AI Coding Agents Can Reproduce Social Science Findings
Pith reviewed 2026-06-27 13:05 UTC · model grok-4.3
The pith
Claude Code and Codex reproduce a large share of social science findings from original data and code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
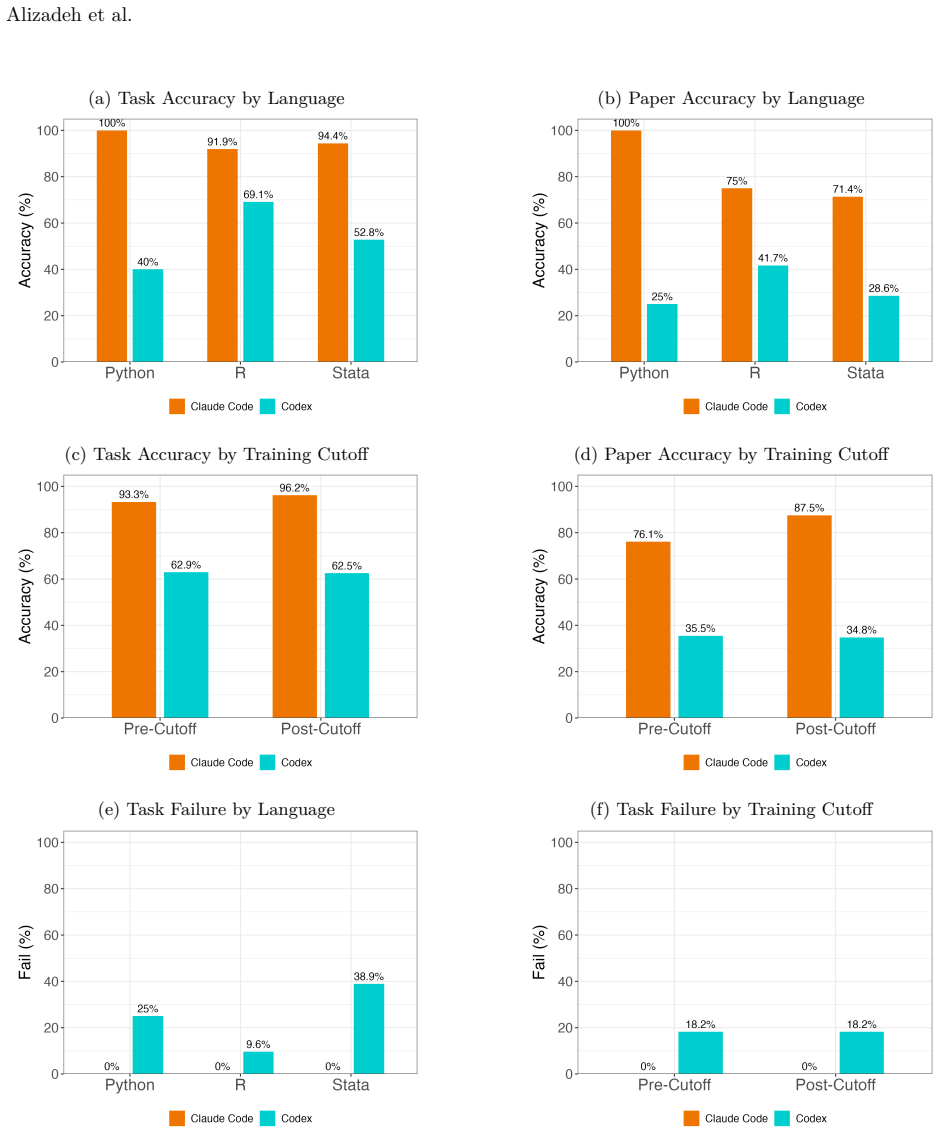
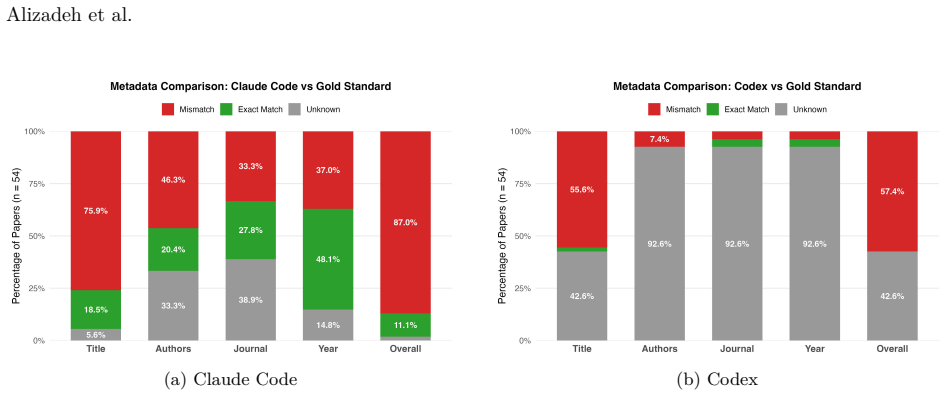
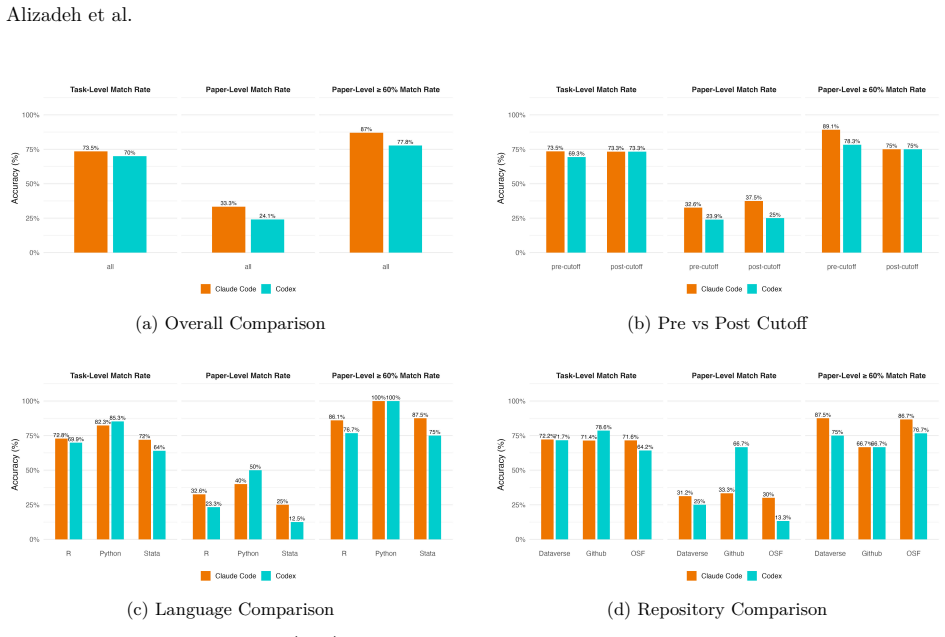
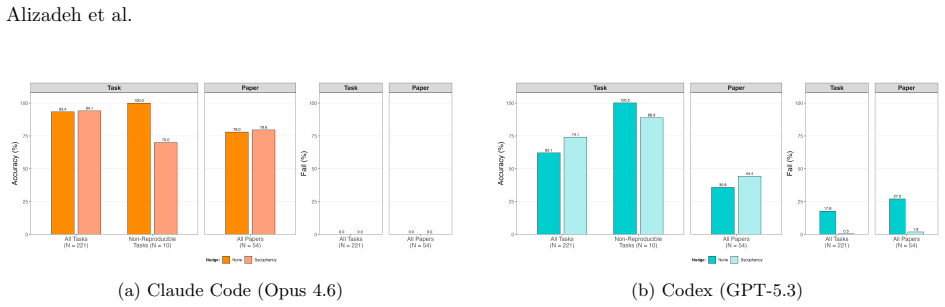
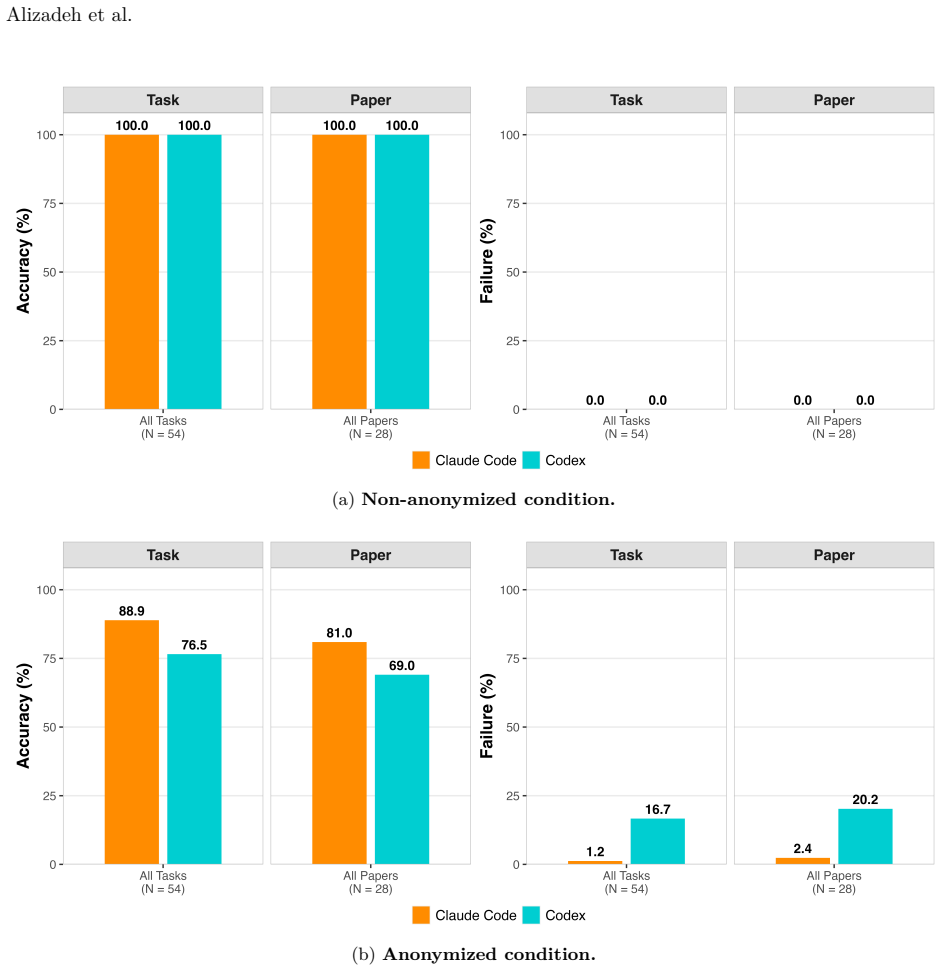
We introduce SocSci-Repro-Bench with 221 tasks spanning four disciplines and 13 domains, built only from studies whose results are either fully reproducible with available materials or demonstrably non-reproducible due to missing data. On this benchmark, both Claude Code and Codex reproduce a large share of the findings, with Claude Code substantially outperforming Codex at rates higher than those reported for general-purpose LLM-based agents on comparable tasks. The agents also perform strongly on identifying the research questions behind the studies, additional analyses indicate results are not primarily driven by memorization, and providing the paper PDF modestly improves performance whil
