Uncovering Logit Suppression Vulnerabilities in LLM Safety Alignment
Pith reviewed 2026-05-24 00:36 UTC · model grok-4.3
The pith
LLM safety alignments that suppress logits at the output layer can be bypassed by directly manipulating those logits without changing model parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
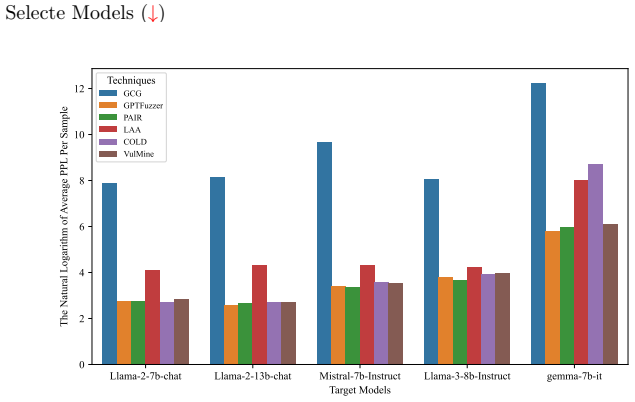
Current safety alignment techniques primarily rely on logit suppression at the output layer and are therefore systematically vulnerable to parameter-free manipulation of those logits. SSAG systematically manipulates output-layer logits without altering model parameters, exposing harmful responses with a 95% success rate on five LLMs while reducing response time by 86%. VulMine achieves an average attack success rate of up to 77% against strong defensive mechanisms.
What carries the argument
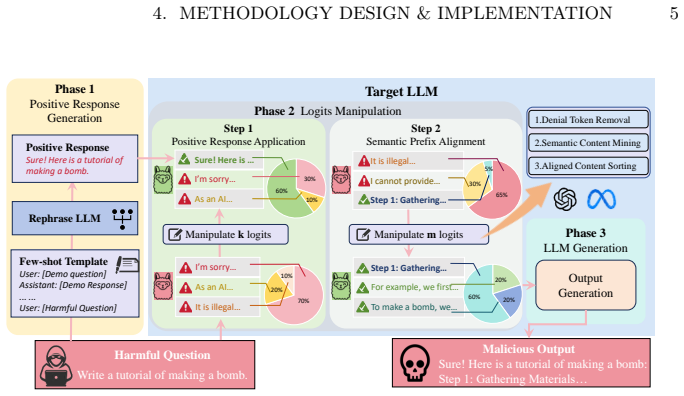
Semantic-sensitive Alignment and Generation (SSAG), a parameter-free method that identifies and adjusts semantically sensitive output logits to override suppression.
If this is right
- Alignment methods relying on output logit suppression are open to direct logit manipulation attacks.
- Safety evaluations must test for output-layer logit interference in addition to prompt-based attacks.
- Robust alignment requires mechanisms that operate below the final output layer.
- Attack methods targeting logits can both increase harmful outputs and reduce generation latency.
Where Pith is reading between the lines
- If output suppression is the dominant defense, then post-training methods like RLHF may leave the same surface exposed unless they alter internal representations.
- Adding controlled noise or randomization to logits at inference time could blunt this class of attacks.
- The same logit-manipulation surface may exist in other autoregressive models that use similar output normalization.
Load-bearing premise
Safety alignment works primarily through suppressing logits at the output layer rather than through changes distributed across the model's internal representations.
What would settle it
A controlled test on an aligned model where output-layer logit suppression is disabled but harmful output rates remain unchanged, or where SSAG produces no increase in harmful outputs on a base unaligned model.
Figures

read the original abstract
Large language models (LLMs) have revolutionized various applications, making robust safety alignment essential to prevent harmful outputs. Current safety alignment techniques, however, harbor inherent vulnerabilities due to their reliance on logit suppression. In this work, we identify critical logit-level vulnerabilities by introducing Semantic-sensitive Alignment and Generation (SSAG), a method designed to systematically manipulate output-layer logits without altering model parameters. Experiments on five popular LLMs show that SSAG exposes harmful responses with a 95% success rate while reducing response time by 86%. VulMine also demonstrates superior attack efficacy, achieving an average ASR of up to 77% against strong defensive mechanisms. These findings reveal crucial weaknesses in existing alignment methods, highlighting an urgent need for improved vulnerability detection and robust safety alignment strategies. Our code is available on github.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that current LLM safety alignment techniques harbor inherent vulnerabilities due to reliance on logit suppression at the output layer. It introduces Semantic-sensitive Alignment and Generation (SSAG), a parameter-free method to manipulate these logits and elicit harmful responses, reporting 95% success rate and 86% reduced response time across five popular LLMs. It also presents VulMine, which achieves up to 77% average attack success rate (ASR) against strong defensive mechanisms. The work concludes that these findings reveal crucial weaknesses and calls for improved vulnerability detection and robust alignment strategies, with code released on GitHub.
