PyEPO: A PyTorch-based End-to-End Predict-then-Optimize Library for Linear and Integer Programming
Pith reviewed 2026-05-24 11:20 UTC · model grok-4.3
The pith
PyEPO is the first generic PyTorch library for end-to-end predict-then-optimize on linear and integer programs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
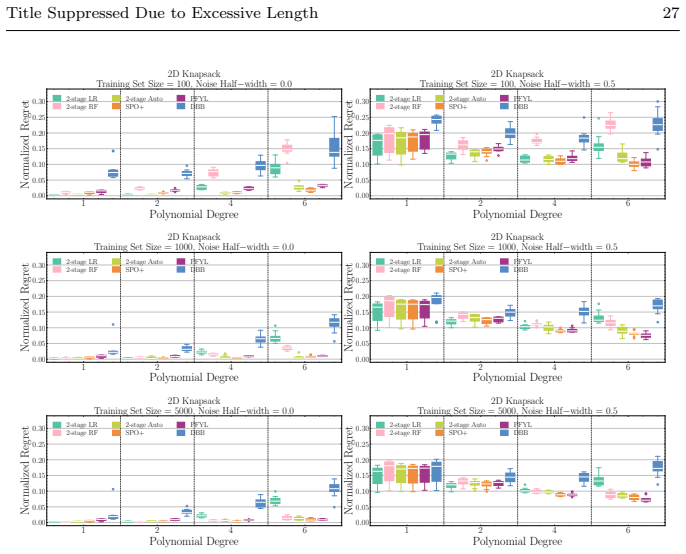
PyEPO is the first generic tool for linear and integer programming with predicted objective function coefficients. It packages surrogate decision losses, black-box solvers, and perturbed methods into a PyTorch library that offers a user-friendly interface for defining new optimization problems, applying state-of-the-art algorithms, and using custom neural network architectures, with experiments on Shortest Path, Multiple Knapsack, and Traveling Salesperson Problem.
What carries the argument
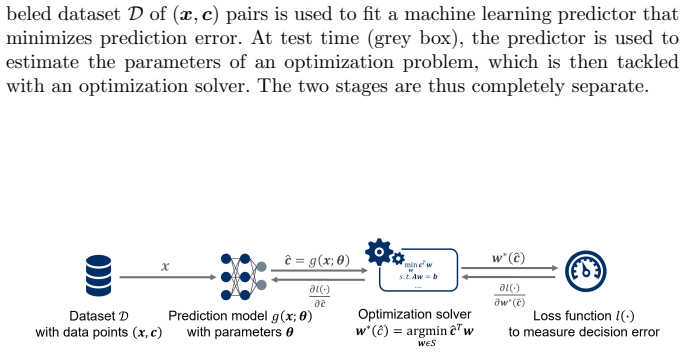
PyEPO library, which integrates neural-network training loops with optimization solvers so that prediction errors are measured by their effect on the solved objective rather than by standalone prediction accuracy.
If this is right
- Users can define new optimization problems and train networks without writing separate prediction and optimization stages.
- Multiple algorithms including surrogate losses, black-box solvers, and perturbed methods become interchangeable within the same training pipeline.
- Custom neural network architectures can be inserted directly into the predict-then-optimize loop.
- Empirical comparisons on Shortest Path, Multiple Knapsack, and TSP instances become reproducible with a single code base.
Where Pith is reading between the lines
- Wider adoption could reduce the gap between learned predictors and operational decisions in logistics and scheduling domains.
- The library's extensibility may accelerate testing of new surrogate losses or perturbation schemes on the same problem set.
- Insights from the reported experiments could inform choices between gradient-based and gradient-free training for integer programs.
Load-bearing premise
The described algorithms can be packaged into a single extensible library that correctly integrates neural network training with optimization solvers for arbitrary user-defined linear and integer programs.
What would settle it
Release of an earlier open-source library that already provided the same generic end-to-end interface for arbitrary linear and integer programs with predicted coefficients, or demonstration that PyEPO's integration produces incorrect gradients or infeasible solutions on a standard test instance.
Figures











read the original abstract
In deterministic optimization, it is typically assumed that all problem parameters are fixed and known. In practice, however, some parameters may be a priori unknown but can be estimated from contextual information. A typical predict-then-optimize approach separates predictions and optimization into two distinct stages. Recently, end-to-end predict-then-optimize has emerged as an attractive alternative. This work introduces the PyEPO package, a PyTorch-based end-to-end predict-then-optimize library in Python. To the best of our knowledge, PyEPO (pronounced like \textit{pineapple} with a silent ``n") is the first such generic tool for linear and integer programming with predicted objective function coefficients. It includes various algorithms such as surrogate decision losses, black-box solvers, and perturbed methods. PyEPO offers a user-friendly interface for defining new optimization problems, applying state-of-the-art algorithms, and using custom neural network architectures. We conducted experiments comparing various methods on problems such as Shortest Path, Multiple Knapsack, and Traveling Salesperson Problem, and discussed empirical insights that may guide future research. PyEPO and its documentation are available at https://github.com/khalil-research/PyEPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PyEPO, a PyTorch-based open-source library for end-to-end predict-then-optimize frameworks applied to linear and integer programs whose objective coefficients are predicted from contextual features. It implements surrogate decision losses, black-box differentiation, and perturbed optimization methods; supplies a user interface for specifying arbitrary user-defined problems; and reports numerical comparisons on shortest-path, multiple-knapsack, and TSP instances together with empirical observations.