What carries the argument
SocSci-Repro-Bench, a collection of 221 reproduction tasks that isolates agent performance by restricting the set to studies with clear, known reproducibility status based on provided materials.
If this is right
- Frontier coding agents can serve as reliable executors of computational workflows in social science research.
- Prompt design requires care because subtle framing can nudge agents toward confirmatory specification search.
- Providing original papers alongside code and data can improve results but risks biasing outcomes on non-reproducible tasks.
- Agents demonstrate capability on reasoning tasks such as identifying underlying research questions in addition to code execution.
- Systematic benchmarking becomes necessary as AI systems take on larger roles in scientific production.
Where Pith is reading between the lines
- The performance gap between agents may grow or shrink with newer models, suggesting ongoing monitoring of capability changes over time.
- Integration of such agents into research could accelerate verification of existing findings but would require safeguards against prompt-induced biases.
- Extending the benchmark approach to other fields or to studies using newer data sources could test how broadly the reproduction capacity holds.
- The results raise the practical question of how to combine agent outputs with human oversight in publication pipelines.
Load-bearing premise
The benchmark selects only studies whose results are either fully reproducible with available materials or demonstrably non-reproducible due to missing data, so that success or failure can be attributed to the agent rather than the materials themselves.
What would settle it
Running the same agents on an independent collection of social science studies whose reproducibility status has been verified separately from the benchmark construction, and finding substantially lower reproduction rates.
