Sub-linear Regret Bounds for Bayesian Optimisation in Unknown Search Spaces
Pith reviewed 2026-05-24 14:37 UTC · model grok-4.3
The pith
Bayesian optimisation algorithms achieve sub-linear cumulative regret by expanding unknown search spaces using a hyperharmonic series.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By expanding the search space according to the hyperharmonic series, the proposed algorithms ensure that the cumulative regret grows sub-linearly, even starting from an initial unknown or bounded space, under standard regularity conditions on the objective function.
What carries the argument
The hyperharmonic series that dictates the controlled expansion and shifting of the search space bounds.
If this is right
- Cumulative regret for both algorithms grows sub-linearly with the number of iterations.
- The high-dimensional variant preserves the sub-linear regret property while scaling to higher dimensions.
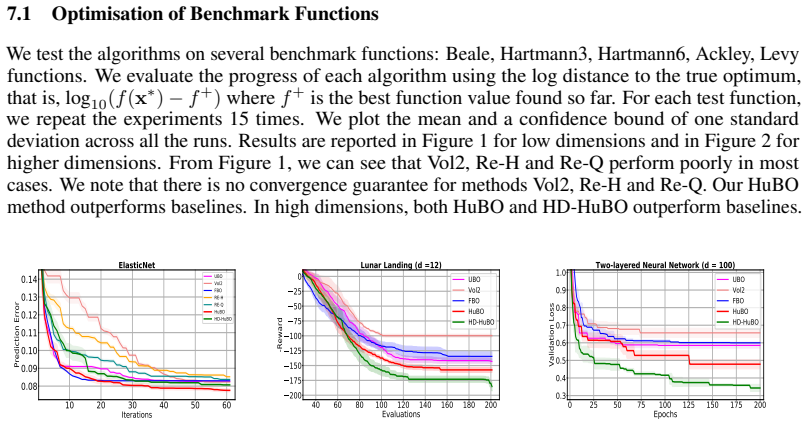
- Both algorithms show better empirical performance than existing methods on synthetic and real-world tasks with unknown search spaces.
Where Pith is reading between the lines
- The expansion rule could be tested on other sequential optimizers if similar regularity conditions apply.
- This method suggests a general strategy for handling uncertain domains in black-box problems beyond Bayesian optimisation.
- Sub-linear regret implies the average per-step cost decreases over long horizons, which may matter for repeated optimisation runs.
Load-bearing premise
The objective function must satisfy regularity conditions such as a bounded norm in a reproducing kernel Hilbert space that remain valid even as the search space expands.
What would settle it
A counter-example objective function where cumulative regret grows linearly or faster despite following the hyperharmonic expansion rule.
Figures







read the original abstract
Bayesian optimisation is a popular method for efficient optimisation of expensive black-box functions. Traditionally, BO assumes that the search space is known. However, in many problems, this assumption does not hold. To this end, we propose a novel BO algorithm which expands (and shifts) the search space over iterations based on controlling the expansion rate thought a hyperharmonic series. Further, we propose another variant of our algorithm that scales to high dimensions. We show theoretically that for both our algorithms, the cumulative regret grows at sub-linear rates. Our experiments with synthetic and real-world optimisation tasks demonstrate the superiority of our algorithms over the current state-of-the-art methods for Bayesian optimisation in unknown search space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes two Bayesian optimization algorithms for unknown search spaces: one that expands and shifts the domain over iterations at a rate controlled by a hyperharmonic series, and a high-dimensional scaling variant. It claims to establish sub-linear cumulative regret bounds for both via theoretical analysis under RKHS regularity assumptions, and reports experimental superiority over existing methods on synthetic and real-world tasks.
Significance. If the sub-linear regret results hold, the work would meaningfully extend BO theory and practice by removing the fixed known-domain assumption while preserving the key o(T) regret property. The combination of a novel expansion mechanism, theoretical analysis, and empirical comparisons is a positive feature.