Significance. If the library correctly integrates the cited algorithms with standard solvers and the reported experiments are reproducible, the work supplies a concrete, extensible platform that lowers the barrier for researchers to test and compare end-to-end methods on custom linear and integer programs. The public GitHub repository and documentation constitute a reproducible artifact that can serve as a reference implementation for the community.
minor comments (3)
- [Introduction] The abstract states that PyEPO is 'the first such generic tool … to the best of our knowledge.' A brief related-work paragraph in the introduction that explicitly contrasts PyEPO with prior specialized implementations (e.g., those limited to particular problem classes) would strengthen this claim.
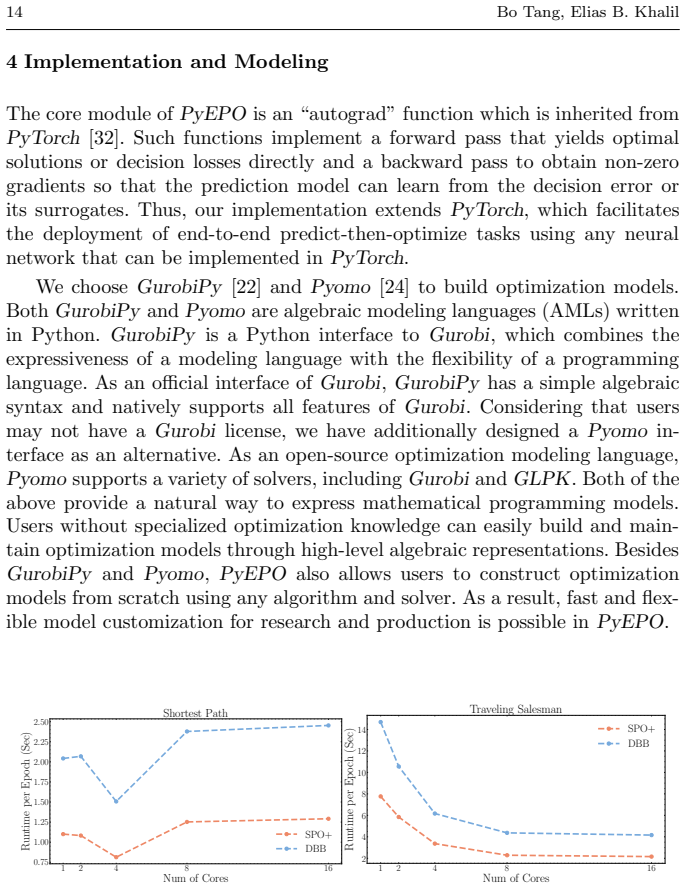
- [Experiments] Section 4 (or the experiments section) should include a short table listing the exact solver interfaces, PyTorch versions, and random seeds used for each benchmark so that the reported runtimes and solution qualities can be reproduced without inspecting the repository.
- [Library Design] The user-interface description would benefit from a minimal complete code snippet showing how a new problem class is registered and how a custom neural network is attached; the current prose description leaves the exact API surface unclear.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report correctly identifies PyEPO's contributions as the first generic PyTorch library for end-to-end predict-then-optimize on linear and integer programs. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The manuscript presents a software library (PyEPO) implementing existing predict-then-optimize algorithms for linear and integer programs. No derivation chain, first-principles result, or fitted prediction is claimed; the contribution is the packaging, interface, and empirical comparison on standard problems. The qualified priority statement ('to the best of our knowledge') is not load-bearing for any mathematical claim and does not reduce to self-citation or self-definition. The work is self-contained as an engineering artifact whose correctness is evidenced by the public repository and reported experiments.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
IGT-OMD: Implicit Gradient Transport for Decision-Focused Learning under Delayed Feedback
IGT-OMD reduces gradient transport error from quadratic to linear in delay length for delayed bilevel optimization and achieves sublinear regret with adaptive steps.
-
Decision-Focused Learning via Tangent-Space Projection of Prediction Error
Regret gradients in DFL are the tangent-space projection of prediction error scaled by curvature, enabling efficient direct computation without differentiating through solvers.
