The EDGE Language: Extended General Einsums for Graph Algorithms
Pith reviewed 2026-05-24 01:34 UTC · model grok-4.3
The pith
The EDGE language expresses graph algorithms as extended Einsum tensor expressions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EDGE extends Einsum notation to support the operations common in graph algorithms while retaining the graph-matrix duality in which a graph is treated as a 2D tensor; any graph algorithm can therefore be written as one compact EDGE expression that can be compared, factored, or transformed algebraically.
What carries the argument
The EDGE language, which adds extensions to Einsum notation to capture graph operations while preserving the tensor-algebra foundation.
If this is right
- Researchers can compare different algorithms and different implementations of the same algorithm by writing both as EDGE expressions.
- Developers can separate the concerns of what to compute (the EDGE expression) from the lower-level details of how to compute it.
- New algorithmic variants of a problem can be discovered by performing algebraic manipulations and transformations on a given EDGE expression.
Where Pith is reading between the lines
- The same notation could be used inside tensor compilers to automatically generate specialized graph kernels from high-level expressions.
- Seemingly unrelated graph algorithms might turn out to share identical or closely related EDGE forms, revealing hidden structural similarities.
- The approach could be tested by taking a collection of textbook graph algorithms and checking whether each fits inside the stated EDGE extensions without remainder.
Load-bearing premise
The described extensions to Einsum notation are sufficient to express all common graph-algorithm operations without needing further ad-hoc additions.
What would settle it
A standard graph algorithm that cannot be written in EDGE without introducing new operations outside the extensions given in the paper.
Figures










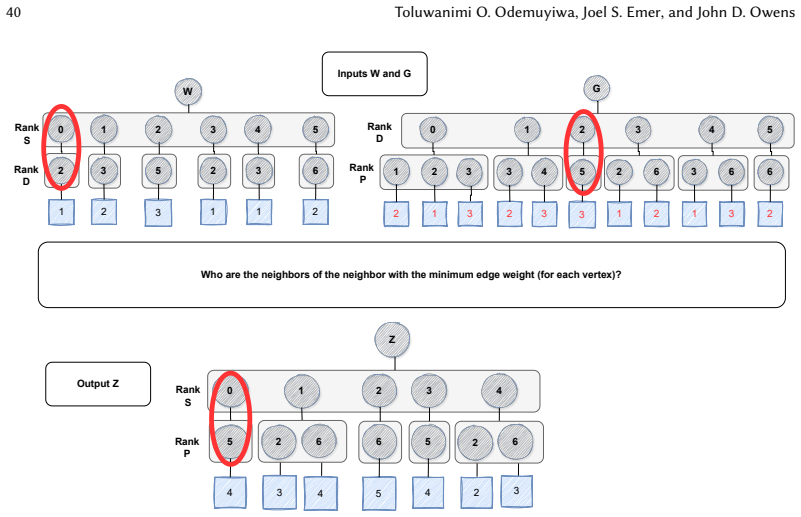

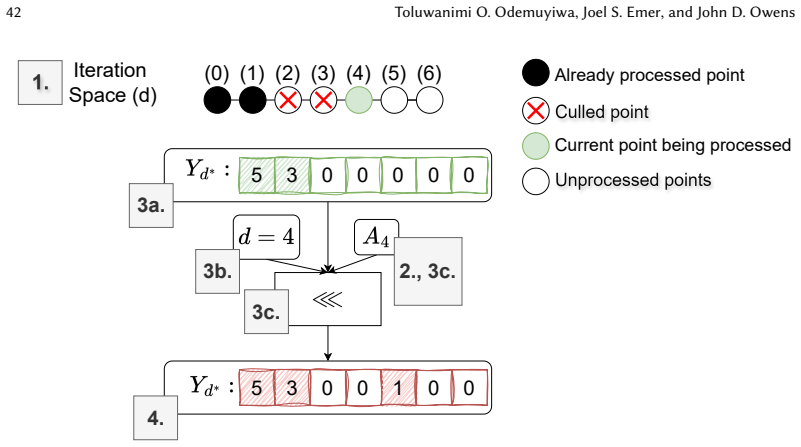


read the original abstract
In this work, we propose a unified abstraction for graph algorithms: the Extended General Einsums language, or EDGE. The EDGE language expresses graph algorithms in the language of tensor algebra, providing a rigorous, succinct, and expressive mathematical framework. EDGE leverages two ideas: (1) the well-known foundations provided by the graph-matrix duality, where a graph is simply a 2D tensor, and (2) the power and expressivity of Einsum notation in the tensor algebra world. In this work, we describe our design goals for EDGE and walk through the extensions we add to Einsums to support more complex operations common in graph algorithms. Additionally, we provide a few examples of how to express graph algorithms in our proposed notation. We hope that a single, mathematical notation for graph algorithms will (1) allow researchers to more easily compare different algorithms and different implementations of a graph algorithm; (2) enable developers to factor complexity by separating the concerns of what to compute (described with the extended Einsum notation) from the lower level details of how to compute; and (3) enable the discovery of different algorithmic variants of a problem through algebraic manipulations and transformations on a given EDGE expression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the EDGE (Extended General Einsums) language as a unified abstraction for graph algorithms. It extends Einsum notation using the graph-matrix duality to express graph algorithms in tensor algebra, describes design goals and extensions for complex graph operations, provides examples, and claims this will enable easier algorithm comparison, complexity factoring by separating what from how, and variant discovery via algebraic manipulations.
Significance. If accompanied by formal semantics and rewrite rules that demonstrably support the claimed manipulations, EDGE could provide a useful unified notation for graph algorithms, aiding comparison and implementation separation in graph theory and tensor algebra. The proposal builds on established ideas but currently offers only informal descriptions and examples.
major comments (2)
