Using 3D Convolutional Neural Networks to Learn Spatiotemporal Features for Automatic Surgical Gesture Recognition in Video
Pith reviewed 2026-05-24 15:57 UTC · model grok-4.3
The pith
A 3D CNN learns joint spatiotemporal features from video frames to recognize surgical gestures at over 84 percent frame-wise accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
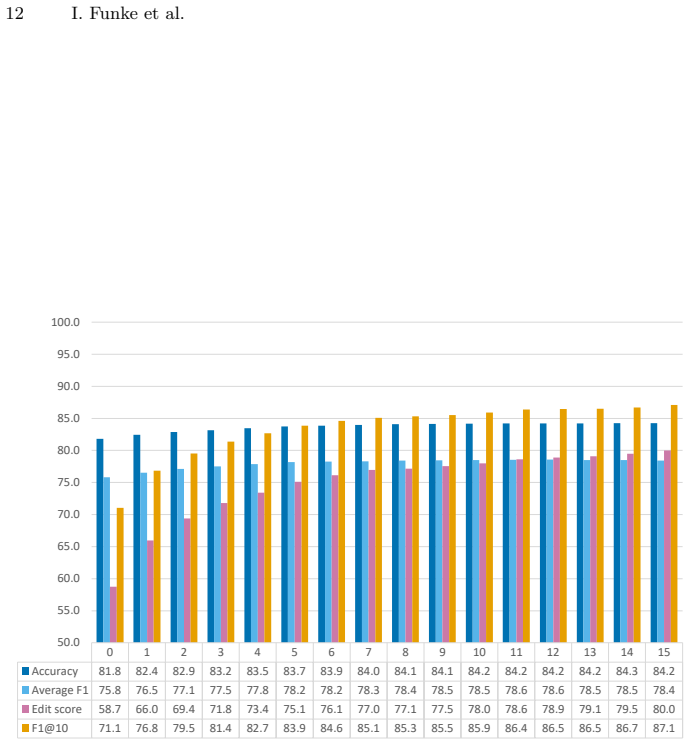
The central claim is that a 3D CNN trained directly on consecutive video frames can learn spatiotemporal features for surgical gesture recognition, producing frame-wise accuracies of more than 84 percent on the JIGSAWS robot-assisted suturing recordings and outperforming models that extract only spatial features or treat spatial and low-level temporal information separately.
What carries the argument
3D Convolutional Neural Network that takes stacks of consecutive video frames as input and jointly computes spatial and temporal filters across the volume.
If this is right
- Video-only gesture recognition becomes feasible at low cost in any operating room equipped with a standard laparoscope.
- Automatic skill assessment and intra-operative alerts for critical steps can be built without attaching extra tracking hardware to the instruments.
- The same architecture can be retrained on other recorded procedures once labeled gesture data for those tasks exists.
- Real-time deployment on surgical video streams becomes practical if the 3D network is optimized for inference speed.
Where Pith is reading between the lines
- Extending the input stack length or adding recurrent layers on top of the 3D features might capture longer-range dependencies that single 3D convolutions miss.
- The approach could be tested on full-length procedures rather than short bench-top suturing clips to check whether performance holds when gesture transitions are rarer.
- Combining the learned spatiotemporal features with kinematic data from the robot, when available, would likely raise accuracy further but would lose the pure-video advantage.
Load-bearing premise
The reported accuracy advantage is caused by the joint spatiotemporal modeling inside the 3D CNN rather than by differences in network size, training schedule, or preprocessing steps.
What would settle it
An ablation study that trains a 2D CNN baseline and a 3D CNN on identical network capacity, identical data splits, and identical optimization settings, then measures whether the 3D version still shows a clear accuracy gain on the same suturing videos.
Figures


read the original abstract
Automatically recognizing surgical gestures is a crucial step towards a thorough understanding of surgical skill. Possible areas of application include automatic skill assessment, intra-operative monitoring of critical surgical steps, and semi-automation of surgical tasks. Solutions that rely only on the laparoscopic video and do not require additional sensor hardware are especially attractive as they can be implemented at low cost in many scenarios. However, surgical gesture recognition based only on video is a challenging problem that requires effective means to extract both visual and temporal information from the video. Previous approaches mainly rely on frame-wise feature extractors, either handcrafted or learned, which fail to capture the dynamics in surgical video. To address this issue, we propose to use a 3D Convolutional Neural Network (CNN) to learn spatiotemporal features from consecutive video frames. We evaluate our approach on recordings of robot-assisted suturing on a bench-top model, which are taken from the publicly available JIGSAWS dataset. Our approach achieves high frame-wise surgical gesture recognition accuracies of more than 84%, outperforming comparable models that either extract only spatial features or model spatial and low-level temporal information separately. For the first time, these results demonstrate the benefit of spatiotemporal CNNs for video-based surgical gesture recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes using 3D Convolutional Neural Networks to learn joint spatiotemporal features directly from sequences of laparoscopic video frames for frame-wise surgical gesture recognition. It evaluates the method on robot-assisted suturing recordings from the public JIGSAWS dataset and reports frame-wise accuracies above 84%, claiming outperformance over models that extract only spatial features or handle spatial and temporal information separately.
Significance. If the performance advantage can be rigorously attributed to the 3D CNN architecture, the result would be significant for video-based surgical analysis by showing that end-to-end spatiotemporal feature learning improves gesture recognition without additional sensors. The work addresses a practical clinical problem and uses a public benchmark, but the current evidence does not yet isolate the contribution of joint spatiotemporal modeling.
major comments (2)
- [Abstract] Abstract: the claim that the 3D CNN 'outperforms comparable models that either extract only spatial features or model spatial and low-level temporal information separately' cannot be evaluated because no architecture specifications, parameter counts, training schedules, or preprocessing details are supplied for the baselines; without these, the accuracy difference cannot be attributed to joint spatiotemporal learning.
