SpectrumKV: Per-Token Mixed-Precision KV Cache Transfer for Prefill-Decode Disaggregated LLM Serving
Pith reviewed 2026-06-27 18:49 UTC · model grok-4.3
The pith
SpectrumKV assigns three precision levels to each KV token during transfer instead of binary keep-or-drop, preserving quality at the same network budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
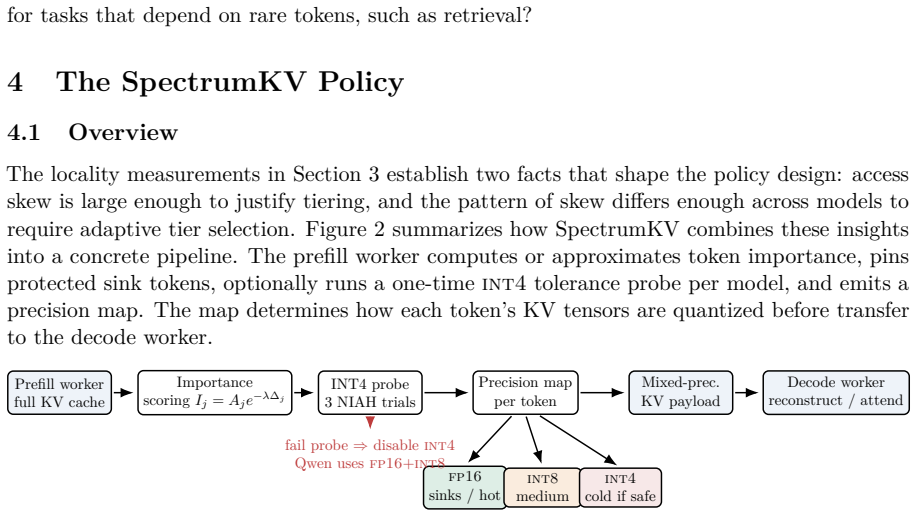
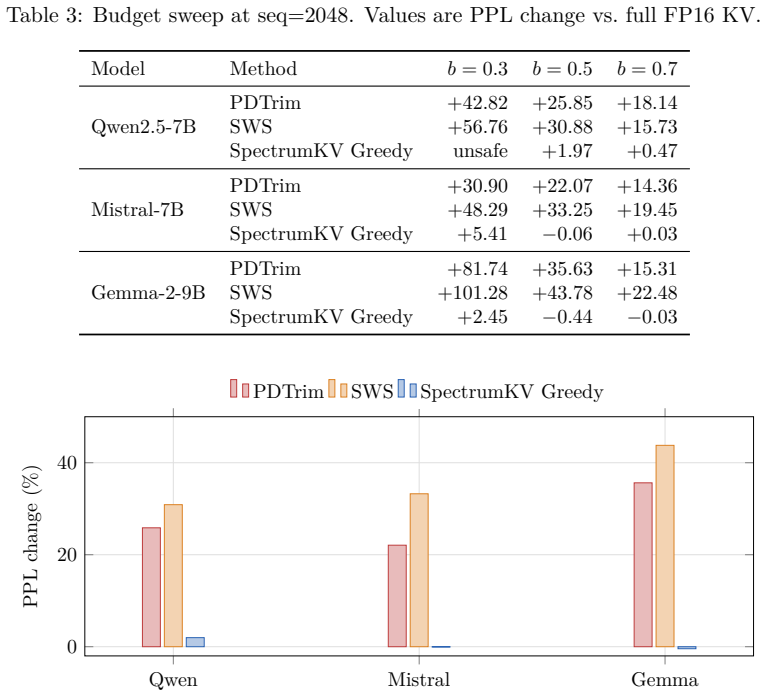
SpectrumKV assigns FP16 to attention sinks and other high-importance tokens, INT8 to medium-importance tokens, and INT4 to low-importance tokens when the model passes a three-trial NIAH probe; models that fail the probe fall back to FP16 plus INT8. Across Qwen2.5-7B, Mistral-7B, and Gemma-2-9B this three-tier (or two-tier) policy produces far smaller quality loss than binary token pruning at identical normalized KV budgets.
What carries the argument
The three-tier per-token precision policy (FP16/INT8/INT4) gated by a lightweight deployment-time NIAH probe that decides whether INT4 is safe for a given model.