- [Abstract] Abstract: the claim that EDGE supplies a 'rigorous' mathematical framework supporting 'algebraic manipulations and transformations' for variant discovery is unsupported, as the manuscript supplies neither a grammar nor denotational semantics nor rewrite rules for the described extensions.
- [Extensions] Section describing the extensions: without explicit transformation rules or a semantics that preserves meaning under the listed operations, it is impossible to verify that the notation remains unambiguous or that complexity factoring and variant discovery are actually enabled by the extensions.
minor comments (1)
- The manuscript would benefit from an explicit comparison table or section contrasting EDGE with existing notations such as GraphBLAS or standard tensor libraries to clarify the precise scope of the proposed extensions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for formal foundations. We agree that the current informal presentation does not fully substantiate the claims of a rigorous framework enabling algebraic manipulations, and we will revise the manuscript accordingly by adding explicit syntax, semantics, and rewrite rules.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that EDGE supplies a 'rigorous' mathematical framework supporting 'algebraic manipulations and transformations' for variant discovery is unsupported, as the manuscript supplies neither a grammar nor denotational semantics nor rewrite rules for the described extensions.
Authors: We acknowledge that the abstract overstates the rigor of the current presentation. The manuscript grounds EDGE in the graph-matrix duality and illustrates extensions via examples, but does not supply a grammar, denotational semantics, or rewrite rules. In revision we will add a dedicated section defining the syntax of EDGE, a denotational semantics mapping expressions to tensor operations, and a small set of sound rewrite rules (e.g., associativity and distributivity transformations) that demonstrate how algebraic manipulation can produce algorithmic variants. These additions will directly support the abstract claim. revision: yes
-
Referee: [Extensions] Section describing the extensions: without explicit transformation rules or a semantics that preserves meaning under the listed operations, it is impossible to verify that the notation remains unambiguous or that complexity factoring and variant discovery are actually enabled by the extensions.
Authors: The observation is correct: the extensions section currently relies on descriptive text and examples rather than formal rules. To address this we will extend the section with (1) a compositional semantics that assigns meaning to each new operator while preserving equivalence to the underlying tensor expression, and (2) a collection of explicit transformation rules (including rules for re-association and operator reordering) together with brief proofs that the rules preserve semantics. These rules will illustrate both complexity factoring and variant discovery, allowing verification of the claimed benefits. revision: yes
Circularity Check
Notation proposal with no derivation chain or load-bearing reductions
full rationale
The paper introduces the EDGE notation by describing design goals, extensions to Einsum, and examples of expressing graph algorithms. It relies on the established graph-matrix duality and standard Einsum notation but presents no equations, predictions, fitted parameters, uniqueness theorems, or algebraic derivations. No steps reduce by construction to inputs, self-citations, or ansatzes. The work is a descriptive framework proposal, self-contained without any circular derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A graph is simply a 2D tensor (graph-matrix duality)
- domain assumption Einsum notation provides a rigorous and expressive base that can be extended for graph algorithms
invented entities (1)
-
EDGE language (Extended General Einsums)
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Fast and Fusiest: An Optimal Fusion-Aware Mapper for Accelerator Design
FFM finds optimal fused mappings for tensor accelerators over 10,000 times faster than prior mappers while cutting energy-delay product by up to 1.8x versus hand-tuned designs.
