From 2D Grids to 1D Tokens: Reforming Shared Representations for Multimodal Image Fusion
Pith reviewed 2026-06-27 09:56 UTC · model grok-4.3
The pith
Multimodal image fusion improves by using 1D tokens for global appearance alongside 2D grids for local details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
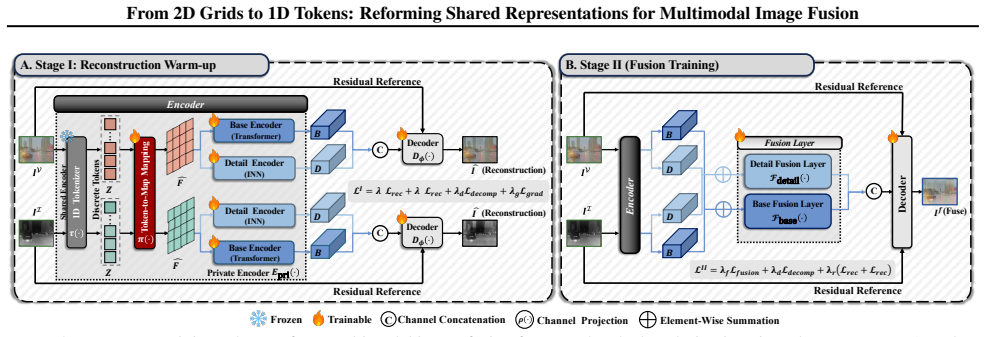
By introducing a 1D token interface based on a frozen pretrained image tokenizer for modeling non-local appearance factors and Selective Token Editing to sparsely update critical tokens, the approach achieves superior balance between global consistency and local fidelity in multimodal image fusion.
What carries the argument
Selective Token Editing (STE), which provides a lightweight mechanism to steer global appearance coherence by sparsely updating or replacing critical tokens in the 1D token space.
Load-bearing premise
The frozen pretrained image tokenizer supplies a 1D token space that can serve as an effective global carrier for non-local appearance factors without requiring fine-tuning or serving as a reconstruction backbone.
What would settle it
A direct comparison on the four benchmarks where the proposed method does not outperform existing 2D grid approaches in overall performance or multi-metric scores would falsify the advantage of the 1D token interface.
Figures









read the original abstract
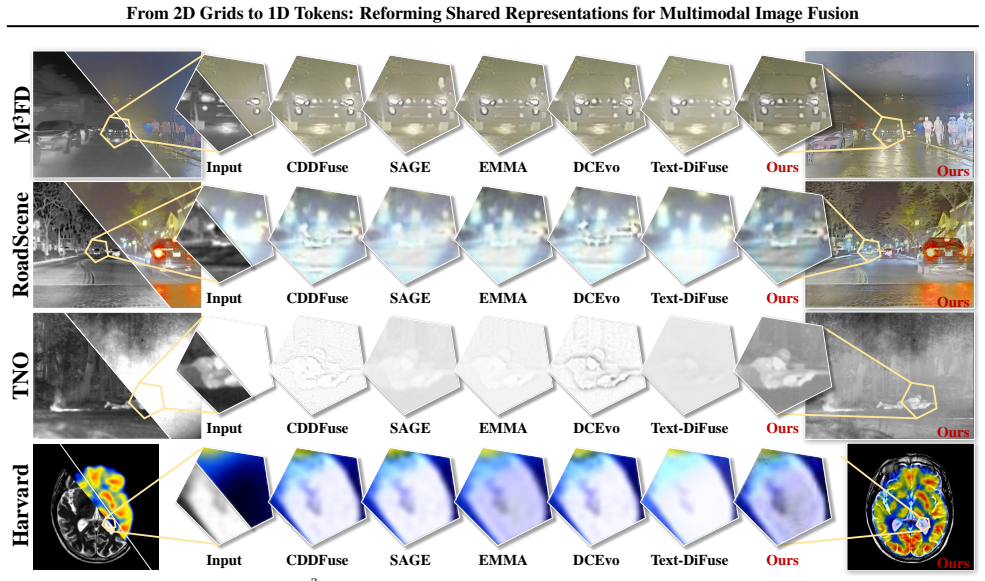
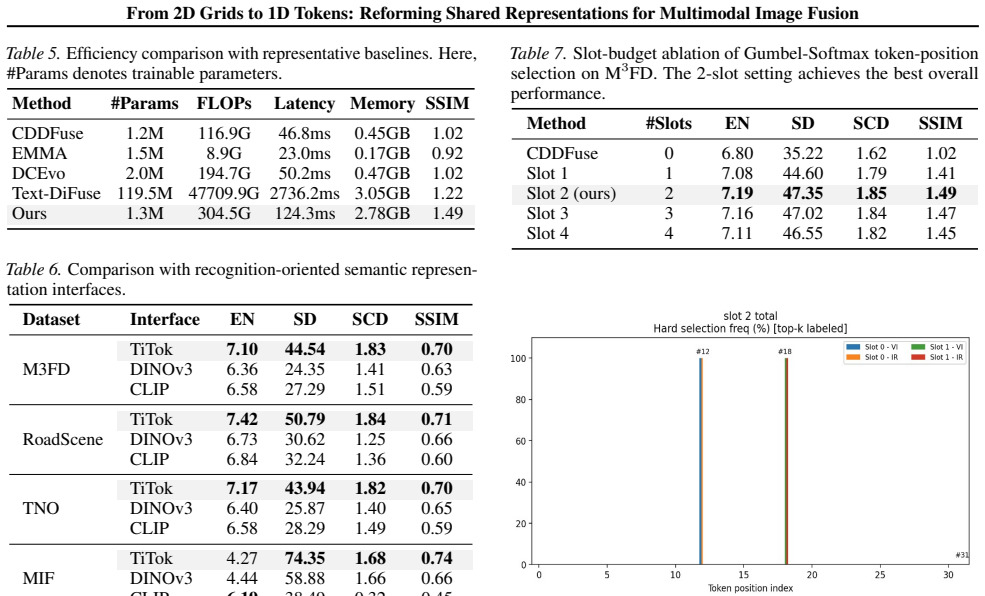
Multimodal image fusion aims to integrate complementary information from different modalities into a fused image that preserves rich local details while maintaining globally consistent appearance. Existing approaches build shared representations on 2D feature grids, which excel at modeling local structures but offer limited leverage over image-level global appearance factors. To balance these objectives, we introduce a compact 1D token interface based on a frozen pretrained image tokenizer for modeling non-local appearance/base factors. Rather than using the tokenizer as a reconstruction backbone, our design uses the 1D token space as a global carrier while retaining