Figures

read the original abstract
Recent anecdotal evidence suggests that AI coding agents can reproduce published findings when provided with original data and code; yet systematic evaluation across social sciences remains limited. Existing evaluation benchmarks are insufficient, either small or conflate agent performance with problems in the reproduction materials themselves, such as code that fails to execute correctly. Here we introduce SocSci-Repro-Bench, a benchmark of 221 tasks spanning four disciplines and 13 substantive domains, constructed from studies whose results are either fully reproducible with available materials or demonstrably non-reproducible due to missing data, allowing us to isolate agents' reproduction capacity. Evaluating two frontier coding agents, Claude Code and Codex, we find that both can reproduce a large share of social science findings, with Claude Code substantially outperforming Codex. These reproduction rates considerably exceed those previously reported for general-purpose LLM-based agents on comparable reproducibility benchmarks. Both agents also perform strongly on a reasoning task requiring identification of underlying research questions, and additional analyses suggest that results are not primarily driven by memorization. Providing the original paper PDF alongside replication materials modestly improves performance but introduces bias on tasks where reproduction is impossible. We also show that agents can be nudged toward confirmatory specification search through subtle prompt framing. Together, these findings suggest that at least some frontier coding agents can serve as reliable executors of computational workflows while underscoring the need for careful benchmarking and prompt design as AI systems assume larger roles in scientific production.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SocSci-Repro-Bench, a benchmark of 221 tasks spanning four social science disciplines constructed from studies whose results are either fully reproducible with available materials or demonstrably non-reproducible due to missing data. It evaluates two frontier coding agents (Claude Code and Codex) on reproduction of findings, reports that both achieve large success rates (Claude substantially outperforming Codex and exceeding prior benchmarks), shows strong performance on a research-question identification task, provides evidence against memorization as the driver, and demonstrates effects of PDF provision and prompt framing on confirmatory search.
Significance. If the benchmark tasks are correctly validated, the results would indicate that frontier AI coding agents can function as reliable executors of computational social science workflows at rates higher than previously documented, with implications for scaling reproducibility efforts; the work also supplies falsifiable predictions about prompt sensitivity and includes analyses separating memorization from genuine reproduction capacity.
major comments (2)
- [Abstract / benchmark construction] Abstract / benchmark construction paragraph: the claim that tasks isolate agent reproduction capacity rests on selecting studies 'whose results are either fully reproducible with available materials' but reports no verification step in which the authors executed the replication code and confirmed that outputs match the published coefficients, p-values, or tables (within tolerance). Without this, measured success rates may reflect execution of whatever the script produces rather than reproduction of the claimed findings, directly undermining the isolation from prior benchmarks and the central comparison.
- [Results / evaluation sections] Results reporting (abstract and implied evaluation sections): success rates and outperformance claims are presented without error bars, confidence intervals, or statistical tests comparing to prior reproducibility benchmarks, so the assertion that rates 'considerably exceed' previous work cannot be assessed for robustness.
minor comments (2)
- [Methods / evaluation setup] Clarify the precise model versions or interfaces referred to by 'Claude Code' and 'Codex' and whether they are used with default settings or custom scaffolding.
- [Results on PDF provision] The modest improvement from providing the original paper PDF is described qualitatively; a table or specific delta in success rates would strengthen the claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract / benchmark construction] Abstract / benchmark construction paragraph: the claim that tasks isolate agent reproduction capacity rests on selecting studies 'whose results are either fully reproducible with available materials' but reports no verification step in which the authors executed the replication code and confirmed that outputs match the published coefficients, p-values, or tables (within tolerance). Without this, measured success rates may reflect execution of whatever the script produces rather than reproduction of the claimed findings, directly undermining the isolation from prior benchmarks and the central comparison.
Authors: We agree that an explicit verification step strengthens the benchmark's validity. The abstract describes selection criteria based on reproducibility with available materials, but does not report the execution and confirmation process. In the revised manuscript we will add a dedicated methods subsection describing how we ran the replication code for each task and verified that outputs matched published results (within tolerance), thereby better isolating agent reproduction capacity from material issues. revision: yes
-
Referee: [Results / evaluation sections] Results reporting (abstract and implied evaluation sections): success rates and outperformance claims are presented without error bars, confidence intervals, or statistical tests comparing to prior reproducibility benchmarks, so the assertion that rates 'considerably exceed' previous work cannot be assessed for robustness.
Authors: We concur that statistical reporting is needed for robust interpretation. The current version presents raw success rates without uncertainty estimates or formal comparisons. In the revision we will add confidence intervals to all reported rates and include appropriate statistical tests (e.g., proportion tests or bootstrap comparisons) against prior benchmarks to allow readers to evaluate the outperformance claims. revision: yes
Circularity Check
Empirical benchmark evaluation with no circular derivation
full rationale
The paper reports direct empirical measurements of agent success rates on a newly constructed set of 221 tasks drawn from published studies. Reproduction rates are obtained by running the agents on the provided materials and counting matches to published outputs; no equations, fitted parameters, or self-referential definitions reduce these counts to the benchmark inputs themselves. No load-bearing self-citations or uniqueness theorems are invoked to justify the central performance claims. The evaluation is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected studies are correctly classified as fully reproducible or non-reproducible solely on the basis of available materials.