-
Mambalaya: Einsum-Based Fusion Optimizations on State-Space Models
Mambalaya delivers 4.9x prefill and 1.9x generation speedups on Mamba layers over prior accelerators by systematically fusing inter-Einsum operations.
Reference graph
Works this paper leans on
- [1]
-
[2]
2023. Fibertree Project. https://github.com/Fibertree-Project/fibertree
work page 2023
-
[3]
Andy Adinets. 2017. Adaptive Parallel Computation with CUDA Dynamic Parallelism. Blog Post. https://doi.org/ blog/introduction-cuda-dynamic-parallelism/
work page 2017
-
[4]
Willow Ahrens, Fredrik Kjolstad, and Saman Amarasinghe. 2022. Autoscheduling for Sparse Tensor Algebra with an Asymptotic Cost Model. In Proceedings of the 43rd ACM SIGPLAN International Conference on Programming Language Design and Implementation (PLDI ’22). ACM, 269–285. https://doi.org/10.1145/3519939.3523442
-
[5]
Corinne Ancourt and François Irigoin. 1991. Scanning Polyhedra with DO Loops. In Proceedings of the Third ACM SIGPLAN Symposium on Principles & Practice of Parallel Programming (Williamsburg, Virginia, USA) (PPOPP 1991), David S. Wise (Ed.). ACM, 39–50. https://doi.org/10.1145/109625.109631
-
[6]
Renzo Angles. 2018. The Property Graph Database Model. In Proceedings of the 12th Alberto Mendelzon International Workshop on Foundations of Data Management (Cali, Colombia) (CEUR Workshop Proceedings, Vol. 2100), Dan Olteanu and Barbara Poblete (Eds.). CEUR-WS.org. https://ceur-ws.org/Vol-2100/paper26.pdf
work page 2018
-
[7]
Baruch Awerbuch and Yossi Shiloach. 1987. New Connectivity and MSF Algorithms for Shuffle-Exchange Network and PRAM. IEEE Trans. Computers 36, 10 (1987), 1258–1263. https://doi.org/10.1109/TC.1987.1676869
-
[8]
Ariful Azad and Aydin Buluç. 2019. LACC: A Linear-Algebraic Algorithm for Finding Connected Components in Distributed Memory. In IEEE International Parallel and Distributed Processing Symposium (Rio de Janeiro, Brazil) (IPDPS 2019). IEEE, 2–12. https://doi.org/10.1109/IPDPS.2019.00012 The EDGE Language: Extended General Einsums for Graph Algorithms 71
-
[9]
John W. Backus, Robert J. Beeber, Sheldon Best, Richard Goldberg, Lois M. Haibt, Harlan L. Herrick, Robert A. Nelson, David Sayre, Peter B. Sheridan, H. Stern, Irving Ziller, Robert A. Hughes, and R. Nutt. 1957. The FORTRAN automatic coding system. In Papers presented at the 1957 Western Joint Computer Conference: Techniques for Reliability (Los Angeles, ...