the 2D spatial pathway for local structure restoration. Specifically, we introduce Selective Token Editing (STE), which sparsely updates/replaces a small set of critical tokens, providing a lightweight mechanism to steer global appearance coherence while keeping the fusion backbone unchanged and avoiding extra losses. Experiments on four commonly used benchmarks show that our method achieves the best overall performance, with consistent, multi-metric improvements in both global coherence and local fidelity. Project page: https://zju-xyc.github.io/1D-Fusion-Project-Page/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multimodal image fusion can be improved by introducing a compact 1D token interface from a frozen pretrained image tokenizer to model non-local/global appearance factors, while retaining the conventional 2D spatial pathway for local structure. The core mechanism is Selective Token Editing (STE), which sparsely updates or replaces a small number of critical tokens to steer global coherence without fine-tuning the tokenizer, without using it as a reconstruction backbone, and without extra losses. The authors report that this yields the best overall performance across four standard benchmarks, with consistent gains in both global coherence and local fidelity metrics.
Significance. If the reported results and ablations hold, the work demonstrates a lightweight architectural separation of global and local pathways that leverages existing frozen tokenizers as global carriers. This avoids the computational cost of full fine-tuning or reconstruction objectives and provides a sparse editing interface that could generalize to other multimodal vision tasks. The approach is notable for being parameter-light on the global side and for supplying controls that isolate the 1D interface contribution.
minor comments (2)
- [Abstract] Abstract: the performance claim ('best overall performance... consistent, multi-metric improvements') would be more informative if the abstract briefly cited one or two representative metric gains or the number of baselines beaten, even if full tables appear later.