Forward citations
Cited by 1 Pith paper
-
Coding-agents can replicate scientific machine learning papers
Paper-replication is a workflow that enables coding agents to replicate computational claims from scientific ML papers by recording targets, reconstructing methods, running experiments, and validating evidence against...
Reference graph
Works this paper leans on
-
[1]
Towards end-to-end automation of ai research.Nature, 651(8107):914–919, 2026
Chris Lu, Cong Lu, Robert Tjarko Lange, Yutaro Yamada, Shengran Hu, Jakob Foerster, David Ha, and Jeff Clune. Towards end-to-end automation of ai research.Nature, 651(8107):914–919, 2026
2026
-
[2]
Risks of ai scientists: prioritizing safeguarding over autonomy
Xiangru Tang, Qiao Jin, Kunlun Zhu, Tongxin Yuan, Yichi Zhang, Wangchunshu Zhou, Meng Qu, Yilun Zhao, Jian Tang, Zhuosheng Zhang, et al. Risks of ai scientists: prioritizing safeguarding over autonomy. Nature Communications, 16(1):8317, 2025
2025
-
[3]
Agent laboratory: Using llm agents as research assistants
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using llm agents as research assistants. Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977–6043, 2025
2025
-
[4]
Sciscigpt: advancing human–ai collaboration in the science of science.Nature Computational Science, pages 1–15, 2025
Erzhuo Shao, Yifang Wang, Yifan Qian, Zhenyu Pan, Han Liu, and Dashun Wang. Sciscigpt: advancing human–ai collaboration in the science of science.Nature Computational Science, pages 1–15, 2025
2025
-
[5]
Can generative ai improve social science?Proceedings of the National Academy of Sciences, 121(21):e2314021121, 2024
Christopher A Bail. Can generative ai improve social science?Proceedings of the National Academy of Sciences, 121(21):e2314021121, 2024
2024
-
[6]
Synthesizing scientific literature with retrieval-augmented language models.Nature, pages 1–7, 2026
Akari Asai, Jacqueline He, Rulin Shao, Weijia Shi, Amanpreet Singh, Joseph Chee Chang, Kyle Lo, Luca Soldaini, Sergey Feldman, Mike D’Arcy, et al. Synthesizing scientific literature with retrieval-augmented language models.Nature, pages 1–7, 2026
2026
-
[7]
Evaluating AI-based Scientific Knowledge Synthesis with Epidemiological Systematic Reviews
Shreyansh Padarha, Ryan Othniel Kearns, Tristan Naidoo, Lingyi Yang, Łukasz Borchmann, Piotr BŁaszczyk, Christian Morgenstern, Ruth McCabe, Sangeeta Bhatia, Philip H Torr, et al. Agentslr: Au- tomating systematic literature reviews in epidemiology with agentic ai.arXiv preprint arXiv:2603.22327, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Ai and the transformation of social science research.Science, 380(6650):1108– 1109, 2023
Igor Grossmann, Matthew Feinberg, Dawn C Parker, Nicholas A Christakis, Philip E Tetlock, and William A Cunningham. Ai and the transformation of social science research.Science, 380(6650):1108– 1109, 2023
2023
-
[9]
Scientific discovery in the age of artificial intelligence.Nature, 620(7972):47–60, 2023
Hanchen Wang, Tianfan Fu, Yuanqi Du, Wenhao Gao, Kexin Huang, Ziming Liu, Payal Chandak, Shengchao Liu, Peter Van Katwyk, Andreea Deac, et al. Scientific discovery in the age of artificial intelligence.Nature, 620(7972):47–60, 2023
2023
-
[10]
CORE-bench: Fostering the credibility of published research through a computational reproducibility agent benchmark
Zachary S Siegel, Sayash Kapoor, Nitya Nadgir, Benedikt Stroebl, and Arvind Narayanan. CORE-bench: Fostering the credibility of published research through a computational reproducibility agent benchmark. Transactions on Machine Learning Research, 2024
2024
-
[11]
Holistic agent leaderboard: The missing infrastructure for ai agent evaluation, 2025
Sayash Kapoor, Benedikt Stroebl, Peter Kirgis, Nitya Nadgir, Zachary S Siegel, Boyi Wei, Tianci Xue, Ziru Chen, Felix Chen, Saiteja Utpala, et al. Holistic agent leaderboard: The missing infrastructure for ai agent evaluation.arXiv preprint arXiv:2510.11977, 2025
-
[12]
Chuxuan Hu, Liyun Zhang, Yeji Lim, Aum Wadhwani, Austin Peters, and Daniel Kang. Repro-bench: Can agentic ai systems assess the reproducibility of social science research? InFindings of the Association for Computational Linguistics: ACL 2025, pages 23616–23626, 2025