-
[10]
Albert László Barabási, Natali Gulbahce, and Joseph Loscalzo. 2011. Network medicine: A network-based approach to human disease. Nature Reviews Genetics 12 (1 2011), 56–68. Issue 1. https://doi.org/10.1038/nrg2918
-
[11]
Richard Bellman. 1958. On a routing problem. Quarterly of applied mathematics 16, 1 (1958), 87–90
work page 1958
-
[12]
Vincent D Blondel, Jean-Loup Guillaume, Renaud Lambiotte, and Etienne Lefebvre. 2008. Fast unfolding of communities in large networks. Journal of Statistical Mechanics: Theory and Experiment 2008, 10 (Oct. 2008), P10008. https: //doi.org/10.1088/1742-5468/2008/10/p10008
-
[13]
Boisvert, Roldan Pozo, Karin Remington, Richard F
Ronald F. Boisvert, Roldan Pozo, Karin Remington, Richard F. Barrett, and Jack J. Dongarra. 1997. Matrix Market: a web resource for test matrix collections. In IFIP Advances in Information and Communication Technology . Springer US, 125–137. https://doi.org/10.1007/978-1-5041-2940-4_9
-
[14]
Pierre Boulet and Paul Feautrier. 1998. Scanning Polyhedra without Do-loops. In Proceedings of the 1998 International Conference on Parallel Architectures and Compilation Techniques (Paris, France). IEEE Computer Society, 4–11. https: //doi.org/10.1109/PACT.1998.727127
-
[15]
Ajay Brahmakshatriya, Yunming Zhang, Changwan Hong, Shoaib Kamil, Julian Shun, and Saman Amarasinghe. 2021. Compiling Graph Applications for GPUs with GraphIt. In IEEE/ACM International Symposium on Code Generation and Optimization (CGO 2021). 248–261. https://doi.org/10.1109/CGO51591.2021.9370321
-
[16]
2017.The GraphBLAS C API Specification
Aydın Buluç, Timothy Mattson, Scott McMillan, Jose Moreira, and Carl Yang. 2017.The GraphBLAS C API Specification . http://graphblas.org/index.php/C_language_API Rev. 1.1
work page 2017
-
[17]
Daniel Cederman and Philippas Tsigas. 2012. Dynamic Load Balancing Using Work-Stealing. In GPU Computing Gems Jade Edition , Wen mei W. Hwu (Ed.). Morgan Kaufmann, Boston, MA, USA, Chapter 35, 485–499. https: //doi.org/10.1016/B978-0-12-385963-1.00035-6
-
[18]
Sheaffer, Sang-Ha Lee, and Kevin Skadron
Shuai Che, Michael Boyer, Jiayuan Meng, David Tarjan, Jeremy W. Sheaffer, Sang-Ha Lee, and Kevin Skadron
-
[19]
In IEEE International Symposium on Workload Characterization (IISWC 2009)
Rodinia: A Benchmark Suite for Heterogeneous Computing. In IEEE International Symposium on Workload Characterization (IISWC 2009). 44–54. https://doi.org/10.1109/IISWC.2009.5306797
-
[20]
Stephen Chou, Fredrik Kjolstad, and Saman Amarasinghe. 2018. Format Abstraction for Sparse Tensor Algebra Compilers. Proceedings of the ACM on Programming Languages 2, OOPSLA (Oct. 2018), 1–30. https://doi.org/10.1145/ 3276493
work page 2018
-
[21]
Fan R. K. Chung. 1997. Spectral Graph Theory . Vol. 92. American Mathematical Society. https://dx.doi.org/10.1090/ cbms/092
work page 1997
-
[22]
Miguel E. Coimbra, Alexandre P. Francisco, and Luís Veiga. 2021. An analysis of the graph processing landscape. Journal of Big Data 8, 1 (2021), 55. https://doi.org/10.1186/s40537-021-00443-9
-
[23]
Keith D. Cooper and Linda Torczon. 2023. Chapter 4 - Intermediate Representations. In Engineering a Compiler (Third Edition) (third edition ed.), Keith D. Cooper and Linda Torczon (Eds.). Morgan Kaufmann, Philadelphia, 159–207. https://doi.org/10.1016/B978-0-12-815412-0.00010-3
-
[24]
The Theory of Industrial Organization
Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. 2022. Introduction to Algorithms, 4th Edition. MIT Press. https://mitpress.mit.edu/9780262367509
-
[25]
Timothy A. Davis. 2019. Algorithm 1000: SuiteSparse: GraphBLAS: Graph Algorithms in the Language of Sparse Linear Algebra. ACM Trans. Math. Softw. 45, 4 (Dec. 2019), 44:1–44:25. https://doi.org/10.1145/3322125
-
[26]
Xiaojun Dong, Yan Gu, Yihan Sun, and Yunming Zhang. 2021. Efficient Stepping Algorithms and Implementations for Parallel Shortest Paths. In 33rd ACM Symposium on Parallelism in Algorithms and Architectures (Virtual Event, USA) (SPAA ’21), Kunal Agrawal and Yossi Azar (Eds.). ACM, 184–197. https://doi.org/10.1145/3409964.3461782
-
[27]
Zhihui Du, Oliver Alvarado Rodriguez, Fuhuan Li, Mohammad Dindoost, and David Bader. 2023. Minimum-Mapping based Connected Components Algorithm. The 10th Annual Chapel Implementers and Users Workshop (CHIUW). https://chapel-lang.org/CHIUW/2023/Du.pdf
work page 2023
-
[28]
A. Einstein. 1916. The Foundation of the General Theory of Relativity. Annalen der Physik 354, 7 (Jan. 1916), 769–822. https://doi.org/10.1002/andp.19163540702
-
[29]
Lester Randolph Ford. 2015. Flows in networks. (2015)
work page 2015
-
[30]
Anil Gaihre, Xiaoye Sherry Li, and Hang Liu. 2022. gSoFa: Scalable Sparse Symbolic LU Factorization on GPUs. IEEE Transactions on Parallel and Distributed Systems 33, 4 (2022), 1015–1026. https://doi.org/10.1109/TPDS.2021.3090316
-
[31]
Michael Gilbert, Yannan Nellie Wu, Angshuman Parashar, Vivienne Sze, and Joel S. Emer. 2023. LoopTree: Enabling Exploration of Fused-layer Dataflow Accelerators. 2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 316–318. https://doi.org/10.1109/ispass57527.2023.00038 72 Toluwanimi O. Odemuyiwa, Joel S. Emer, and J...
- [32]
-
[33]
Wei Guo and Jing-Mei Qiu. 2022. A low rank tensor representation of linear transport and nonlinear Vlasov solutions and their associated flow maps. J. Comput. Phys. 458 (2022), 111089. https://doi.org/10.1016/j.jcp.2022.111089
-
[34]
Hamilton, Zhitao Ying, and Jure Leskovec
William L. Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive Representation Learning on Large Graphs. In Advances in Neural Information Processing Systems (Long Beach, CA, USA) (NeurIPS 2017), Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett (Eds.). 1024–1034
work page 2017
-
[35]
F. Harary and G. Gupta. 1997. Dynamic Graph Models. Math. Comput. Model. 25, 7 (April 1997), 79–87. https: //doi.org/10.1016/S0895-7177(97)00050-2
-
[36]
Charles R. Harris, K. Jarrod Millman, Stéfan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, Allan Haldane, Jaime Fernández del Río, Mark Wiebe, Pearu Peterson, Pierre Gérard- Marchant, Kevin Shep...
-
[37]
Array programming with NumPy. Nature 585, 7825 (Sept. 2020), 357–362. https://doi.org/10.1038/s41586-020- 2649-2
-
[38]
Kartik Hegde, Hadi Asghari Moghaddam, Michael Pellauer, Neal Clayton Crago, Aamer Jaleel, Edgar Solomonik, Joel S. Emer, and Christopher W. Fletcher. 2019. ExTensor: An Accelerator for Sparse Tensor Algebra. InProceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO-52) . 319–333. https://doi.org/10.1145/ 3352460.3358275
-
[39]
Kartik Hegde, Po-An Tsai, Sitao Huang, Vikas Chandra, Angshuman Parashar, and Christopher W. Fletcher. 2021. Mind mappings: enabling efficient algorithm-accelerator mapping space search. In 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (Virtual Event, USA) (ASPLOS 2021), Tim Sherwood, Emery D. B...
