DynamicMem: A Long-Horizon Memory Benchmark in Real-World Settings
Pith reviewed 2026-06-26 08:40 UTC · model grok-4.3
The pith
DynamicMem benchmark shows profile reconstruction accuracy falls as history length grows to 15 months while service-task accuracy stays flat.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
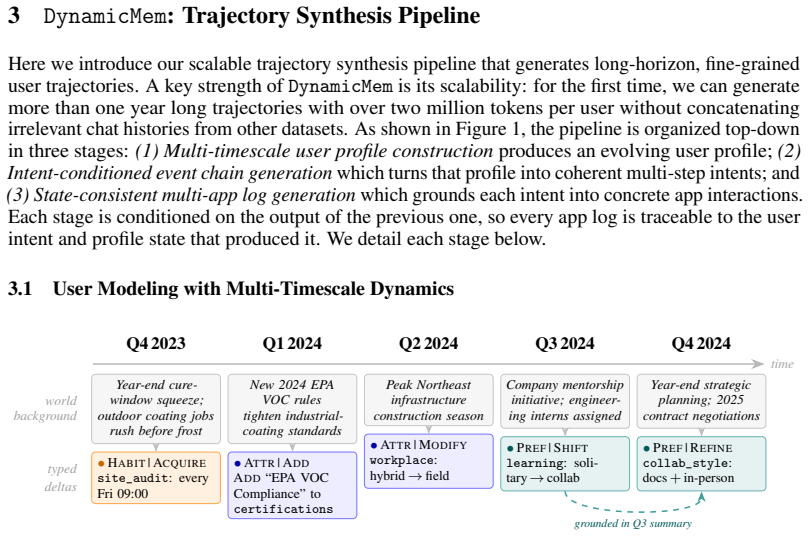
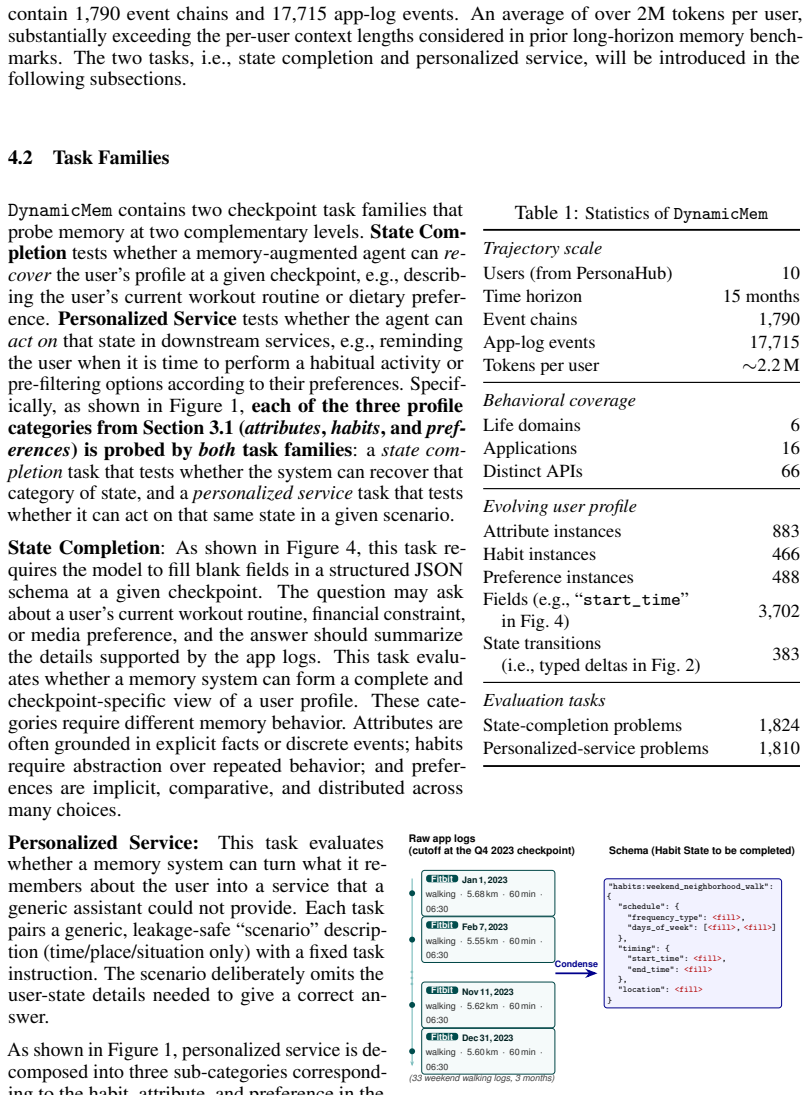
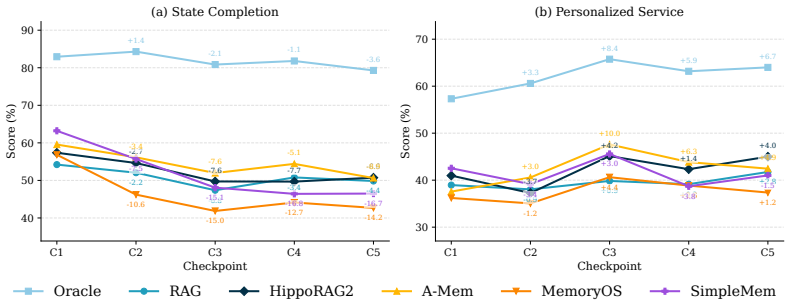
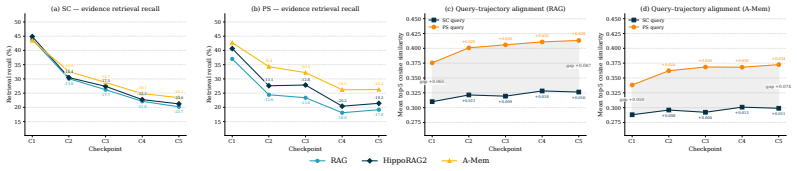
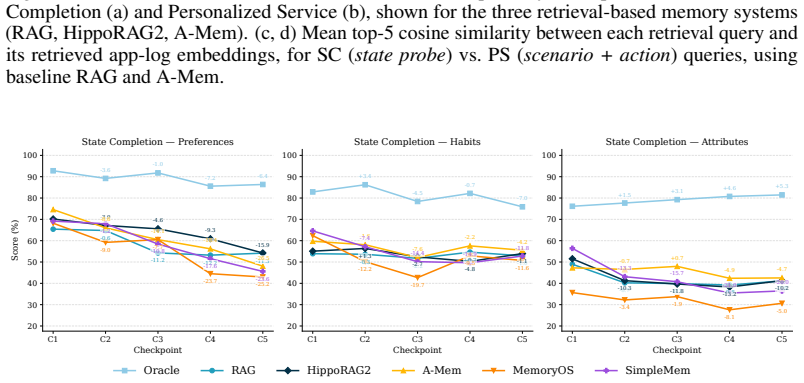
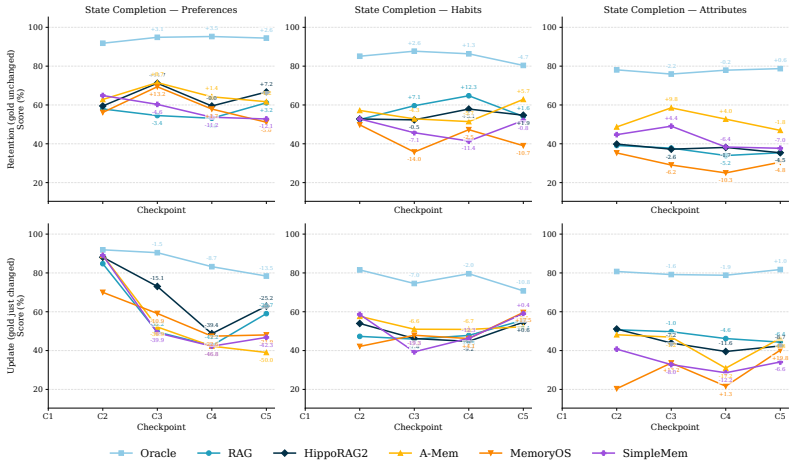
DynamicMem constructs user-consistent trajectories averaging 2.2 million tokens and 1,772 grounded events per user across 16 applications, with the profile evolving without ever being given explicitly. At five quarterly checkpoints, five representative systems show profile reconstruction degrading with history length while service-task accuracy remains unchanged, no system succeeds at both keeping facts that stay true and replacing facts that change, and more than 93 percent of failures trace to what the memory retrieves rather than to answer generation.