If this is right
- At 50 percent normalized KV budget, perplexity change stays near zero or single-digit percent on WikiText-2 while binary methods exceed 20 percent.
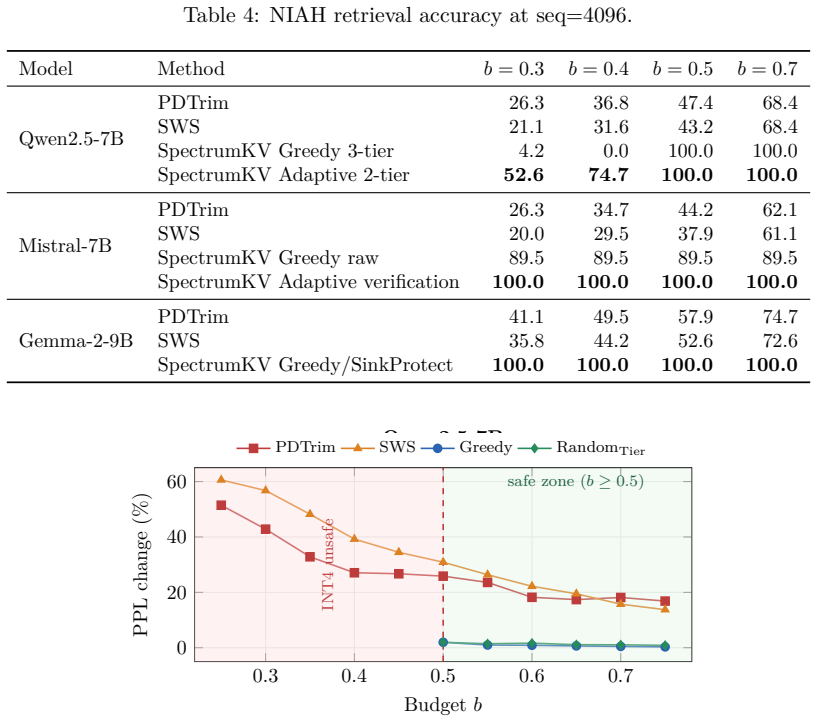
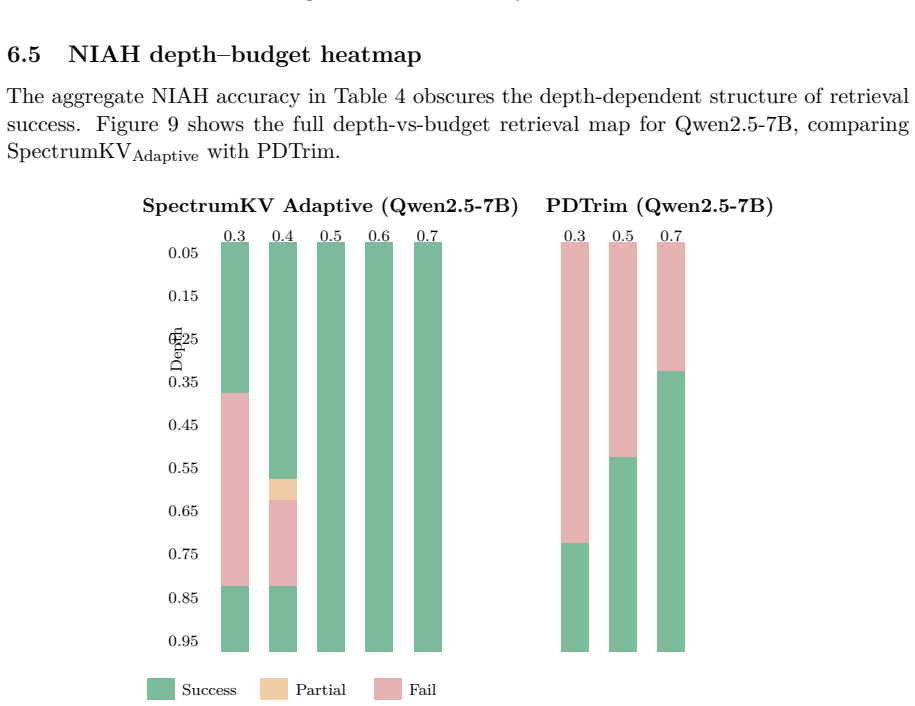
- Needle-in-a-haystack retrieval at b=0.3 reaches 52.6 percent on Qwen versus 26.3 percent for binary selection.