major comments (2)
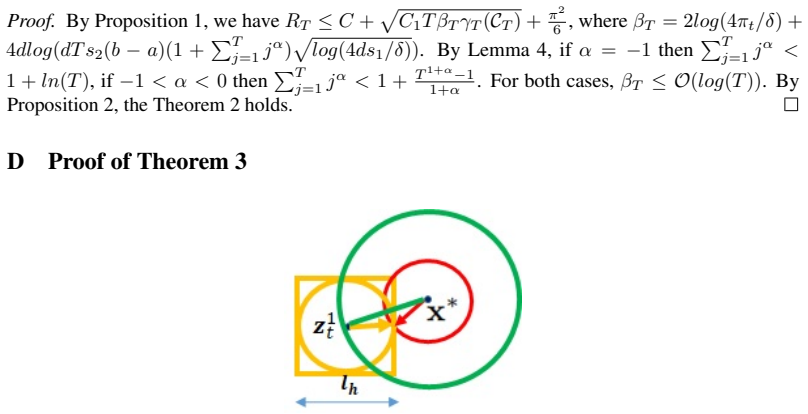
- [§4 (Regret Analysis)] §4 (Regret Analysis) and the statement of the main theorem: the derivation invokes a uniform bound B on the RKHS norm that is assumed to continue to hold as the domain is successively enlarged according to the hyperharmonic series. No explicit argument is given showing that the kernel's eigenvalue decay or maximum information gain remains controlled independently of domain volume growth; without this, the per-step regret terms are not guaranteed to be summable and the o(T) claim does not follow.
- [Algorithm 2 and associated theorem] High-dimensional variant (Algorithm 2 and its regret theorem): the analysis again relies on the same RKHS regularity persisting after domain expansion, yet the additional dimensionality-reduction step introduces an extra approximation whose effect on the information-gain bound is not quantified. If this approximation degrades the effective smoothness, the sub-linear guarantee may fail.
minor comments (2)
- [Abstract] The abstract contains the phrase 'thought a hyperharmonic series'; this appears to be a typographical error for 'through'.
- [Experiments] Experimental section: more precise reporting of the kernel hyperparameters and the exact hyperharmonic coefficients used would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and insightful comments on the theoretical analysis. We address each major comment below and will revise the manuscript to strengthen the proofs.
read point-by-point responses
-
Referee: [§4 (Regret Analysis)] §4 (Regret Analysis) and the statement of the main theorem: the derivation invokes a uniform bound B on the RKHS norm that is assumed to continue to hold as the domain is successively enlarged according to the hyperharmonic series. No explicit argument is given showing that the kernel's eigenvalue decay or maximum information gain remains controlled independently of domain volume growth; without this, the per-step regret terms are not guaranteed to be summable and the o(T) claim does not follow.
Authors: We agree that the current version does not provide an explicit lemma bounding the maximum information gain independently of domain volume. The analysis assumes a fixed kernel and a uniform RKHS-norm bound B on the unknown function f (which is defined over the expanding domain). The hyperharmonic expansion rate is chosen precisely so that volume growth is slow enough for standard information-gain bounds to remain sub-linear, but this step is only sketched. In the revision we will insert a new lemma (Lemma 4.X) that uses the specific hyperharmonic decay to show that the eigenvalue decay of the kernel operator on the enlarged domain yields γ_T = O(T^β) for β<1 independent of the volume at step T, thereby restoring summability of the per-step regret terms. revision: yes
-
Referee: [Algorithm 2 and associated theorem] High-dimensional variant (Algorithm 2 and its regret theorem): the analysis again relies on the same RKHS regularity persisting after domain expansion, yet the additional dimensionality-reduction step introduces an extra approximation whose effect on the information-gain bound is not quantified. If this approximation degrades the effective smoothness, the sub-linear guarantee may fail.
Authors: The dimensionality-reduction step in Algorithm 2 is a controlled projection onto a lower-dimensional subspace that preserves the RKHS inner product up to an additive error term whose magnitude is bounded by the projection tolerance. We acknowledge that the manuscript does not quantify how this error propagates into the information-gain bound. In the revision we will add a proposition (Proposition 5.X) that bounds the perturbation to γ_T by a summable series; the resulting extra term remains o(T) and does not invalidate the sub-linear regret claim for the high-dimensional variant. revision: yes
Circularity Check
No circularity: regret bounds derived from standard GP assumptions plus explicit domain-expansion rate
full rationale
The paper states a standard RKHS-norm boundedness assumption on the objective and then derives sub-linear regret for its hyperharmonic expansion schedule. No equation reduces a fitted quantity to a prediction by construction, no self-citation is invoked as a uniqueness theorem, and the central claim (cumulative regret o(T)) follows from the usual information-gain or covering-number arguments once the expansion rate is fixed. The persistence of the RKHS bound across expanding domains is an explicit modeling assumption, not a hidden self-definition. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Objective function has bounded norm in a reproducing kernel Hilbert space
Reference graph
Works this paper leans on
-
[1]
Tom M. Apostol. An elementary view of euler's summation formula. The American Mathematical Monthly, 106 0 (5): 0 409--418, 1999. ISSN 00029890, 19300972
work page 1999
-
[2]