-
Decision-Focused Learning via Tangent-Space Projection of Prediction Error
PEAR computes regret gradients via tangent-space projection of prediction error, delivering top decision quality and efficiency on LP and QP tasks without solver differentiation.
Reference graph
Works this paper leans on
-
[1]
(2016) Tensorflow: Large-scale machine learning on heterogeneous distributed systems
Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z, Citro C, Corrado GS, Davis A, Dean J, Devin M, et al. (2016) Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv preprint arXiv:160304467
work page 2016
-
[2]
Agrawal A, Amos B, Barratt S, Boyd S, Diamond S, Kolter JZ (2019) Differentiable convex optimization layers. In: Wallach H, Larochelle H, Beygelzimer A, d'Alch´ e-Buc F, Fox E, Garnett R (eds) Advances in Neural Information Processing Systems, Curran Associates, Inc., vol 32
work page 2019
-
[3]
arXiv preprint arXiv:190409043
Agrawal A, Barratt S, Boyd S, Busseti E, Moursi WM (2019) Differenti- ating through a cone program. arXiv preprint arXiv:190409043
work page 2019
-
[4]
In: International Conference on Machine Learning, PMLR, pp 136–145
Amos B, Kolter JZ (2017) Optnet: Differentiable optimization as a layer in neural networks. In: International Conference on Machine Learning, PMLR, pp 136–145
work page 2017
-
[5]
International Journal of Neural Systems 8(04):433–443
Bengio Y (1997) Using a financial training criterion rather than a predic- tion criterion. International Journal of Neural Systems 8(04):433–443
work page 1997
-
[6]
arXiv preprint arXiv:200208676
Berthet Q, Blondel M, Teboul O, Cuturi M, Vert JP, Bach F (2020) Learning with differentiable perturbed optimizers. arXiv preprint arXiv:200208676
work page 2020
-
[7]
Blondel M, Martins AF, Niculae V (2020) Learning with fenchel-young losses. J Mach Learn Res 21(35):1–69
work page 2020
-
[8]
arXiv preprint arXiv:151201274
Chen T, Li M, Li Y, Lin M, Wang N, Wang M, Xiao T, Xu B, Zhang C, Zhang Z (2015) Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv preprint arXiv:151201274
work page 2015
-
[9]
Cplex II (2009) V12. 1: User’s manual for cplex. International Business Machines Corporation 46(53):157
work page 2009
-
[10]
arXiv preprint arXiv:220713513
Dalle G, Baty L, Bouvier L, Parmentier A (2022) Learning with com- binatorial optimization layers: a probabilistic approach. arXiv preprint arXiv:220713513
work page 2022
-
[11]
Journal of the operations research society of America 2(4):393–410
Dantzig G, Fulkerson R, Johnson S (1954) Solution of a large-scale traveling-salesman problem. Journal of the operations research society of America 2(4):393–410
work page 1954
-
[12]
Djolonga J, Krause A (2017) Differentiable learning of submodular models. In: Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, Garnett R (eds) Advances in Neural Information Processing Systems, Curran Associates, Inc., vol 30
work page 2017
-
[13]
In: Artificial Intelligence and Statistics, PMLR, pp 318–326
Domke J (2012) Generic methods for optimization-based modeling. In: Artificial Intelligence and Statistics, PMLR, pp 318–326
work page 2012
-
[14]
Donti P, Amos B, Kolter JZ (2017) Task-based end-to-end model learning in stochastic optimization. In: Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, Garnett R (eds) Advances in Neural Infor- mation Processing Systems, Curran Associates, Inc., vol 30
work page 2017
-
[15]
Elmachtoub A, Liang JCN, McNellis R (2020) Decision trees for decision- making under the predict-then-optimize framework. In: International Con- ference on Machine Learning, PMLR, vol 119, pp 2858–2867 Title Suppressed Due to Excessive Length 37
work page 2020
-
[16]
Elmachtoub AN, Grigas P (2021) Smart “predict, then optimize”. Man- agement Science 0(0)
work page 2021
-
[17]
In: Proceedings of the AAAI Conference on Artificial Intelligence, vol 34, pp 1504–1511
Ferber A, Wilder B, Dilkina B, Tambe M (2020) Mipaal: Mixed integer program as a layer. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol 34, pp 1504–1511
work page 2020
-
[18]
In: Advances in Neural Information Processing Systems 28 (2015), pp 2962– 2970
Feurer M, Klein A, Eggensperger J Katharina Springenberg, Blum M, Hutter F (2015) Efficient and robust automated machine learning. In: Advances in Neural Information Processing Systems 28 (2015), pp 2962– 2970
work page 2015
-
[19]
In: International Conference on Decision and Game Theory for Security, Springer, pp 35–56