- Models that pass the probe achieve the full three-tier benefit; others safely fall back to two tiers without manual intervention.
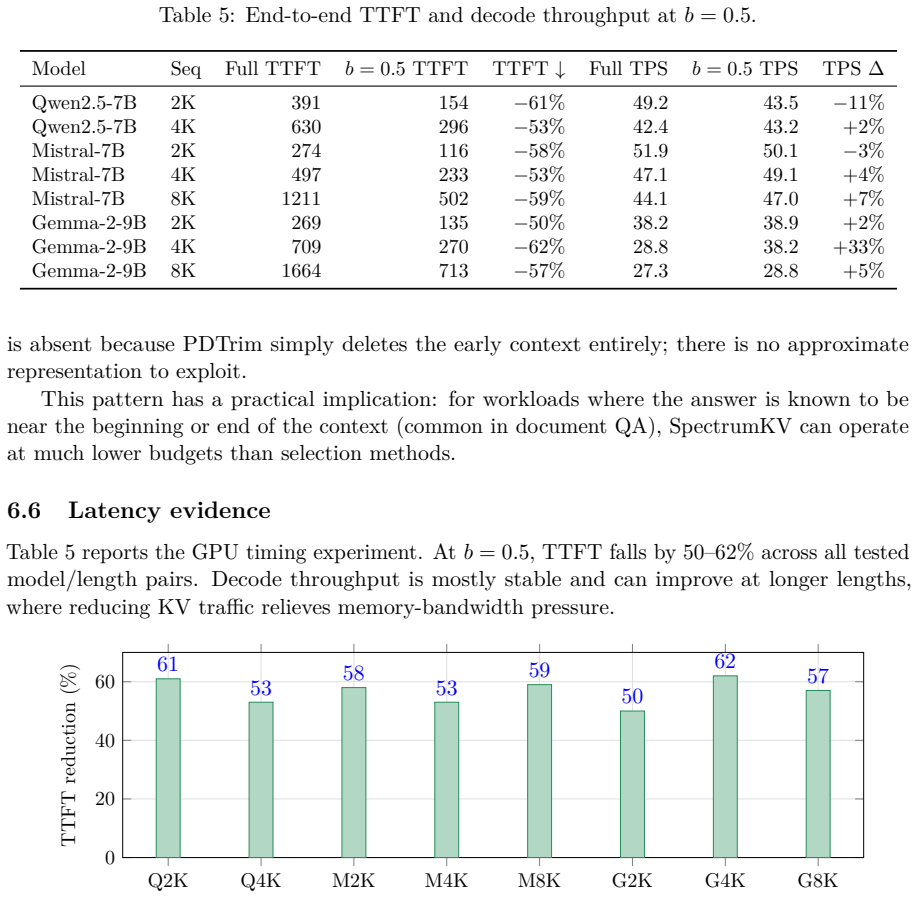
- Measured transfer-path timing shows 50-62 percent TTFT reduction at b=0.5.
Where Pith is reading between the lines
- The probe approach could be extended to other quantization bit-widths or to dynamic importance scoring beyond the paper's attention-sink heuristic.
- Production serving systems could run the probe once per model version and cache the resulting tier policy for all subsequent requests.
- The same per-token precision idea might apply to activations or weights transferred between prefill and decode nodes.
Load-bearing premise
A short three-trial NIAH probe run at deployment time can reliably detect whether a model will tolerate INT4 KV quantization without later catastrophic failure.
What would settle it
A model that passes the three-trial probe yet exhibits a large quality drop (for example, perplexity rise exceeding 10 percent) when the three-tier policy is applied on WikiText-2 or NIAH at the same budget used in the paper.