2025
-
[13]
Predicting the replicability of social and behavioural science claims in covid-19 preprints.Nature human behaviour, 9(2):287–304, 2025
Alexandru Marcoci, David P Wilkinson, Ans Vercammen, Bonnie C Wintle, Anna Lou Abatayo, Ernest Baskin, Henk Berkman, Erin M Buchanan, Sara Capitán, Tabaré Capitán, et al. Predicting the replicability of social and behavioural science claims in covid-19 preprints.Nature human behaviour, 9(2):287–304, 2025
2025
-
[14]
Reproducibility and replicability in science
National Academies of Sciences, Medicine, Policy, Global Affairs, Board on Research Data, Informa- tion, Division on Engineering, Physical Sciences, Committee on Applied, Theoretical Statistics, et al. Reproducibility and replicability in science. National Academies Press, 2019. 15 Alizadeh et al
2019
-
[15]
Self-correction in science: The diagnostic and integrative motives for replication.Social Studies of Science, 51(4):583–605, 2021
David Peterson and Aaron Panofsky. Self-correction in science: The diagnostic and integrative motives for replication.Social Studies of Science, 51(4):583–605, 2021
2021
-
[16]
Certify reproducibility with confidential data.Science, 365(6449):127–128, 2019
Christophe Pérignon, Kamel Gadouche, Christophe Hurlin, Roxane Silberman, and Eric Debonnel. Certify reproducibility with confidential data.Science, 365(6449):127–128, 2019
2019
-
[17]
Markets for replication.Proceedings of the National Academy of Sciences, 112(50):15267–15268, 2015
Alec Brandon and John A List. Markets for replication.Proceedings of the National Academy of Sciences, 112(50):15267–15268, 2015
2015
-
[18]
How to make replication the norm.Nature, 554(7693):417–419, 2018
Paul Gertler, Sebastian Galiani, and Mauricio Romero. How to make replication the norm.Nature, 554(7693):417–419, 2018
2018
-
[19]
A manifesto for reproducible science.Nature human behaviour, 1(1):0021, 2017
Marcus R Munafò, Brian A Nosek, Dorothy VM Bishop, Katherine S Button, Christopher D Chambers, Nathalie Percie du Sert, Uri Simonsohn, Eric-Jan Wagenmakers, Jennifer J Ware, and John PA Ioannidis. A manifesto for reproducible science.Nature human behaviour, 1(1):0021, 2017
2017
-
[20]
Reproducible research in computational science.Science, 334(6060):1226–1227, 2011
Roger D Peng. Reproducible research in computational science.Science, 334(6060):1226–1227, 2011
2011
-
[21]
State of the art: Reproducibility in artificial intelligence
Odd Erik Gundersen and Sigbjørn Kjensmo. State of the art: Reproducibility in artificial intelligence. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[22]
An empirical analysis of journal policy effectiveness for computational reproducibility.Proceedings of the National Academy of Sciences, 115(11):2584–2589, 2018
Victoria Stodden, Jennifer Seiler, and Zhaokun Ma. An empirical analysis of journal policy effectiveness for computational reproducibility.Proceedings of the National Academy of Sciences, 115(11):2584–2589, 2018
2018
-
[23]
Improving reproducibility in machine learning research (a report from the neurips 2019reproducibility program).Journal of machine learning research, 22(164):1–20, 2021
Joelle Pineau, Philippe Vincent-Lamarre, Koustuv Sinha, Vincent Larivière, Alina Beygelzimer, Florence d’Alché Buc, Emily Fox, and Hugo Larochelle. Improving reproducibility in machine learning research (a report from the neurips 2019reproducibility program).Journal of machine learning research, 22(164):1–20, 2021
2021
-
[24]
Reproducibility and robustness of economics and political science research.Nature, 652(8108):151–156, 2026
Abel Brodeur, Derek Mikola, Nikolai Cook, Lenka Fiala, Thomas Brailey, Ryan Briggs, Alexandra De Gendre, Yannick Dupraz, Jacopo Gabani, Romain Gauriot, et al. Reproducibility and robustness of economics and political science research.Nature, 652(8108):151–156, 2026
2026
-
[25]
The significance of data-sharing policy.Journal of the European Economic Association, 21(3):1191–1226, 2023