Roberto Calandra, Andr \' e Seyfarth, Jan Peters, and Marc Peter Deisenroth. Bayesian optimization for learning gaits under uncertainty - an experimental comparison on a dynamic bipedal walker. Ann. Math. Artif. Intell., 76 0 (1-2): 0 5--23, 2016. doi:10.1007/s10472-015-9463-9
-
[3]
Adaptive expansion bayesian optimization for unbounded global optimization
Wei Chen and Mark Fuge. Adaptive expansion bayesian optimization for unbounded global optimization. CoRR, abs/2001.04815, 2020. URL https://arxiv.org/abs/2001.04815
-
[4]
An approximate formula for a partial sum of the divergent p-series
Edward Chlebus. An approximate formula for a partial sum of the divergent p-series. Appl. Math. Lett., 22: 0 732--737, 2009
work page 2009
-
[5]
High-dimensional gaussian process bandits
Josip Djolonga, Andreas Krause, and Volkan Cevher. High-dimensional gaussian process bandits. In Proceedings of the 26th International Conference on Neural Information Processing Systems - Volume 1, NIPS'13, pages 1025--1033, USA, 2013. Curran Associates Inc
work page 2013
-
[6]
Scaling gaussian process regression with derivatives
David Eriksson, Kun Dong, Eric Hans Lee, David Bindel, and Andrew Gordon Wilson. Scaling gaussian process regression with derivatives. In Advances in Neural Information Processing Systems, pages 6868--6878, 2018
work page 2018
-
[7]
Gardner, Ryan Turner, and Matthias Poloczek
David Eriksson, Michael Pearce, Jacob R. Gardner, Ryan Turner, and Matthias Poloczek. Scalable global optimization via local bayesian optimization. In Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, 8-14 December 2019, Vancouver, BC, Canada, pages 5497--5508, 2019
work page 2019
-
[8]
Roman Garnett, Michael A. Osborne, and Philipp Hennig. Active learning of linear embeddings for gaussian processes. In Proceedings of the Thirtieth Conference on Uncertainty in Artificial Intelligence, UAI'14, pages 230--239, Arlington, Virginia, United States, 2914. AUAI Press. ISBN 978-0-9749039-1-0
-
[9]
Bayesian optimization with unknown search space
Huong Ha, Santu Rana, Sunil Gupta, Thanh Tang Nguyen, Hung Tran - The, and Svetha Venkatesh. Bayesian optimization with unknown search space. In Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, 8-14 December 2019, Vancouver, BC, Canada, pages 11772--11781, 2019
work page 2019
-
[10]
Hoffman, and Zoubin Ghahramani
Jos \' e Miguel Hern \' a ndez - Lobato, Matthew W. Hoffman, and Zoubin Ghahramani. Predictive entropy search for efficient global optimization of black-box functions. In Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada, pages 918--926, 2014
work page 2014
-
[11]
Decentralized high-dimensional bayesian optimization with factor graphs
Trong Nghia Hoang, Quang Minh Hoang, Ruofei Ouyang, and Kian Hsiang Low. Decentralized high-dimensional bayesian optimization with factor graphs. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI) , pages 3231--3238, 2018
work page 2018
-
[12]
High dimensional bayesian optimisation and bandits via additive models
Kandasamy. High dimensional bayesian optimisation and bandits via additive models. In Proceedings of the 32Nd International Conference on International Conference on Machine Learning - Volume 37, ICML'15, pages 295--304. JMLR.org, 2015
work page 2015
-
[13]
Adaptive and Safe Bayesian Optimization in High Dimensions via One-Dimensional Subspaces
Johannes Kirschner, Mojm \' r Mutn \' y , Nicole Hiller, Rasmus Ischebeck, and Andreas Krause. Adaptive and safe bayesian optimization in high dimensions via one-dimensional subspaces. CoRR, abs/1902.03229, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[14]
High dimensional bayesian optimization via restricted projection pursuit models
Chun-Liang Li. High dimensional bayesian optimization via restricted projection pursuit models. In Arthur Gretton and Christian C. Robert, editors, Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, volume 51 of Proceedings of Machine Learning Research, pages 884--892, Cadiz, Spain, 09--11 May 2016. PMLR
work page 2016
-
[15]
On bayesian methods for seeking the extremum
Jonas Mockus. On bayesian methods for seeking the extremum. In Proceedings of the IFIP Technical Conference, pages 400--404, London, UK, UK, 1974. Springer-Verlag. ISBN 3-540-07165-2
work page 1974
-
[16]
Efficient high dimensional bayesian optimization with additivity and quadrature fourier features
Mojm\' r Mutn\' y and Andreas Krause. Efficient high dimensional bayesian optimization with additivity and quadrature fourier features. In Proceedings of the 32Nd International Conference on Neural Information Processing Systems, NIPS'18, pages 9019--9030, USA, 2018. Curran Associates Inc
work page 2018
-
[17]
A framework for B ayesian optimization in embedded subspaces
Amin Nayebi, Alexander Munteanu, and Matthias Poloczek. A framework for B ayesian optimization in embedded subspaces. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 4752--4761, Long Beach, California, USA, 09--15 Jun...