Figures







read the original abstract
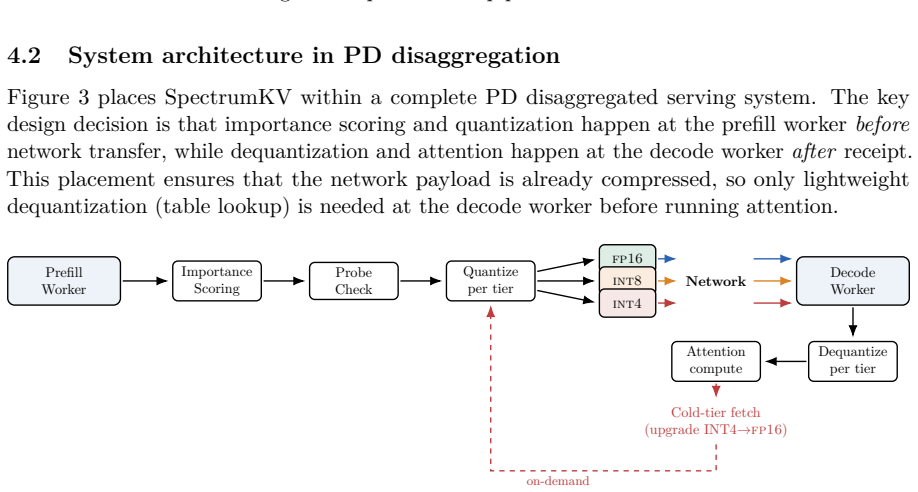
Prefill-decode (PD) disaggregation decouples prompt processing from token generation, but it also turns the key-value (KV) cache into a network payload. Existing PD-side KV reduction methods are mostly binary: selected tokens are transmitted at full precision and the rest are not transmitted. This paper argues that binary selection leaves a useful design space unused. SpectrumKV assigns a precision level to each token instead: attention sinks and other high-importance tokens are protected at FP16, medium-importance tokens are sent at INT8, and low-importance tokens are sent at INT4 when the model can tolerate it. The main practical complication is that INT4 tolerance is model-dependent. Qwen2.5-7B catastrophically fails under INT4 KV quantization, while Mistral-7B and Gemma-2-9B remain stable. SpectrumKV therefore runs a lightweight deployment-time probe: three aggressive NIAH trials under a 3-tier policy. Models that pass use FP16+INT8+INT4; models that fail fall back to FP16+INT8. Across Qwen2.5-7B-Instruct, Mistral-7B-Instruct-v0.3, and Gemma-2-9B-it, SpectrumKV improves quality at the same transfer budget. At a 50% normalized KV budget on WikiText-2, SpectrumKV changes perplexity by +1.97%,-0.06%, and-0.44%, respectively, compared with PDTrim's +25.85%, +22.07%, and +35.63%. On NIAH retrieval at 4096 tokens, the adaptive policy reaches 52.6% on Qwen at the aggressive b=0.3 budget versus 26.3% for PDTrim, and reaches 100% by b=0.5; Mistral and Gemma preserve retrieval under the 3-tier policy. End-to-end GPU timing of the transfer path shows 50-62% TTFT reductions at b=0.5. These results suggest that PD KV transfer should be treated as a precision-allocation problem, not only as token pruning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SpectrumKV for prefill-decode disaggregated LLM serving, replacing binary KV token selection with per-token mixed-precision transfer: high-importance tokens (attention sinks) at FP16, medium at INT8, and low at INT4 when the model tolerates it. A lightweight deployment-time probe of three aggressive NIAH trials decides whether to enable the 3-tier (FP16+INT8+INT4) policy or fall back to FP16+INT8. On Qwen2.5-7B-Instruct, Mistral-7B-Instruct-v0.3, and Gemma-2-9B-it, SpectrumKV reports better perplexity on WikiText-2 at 50% normalized KV budget (+1.97%, -0.06%, -0.44% vs. PDTrim's +25.85%, +22.07%, +35.63%) and higher NIAH accuracy at b=0.3 (52.6% vs. 26.3% on Qwen), with 50-62% TTFT reductions at b=0.5.
Significance. If the central empirical claims hold, the work reframes PD KV transfer as a precision-allocation problem rather than pure token pruning, enabling higher quality at fixed transfer budgets. The model-dependent INT4 tolerance observation and the probe-based adaptive policy are novel contributions. The end-to-end GPU timing results provide practical evidence of latency benefits. No machine-checked proofs or parameter-free derivations are present; the strength lies in the multi-model empirical evaluation.
major comments (2)
- [Abstract (deployment-time probe description)] The deployment-time probe (three aggressive NIAH trials) is load-bearing for the adaptive policy, yet the manuscript provides no cross-task validation that passing NIAH guarantees stability on non-retrieval workloads such as long-context reasoning, code generation, or math where KV quantization noise may accumulate differently. The abstract states Qwen2.5-7B fails catastrophically under INT4 while Mistral/Gemma do not, but only NIAH and WikiText-2 results are reported.
