Segment and Select: Vision-Language Segmentation in 3D Scenarios
Pith reviewed 2026-06-27 13:42 UTC · model grok-4.3
The pith
SEGA3D segments 3D objects from language by selecting fine-grained mask candidates without superpoints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
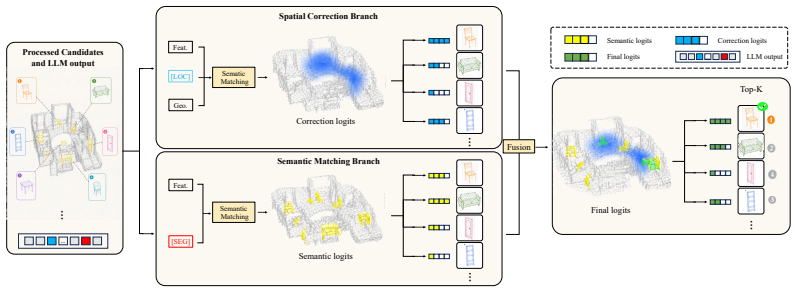
Our SEGA3D paradigm directly operates on the fine-grained visual information and is free from the superpoint dependency. Specifically, we first leverage a mask candidate generator to provide fine-grained categorical mask candidates, substantially improving the quality of candidate masks over the superpoint counterparts. Then, a Large Language Model (LLM) is utilized to generate the semantic and spatial information based on the linguistic description and visual features. The LLM output and visual features are fed to the Semantic-Spatial Selector (SSS) to produce the top-ranking mask candidates. Eventually, the Loopback Verification Module (LVM) is designed to yield the segmentation mask from
What carries the argument
The mask candidate generator providing fine-grained categorical mask candidates, which substantially improves quality over superpoint counterparts, along with the Semantic-Spatial Selector and Loopback Verification Module.
If this is right
- Yields segmentation masks with improved quality and fewer messy boundaries.
- Achieves higher mIoU scores on ScanNet and Matterport3D than prior superpoint-based approaches.
- Allows incorporation of both semantic and spatial information from the query via the LLM.
- Enables direct use of fine-grained visual features without superpoint coarsening.
Where Pith is reading between the lines
- If the mask candidate generator can be made even more accurate, segmentation performance could improve further on complex scenes.
- This selection-based approach might inspire similar methods in 2D vision-language tasks.
- The reliance on LLM could be tested for handling more ambiguous or complex language instructions.
Load-bearing premise
The mask candidate generator produces substantially higher-quality categorical mask candidates than superpoint-based methods, which is presented as the key enabler of the reported performance gains.
What would settle it
A direct comparison of mask quality metrics showing the generator does not produce substantially better candidates than superpoint methods, or ablation results where performance gains vanish when swapping the generator, would falsify the central claim.
Figures




read the original abstract
3D vision-language segmentation aims to segment target objects in 3D scenarios according to the linguistic instructions and visual observations. Prior art heavily relies on the coarse superpoint representation to reduce the computation complexity, which suffers from poor segmentation quality and messy object boundaries. In this paper, we propose the SEGment-And-select (SEGA3D) paradigm for 3D visionlanguage segmentation that directly operates on the fine-grained visual information and is free from the superpoint dependency. Specifically, we first leverage a mask candidate generator to provide fine-grained categorical mask candidates, substantially improving the quality of candidate masks over the superpoint counterparts. Then, a Large Language Model (LLM) is utilized to generate the semantic and spatial information based on the linguistic description and visual features. The LLM output and visual features are fed to the Semantic-Spatial Selector (SSS) to produce the top-ranking mask candidates. Eventually, the Loopback Verification Module (LVM) is designed to yield the segmentation mask from the selected candidate masks. Our SEGA3D attains competitive performance on ScanRefer, ScanNet and Matterport3D benchmarks. Notably, our SEGA3D surpasses the top-performing counterpart by 8.3 mIoU and 5.3 mIoU on ScanNet and Matterport3D, respectively. Codes will be available upon publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the SEGA3D paradigm for 3D vision-language segmentation. It replaces coarse superpoint representations with a mask candidate generator that produces fine-grained categorical mask candidates, then uses an LLM to derive semantic and spatial information from linguistic descriptions and visual features, a Semantic-Spatial Selector (SSS) to rank top candidates, and a Loopback Verification Module (LVM) to output the final mask. The work reports competitive results on ScanRefer, ScanNet, and Matterport3D, with gains of 8.3 mIoU on ScanNet and 5.3 mIoU on Matterport3D over prior top methods.