What carries the argument
The DynamicMem generator that produces 15-month multi-app trajectories with heterogeneous profile evolution inferred from scattered implicit signals.
If this is right
- Profile reconstruction accuracy decreases as the amount of history grows.
- No evaluated system both retains facts that remain true and updates facts that change, with errors concentrated on preferences and exact referents.
- Over 93 percent of failures originate in memory retrieval rather than in how the model writes the final answer.
Where Pith is reading between the lines
- Memory designs could prioritize selective retention and targeted update rules to address the observed split between stable and changing facts.
- Testing the same checkpoint protocol on logs from actual apps would check whether the synthetic generation process matches real user patterns.
- Focusing improvements on retrieval mechanisms would likely lift overall performance more than changes to answer generation alone.
- The quarterly evaluation setup could be applied to other long-horizon agent tasks beyond memory.
Load-bearing premise
The synthetic trajectories accurately reflect the heterogeneous timelines, external-context changes, and scattered implicit evidence of real multi-app user behavior.
What would settle it
A memory system tested on the same 15-month trajectories that maintains or improves profile reconstruction accuracy as history length increases and correctly distinguishes stable facts from changing ones would falsify the reported scaling problems.
Figures




read the original abstract
LLM agents increasingly act as personal assistants that must remember a user's profile over months: who they are (attributes), what they routinely do (habits), and what they prefer (preferences), and keep it updated as jobs, routines, and tastes drift. Existing benchmarks evaluate this "memory" ability through short, simplified interactions, missing three core properties of real behavior: the profile is heterogeneous, with attributes, habits, and preferences evolving on different timelines; changes are driven by external context such as seasons and life events; and evidence is rarely stated explicitly, instead scattered across many small actions in different apps that a memory system must infer from. We introduce DynamicMem, a synthetic benchmark that constructs 15 months of activity per user, providing long-term multi-app data that real users' privacy keeps out of reach. It provides user-consistent trajectories averaging 2.2M tokens and 1,772 grounded events per user across 16 applications such as e-commerce, fitness, and social platforms. The profile evolves over this period and is never given explicitly: each attribute, habit, or preference must be inferred from small signals scattered across apps. We evaluate at five quarterly checkpoints to track how systems scale as history grows. Benchmarking five representative systems exposes problems a single accuracy score hides: (i) profile reconstruction degrades with history length while service-task accuracy stays flat, despite both drawing on the same memory; (ii) no system both keeps facts that stay true and replaces facts that change, with errors clustering on preferences and on naming the exact referent; and (iii) over 93% of failures trace to what the memory retrieves, not to the model writing the answer, so the largest room for improvement lies in memory itself. Code: https://wenyaxie023.github.io/DynamicMem/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce DynamicMem, a synthetic benchmark for long-horizon memory in LLM-based personal assistants. It generates 15 months of multi-app user activity (2.2M tokens, 1,772 events across 16 apps) where profiles evolve implicitly and must be inferred. Evaluating five systems at quarterly checkpoints reveals that profile reconstruction degrades with history length (unlike service tasks), no system effectively retains stable facts while updating changed ones (errors on preferences and exact referents), and >93% of failures are retrieval-related rather than generation-related.
Significance. If valid, the benchmark and findings would be significant for highlighting that memory retrieval, not just model capacity, is the primary bottleneck in long-term personal assistance, and that single accuracy metrics obscure important failure modes. The open code supports reproducibility and further research on memory systems.
major comments (2)
- [Benchmark Construction] Benchmark Construction section: The mechanisms used to generate the 2.2M-token trajectories, ensure grounding of 1,772 events, enforce user consistency across apps, and produce heterogeneous timelines with external-context-driven changes and scattered implicit evidence are not described in sufficient detail. This is load-bearing for the central claims, as the reported contrasts (degrading profile reconstruction vs. flat service-task accuracy) and error clusters (on preferences and exact referents) could be artifacts of the simulator's sampling rules rather than properties of real multi-app behavior.