- [Abstract (quantitative results)] No details are supplied on the method for computing per-token importance scores that determine the FP16/INT8/INT4 tier assignment, the exact experimental controls (e.g., how the 50% normalized KV budget is enforced), or statistical significance of the reported perplexity deltas. These omissions prevent verification of the central claim that mixed-precision outperforms binary selection at the same budget.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below.
read point-by-point responses
-
Referee: [Abstract (deployment-time probe description)] The deployment-time probe (three aggressive NIAH trials) is load-bearing for the adaptive policy, yet the manuscript provides no cross-task validation that passing NIAH guarantees stability on non-retrieval workloads such as long-context reasoning, code generation, or math where KV quantization noise may accumulate differently. The abstract states Qwen2.5-7B fails catastrophically under INT4 while Mistral/Gemma do not, but only NIAH and WikiText-2 results are reported.
Authors: The probe uses aggressive NIAH trials specifically to detect catastrophic INT4 failure modes, as NIAH is a standard and sensitive test for KV cache fidelity in retrieval. WikiText-2 serves as a general perplexity check. We agree that the probe's behavior on code generation, math, or other reasoning tasks is not directly validated in the current experiments and will add an explicit limitations paragraph discussing this scope in the revision. revision: partial
-
Referee: [Abstract (quantitative results)] No details are supplied on the method for computing per-token importance scores that determine the FP16/INT8/INT4 tier assignment, the exact experimental controls (e.g., how the 50% normalized KV budget is enforced), or statistical significance of the reported perplexity deltas. These omissions prevent verification of the central claim that mixed-precision outperforms binary selection at the same budget.
Authors: We will expand the abstract and methods section to include these details. Per-token importance is computed from aggregated attention scores (detailed in Section 3); the normalized budget is met by sorting tokens by importance and greedily assigning the highest feasible precision tier until the exact budget is reached. We will also report standard deviations across multiple runs to support the perplexity deltas. revision: yes
- Empirical cross-task validation of the NIAH-based probe on non-retrieval workloads (code generation, math, long-context reasoning) beyond the reported NIAH and WikiText-2 results.
Circularity Check
No circularity; purely empirical evaluation with no derivations or self-referential reductions
full rationale
The paper presents SpectrumKV as an empirical system: a deployment-time NIAH probe decides between 3-tier (FP16/INT8/INT4) and 2-tier (FP16/INT8) policies, with quality measured directly on WikiText-2 perplexity and NIAH accuracy at given budgets. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Claims reduce to observed benchmark deltas (e.g., +1.97% vs +25.85% perplexity change) rather than any definitional or constructional equivalence. This is the expected non-finding for a systems/empirical paper without mathematical derivations.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Can I Buy Your KV Cache?
Proposes an agent-native prefill CDN where precomputed KV caches are hosted and sold to agents, delivering 9-50x compute savings with exact token and logit matching on Qwen3-4B.