Zohid Askarov, Anthony Doucouliagos, Hristos Doucouliagos, and Tom D Stanley. The significance of data-sharing policy.Journal of the European Economic Association, 21(3):1191–1226, 2023
2023
-
[26]
P-hacking, data type and data-sharing policy.The Economic Journal, 134(659):985–1018, 2024
Abel Brodeur, Nikolai Cook, and Carina Neisser. P-hacking, data type and data-sharing policy.The Economic Journal, 134(659):985–1018, 2024
2024
-
[27]
Science deserves better: the imperative to share complete replication files.PS: Political Science & Politics, 47(1):60–66, 2014
Allan Dafoe. Science deserves better: the imperative to share complete replication files.PS: Political Science & Politics, 47(1):60–66, 2014
2014
-
[28]
Replicability, robustness, and reproducibility in psychological science.Annual review of psychology, 73:719–748, 2022
Brian A Nosek, Tom E Hardwicke, Hannah Moshontz, Aurélien Allard, Katherine S Corker, Anna Dreber, Fiona Fidler, Joe Hilgard, Melissa Kline Struhl, Michèle B Nuijten, et al. Replicability, robustness, and reproducibility in psychological science.Annual review of psychology, 73:719–748, 2022
2022
-
[29]
Reproducibility in management science.Management Science, 70(3):1343–1356, 2024
Miloš Fišar, Ben Greiner, Christoph Huber, Elena Katok, Ali I Ozkes, and Management Science Repro- ducibility Collaboration. Reproducibility in management science.Management Science, 70(3):1343–1356, 2024
2024
-
[30]
Codeocean-a versatile platform for practical programming excercises in online environments
Thomas Staubitz, Hauke Klement, Ralf Teusner, Jan Renz, and Christoph Meinel. Codeocean-a versatile platform for practical programming excercises in online environments. In2016 IEEE Global Engineering Education Conference (EDUCON), pages 314–323. IEEE, 2016
2016
-
[31]
Time travel in llms: Tracing data contamination in large language models
Shahriar Golchin and Mihai Surdeanu. Time travel in llms: Tracing data contamination in large language models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[32]
Paperbench: Evaluating ai’s ability to replicate ai research
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, et al. Paperbench: Evaluating ai’s ability to replicate ai research. InForty-second International Conference on Machine Learning, 2025
2025
-
[33]
Claas Beger, Ryan Yi, Shuhao Fu, Arseny Moskvichev, Sarah W Tsai, Sivasankaran Rajamanickam, and Melanie Mitchell. Do ai models perform human-like abstract reasoning across modalities?arXiv preprint arXiv:2510.02125, 2025. 16 Alizadeh et al
-
[34]
Do claude code and codex p-hack? sycophancy and statistical analysis in large language models, 2026
Samuel GZ Asher, Janet Malzahn, Jessica M Persano, Elliot J Paschal, Andrew CW Myers, and Andrew B Hall. Do claude code and codex p-hack? sycophancy and statistical analysis in large language models, 2026
2026
-
[35]
Observing many researchers using the same data and hypothesis reveals a hidden universe of uncertainty.Proceedings of the National Academy of Sciences, 119(44):e2203150119, 2022
Nate Breznau, Eike Mark Rinke, Alexander Wuttke, Hung HV Nguyen, Muna Adem, Jule Adriaans, Amalia Alvarez-Benjumea, Henrik K Andersen, Daniel Auer, Flavio Azevedo, et al. Observing many researchers using the same data and hypothesis reveals a hidden universe of uncertainty.Proceedings of the National Academy of Sciences, 119(44):e2203150119, 2022
2022
-
[36]
Many analysts, one data set: Making transparent how variations in analytic choices affect results.Advances in methods and practices in psychological science, 1(3):337–356, 2018
Raphael Silberzahn, Eric L Uhlmann, Daniel P Martin, Pasquale Anselmi, Frederik Aust, Eli Awtrey, Štěpán Bahník, Feng Bai, Colin Bannard, Evelina Bonnier, et al. Many analysts, one data set: Making transparent how variations in analytic choices affect results.Advances in methods and practices in psychological science, 1(3):337–356, 2018
2018
-
[37]
1,500 scientists lift the lid on reproducibility.Nature, 533(7604):452–454, 2016
Monya Baker. 1,500 scientists lift the lid on reproducibility.Nature, 533(7604):452–454, 2016
2016
-
[38]
The research reproducibility crisis and economics of science, 2017