Significance. If the performance gains are substantiated by evidence that the mask generator indeed yields substantially higher-quality candidates than superpoints, the work would be significant for the field. It offers a concrete alternative to superpoint-based pipelines and demonstrates a modular LLM-plus-selector architecture that could improve boundary precision in 3D VL tasks.
major comments (1)
- [Abstract] Abstract: The headline claim that SEGA3D 'surpasses the top-performing counterpart by 8.3 mIoU' on ScanNet is explicitly attributed to the mask candidate generator producing 'substantially' better fine-grained categorical masks than superpoint methods. No candidate-level metrics (recall, boundary F-score, object coverage) or ablation that isolates the generator while holding the LLM/SSS/LVM fixed are referenced, leaving the central methodological premise unsupported.
Simulated Author's Rebuttal
Thank you for the constructive review. We appreciate the referee's focus on substantiating the central claim regarding the mask candidate generator. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that SEGA3D 'surpasses the top-performing counterpart by 8.3 mIoU' on ScanNet is explicitly attributed to the mask candidate generator producing 'substantially' better fine-grained categorical masks than superpoint methods. No candidate-level metrics (recall, boundary F-score, object coverage) or ablation that isolates the generator while holding the LLM/SSS/LVM fixed are referenced, leaving the central methodological premise unsupported.
Authors: We agree the abstract's attribution would be strengthened by direct evidence. The manuscript reports end-to-end gains, but does not include the requested candidate-level metrics or isolating ablation. In revision we will add: (1) quantitative comparison of mask candidates vs. superpoints using recall, boundary F-score, and object coverage; (2) an ablation holding LLM/SSS/LVM fixed and varying only the generator. These additions will directly support the premise and the reported significance. revision: yes
Circularity Check
No circularity; empirical benchmark claims rest on external data rather than internal re-derivation
full rationale
The paper describes an architectural pipeline (mask candidate generator feeding LLM/SSS/LVM) whose headline performance numbers are obtained by direct comparison against prior methods on the fixed external benchmarks ScanRefer, ScanNet and Matterport3D. No equations, fitted parameters, or uniqueness theorems appear in the provided text; the central methodological claim is therefore an empirical assertion about mask quality rather than a derivation that reduces to its own inputs by construction. Self-citations are not invoked as load-bearing support for any result. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Heterogeneous and Adept Snapshot Distillation for 3D Semantic Segmentation
HAS-KD combines information-oriented heterogeneous distillation from multi-modal models with adept snapshot distillation from training checkpoints to reach SOTA 3D semantic segmentation on ScanNetV2 and S3DIS without ...
Reference graph
Works this paper leans on
-
[1]
Scanrefer: 3d object localization in rgb-d scans using natural language
Dave Zhenyu Chen, Angel X Chang, and Matthias Nießner. Scanrefer: 3d object localization in rgb-d scans using natural language. InEuropean conference on computer vision, pages 202–221. Springer, 2020
2020
-
[2]
Text-guided graph neural networks for referring 3d instance segmentation
Pin-Hao Huang, Han-Hung Lee, Hwann-Tzong Chen, and Tyng-Luh Liu. Text-guided graph neural networks for referring 3d instance segmentation. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 1610–1618, 2021
2021
-
[3]
X-refseg3d: Enhancing referring 3d instance segmentation via structured cross-modal graph neural networks
Zhipeng Qian, Yiwei Ma, Jiayi Ji, and Xiaoshuai Sun. X-refseg3d: Enhancing referring 3d instance segmentation via structured cross-modal graph neural networks. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 4551–4559, 2024
2024
-
[4]
3d-stmn: Dependency-driven superpoint-text matching network for end-to-end 3d referring expression segmentation
Changli Wu, Yiwei Ma, Qi Chen, Haowei Wang, Gen Luo, Jiayi Ji, and Xiaoshuai Sun. 3d-stmn: Dependency-driven superpoint-text matching network for end-to-end 3d referring expression segmentation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 5940–5948, 2024
2024
-
[5]
Reason3d: Searching and reasoning 3d segmentation via large language model
Kuan-Chih Huang, Xiangtai Li, Lu Qi, Shuicheng Yan, and Ming-Hsuan Yang. Reason3d: Searching and reasoning 3d segmentation via large language model. In2025 International Conference on 3D Vision (3DV), pages 1177–1186. IEEE, 2025