- [Results] Results section (analysis of failure modes): The claim that over 93% of failures trace to retrieval rather than answer writing requires an explicit description of the attribution methodology (e.g., how retrieval vs. generation errors were isolated across the five systems and checkpoints). Without this, it is unclear whether the percentage generalizes or depends on particular implementation choices in the evaluated memory systems.
minor comments (1)
- [Abstract] Abstract: '2.2M tokens' should be expanded to 'approximately 2.2 million tokens' on first use for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on benchmark construction and failure-mode analysis. We address each major comment below and will revise the manuscript accordingly to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark Construction section: The mechanisms used to generate the 2.2M-token trajectories, ensure grounding of 1,772 events, enforce user consistency across apps, and produce heterogeneous timelines with external-context-driven changes and scattered implicit evidence are not described in sufficient detail. This is load-bearing for the central claims, as the reported contrasts (degrading profile reconstruction vs. flat service-task accuracy) and error clusters (on preferences and exact referents) could be artifacts of the simulator's sampling rules rather than properties of real multi-app behavior.
Authors: We agree that the Benchmark Construction section requires substantially more detail on the generation pipeline. The current manuscript outlines the high-level properties (15-month multi-app trajectories, implicit profile evolution, cross-app consistency) but does not provide the concrete sampling rules, grounding procedures, consistency enforcement logic, or external-context injection mechanisms. In the revised version we will expand this section with pseudocode for the trajectory generator, explicit rules for event grounding and cross-app consistency checks, and examples illustrating how external contexts produce heterogeneous timelines and scattered implicit evidence. These additions will allow readers to assess whether the reported contrasts and error patterns are artifacts of the simulator or reflect the intended long-horizon memory challenges. revision: yes
-
Referee: [Results] Results section (analysis of failure modes): The claim that over 93% of failures trace to retrieval rather than answer writing requires an explicit description of the attribution methodology (e.g., how retrieval vs. generation errors were isolated across the five systems and checkpoints). Without this, it is unclear whether the percentage generalizes or depends on particular implementation choices in the evaluated memory systems.
Authors: We agree that the attribution methodology must be described explicitly. Our analysis classified each error by first checking whether the ground-truth fact appeared in the memory system's retrieved context (retrieval failure) versus whether the fact was retrieved but then incorrectly synthesized or omitted during answer generation. We will add a dedicated subsection in Results that formalizes this decision procedure, lists the exact criteria applied uniformly across all five systems and five checkpoints, and reports any edge-case handling. This will make the 93% figure reproducible and clarify its dependence on the evaluated memory implementations. revision: yes
Circularity Check
No circularity: benchmark evaluation is independent of self-referential inputs or fitted parameters
full rationale
The paper introduces DynamicMem as an external synthetic benchmark constructed from explicit generation rules for 15-month user trajectories across 16 apps, then evaluates five existing memory systems on it at quarterly checkpoints. No derivation chain, equations, or first-principles predictions are present; the reported observations (degrading profile reconstruction, inability to retain vs. update facts, 93% retrieval failures) are direct empirical measurements on the generated data rather than quantities forced by construction from fitted parameters or self-citations. The synthetic generator is described as producing the trajectories but does not tautologically encode the specific error patterns or contrasts claimed as results. No load-bearing self-citations or uniqueness theorems appear. The work is self-contained as a standard benchmark contribution whose central claims rest on observable system behavior rather than reduction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption User profiles are heterogeneous with attributes, habits, and preferences evolving on different timelines driven by external context such as seasons and life events.
- domain assumption Evidence for profile elements is rarely stated explicitly and is instead scattered across many small actions in different apps.
Forward citations
Cited by 1 Pith paper
-
A-TMA: Decoupling State-Aware Memory Failures in Long-Term Agent Memory
ATMA adds state labels and evidence packets to existing memory systems to reduce ghost memory failures, with reported gains on a new LTP benchmark and LoCoMo.
Reference graph
Works this paper leans on
-
[1]
Core is the central value, relationship, direction, routine component, or attribute that must be present for the prediction to be practically the same profile information
Identify the requested field’s core meaning from state_key, field_path, and golden. Core is the central value, relationship, direction, routine component, or attribute that must be present for the prediction to be practically the same profile information
-
[2]
Decide core_correct. Set true when the predicted entry captures that core meaning, even if details are incomplete; set false when the prediction omits the field, contradicts it, gives a different core value, or is too vague to identify the same field meaning
-
[3]
Detail means supporting precision beyond the core, such as exact wording, exact time, exact encoding, qualifiers, constraints, tier/version, branch/address, examples, or scope
Decide detail_quality. Detail means supporting precision beyond the core, such as exact wording, exact time, exact encoding, qualifiers, constraints, tier/version, branch/address, examples, or scope. Use 2 when key details are complete and accurate; 1 when important details are missing, vague, or slightly imprecise; 0 when details are mostly missing, wron...
