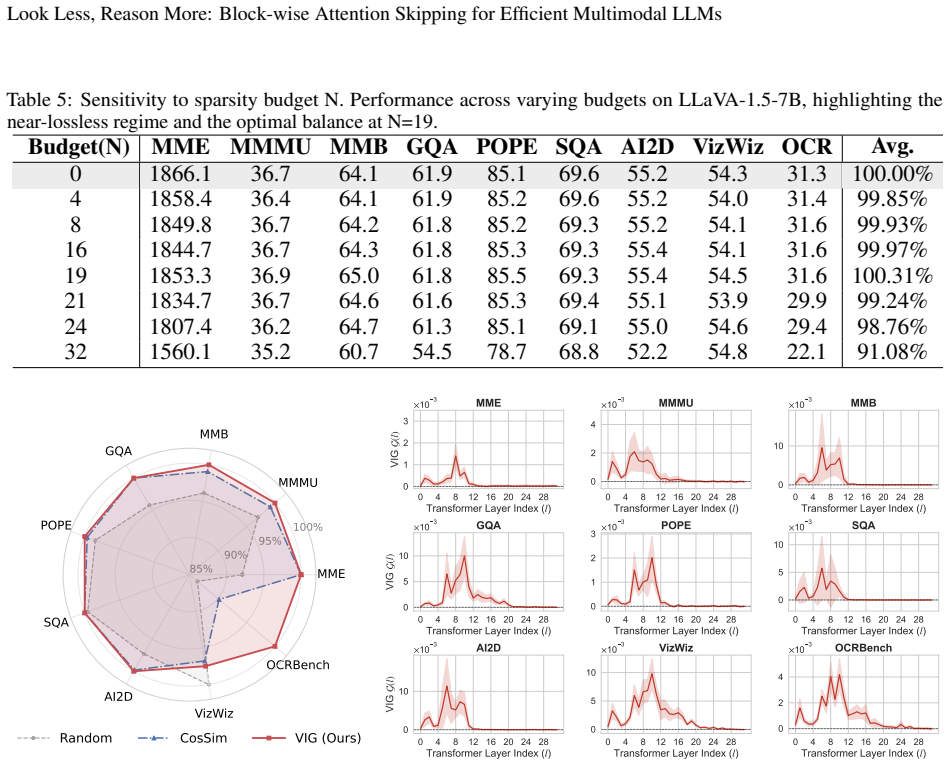
- Performance retention of 94.16% to 100.31% is achieved across diverse MLLMs.
- Spatial structure is handled early while semantic projection continues via FFNs.
- Task-specific sparsity paths can be selected dynamically without retraining.
- Models reason effectively by looking less at the right depths rather than discarding tokens.
Where Pith is reading between the lines
- Similar saturation patterns might exist in other transformer-based models beyond vision-language.
- This approach could be combined with token pruning methods for further efficiency gains.
- Hardware accelerators might benefit from conditional layer skipping logic.
- The finding challenges the assumption that all attention layers contribute equally to multimodal reasoning.
Load-bearing premise
That the saturation of visual attention is consistent enough across models and tasks that bypassing later modules loses no essential information for downstream performance.
What would settle it
Observing a significant performance drop on a visual reasoning benchmark when applying the block-wise skipping to a new MLLM architecture not tested in the paper.
Figures


read the original abstract
Multimodal Large Language Models (MLLMs) face a significant inference bottleneck due to the quadratic computational cost of self-attention over long visual token sequences. However, we identify a critical inefficiency in current architectures: Visual Attention Saturation. Our analysis reveals that visual tokens rapidly establish their spatial structure and intra-modal relationships in early layers, rendering visual-to-visual self-attention in deeper layers computationally redundant. Conversely, Feed-Forward Networks (FFNs) in these layers remain essential for projecting visual features into the evolving textual semantic space. Leveraging this insight, we present Visual-Skip (V-Skip), a training-free inference paradigm that decouples spatial interaction from semantic evolution. Rather than discarding tokens, V-Skip imposes block-wise structured sparsity by selectively bypassing saturated visual self-attention modules. Furthermore, recognizing that varying downstream tasks demand distinct reasoning depths, V-Skip employs a lightweight, few-shot calibration to dynamically route the task-optimal sparsity path. Extensive experiments demonstrate that V-Skip effectively bypasses redundant vision attention to achieve block-wise sparsity, maintaining a 94.16% to 100.31% performance retention across diverse MLLMs. Ultimately, we prove that to reason more effectively, models do not need to discard what they see -- they simply need to "look less" at the right depth.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that visual tokens in MLLMs rapidly establish their spatial structure and intra-modal relationships in early layers, rendering visual-to-visual self-attention in deeper layers redundant while FFNs remain essential for semantic projection. It introduces V-Skip, a training-free inference paradigm that imposes block-wise structured sparsity by bypassing saturated visual self-attention modules, with a lightweight few-shot calibration to select task-optimal sparsity paths, achieving 94.16% to 100.31% performance retention across diverse MLLMs.