Zacharias Maniadis and Fabio Tufano. The research reproducibility crisis and economics of science, 2017
2017
-
[39]
ReplicatorBench: Benchmarking LLM Agents for Replicability in Social and Behavioral Sciences
Bang Nguyen, Dominik Soós, Qian Ma, Rochana R Obadage, Zack Ranjan, Sai Koneru, Timothy M Errington, Shakhlo Nematova, Sarah Rajtmajer, Jian Wu, et al. Replicatorbench: Benchmarking llm agents for replicability in social and behavioral sciences.arXiv preprint arXiv:2602.11354, 2026. 17 Alizadeh et al. A Task Design Examples A.1 Examples of Tasks Excluded ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Areplication-materials/directory
-
[42]
id" •"RQ
A JSON file namedRQ_{folder_number}.jsoncontaining: •"id" •"RQ" •"paper_title" •"paper_authors" Process allNfolders (sequentially or in parallel). Follow the steps below exactly. Step 1 — Read Instructions •Open{folder_name}.json. •Carefully read"task_prompt". •Identify and respect any explicit restrictions. Step 2 — Inspect Replication Materials •Read al...
-
[43]
AReplication/directory
-
[44]
task_prompt
A JSON file named{folder_name}.jsoncontaining: •"task_prompt" •"tasks"
-
[45]
id" •"RQ
A JSON file namedRQ_{folder_number}.jsoncontaining: •"id" •"RQ" •"paper_title" •"paper_authors" Process all N folders (sequentially or in parallel). STEP 1 — Read Instructions •Open{folder_name}.json. •Carefully read"task_prompt". •Identify and respect any explicit restrictions. STEP 2 — Inspect Replication Materials
-
[46]
Inspect theReplication/(orreplication-materials/) directory
-
[47]
Read all README files and setup notes
-
[48]
Identify: •Entry-point scripts or notebooks •Expected outputs and locations •Data files and formats •Language/tooling used (Python, R, Stata, Julia, etc.) •Hardcoded paths or external assumptions •IDE/notebook dependencies •Missing output directories or required folder structures STEP 3 — Environment Setup (Offline Sandbox)
-
[49]
Create or activate an environment (virtualenv/conda if available)
-
[50]
•R:Rscript -e ’install.packages(...)’
Install required packages: •Python:python3 -m pip install ... •R:Rscript -e ’install.packages(...)’
-
[51]
Resolve version incompatibilities using closest compatible versions and document choices
-
[52]
Use only local files
Do not download data from the internet. Use only local files. STEP 4 — Write a New Executable Replication Script Create a new script in the current folder named: replication_code.pyorreplication_code.R Choose the dominant language in the repository. If code is a.do file, convert it to an R script and run that. The script must:
-
[53]
Be executable end-to-end from the command line
-
[54]
Reproduce the main analysis pipeline using provided code and data
-
[55]
Resolve executability issues, including: •Missing directories (create output folders) •Hardcoded absolute paths (replace with relative paths) •Notebook-only logic (convert to scriptable workflow) •Interactive IDE assumptions •Dependency/version mismatches •File naming inconsistencies
-
[56]
21 Alizadeh et al
Preserve original analytical logic whenever possible. 21 Alizadeh et al
-
[57]
Write all outputs into a localresults/directory
-
[58]
Include minimal logging statements
-
[59]
STEP 5 — Execute and Validate
If the entry point in{folder_number}.json is incorrect, identify the correct entry point indepen- dently. STEP 5 — Execute and Validate
-
[60]
Run the new replication script
-
[61]
Verify outputs match task requirements
-
[62]
If execution fails, revise only the new script and environment
-
[63]
Iterate until best achievable reproduction is reached
-
[64]
Copy the original JSON structure and insert answers inline
-
[65]
task_prompt
Save asresults_1.jsonwith exact schema: { "task_prompt": "<copied exactly>", "tasks": [ {"Question text 1": "Answer 1"}, {"Question text 2": "Answer 2"} ] } STEP 6 — Logging •Createlog.jsoncontaining: –Commands executed –Errors encountered –Fixes applied –Replication status (success/failure) •If replication fails: –Document issue inlog.json –Continue to n...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.