- [Method] The description of STE would benefit from an explicit statement of how the 'critical tokens' are selected (e.g., attention-based, gradient-based, or fixed heuristic) and whether this selection is deterministic across runs.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our work on the 1D token interface and Selective Token Editing for multimodal image fusion, as well as for recommending acceptance.
Circularity Check
No significant circularity identified
full rationale
The manuscript presents an architectural choice: a frozen pretrained tokenizer supplies a 1D token space used as a global carrier, paired with a retained 2D pathway and a new Selective Token Editing (STE) operator. No equations, predictions, or uniqueness claims are shown that reduce by construction to fitted parameters defined inside the method itself. The central claims rest on explicit design decisions plus multi-metric experimental results on external benchmarks, with ablations that isolate the 1D interface contribution. No self-citation chain, ansatz smuggling, or renaming of known results appears in the provided derivation steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 1D token space from a frozen pretrained image tokenizer can effectively model non-local appearance and base factors when used as a global carrier.
invented entities (1)
-
Selective Token Editing (STE)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Multi-modality Image Fusion under Adverse Weather: Mask-Guided Feature Restoration and Interaction
Mask-guided MMIF method with pseudo ground truth and cross-attention for feature restoration and interaction under adverse weather, claiming SOTA results on synthetic and real data.
Reference graph
Works this paper leans on
-
[1]
ICML , pages=
Crafting papers on machine learning , author=. ICML , pages=
-
[2]
IEEE TIP , year=
Image quality assessment: from error visibility to structural similarity , author=. IEEE TIP , year=
-
[3]
IEEE TCOM , year=
Image quality measures and their performance , author=. IEEE TCOM , year=
-
[4]
International Journal of Engineering Science Invention , year=
Hybrid multimodality medical image fusion technique for feature enhancement in medical diagnosis , author=. International Journal of Engineering Science Invention , year=
-
[5]
Optics Communications , year=
Detail preserved fusion of visible and infrared images using regional saliency extraction and multi-scale image decomposition , author=. Optics Communications , year=
-
[6]
arXiv preprint arXiv:2401.00421 , year=
From text to pixels: A context-aware semantic synergy solution for infrared and visible image fusion , author=. arXiv preprint arXiv:2401.00421 , year=
-
[7]
arXiv preprint arXiv:2603.03871 , year=
Bridging Human Evaluation to Infrared and Visible Image Fusion , author=. arXiv preprint arXiv:2603.03871 , year=
-
[8]
ACM MM , year=
Toward a Training-Free Plug-and-Play Refinement Framework for Infrared and Visible Image Registration and Fusion , author=. ACM MM , year=
-
[9]
NeurIPS , year=
Efficient Rectified Flow for Image Fusion , author=. NeurIPS , year=
-
[10]
arXiv preprint arXiv:2603.14214 , year=
UniFusion: A Unified Image Fusion Framework with Robust Representation and Source-Aware Preservation , author=. arXiv preprint arXiv:2603.14214 , year=
-
[11]
AAAI , year=
Domain Adaptation Guided Infrared and Visible Image Fusion , author=. AAAI , year=
-
[12]
IEEE/CAA Journal of Automatica Sinica , year=
PromptFusion: Harmonized semantic prompt learning for infrared and visible image fusion , author=. IEEE/CAA Journal of Automatica Sinica , year=
-
[13]
arXiv preprint arXiv:2601.03955 , year=
ResTok: Learning Hierarchical Residuals in 1D Visual Tokenizers for Autoregressive Image Generation , author=. arXiv preprint arXiv:2601.03955 , year=
-
[14]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[15]
M. J. Kearns , title =
-
[16]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[17]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[18]
Suppressed for Anonymity , author=
-
[19]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[20]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[21]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[22]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[23]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[24]
Proceedings of the 40th International Conference on Machine Learning (ICML) , pages =