Significance. If the empirical observations and retention results hold under rigorous testing, this could enable substantial inference efficiency gains in multimodal LLMs by exploiting attention saturation without discarding tokens or requiring retraining. The training-free nature and dynamic task-specific routing represent practical strengths for deployment.
major comments (1)
- [Abstract] Abstract: the central claim of 94.16% to 100.31% performance retention is presented without any experimental details, error bars, ablation tables, or verification of the saturation observation, which is load-bearing for the assertion that later visual self-attention is redundant and FFNs alone suffice.
minor comments (1)
- [Abstract] Abstract: the final sentence uses rhetorical phrasing ('we prove that... they simply need to "look less"') that could be revised for a more measured, technical tone.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and for highlighting the need for clarity on how the abstract's claims are supported. We address the single major comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 94.16% to 100.31% performance retention is presented without any experimental details, error bars, ablation tables, or verification of the saturation observation, which is load-bearing for the assertion that later visual self-attention is redundant and FFNs alone suffice.
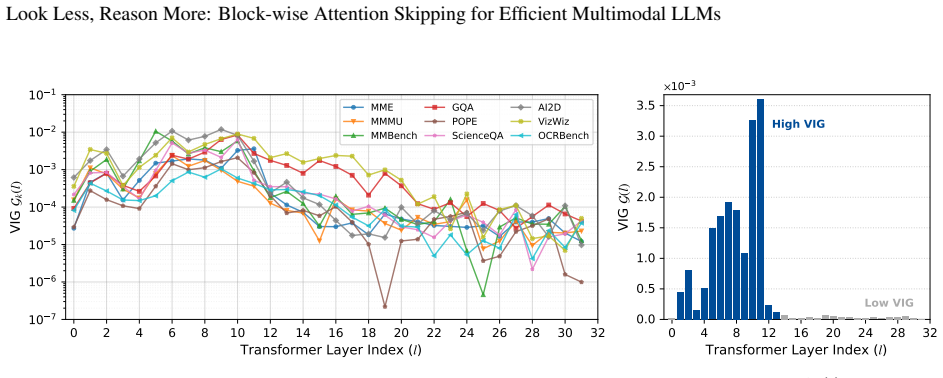
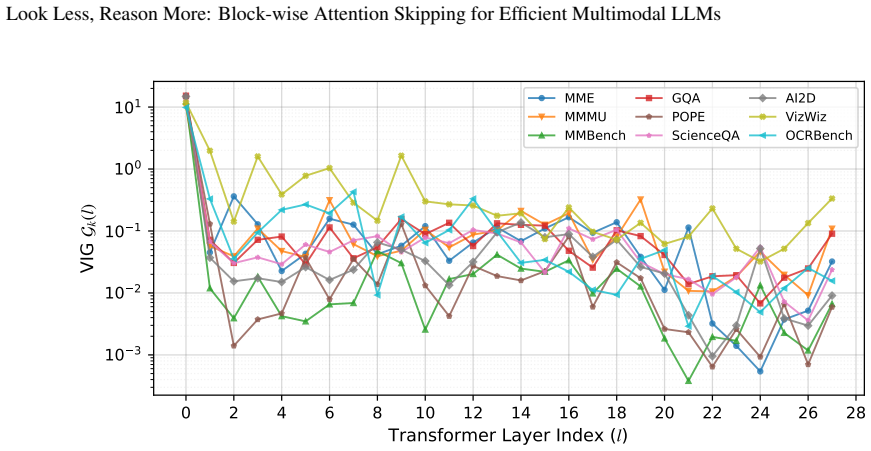
Authors: We agree that the abstract itself contains no experimental details, error bars, ablation tables, or direct verification, as abstracts are space-constrained summaries. The saturation observation (rapid establishment of spatial structure in early layers) is verified in Section 3.1 via layer-wise attention similarity metrics and visualizations (Figure 2), showing >0.95 cosine similarity in deeper layers for visual self-attention. The 94.16-100.31% retention is substantiated in Section 4 with full experimental details: per-model results on LLaVA-1.5, Qwen-VL, and others across VQA, captioning, and reasoning benchmarks (Tables 1-3), using the few-shot calibration procedure described in Section 3.3. No error bars appear because inference is deterministic after calibration; ablations on block sizes and task-specific paths are in Section 4.3. The manuscript body therefore supplies the required verification, and we do not believe the abstract requires modification to remain within standard length and style. revision: no
Circularity Check
No significant circularity; derivation rests on empirical observation and external validation
full rationale