Reference graph
Works this paper leans on
-
[1]
Zefan Cai et al. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling.arXiv preprint arXiv:2406.02069, 2024
Pith/arXiv arXiv 2024
-
[2]
QuIP: 2-bit quantization of large language models with guarantees
Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher De Sa. QuIP: 2-bit quantization of large language models with guarantees. InAdvances in Neural Information Processing Systems, 2023
2023
-
[3]
Peter J. Denning. The working set model for program behavior.Communications of the ACM, 11(5):323–333, 1968
1968
-
[4]
GPTQ: Accurate post- training quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post- training quantization for generative pre-trained transformers. InInternational Conference on Learning Representations, 2023
2023
-
[5]
Yipin Guo and Siddharth Joshi. SplitZip: Ultra fast lossless KV compression for disaggre- gated LLM serving.arXiv preprint arXiv:2605.01708, 2025
Pith/arXiv arXiv 2025
-
[6]
Kvquant: Towards 10 million context length llm inference with kv cache quantization
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Hasan Genc, Kurt Keutzer, and Amir Gholami. Kvquant: Towards 10 million context length llm inference with kv cache quantization. InAdvances in Neural Information Processing Systems, 2024
2024
-
[7]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention.arXiv preprint arXiv:2309.06180, 2023
Pith/arXiv arXiv 2023
-
[8]
Yichao Li et al. Flowkv: A disaggregated inference framework with low-latency kv cache transfer and load-aware scheduling.arXiv preprint arXiv:2504.03775, 2025
arXiv 2025
-
[9]
Snapkv: LLM knows what you are looking for before generation
Yuhong Li et al. Snapkv: LLM knows what you are looking for before generation. In Advances in Neural Information Processing Systems, 2024
2024
-
[10]
Huan Liu et al. KVServe: Service-aware kv cache compression for communication-efficient disaggregated LLM serving.arXiv preprint arXiv:2605.13734, 2026
Pith/arXiv arXiv 2026
-
[11]
Kivi: A tuning-free asymmetric 2bit quantization for kv cache
Zirui Liu, Jiayi Zhao, Wenxuan Yao, Shijie Cheng, Yucheng Li, Zhe Liang, Jiarong Luo, Xiaodong Wang, Quanquan Gu, Xuehai Li, Yuxuan Liu, Yuandong Wang, and Beidi Chen. Kivi: A tuning-free asymmetric 2bit quantization for kv cache. InInternational Conference on Machine Learning, 2024
2024
-
[12]
LMCache: KV cache offloading for vLLM.arXiv preprint arXiv:2504.02257, 2025
LMCache Team. LMCache: KV cache offloading for vLLM.arXiv preprint arXiv:2504.02257, 2025
arXiv 2025
-
[13]
OrbitFlow: SLO-aware long-context LLM serving with fine-grained KV cache reconfiguration.Proceedings of the VLDB Endowment, 19:1046–1060, 2026
Xinyu Ma et al. OrbitFlow: SLO-aware long-context LLM serving with fine-grained KV cache reconfiguration.Proceedings of the VLDB Endowment, 19:1046–1060, 2026
2026
-
[14]
NVIDIA Dynamo: Multi-level KV cache management for LLM serving.NVIDIA Technical Blog, 2025.https://developer.nvidia.com/blog/tag/dynamo/
NVIDIA. NVIDIA Dynamo: Multi-level KV cache management for LLM serving.NVIDIA Technical Blog, 2025.https://developer.nvidia.com/blog/tag/dynamo/. 24
2025
-
[15]
Splitwise: Efficient generative llm inference using phase splitting
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Inigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting. InProceedings of the International Symposium on Computer Architecture, 2024
2024
-
[16]
Rui Qin, Zhaozhuo Li, Weiran He, Ming Zhang, Yongwei Wu, Weimin Zheng, and Xiaowen Xu. Mooncake: A KVCache-centric disaggregated architecture for LLM serving.arXiv preprint arXiv:2407.00079, 2024
arXiv 2024
-
[17]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InInternational Conference on Learning Representations, 2024
2024
-
[18]
Yihong Yao et al. Cacheblend: Fast large language model serving for rag with cached knowledge fusion.arXiv preprint arXiv:2405.16444, 2024
arXiv 2024
-
[19]
Hao Zhang, Mengsi Lyu, Yulong Ao, and Yonghua Lin. Enhancing llm efficiency: Targeted pruning for prefill-decode disaggregation in inference.arXiv preprint arXiv:2509.04467, 2025
arXiv 2025
-
[20]
H2O: Heavy-hitter oracle for efficient generative inference of large language models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Re, Clark Barrett, Zhangyang Wang, and Beidi Chen. H2O: Heavy-hitter oracle for efficient generative inference of large language models. In Advances in Neural Information Processing Systems, 2023
2023
-
[21]
Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jian Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving. InProceedings of the USENIX Symposium on Operating Systems Design and Implementation, 2024
2024
-
[22]
Yuxuan Zhou et al. Dynamickv: Task-aware adaptive kv cache compression for long context llms.arXiv preprint arXiv:2412.14838, 2024. A Decay-Rate Sweep The decay-rate sweep in Table 15 comes from the simulation-v3 scan rather than the main GPU PPL suite. It is included as an auxiliary sensitivity result. Larger decay rates help Mistral and Gemma in this sw...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.