-
[40]
Amarasinghe, and Fredrik Kjolstad
Rawn Henry, Olivia Hsu, Rohan Yadav, Stephen Chou, Kunle Olukotun, Saman P. Amarasinghe, and Fredrik Kjolstad
-
[41]
Compilation of sparse array programming models. Proc. ACM Program. Lang. 5, OOPSLA (2021), 1–29. https://doi.org/10.1145/3485505
-
[42]
Charles Hong, Qijing Huang, Grace Dinh, Mahesh Subedar, and Yakun Sophia Shao. 2023. DOSA: Differentiable Model- Based One-Loop Search for DNN Accelerators. In56th Annual IEEE/ACM International Symposium on Microarchitecture (Toronto, ON) (MICRO ’23). IEEE, 209–224. https://doi.org/10.1145/3613424.3623797
-
[43]
Hopcroft and Robert Endre Tarjan
John E. Hopcroft and Robert Endre Tarjan. 1973. Algorithm 447: efficient algorithms for graph manipulation.Commun. ACM 16, 6 (1973), 372–378. https://doi.org/10.1145/362248.362272
-
[44]
Olivia Hsu, Maxwell Strange, Ritvik Sharma, Jaeyeon Won, Kunle Olukotun, Joel S. Emer, Mark A. Horowitz, and Fredrik Kjølstad. 2023. The Sparse Abstract Machine. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (Vancouver, BC, Canada) (ASPLOS ’23, Vol. 3). 710–726. https://doi...
-
[45]
Qijing Huang, Aravind Kalaiah, Minwoo Kang, James Demmel, Grace Dinh, John Wawrzynek, Thomas Norell, and Yakun Sophia Shao. 2021. CoSA: Scheduling by Constrained Optimization for Spatial Accelerators. In 48th ACM/IEEE Annual International Symposium on Computer Architecture (Valencia, Spain) (ISCA 2021). IEEE, 554–566. https://doi.org/10.1109/ISCA52012.2021.00050
-
[46]
Sheng-Chun Kao and Tushar Krishna. 2020. GAMMA: Automating the HW Mapping of DNN Models on Accelerators via Genetic Algorithm. In IEEE/ACM International Conference On Computer Aided Design (San Diego, CA, USA) (ICCAD 2020). IEEE, 44:1–44:9. https://doi.org/10.1145/3400302.3415639
-
[47]
David Kempe, Jon Kleinberg, and Éva Tardos. 2003. Maximizing the spread of influence through a social network. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Washington, D.C.) (KDD ’03). Association for Computing Machinery, New York, NY, USA, 137–146. https://doi.org/10.1145/956750. 956769
-
[48]
Owens, Carl Yang, Marcin Zalewski, and Timothy Mattson
Jeremy Kepner, Peter Aaltonen, David Bader, Aydın Buluç, Franz Franchetti, John Gilbert, Dylan Hutchison, Manoj Kumar, Andrew Lumsdaine, Henning Meyerhenke, Scott McMillan, Jose Moreira, John D. Owens, Carl Yang, Marcin Zalewski, and Timothy Mattson. 2016. Mathematical Foundations of the GraphBLAS. In Proceedings of the IEEE High Performance Extreme Compu...
-
[49]
Jeremy Kepner and John R. Gilbert (Eds.). 2011. Graph Algorithms in the Language of Linear Algebra . Software, environments, tools, Vol. 22. SIAM. https://doi.org/10.1137/1.9780898719918
-
[50]
Fredrik Kjolstad, Shoaib Kamil, Stephen Chou, David Lugato, and Saman Amarasinghe. 2017. The tensor algebra compiler. Proceedings of the ACM on Programming Languages 1, OOPSLA (Oct. 2017), 1–29. https://doi.org/10.1145/ 3133901 The EDGE Language: Extended General Einsums for Graph Algorithms 73
work page 2017
-
[51]
Fredrik Berg Kjolstad. 2020. Sparse Tensor Algebra Compilation. PhD thesis. Massachusetts Institute of Technology, Cambridge, MA. Available at https://dspace.mit.edu/handle/1721.1/128314
work page 2020
-
[52]
Haewoon Kwak, Changhyun Lee, Hosung Park, and Sue B. Moon. 2010. What is Twitter, a social network or a news media?. In Proceedings of the 19th International Conference on World Wide Web, WWW 2010, Raleigh, North Carolina, USA, April 26-30, 2010. ACM, 591–600. https://doi.org/10.1145/1772690.1772751
-
[53]
Hyoukjun Kwon, Prasanth Chatarasi, Michael Pellauer, Angshuman Parashar, Vivek Sarkar, and Tushar Krishna. 2019. Understanding Reuse, Performance, and Hardware Cost of DNN Dataflow: A Data-Centric Approach. InProceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture (Columbus, OH, USA) (MICRO 2019). ACM, 754–768. https://doi.org...