The paper's central claim rests on an empirical analysis of attention patterns across layers, followed by a training-free bypass method whose performance is measured via direct experiments on multiple MLLMs (94.16–100.31% retention). No equation reduces a prediction to a fitted parameter by construction, no uniqueness theorem is imported from self-citation, and the few-shot calibration is presented as a lightweight routing step rather than a self-referential fit. The derivation chain is therefore self-contained against the reported benchmarks and does not collapse to its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- task-optimal sparsity path
axioms (1)
- domain assumption Visual tokens establish spatial structure and intra-modal relationships in early layers
Forward citations
Cited by 1 Pith paper
-
Attend, Transform, or Silence: Operator-Level Visual Skipping for Efficient Multimodal LLM Inference
The paper proposes an operator-level visual-token skipping framework for MLLMs that reduces TFLOPs by 33.7% on Qwen3-VL while retaining 99.5% performance across VQA benchmarks.
Reference graph
Works this paper leans on
-
[1]
Visual instruction tuning.ArXiv, abs/2304.08485, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.ArXiv, abs/2304.08485, 2023
Pith/arXiv arXiv 2023
-
[2]
Improved baselines with visual instruction tuning.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26286–26296, 2023
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26286–26296, 2023
2024
-
[3]
Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
2024
-
[4]
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Chunsheng Wu, Huajie Tan, Chunyuan Li, Jing Yang, Jie Yu, Xiyao Wang, Bin Qin, Yumeng Wang, Zizhen Yan, Ziyong Feng, Ziwei Liu, Bo Li, and Jiankang Deng. Llava-onevision-1.5: Fully open framework for democratized multimodal training.CoRR, abs/...
Pith/arXiv arXiv 2025
-
[5]
Deepseek-v3 technical report, 2025
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, and et al. Deepseek-v3 technical report, 2025
2025
-
[6]
Qwen2.5-vl technical report.CoRR, abs/2502.13923, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Ming-Hsuan Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report...
Pith/arXiv arXiv 2025
-
[7]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, and et al. Qwen3 technical report, 2025
2025
-
[8]
Boosting multimodal large language models with visual tokens withdrawal for rapid inference
Zhihang Lin, Mingbao Lin, Luxi Lin, and Rongrong Ji. Boosting multimodal large language models with visual tokens withdrawal for rapid inference. In Toby Walsh, Julie Shah, and Zico Kolter, editors,AAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA, pages 5334–5342. AAAI...