-
[6]
Judge each requestedfield_pathindependently, while using the full predicted profile entry as context
-
[9]
field_judgments
In every field judgment, writeanalysisbeforecore_correctanddetail_quality. [Example] [Example Input] {example_input} [Example Output] {example_output} 27 [Input/Output Format] Input:state_key,golden,predicted,fields_to_judge. Output JSON only: { "field_judgments": [ { "field_path": "<field_path>", "analysis": "<brief analysis before the labels>", "core_co...
-
[10]
Core is the central service meaning that must be present for the pre- dicted response to be practically useful for the same personalized service moment
Identify the requested field’s core service value from scenario, task_instruction, field_path, fields_to_judge, and reference. Core is the central service meaning that must be present for the pre- dicted response to be practically useful for the same personalized service moment. Core belongs to the service output field being judged, not to a raw source record
-
[11]
Decide core_correct. Set true when the predicted response captures that core service value, even if details are incomplete; set false when the prediction omits the field, contradicts it, gives a different core value, targets a different service moment, or is too vague to identify the same field meaning
-
[12]
Decide detail_quality. Detail means service-useful precision beyond the core, such as exact time, date, place, cadence, exact encoding, qualifiers, exclusions, constraints, tier/version, branch/address, examples, or scope. Use 2 when key details are complete and accurate; 1 when important details are missing, vague, or slightly imprecise; 0 when details a...
-
[13]
Judge only the requestedfields_to_judge
-
[14]
Return every requestedfield_pathexactly once
-
[15]
Judge each requestedfield_pathindependently, while using the full predicted response and service context
-
[16]
Usedetail_qualityonly for detail completeness and precision; do not use it to overridecore_correct
-
[17]
Do not require exact wording, JSON field names, key order, or identical formatting when the meaning is semantically equivalent
-
[18]
Do not penalize the prediction for not restating source records when the service output is correct, but do penalize missing details needed for the service response to be specific and actionable
-
[19]
field_judgments
In every field judgment, writeanalysisbeforecore_correctanddetail_quality. [Example] [Example Input] {example_input} [Example Output] {example_output} [Input/Output Format] Input:scenario,task_instruction,reference,predicted,fields_to_judge. 28 Output JSON only: { "field_judgments": [ { "field_path": "<field_path>", "analysis": "<brief analysis before the...
-
[20]
Extract explicit facts from the description
-
[21]
Infer missing details to create a complete, coherent profile
-
[22]
Ensure all fields are internally consistent (e.g., student income matches student occupation)
-
[23]
age": <integer 18-85>,
Choose specific values: no vague or placeholder text. [Consistency Rules] –Students: income Low/Lower_Mid, work_hours 0–25, education Associate/Bachelor. –Full-time workers: work_hours 35–50, income Mid or higher. –Parents with young children: caregiving_load Moderate/High, household_size 2+. –Age & education: Bachelor typically 22+, Master 24+, Doctorate...
2023
-
[24]
Use generic types, not specific names
-
[25]
Extract only what’s in habits or blocks scheduling
-
[26]
Minimize entries: 4 time_budgets, 3–5 edges, 5–8 places
-
[27]
change_type
If unsure, omit (better sparse than speculative). Life Context Delta [Task Instruction] You are a constraint delta agent. Analyze a time window to identify TEMPORARY changes to the user’s life context constraints. [Input] –basic_profile: {user_basic_profile_json}. –baseline: {life_context_baseline_json}. –time_window: {window_description}, {window_summary...
-
[28]
Only generate deltas with explicit evidence in window text
-
[29]
entire window
Specifyeffective_dateswhen possible (rather than “entire window”)
-
[30]
Prefersuspendoverdelete: constraints usually return after the window
-
[31]
Bitcoin Halving
Don’t infer lifestyle from events (e.g., “Bitcoin Halving” does not change schedule)
-
[32]
window_id
Don’t duplicate baseline seasonal modifiers. Events Chain Generation [Task Instruction] You are an expert at generating realistic event chains that demonstrate user behaviors based on their dynamic profile state. Given a user’s state for a specific time window, generate a sequence of realistic events that would naturally occur based on their attributes, h...