- [54]
-
[55]
Sören Laue, Matthias Mitterreiter, and Joachim Giesen. 2020. A Simple and Efficient Tensor Calculus. Proceedings of the AAAI Conference on Artificial Intelligence 34, 04 (April 2020), 4527–4534. https://doi.org/10.1609/aaai.v34i04.5881
-
[56]
Jure Leskovec and Christos Faloutsos. 2006. Sampling from large graphs. In Proceedings of the Twelfth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Philadelphia, PA, USA) (KDD’06), Tina Eliassi-Rad, Lyle H. Ungar, Mark Craven, and Dimitrios Gunopulos (Eds.). ACM, 631–636. https://doi.org/10.1145/1150402.1150479
-
[57]
Sixue Cliff Liu and Robert Endre Tarjan. 2022. Simple Concurrent Connected Components Algorithms. ACM Trans. Parallel Comput. 9, 2 (2022), 9:1–9:26. https://doi.org/10.1145/3543546
-
[58]
Grzegorz Malewicz, Matthew H. Austern, Aart J. C. Bik, James C. Dehnert, Ilan Horn, Naty Leiser, and Grzegorz Czajkowski. 2010. Pregel: A System for Large-scale Graph Processing. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data (Indianapolis, Indiana, USA) (SIGMOD ’10). 135–146. https://doi.org/ 10.1145/1807167.1807184
-
[59]
Robert Ryan McCune, Tim Weninger, and Greg Madey. 2015. Thinking Like a Vertex: A Survey of Vertex-Centric Frameworks for Large-Scale Distributed Graph Processing. ACM Comput. Surv. 48, 2, Article 25 (Oct. 2015), 39 pages. https://doi.org/10.1145/2818185
-
[60]
Duane Merrill, Michael Garland, and Andrew Grimshaw. 2012. Scalable GPU Graph Traversal. In Proceedings of the 17th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (New Orleans, Louisiana, USA) (PPoPP ’12). 117–128. https://doi.org/10.1145/2145816.2145832
-
[61]
Edward F Moore. 1959. The shortest path through a maze. In Proc. of the International Symposium on the Theory of Switching. Harvard University Press, 285–292
work page 1959
-
[62]
Francisco Muñoz-Martínez, Raveesh Garg, Michael Pellauer, José L. Abellán, Manuel E. Acacio, and Tushar Krishna
-
[63]
Flexagon: A Multi-dataflow Sparse-Sparse Matrix Multiplication Accelerator for Efficient DNN Processing. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (Vancouver, BC, Canada) (ASPLOS 2023), Tor M. Aamodt, Natalie D. Enright Jerger, and Michael M. Swift (Eds.). ACM, 252–265....
-
[64]
Tanase, Hyesoon Kim, and Ching-Yung Lin
Lifeng Nai, Yinglong Xia, Ilie G. Tanase, Hyesoon Kim, and Ching-Yung Lin. 2015. GraphBIG: understanding graph computing in the context of industrial solutions. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC’15). 1–12. https://doi.org/10.1145/2807591.2807626
-
[65]
Odemuyiwa, Shubham Ugare, Christopher Fletcher, Michael Pellauer, and Joel Emer
Nandeeka Nayak, Toluwanimi O. Odemuyiwa, Shubham Ugare, Christopher Fletcher, Michael Pellauer, and Joel Emer. 2023. TeAAL: A Declarative Framework for Modeling Sparse Tensor Accelerators. In56th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO ’23). ACM, 1255–1270. https://doi.org/10.1145/3613424.3623791
-
[66]
Toluwanimi O. Odemuyiwa, Hadi Asghari-Moghaddam, Michael Pellauer, Kartik Hegde, Po-An Tsai, Neal Crago, Aamer Jaleel, John D. Owens, Edgar Solomonik, Joel Emer, and Christopher Fletcher. 2023. Accelerating Sparse Data Orchestration via Dynamic Reflexive Tiling. In Proceedings of the 28th ACM International Conference on Architectural Support for Programmi...