Fast inference from transformers via speculative decoding , author =. Proceedings of the 40th International Conference on Machine Learning (ICML) , pages =. 2023 , volume =
2023
-
[25]
Advances in Neural Information Processing Systems (NeurIPS) , year =
SpecTr: Fast Speculative Decoding via Optimal Transport , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[26]
IEEE Transactions on Information Theory , volume =
On Optimum Recognition Error and Reject Tradeoff , author =. IEEE Transactions on Information Theory , volume =
-
[27]
arXiv preprint arXiv:2307.02764 , year =
When Does Confidence-Based Cascade Deferral Suffice? , author =. arXiv preprint arXiv:2307.02764 , year =
-
[28]
International Conference on Learning Representations (ICLR) , year =
Language Model Cascades: Token-level Uncertainty and Beyond , author =. International Conference on Learning Representations (ICLR) , year =
-
[29]
Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS) , year =
Speculative Decoding with Big Little Decoder , author =. Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS) , year =
-
[30]
Advances in Neural Information Processing Systems , volume =
Blockwise parallel decoding for deep autoregressive models , author =. Advances in Neural Information Processing Systems , volume =
-
[31]
Patterson , title =
David A. Patterson , title =. Communications of the ACM , volume =. 2004 , publisher =
2004
-
[32]
Hennessy and David A
John L. Hennessy and David A. Patterson , title =. 2012 , publisher =
2012
-
[33]
CoRR , volume =
Xiaoxuan Liu and Lanxiang Hu and Peter Bailis and Ion Stoica and Zhijie Deng and Alvin Cheung and Hao Zhang , title =. CoRR , volume =. 2023 , url =
2023
-
[34]
R. Svirschevski and A. May and Z. Chen and B. Chen and Z. Jia and M. Ryabinin , title =. arXiv preprint arXiv:2406.02532 , year =
-
[35]
C. Hooper and S. Kim and H. Mohammadzadeh and H. Genc and K. Keutzer and A. Gholami and S. Shao , title =. arXiv preprint arXiv:2310.12072 , year =
-
[36]
Noam M. Shazeer , title =. arXiv preprint arXiv:1911.02150 , year =
Pith/arXiv arXiv 1911
-
[37]
F. W. Burton , title =. IEEE Transactions on Computers , volume =. 1985 , doi =
1985
-
[38]
The Thirteenth International Conference on Learning Representations , year=
Faster Cascades via Speculative Decoding , author=. The Thirteenth International Conference on Learning Representations , year=
-
[39]
Information Geometry and Its Applications , author =
-
[40]
Elements of Information Theory (2nd ed.) , author =
-
[41]
2016 , publisher=
Information Geometry and Its Applications , author=. 2016 , publisher=
2016
-
[42]
arXiv preprint arXiv:2406.17276 , year =
Opt-Tree: Speculative Decoding with Adaptive Draft Tree Structure , author =. arXiv preprint arXiv:2406.17276 , year =
-
[43]
arXiv preprint arXiv:2305.09781 , year =
SpecInfer: Accelerating Generative Large Language Model Serving with Tree-based Speculative Inference and Verification , author =. arXiv preprint arXiv:2305.09781 , year =
-
[44]
arXiv preprint arXiv:2401.10774 , year =
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads , author =. arXiv preprint arXiv:2401.10774 , year =
-
[45]
arXiv preprint arXiv:2401.15077 , year =
Eagle: Speculative Sampling Requires Rethinking Feature Uncertainty , author =. arXiv preprint arXiv:2401.15077 , year =
-
[46]
CoRR , volume =
Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding , author =. CoRR , volume =. 2023 , url =
2023
-
[47]
CoRR , volume =
Predictive Pipelined Decoding: A Compute-Latency Trade-off for Exact LLM Decoding , author =. CoRR , volume =. 2023 , url =
2023
-
[48]
arXiv preprint arXiv:2402.12374 , year =
Sequoia: Scalable, Robust, and Hardware-Aware Speculative Decoding , author =. arXiv preprint arXiv:2402.12374 , year =
-
[49]
arXiv preprint arXiv:2409.16560 , year =
Dynamic-Width Speculative Beam Decoding for Efficient LLM Inference , author =. arXiv preprint arXiv:2409.16560 , year =
-
[50]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =
Speculative decoding: Exploiting speculative execution for accelerating seq2seq generation , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =. 2023 , address =
2023
-
[51]
2006 , publisher=
Elements of Information Theory , author=. 2006 , publisher=
2006
-
[52]
Transactions of the Association for Computational Linguistics , year=
Speculative decoding with token-wise acceptance prediction , author=. Transactions of the Association for Computational Linguistics , year=