2025
-
[9]
Qianhao Yuan, Qingyu Zhang, Yanjiang Liu, Jiawei Chen, Yaojie Lu, Hongyu Lin, Jia Zheng, Xianpei Han, and Le Sun. Shortv: Efficient multimodal large language models by freezing visual tokens in ineffective layers.CoRR, abs/2504.00502, 2025
arXiv 2025
-
[10]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In European Conference on Computer Vision, 2024
2024
-
[11]
Long Xing, Qidong Huang, Xiao wen Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, and Dahua Lin. Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction.Computer Vision and Pattern Recognition Conference, abs/2410.17247, 2025
Pith/arXiv arXiv 2025
-
[12]
Sparsevlm: Visual token sparsification for efficient vision-language model inference
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. Sparsevlm: Visual token sparsification for efficient vision-language model inference. InInternational Conference on Machine Learning, 2025
2025
-
[13]
Qizhe Zhang, Aosong Cheng, Ming Lu, Renrui Zhang, Zhiyong Zhuo, Jiajun Cao, Shaobo Guo, Qi She, and Shanghang Zhang. Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms.arXiv preprint arXiv:2412.01818, 2025
arXiv 2025
-
[14]
Token merging: Your vit but faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023
2023
-
[15]
How multimodal llms solve image tasks: A lens on visual grounding, task reasoning, and answer decoding
Zhuoran Yu and Yong Jae Lee. How multimodal llms solve image tasks: A lens on visual grounding, task reasoning, and answer decoding. 2025
2025
-
[16]
Constantin Venhoff, Ashkan Khakzar, Sonia Joseph, Philip Torr, and Neel Nanda. How visual representations map to language feature space in multimodal llms.CoRR, abs/2506.11976, 2025
arXiv 2025
-
[17]
GPT-4 technical report.CoRR, abs/2303.08774, 2023
OpenAI. GPT-4 technical report.CoRR, abs/2303.08774, 2023
Pith/arXiv arXiv 2023
-
[18]
Gemini: A family of highly capable multimodal models.CoRR, abs/2312.11805, 2023
Gemini Team. Gemini: A family of highly capable multimodal models.CoRR, abs/2312.11805, 2023. 11 Look Less, Reason More: Block-wise Attention Skipping for Efficient Multimodal LLMs
Pith/arXiv arXiv 2023
-
[19]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In9th International Conference on Learning Representations, ICLR 2021, V...
2021
-
[20]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 19792–19802. Computer Vision Foundation / IEEE, 2025
2025
-
[21]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors,Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 Novem...
2021
-
[22]
How contextual are contextualized word representations? comparing the geometry of bert, elmo, and GPT-2 embeddings
Kawin Ethayarajh. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and GPT-2 embeddings. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Process...
2019
-
[23]
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Zhenyu Qiu, Wei Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, and Rongrong Ji. MME: A comprehensive evaluation benchmark for multimodal large language models.CoRR, abs/2306.13394, 2023
Pith/arXiv arXiv 2023
-
[24]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. Mmbench: Is your multi-modal model an all-around player? In Ales Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors,Computer Vision - ECCV 2024 - 18th European Confere...
2024
-
[25]
MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for expert AGI
Xiang Yue, Yuansheng Ni, Tianyu Zheng, Kai Zhang, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for exp...
2024
-
[26]
Hudson and Christopher D
Drew A. Hudson and Christopher D. Manning. GQA: A new dataset for real-world visual reasoning and compositional question answering. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pages 6700–6709. Computer Vision Foundation / IEEE, 2019
2019
-
[27]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: ...
2022
-
[28]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 292–305. Association fo...
2023
-
[29]
A diagram is worth a dozen images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Min Joon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. In Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, editors,Computer Vision - ECCV 2016 - 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part IV, volume 9908 ofLecture Notes in ...
2016
-
[30]
Bigham, Chandrika Jayant, Hanjie Ji, Greg Little, Andrew Miller, Robert C
Jeffrey P. Bigham, Chandrika Jayant, Hanjie Ji, Greg Little, Andrew Miller, Robert C. Miller, Robin Miller, Aubrey Tatarowicz, Brandyn White, Samuel White, and Tom Yeh. Vizwiz: nearly real-time answers to visual questions. In Ken Perlin, Mary Czerwinski, and Rob Miller, editors,Proceedings of the 23rd Annual ACM Symposium on User Interface Software and Te...
2010
-
[31]
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. Ocrbench: on the hidden mystery of OCR in large multimodal models.Sci. China Inf. Sci., 67(12), 2024. 12 Look Less, Reason More: Block-wise Attention Skipping for Efficient Multimodal LLMs A More Implementation Details A.1 Deta...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.