-
[67]
Muhammad Osama, Serban D. Porumbescu, and John D. Owens. 2022. Essentials of Parallel Graph Analytics. In Proceedings of the Workshop on Graphs, Architectures, Programming, and Learning (GrAPL 2022) . 314–317. https: //doi.org/10.1109/IPDPSW55747.2022.00061
-
[68]
Muhammad Osama, Serban D. Porumbescu, and John D. Owens. 2023. A Programming Model for GPU Load Balancing. In Proceedings of the 28th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP 2023) . 79–91. https://doi.org/10.1145/3572848.3577434
-
[69]
Angshuman Parashar, Priyanka Raina, Yakun Sophia Shao, Yu-Hsin Chen, Victor A. Ying, Anurag Mukkara, Rang- harajan Venkatesan, Brucek Khailany, Stephen W. Keckler, and Joel Emer. 2019. Timeloop: A Systematic Approach to DNN Accelerator Evaluation. In 2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 304–315. https...
-
[70]
Adam Paszke, S. Gross, Francisco Massa, A. Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Z. Lin, N. Gimelshein, L. Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. PyTorch: An Imperative Style, High-Performance Deep...
-
[71]
Michael Pellauer, Yakun Sophia Shao, Jason Clemons, Neal Crago, Kartik Hegde, Rangharajan Venkatesan, Stephen W. Keckler, Christopher W. Fletcher, and Joel Emer. 2019. Buffets: An Efficient and Composable Storage Idiom for Explicit Decoupled Data Orchestration. In International Conference on Architectural Support for Programming Languages and Operating Sy...
-
[72]
Louis-Noël Pouchet, Uday Bondhugula, Cédric Bastoul, Albert Cohen, J. Ramanujam, P. Sadayappan, and Nicolas Vasilache. 2011. Loop transformations: convexity, pruning and optimization. In Proceedings of the 38th ACM SIGPLAN- SIGACT Symposium on Principles of Programming Languages (Austin, TX, USA) (POPL 2011), Thomas Ball and Mooly Sagiv (Eds.). ACM, 549–5...
- [73]
-
[74]
Sumit Purohit, Nhuy Van, and George Chin. 2021. Semantic Property Graph for Scalable Knowledge Graph Analytics. In 2021 IEEE International Conference on Big Data (Orlando, FL, USA) (Big Data), Yixin Chen, Heiko Ludwig, Yicheng Tu, Usama M. Fayyad, Xingquan Zhu, Xiaohua Hu, Suren Byna, Xiong Liu, Jianping Zhang, Shirui Pan, Vagelis Papalexakis, Jianwu Wang...
-
[75]
Jonathan Ragan-Kelley, Connelly Barnes, Andrew Adams, Sylvain Paris, Frédo Durand, and Saman Amarasinghe
-
[76]
Halide: A Language and Compiler for Optimizing Parallelism, Locality, and Recomputation in Image Processing Pipelines. In Proceedings of the 34th ACM SIGPLAN Conference on Programming Language Design and Implementation (Seattle, Washington, USA) (PLDI ’13). 519–530. https://doi.org/10.1145/2491956.2462176
-
[77]
John H. Reif. 1985. Optimal parallel algorithms for integer sorting and graph connectivity . Technical Report TR-08-85. Harvard University, Cambridge, MA
work page 1985
-
[78]
Amitabha Roy, Ivo Mihailovic, and Willy Zwaenepoel. 2013. X-Stream: Edge-centric Graph Processing using Streaming Partitions. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles (Farmington, PA, USA) (SOSP ’13), Michael Kaminsky and Mike Dahlin (Eds.). ACM, 472–488. https://doi.org/10.1145/2517349.2522740
-
[79]
Mo Sha, Yuchen Li, and Kian-Lee Tan. 2019. GPU-based Graph Traversal on Compressed Graphs. In Proceedings of the 2019 International Conference on Management of Data (Amsterdam, The Netherlands) (SIGMOD Conference 2019), Peter A. Boncz, Stefan Manegold, Anastasia Ailamaki, Amol Deshpande, and Tim Kraska (Eds.). ACM, 775–792. https://doi.org/10.1145/3299869.3319871
-
[80]
Julian Shun and Guy E. Blelloch. 2013. Ligra: a lightweight graph processing framework for shared memory. In Proceedings of the 18th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (Shenzhen, China) (PPoPP ’13). 135–146. https://doi.org/10.1145/2442516.2442530
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.