work page 2019
-
[18]
Bayesian optimization in weakly specified search space
Vu Nguyen, Sunil Gupta, Santu Rana, Cheng Li, and Svetha Venkatesh. Bayesian optimization in weakly specified search space. In 2017 IEEE International Conference on Data Mining, ICDM 2017, New Orleans, LA, USA, November 18-21, 2017 , pages 347--356, 2017. doi:10.1109/ICDM.2017.44
-
[19]
Filtering bayesian optimization approach in weakly specified search space
Vu Nguyen, Sunil Gupta, Santu Rana, Cheng Li, and Svetha Venkatesh. Filtering bayesian optimization approach in weakly specified search space. Knowl. Inf. Syst., 60 0 (1): 0 385--413, July 2019. ISSN 0219-1377. doi:10.1007/s10115-018-1238-2
-
[20]
BOCK : Bayesian optimization with cylindrical kernels
ChangYong Oh, Efstratios Gavves, and Max Welling. BOCK : Bayesian optimization with cylindrical kernels. In ICML , volume 80 of Proceedings of Machine Learning Research, pages 3865--3874. PMLR , 2018
work page 2018
-
[21]
Scikit-learn: Machine learning in python
Fabian Pedregosa, Ga\" e l Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, and \' E douard Duchesnay. Scikit-learn: Machine learning in python. J. Mach. Learn. Res., 12 0 ...
work page 2011
-
[22]
Carl Edward Rasmussen and Christopher K. I. Williams. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning). The MIT Press, 2005. ISBN 026218253X
work page 2005
-
[23]
High-dimensional bayesian optimization via additive models with overlapping groups
Paul Rolland, Jonathan Scarlett, Ilija Bogunovic, and Volkan Cevher. High-dimensional bayesian optimization via additive models with overlapping groups. In Amos Storkey and Fernando Perez-Cruz, editors, Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, volume 84 of Proceedings of Machine Learning Research,...
work page 2018
-
[24]
Unbounded bayesian optimization via regularization
Bobak Shahriari, Alexandre Bouchard-Cote, and Nando Freitas. Unbounded bayesian optimization via regularization. In Arthur Gretton and Christian C. Robert, editors, Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, volume 51 of Proceedings of Machine Learning Research, pages 1168--1176, Cadiz, Spain, 09--11 May 2016. PMLR
work page 2016
-
[25]
Practical bayesian optimization of machine learning algorithms
Jasper Snoek, Hugo Larochelle, and Ryan P Adams. Practical bayesian optimization of machine learning algorithms. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 25, pages 2951--2959. Curran Associates, Inc., 2012
work page 2012
-
[26]
Niranjan Srinivas, Andreas Krause, Sham M. Kakade, and Matthias W. Seeger. Information-theoretic regret bounds for gaussian process optimization in the bandit setting. IEEE Trans. Inf. Theor., 58 0 (5): 0 3250--3265, May 2012. ISSN 0018-9448
work page 2012
-
[27]
Trading convergence rate with computational budget in high dimensional bayesian optimization
Hung Tran - The, Sunil Gupta, Santu Rana, and Svetha Venkatesh. Trading convergence rate with computational budget in high dimensional bayesian optimization. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Edu...
work page 2020
-
[28]
Volumes of generalized unit balls
Xianfu Wang. Volumes of generalized unit balls. Mathematics Magazine, 78 0 (5): 0 390 -- 395, 2005
work page 2005
-
[29]
Bayesian optimization in high dimensions via random embeddings
Ziyu Wang, Masrour Zoghi, Frank Hutter, David Matheson, and Nando De Freitas. Bayesian optimization in high dimensions via random embeddings. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, IJCAI '13, pages 1778--1784. AAAI Press, 2013. ISBN 978-1-57735-633-2
work page 2013
-
[30]
Miao Zhang, Huiqi Li, and Steven W. Su. High dimensional bayesian optimization via supervised dimension reduction. CoRR, abs/1907.08953, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.