2025
-
[6]
3d-llm: Injecting the 3d world into large language models.Advances in Neural Information Processing Systems, 36:20482–20494, 2023
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: Injecting the 3d world into large language models.Advances in Neural Information Processing Systems, 36:20482–20494, 2023
2023
-
[7]
Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning
Sijin Chen, Xin Chen, Chi Zhang, Mingsheng Li, Gang Yu, Hao Fei, Hongyuan Zhu, Jiayuan Fan, and Tao Chen. Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26428–26438, 2024
2024
-
[8]
Scanqa: 3d question answering for spatial scene understanding
Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. Scanqa: 3d question answering for spatial scene understanding. Inproceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19129–19139, 2022
2022
-
[9]
Pointllm: Empowering large language models to understand point clouds
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiangmiao Pang, and Dahua Lin. Pointllm: Empowering large language models to understand point clouds. InEuropean Conference on Computer Vision, pages 131–147. Springer, 2024
2024
-
[10]
Large-scale point cloud semantic segmentation with superpoint graphs
Loic Landrieu and Martin Simonovsky. Large-scale point cloud semantic segmentation with superpoint graphs. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4558–4567, 2018
2018
-
[11]
3d semantic segmentation with submanifold sparse convolutional networks
Benjamin Graham, Martin Engelcke, and Laurens Van Der Maaten. 3d semantic segmentation with submanifold sparse convolutional networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 9224–9232, 2018
2018
-
[12]
Lisa: Reasoning segmentation via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9579–9589, 2024
2024
-
[13]
Pixellm: Pixel reasoning with large multimodal model
Zhongwei Ren, Zhicheng Huang, Yunchao Wei, Yao Zhao, Dongmei Fu, Jiashi Feng, and Xiaojie Jin. Pixellm: Pixel reasoning with large multimodal model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26374–26383, 2024
2024
-
[14]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
2017
-
[15]
Matterport3d: Learning from rgb-d data in indoor environments.arXiv preprint arXiv:1709.06158, 2017
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments.arXiv preprint arXiv:1709.06158, 2017. 10
Pith/arXiv arXiv 2017
-
[16]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660, 2017
2017
-
[17]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
2017
-
[18]
Point transformer
Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip HS Torr, and Vladlen Koltun. Point transformer. In Proceedings of the IEEE/CVF international conference on computer vision, pages 16259–16268, 2021
2021
-
[19]
Point transformer v3: Simpler faster stronger
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xihui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao. Point transformer v3: Simpler faster stronger. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4840–4851, 2024
2024
-
[20]
Hexplane representation for 3d semantic scene understanding.arXiv preprint arXiv:2503.05127, 2025
Zeren Chen, Yuenan Hou, Yulin Chen, Li Liu, Xiao Sun, and Lu Sheng. Hexplane representation for 3d semantic scene understanding.arXiv preprint arXiv:2503.05127, 2025
arXiv 2025
-
[21]
Nerf-det++: Incorporating semantic cues and perspective-aware depth supervision for indoor multi-view 3d detection.IEEE Transactions on Image Processing, 2025
Chenxi Huang, Yuenan Hou, Weicai Ye, Di Huang, Xiaoshui Huang, Binbin Lin, and Deng Cai. Nerf-det++: Incorporating semantic cues and perspective-aware depth supervision for indoor multi-view 3d detection.IEEE Transactions on Image Processing, 2025
2025
-
[22]
Taseg: Temporal aggregation network for lidar semantic segmentation
Xiaopei Wu, Yuenan Hou, Xiaoshui Huang, Binbin Lin, Tong He, Xinge Zhu, Yuexin Ma, Boxi Wu, Haifeng Liu, Deng Cai, et al. Taseg: Temporal aggregation network for lidar semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15311–15320, 2024
2024
-
[23]
Point-to-voxel knowledge distillation for lidar semantic segmentation
Yuenan Hou, Xinge Zhu, Yuexin Ma, Chen Change Loy, and Yikang Li. Point-to-voxel knowledge distillation for lidar semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8479–8488, 2022
2022
-
[24]
Superpoint transformer for 3d scene instance segmentation
Jiahao Sun, Chunmei Qing, Junpeng Tan, and Xiangmin Xu. Superpoint transformer for 3d scene instance segmentation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 2393–2401, 2023
2023
-
[25]
4d spatio-temporal convnets: Minkowski convolutional neural networks