- [Abstract] Abstract / Results: accuracies are stated as 'more than 84%' with no error bars, no statistical significance tests against baselines, and no ablation studies that hold network capacity or optimization procedure fixed; this leaves the central outperformance claim only partially supported.
minor comments (1)
- [Abstract] Abstract: the statement 'For the first time, these results demonstrate the benefit...' should be accompanied by citations to prior spatiotemporal CNN applications in other video domains to avoid overstatement.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. We address the major comments point-by-point below and propose revisions where appropriate to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the 3D CNN 'outperforms comparable models that either extract only spatial features or model spatial and low-level temporal information separately' cannot be evaluated because no architecture specifications, parameter counts, training schedules, or preprocessing details are supplied for the baselines; without these, the accuracy difference cannot be attributed to joint spatiotemporal learning.
Authors: The full manuscript includes detailed descriptions of the baseline architectures (2D CNN and hybrid models), their parameter counts, training schedules, and preprocessing steps in Sections 3 and 4. The abstract summarizes the key finding, but to address this concern, we will revise the abstract to explicitly state that the baselines were implemented with comparable model capacities and trained using identical procedures and data splits. This will allow readers to better evaluate the attribution to joint spatiotemporal learning. revision: yes
-
Referee: [Abstract] Abstract / Results: accuracies are stated as 'more than 84%' with no error bars, no statistical significance tests against baselines, and no ablation studies that hold network capacity or optimization procedure fixed; this leaves the central outperformance claim only partially supported.
Authors: We agree that including error bars, statistical tests, and capacity-controlled ablations would provide stronger support. The manuscript reports average accuracies over multiple folds, but we did not include variance measures or significance tests in the abstract or main results table. We will revise the results section to include standard deviations across runs, perform paired t-tests or similar for significance against baselines, and add an ablation study that matches network capacity and optimization settings. These changes will be incorporated in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical evaluation on public dataset with no derivations or self-referential claims
full rationale
The paper is an empirical ML study proposing 3D CNNs for video-based surgical gesture recognition and reporting frame-wise accuracies >84% on the JIGSAWS dataset, outperforming spatial-only or separate spatial+temporal models. No equations, parameter fits presented as predictions, uniqueness theorems, or ansatzes are present in the provided text. The central claim rests on direct experimental comparison against baselines on an external public benchmark, with no reduction of results to self-definitions or self-citations. This is self-contained empirical work.
Axiom & Free-Parameter Ledger
free parameters (1)
- 3D CNN weights and hyperparameters
axioms (1)
- domain assumption 3D convolutions can jointly capture spatial and temporal information from video sequences
Reference graph
Works this paper leans on
-
[1]
IEEE Trans Biomed Eng 64(9), 2025–2041 (2017)
Ahmidi, N., Tao, L., Sefati, S., Gao, Y., Lea, C., Haro, B.B., et al.: A dataset and benchmarks for segmentation and recognition of gestures in robotic surgery. IEEE Trans Biomed Eng 64(9), 2025–2041 (2017)
work page 2025
- [2]
-
[3]
DiPietro, R., Lea, C., Malpani, A., Ahmidi, N., Vedula, S.S., Lee, G.I., et al.: Recognizing surgical activities with recurrent neural networks. In: MICCAI. pp. 551–558. Springer, Cham (2016)
work page 2016
-
[4]
Hara, K., Kataoka, H., Satoh, Y.: Learning spatio-temporal features with 3D resid- ual networks for action recognition. In: ICCV-W. pp. 3154–3160. IEEE (2017)
work page 2017
- [5]
-
[6]
IEEE Trans Pattern Anal Mach Intell 35(1), 221–231 (2013)
Ji, S., Xu, W., Yang, M., Yu, K.: 3D convolutional neural networks for human action recognition. IEEE Trans Pattern Anal Mach Intell 35(1), 221–231 (2013)
work page 2013
-
[7]
In: ICLR (2015) 3D CNNs for Automatic Surgical Gesture Recognition in Video 9
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: ICLR (2015) 3D CNNs for Automatic Surgical Gesture Recognition in Video 9
work page 2015
- [8]
- [9]
-
[10]
Lea, C., Vidal, R., Reiter, A., Hager, G.D.: Temporal convolutional networks: A unified approach to action segmentation. In: ECCV-W. pp. 47–54. Springer, Cham (2016)
work page 2016
-
[11]
Liu, D., Jiang, T.: Deep reinforcement learning for surgical gesture segmentation and classification. In: MICCAI. pp. 247–255. Springer, Cham (2018)
work page 2018
- [12]
-
[13]
Tao, L., Zappella, L., Hager, G.D., Vidal, R.: Surgical gesture segmentation and recognition. In: MICCAI. pp. 339–346. Springer, Berlin, Heidelberg (2013)
work page 2013
-
[14]
Wang, L., Xiong, Y., Wang, Z., Qiao, Y., Lin, D., Tang, X., et al.: Temporal segment networks: Towards good practices for deep action recognition. In: ECCV. pp. 20–36. Springer, Cham (2016) Supplementary Using 3D Convolutional Neural Networks to Learn Spatiotemporal Features for Automatic Surgical Gesture Recognition in Video Isabel Funke1, Sebastian Bode...
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.