-
[33]
JSON only; no markdown or commentary outside the JSON
-
[34]
Schema fidelity: every required field present and correctly typed
-
[35]
No hallucinated apps/APIs; this prompt is scoped to the single API inapi_schema
-
[36]
Stay consistent withprevious_chain_logsandapp_state
-
[37]
J.4 Evaluation Task Construction Prompt Personalized Service Task – Habit Reminder [Task] Generate exactly one habit-conditioned communication task for a user-facing assistant
Reflect theuser_intentend-to-end: input asks for it, output delivers it. J.4 Evaluation Task Construction Prompt Personalized Service Task – Habit Reminder [Task] Generate exactly one habit-conditioned communication task for a user-facing assistant. Each item contains scenario, task_instruction (copy fixed string exactly), and reference_answer. The task s...
-
[39]
Output JSON only with one top-level keyitemcontainingscenario,task_instruction,reference_answer
-
[41]
I”, “we”, “you
scenario must be short, concrete, third-person world background; no first/second-person (“I”, “we”, “you”, “your”, “you’ve”)
-
[42]
For schedule day fields, clock time alone is insufficient
scenario must anchor the current moment clearly (weekly/weekday routines: weekday + clock time; monthly/date- like routines: calendar anchor + clock time). For schedule day fields, clock time alone is insufficient
-
[43]
scenario may include only: the current moment; whether something has or has not happened yet; whether something has or has not been prepared; at most one additional plausible situational fact
-
[44]
scenario must not restate or paraphrase the routine action, frequency, stored start time, end time, location, or any other personalized habit fact already instate_value
-
[45]
reference_answer is exactly one natural assistant-to-user message; complete enough that a fully correct answer would use every terminal field instate_value
-
[46]
habits_state:client_technical_briefing
Before finalizing, silently confirm: answerability, service_realism, full_field_dependency, low_leakage, out- put_groundedness. [Good Example] state_key: "habits_state:client_technical_briefing" state_value: {"schedule": {"frequency_type": "weekly", "days_of_week": [0]}, "timing": {"start_time": "10:00"}, "location": "regional corporate headquarters"} {"i...
-
[50]
a filtering step is about to run
scenario short, natural, world-background; no first/second-person; plausible user product moment, not a backend log line. Avoid robotic phrasing (“a filtering step is about to run”, etc.)
-
[51]
6.scenariomust not restate or paraphrase the user’s actual preference content
scenario may include only: immediate user goal or option space; the assistant setting search/filter fields; at most one additional situational fact. 6.scenariomust not restate or paraphrase the user’s actual preference content. 35
-
[52]
output_template and reference_output have the same nested shape; every leaf in output_template is the string<fill>
-
[53]
At least one is a core fill; a second may be a detail fill when grounded and service-useful
output_template contains one or two fill leaves total. At least one is a core fill; a second may be a detail fill when grounded and service-useful
-
[54]
reference_anchors: one object per fill leaf with target_path, role (core|detail), state_reference, anchor_note
-
[55]
Do not use a fixed universal key like preference_statement; synthesize request-facing keys that decompose the preference into meaningful filtering dimensions (preferred types, desired attributes, required features, avoided options, priorities)
-
[56]
Every filled value inreference_outputmust be supported bystate_value
-
[57]
preferences_state:learning_modality
Before finalizing, silently confirm: answerability, service_realism, full_field_dependency, low_leakage, out- put_groundedness. [Good Example] state_key: "preferences_state:learning_modality" state_value: {"statement": "Prefers in-depth, self-paced technical white papers and webinars over large live conferences"} {"item": { "scenario": "The user is browsi...