-
[53]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Training deeper neural networks by skip-layer connections , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[54]
CVPR , year=
Densely connected convolutional networks , author=. CVPR , year=
-
[55]
NeurIPS , year=
LLM-ZIP: Efficient LLM Inference via Layer Skipping , author=. NeurIPS , year=
-
[56]
2023 , eprint=
DistillSpec: Improving Speculative Decoding via Knowledge Distillation , author=. 2023 , eprint=
2023
-
[57]
Leibler , title =
Solomon Kullback and Richard A. Leibler , title =. Annals of Mathematical Statistics , volume =. 1951 , publisher =
1951
-
[58]
2025 , eprint=
Cascade Speculative Drafting for Even Faster LLM Inference , author=. 2025 , eprint=
2025
-
[59]
arXiv preprint arXiv:2412.18934 , year=
Dovetail: A CPU/GPU heterogeneous speculative decoding for LLM inference , author=. arXiv preprint arXiv:2412.18934 , year=
-
[60]
and Zhou, Z
Li, C. and Zhou, Z. and Zheng, S. and Zhang, J. and Liang, Y. and Sun, G. , booktitle=. 2024 , publisher=
2024
-
[61]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025), Long Papers , pages =
CLaSp: In-Context Layer Skip for Self-Speculative Decoding , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025), Long Papers , pages =. 2025 , publisher =
2025
-
[62]
Advances in Neural Information Processing Systems , volume =
Speculative Decoding with Big Little Decoder , author =. Advances in Neural Information Processing Systems , volume =. 2023 , publisher =
2023
-
[63]
arXiv preprint arXiv:2302.01318 , year=
Accelerating large language model decoding with speculative sampling , author=. arXiv preprint arXiv:2302.01318 , year=
-
[64]
2025 , url=
Heming Xia and Yongqi Li and Jun Zhang and Cunxiao Du and Wenjie Li , booktitle=. 2025 , url=
2025
-
[65]
Unsupervised Thoughts (blog) , author=
An optimal lossy variant of speculative decoding , url=. Unsupervised Thoughts (blog) , author=
-
[66]
arXiv preprint arXiv:2403.06075 , year=
Multisize dataset condensation , author=. arXiv preprint arXiv:2403.06075 , year=
-
[67]
Journal of Machine Learning Research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of Machine Learning Research , volume=. 2020 , url=
2020
-
[68]
arXiv preprint arXiv:2408.00118 , year=
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
-
[69]
2017 , publisher=
Markov chains and mixing times , author=. 2017 , publisher=
2017
-
[70]
Proceedings of the Ninth Workshop on Statistical Machine Translation , pages=
Findings of the 2014 workshop on statistical machine translation , author=. Proceedings of the Ninth Workshop on Statistical Machine Translation , pages=
2014
-
[71]
arXiv preprint arXiv:2408.11850 , year=
Pearl: Parallel speculative decoding with adaptive draft length , author=. arXiv preprint arXiv:2408.11850 , year=
-
[72]
arXiv preprint arXiv:2406.16858 , year=
Eagle-2: Faster inference of language models with dynamic draft trees , author=. arXiv preprint arXiv:2406.16858 , year=
-
[73]
arXiv preprint arXiv:2503.01840 , year=
Eagle-3: Scaling up inference acceleration of large language models via training-time test , author=. arXiv preprint arXiv:2503.01840 , year=
-
[74]
Advances in Neural Information Processing Systems , volume=
Teaching machines to read and comprehend , author=. Advances in Neural Information Processing Systems , volume=
-
[75]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
Don't give me the details, just the summary! Topic-aware convolutional neural networks for extreme summarization , author=. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
2018
-
[76]
arXiv preprint arXiv:2108.07732 , year=
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
-
[77]
Transactions of the Association for Computational Linguistics , volume=
Natural questions: A benchmark for question answering research , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , doi=
2019
-
[78]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2017 , doi=
2017
-
[79]
Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing , pages=
Semantic parsing on freebase from question-answer pairs , author=. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing , pages=
2013
-
[80]
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages=
SQuAD: 100,000+ questions for machine comprehension of text , author=. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages=. 2016 , doi=
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.