Ford B, Nguyen T, Tambe M, Sintov N, Delle Fave F (2015) Beware the soothsayer: From attack prediction accuracy to predictive reliability in security games. In: International Conference on Decision and Game Theory for Security, Springer, pp 35–56
work page 2015
-
[20]
Operations Research Center Working Paper;OR 078-78
Gavish B, Graves SC (1978) The travelling salesman problem and related problems. Operations Research Center Working Paper;OR 078-78
work page 1978
-
[21]
arXiv preprint arXiv:160705447
Gould S, Fernando B, Cherian A, Anderson P, Cruz RS, Guo E (2016) On differentiating parameterized argmin and argmax problems with applica- tion to bi-level optimization. arXiv preprint arXiv:160705447
work page 2016
-
[22]
Gurobi Optimization, LLC (2021) Gurobi Optimizer Reference Manual. URL https://www.gurobi.com
work page 2021
-
[23]
Hagberg A, Swart P, S Chult D (2008) Exploring network structure, dy- namics, and function using networkx. Tech. rep., Los Alamos National Lab.(LANL), Los Alamos, NM (United States)
work page 2008
-
[24]
(2017) Pyomo-optimization modeling in python, vol 67
Hart WE, Laird CD, Watson JP, Woodruff DL, Hackebeil GA, Nicholson BL, Siirola JD, et al. (2017) Pyomo-optimization modeling in python, vol 67. Springer
work page 2017
-
[25]
Kao Yh, Roy B, Yan X (2009) Directed regression. In: Bengio Y, Schu- urmans D, Lafferty J, Williams C, Culotta A (eds) Advances in Neural Information Processing Systems, Curran Associates, Inc., vol 22
work page 2009
-
[26]
Mandi J, Guns T (2020) Interior point solving for lp-based predic- tion+optimisation. In: Larochelle H, Ranzato M, Hadsell R, Balcan MF, Lin H (eds) Advances in Neural Information Processing Systems, Curran Associates, Inc., vol 33, pp 7272–7282
work page 2020
-
[27]
(2020) Smart predict-and-optimize for hard combinatorial optimization problems
Mandi J, Stuckey PJ, Guns T, et al. (2020) Smart predict-and-optimize for hard combinatorial optimization problems. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol 34, pp 1603–1610, DOI 10.1609/ aaai.v34i02.5521
work page 2020
-
[28]
Martello S, Toth P (1990) Knapsack problems: algorithms and computer implementations. John Wiley & Sons, Inc
work page 1990
-
[29]
Optimization and Engineering 13(1):1–27
Mattingley J, Boyd S (2012) Cvxgen: A code generator for embedded convex optimization. Optimization and Engineering 13(1):1–27
work page 2012
-
[30]
Journal of the ACM (JACM) 7(4):326–329
Miller CE, Tucker AW, Zemlin RA (1960) Integer programming for- mulation of traveling salesman problems. Journal of the ACM (JACM) 7(4):326–329
work page 1960
-
[31]
Synthesis Lectures 38 Bo Tang, Elias B
Ortega-Arranz H, Llanos DR, Gonzalez-Escribano A (2014) The shortest- path problem: Analysis and comparison of methods. Synthesis Lectures 38 Bo Tang, Elias B. Khalil on Theoretical Computer Science 1(1):1–87
work page 2014
-
[32]
In: NIPS 2017 Autodiff Workshop
Paszke A, Gross S, Chintala S, Chanan G, Yang E, DeVito Z, Lin Z, Des- maison A, Antiga L, Lerer A (2017) Automatic differentiation in pytorch. In: NIPS 2017 Autodiff Workshop
work page 2017
-
[33]
Paszke A, Gross S, Massa F, Lerer A, Bradbury J, Chanan G, Killeen T, Lin Z, Gimelshein N, Antiga L, Desmaison A, Kopf A, Yang E, DeVito Z, Raison M, Tejani A, Chilamkurthy S, Steiner B, Fang L, Bai J, Chintala S (2019) Pytorch: An imperative style, high-performance deep learning library. In: Wallach H, Larochelle H, Beygelzimer A, d 'Alch´ e-Buc F, Fox E...
work page 2019
-
[34]
Journal of Machine Learning Research 12:2825–2830
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay E (2011) Scikit- learn: Machine learning in Python. Journal of Machine Learning Research 12:2825–2830
work page 2011
-
[35]
In: International Conference on Learning Representations
Poganˇ ci´ c MV, Paulus A, Musil V, Martius G, Rolinek M (2019) Differen- tiation of blackbox combinatorial solvers. In: International Conference on Learning Representations
work page 2019
-
[36]
Wilder B, Dilkina B, Tambe M (2019) Melding the data-decisions pipeline: Decision-focused learning for combinatorial optimization. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol 33, pp 1658–1665 9 Statements and Declarations 9.1 Funding This work was supported by funding from a SCALE AI Research Chair and an NSERC Discovery Grant. 9...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.