-
[58]
Generate exactly one item
-
[59]
Output JSON only with one top-level key item containing scenario, task_instruction, output_template, reference_output,reference_anchors
-
[60]
Copytask_instructionexactly as the fixed string {fixed_task_instruction}
-
[61]
scenario short, natural, world-background; no first/second-person; plausible user product moment. Prefer natural situations: completing checkout, finishing a setup flow, preparing a profile/form before submission, connecting a de- vice/account, the assistant auto-filling setup/form fields
-
[62]
It must not restate or paraphrase the user’s actual attribute values
scenario may include only: immediate user goal/action; the assistant filling setup/form/configuration fields; at most one additional situational fact. It must not restate or paraphrase the user’s actual attribute values
-
[63]
output_template and reference_output have the same nested shape; every leaf in output_template is the string<fill>; one or two fill leaves total
-
[64]
8.reference_anchors: one object per fill leaf withtarget_path,role,state_reference,anchor_note
At least one fill leaf is a core fill; a second may be a detail fill when grounded and service-useful. 8.reference_anchors: one object per fill leaf withtarget_path,role,state_reference,anchor_note
-
[65]
Do not invent facts not directly instate_value
Prefer configuration-facing schemas that decompose compound attribute strings into execution-relevant fields when supported. Do not invent facts not directly instate_value
-
[66]
Avoid scenarios that require an extra user choice not instate_value (subset, quantity, recipient, priority, destination, commitment)
-
[67]
Every filled value in reference_output must be supported by state_value; for list-valued state preserve source order when configuration represents per-item entries
-
[68]
user_attributes_state:primary_job_role
Before finalizing, silently confirm: answerability, service_realism, full_field_dependency, low_leakage, out- put_groundedness. [Good Example] state_key: "user_attributes_state:primary_job_role" state_value: "Senior Coatings Consultant at PPG Industries (specializing in heavy-duty infrastructure and marine protection)" {"item": { "scenario": "The user is ...
-
[69]
Does the cited evidence contain any content about what the question is asking ? Use the gold answer to d et er min e what ’on - topic ’ means
R el ev anc e check . Does the cited evidence contain any content about what the question is asking ? Use the gold answer to d et er min e what ’on - topic ’ means . - NO -> label = I r r e l e v a n t _ E v i d e n c e . Stop . - YES -> continue
-
[70]
Identity check . Does at least one evidence entry e st ab lis h the gold answer ’ s IDENTITY ( the activity identity for habits , the p r e f e r e n c e di re ct io n for preferences , the named entity for a t t r i b u t e s ) ? - The identity is not e s t a b l i s h a b l e from any evidence entry -> label = I d e n t i t y _ M i s s . Stop . - The id...
-
[71]
Detail check . Does the cited evidence include the gold answer ’ s field - level DETAILS ( specific day , specific time , specific location , named options , year / version , etc .) ? - Any required detail is absent ( evidence carries the identity but does not mention the gold ’ s specific details ) -> label = D e t a i l _ M i s s . Stop . 39 - The detai...
-
[72]
label ":
All checks passed : relevance , identity , and details are all clearly present and u n a m b i g u o u s in the cited evidence . Since we know the p r e d i c t i o n still failed , the failure is a t t r i b u t a b l e to the answer model rather than the memory system . -> label = A ll_ Cl ea r . OUTPUT FORMAT ( JSON ) { " label ": " < one of : I r r e ...
2022
-
[73]
Does the cited evidence contain any content about what the scenario is asking the system to ground in ? Use the gold answer to de te rm ine what ’on - topic ’ means
R el ev anc e check . Does the cited evidence contain any content about what the scenario is asking the system to ground in ? Use the gold answer to de te rm ine what ’on - topic ’ means . - NO -> label = I r r e l e v a n t _ E v i d e n c e . Stop . - YES -> continue
-
[74]
Identity check . Does at least one evidence entry e st ab lis h the gold answer ’ s IDENTITY ( the activity identity for habits , the p r e f e r e n c e di re ct io n for preferences , the named entity for a t t r i b u t e s ) ? - The identity is not e s t a b l i s h a b l e from any evidence entry -> label = I d e n t i t y _ M i s s . Stop . - The id...
-
[75]
Detail check . Does the cited evidence include the gold answer ’ s field - level DETAILS ( specific day , specific time , specific location , named options , year / version , etc .) ? - Any required detail is absent -> label = D e t a i l _ M i s s . Stop . 43 - Details are present BUT c o n t r a d i c t e d by co mp et ing a l t e r n a t i v e details ...
-
[76]
label ":
All checks passed : relevance , identity , and details are all clearly present and u n a m b i g u o u s in the cited evidence . Since we know the response still failed , the failure is a t t r i b u t a b l e to the answer model rather than the memory system . -> label = A ll_ Cl ea r . OUTPUT FORMAT ( JSON ) { " label ": " < one of : I r r e l e v a n t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.