Christopher Choy, JunYoung Gwak, and Silvio Savarese. 4d spatio-temporal convnets: Minkowski convolutional neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3075–3084, 2019
2019
-
[26]
Mask3d: Mask transformer for 3d semantic instance segmentation
Jonas Schult, Francis Engelmann, Alexander Hermans, Or Litany, Siyu Tang, and Bastian Leibe. Mask3d: Mask transformer for 3d semantic instance segmentation. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 8216–8223. IEEE, 2023
2023
-
[27]
Oneformer3d: One transformer for unified point cloud segmentation
Maxim Kolodiazhnyi, Anna V orontsova, Anton Konushin, and Danila Rukhovich. Oneformer3d: One transformer for unified point cloud segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20943–20953, 2024
2024
-
[28]
Openscene: 3d scene understanding with open vocabularies
Songyou Peng, Kyle Genova, Chiyu Jiang, Andrea Tagliasacchi, Marc Pollefeys, Thomas Funkhouser, et al. Openscene: 3d scene understanding with open vocabularies. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 815–824, 2023
2023
-
[29]
Openmask3d: Open-vocabulary 3d instance segmentation.arXiv preprint arXiv:2306.13631, 2023
Ayça Takmaz, Elisabetta Fedele, Robert W Sumner, Marc Pollefeys, Federico Tombari, and Francis Engelmann. Openmask3d: Open-vocabulary 3d instance segmentation.arXiv preprint arXiv:2306.13631, 2023
arXiv 2023
-
[30]
Moe3d: Mixture of experts meets multi-modal 3d understanding.arXiv preprint arXiv:2511.22103, 2025
Yu Li, Yuenan Hou, Yingmei Wei, Xinge Zhu, Yuexin Ma, Wenqi Shao, and Yanming Guo. Moe3d: Mixture of experts meets multi-modal 3d understanding.arXiv preprint arXiv:2511.22103, 2025
arXiv 2025
-
[31]
Towards label-free 3d visual grounding with vision foundation models
Xiaopei Wu, Yuenan Hou, Binbin Lin, Xinge Zhu, Yuexin Ma, Haifeng Liu, Deng Cai, and Xiao Sun. Towards label-free 3d visual grounding with vision foundation models. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 612–617. IEEE, 2025. 11
2025
-
[32]
Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes
Panos Achlioptas, Ahmed Abdelreheem, Fei Xia, Mohamed Elhoseiny, and Leonidas Guibas. Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes. In European conference on computer vision, pages 422–440. Springer, 2020
2020
-
[33]
Instancerefer: Cooperative holistic understanding for visual grounding on point clouds through instance multi-level contextual referring
Zhihao Yuan, Xu Yan, Yinghong Liao, Ruimao Zhang, Sheng Wang, Zhen Li, and Shuguang Cui. Instancerefer: Cooperative holistic understanding for visual grounding on point clouds through instance multi-level contextual referring. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1791–1800, 2021
2021
-
[34]
3dvg-transformer: Relation modeling for visual grounding on point clouds
Lichen Zhao, Daigang Cai, Lu Sheng, and Dong Xu. 3dvg-transformer: Relation modeling for visual grounding on point clouds. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2928–2937, 2021
2021
-
[35]
3d-sps: Single-stage 3d visual grounding via referred point progressive selection
Junyu Luo, Jiahui Fu, Xianghao Kong, Chen Gao, Haibing Ren, Hao Shen, Huaxia Xia, and Si Liu. 3d-sps: Single-stage 3d visual grounding via referred point progressive selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16454–16463, 2022
2022
-
[36]
Visa: Reasoning video object segmentation via large language models
Cilin Yan, Haochen Wang, Shilin Yan, Xiaolong Jiang, Yao Hu, Guoliang Kang, Weidi Xie, and Efstratios Gavves. Visa: Reasoning video object segmentation via large language models. In European Conference on Computer Vision, pages 98–115. Springer, 2024
2024
-
[37]
Deris: Decoupling perception and cognition for enhanced referring image segmentation through loopback synergy
Ming Dai, Wenxuan Cheng, Jiang-jiang Liu, Sen Yang, Wenxiao Cai, Yanpeng Sun, and Wankou Yang. Deris: Decoupling perception and cognition for enhanced referring image segmentation through loopback synergy. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19936–19946, 2025
2025
-
[38]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[39]
Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024
2024
-
[40]
Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[41]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[42]
Language-grounded indoor 3d semantic segmentation in the wild
David Rozenberszki, Or Litany, and Angela Dai. Language-grounded indoor 3d semantic segmentation in the wild. InEuropean Conference on Computer Vision, pages 125–141. Springer, 2022. 12 A Implementation Details This section provides additional implementation details that are omitted from the main paper. We mainly describe the candidate generation protocol...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.