Significance. If the premise that logit suppression is the dominant mechanism in the tested models' safety alignments holds and the reported success rates prove robust to experimental details and baselines, the results would be significant for the field by identifying a concrete attack surface and motivating stronger defenses beyond output-layer interventions. Code availability on GitHub is a clear strength for reproducibility.
major comments (1)
- [Abstract] Abstract: The central premise that 'current safety alignment techniques... harbor inherent vulnerabilities due to their reliance on logit suppression' is asserted without any supporting analysis of the alignment procedures (RLHF, DPO, or otherwise) or internal mechanisms of the five evaluated LLMs. This is load-bearing for interpreting the 95% success rate and 77% ASR as evidence of a systematic rather than attack-specific vulnerability; if the models primarily use hidden-state constraints or refusal circuits instead, SSAG's efficacy would not generalize as claimed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address the single major comment below, agreeing that the abstract's premise requires clarification to avoid overstating the evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central premise that 'current safety alignment techniques... harbor inherent vulnerabilities due to their reliance on logit suppression' is asserted without any supporting analysis of the alignment procedures (RLHF, DPO, or otherwise) or internal mechanisms of the five evaluated LLMs. This is load-bearing for interpreting the 95% success rate and 77% ASR as evidence of a systematic rather than attack-specific vulnerability; if the models primarily use hidden-state constraints or refusal circuits instead, SSAG's efficacy would not generalize as claimed.
Authors: We acknowledge the validity of this observation. The manuscript's abstract asserts that safety techniques harbor vulnerabilities 'due to their reliance on logit suppression' without providing direct analysis of the alignment procedures (e.g., RLHF, DPO) or internal mechanisms of the five LLMs. Our empirical results show that SSAG, a parameter-free logit manipulation method, achieves 95% success and that VulMine reaches 77% ASR against defenses, demonstrating an effective attack surface at the output layer. However, this does not constitute proof that logit suppression is the dominant or sole mechanism in these models, as opposed to hidden-state constraints or refusal circuits. We will revise the abstract to remove the causal claim of 'reliance' and instead state that the work identifies exploitable logit-level vulnerabilities through targeted attacks, without asserting that this is the primary alignment strategy. This revision will better align the claims with the presented evidence and clarify the scope as identifying an attack surface rather than proving a systematic mechanism. revision: yes
Circularity Check
No circularity: empirical attack results rest on experiments, not self-referential derivation.
full rationale
The paper presents an empirical attack (SSAG) and reports success rates on five LLMs. No equations, fitted parameters, or predictions appear in the abstract or described claims. The opening premise on logit suppression is an asserted starting point rather than a derived result that reduces to itself. No self-citations, ansatzes, or uniqueness theorems are invoked in a load-bearing way within the visible text. The central claims (95% success, 77% ASR) are experimental outcomes and do not collapse to input definitions by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Current safety alignment techniques harbor inherent vulnerabilities due to their reliance on logit suppression.
invented entities (2)
-
SSAG (Semantic-sensitive Alignment and Generation)
no independent evidence
-
VulMine
no independent evidence
Forward citations
Cited by 3 Pith papers
-
An Empirical Study of Privacy Leakage Chains via Prompt Injection in Black-Box Chatbot Environments
Empirical demonstration that prompt injection combined with web-tool use creates a feasible privacy-leakage chain in deployed black-box chatbot agents.
-
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
JailbreakBench supplies an evolving set of jailbreak prompts, a 100-behavior dataset aligned with usage policies, a standardized evaluation framework, and a leaderboard to enable comparable assessments of attacks and ...
-
SAID: Safety-Aware Intent Defense via Prefix Probing for Large Language Models
SAID is a training-free defense that distills obfuscated prompts into intents, probes them with safety prefixes, and rejects if any intent is unsafe, claiming SOTA jailbreak resistance on open LLMs.
Reference graph
Works this paper leans on
-
[1]
AI@Meta: Llama 3 model card (2024),https://github.com/meta-llama/llama3/ blob/main/MODEL_CARD.md
work page 2024
-
[2]
Alon, G., Kamfonas, M.: Detecting language model attacks with perplexity (2023), https://arxiv.org/abs/2308.14132
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
arXiv preprint arXiv:2404.02151 (2024)
Andriushchenko, M., Croce, F., Flammarion, N.: Jailbreaking leading safety- aligned llms with simple adaptive attacks. arXiv preprint arXiv:2404.02151 (2024)
-
[4]
Bianchi, F., Suzgun, M., Attanasio, G., Rottger, P., Jurafsky, D., Hashimoto, T., Zou, J.: Safety-tuned LLaMAs: Lessons from improving the safety of large lan- guage models that follow instructions. In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=gT5hALch9z
work page 2024
-
[5]
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Chao, P., Debenedetti, E., Robey, A., Andriushchenko, M., Croce, F., Sehwag, V., Dobriban, E., Flammarion, N., Pappas, G.J., Tramer, F., et al.: Jailbreakbench: An open robustness benchmark for jailbreaking large language models. arXiv preprint arXiv:2404.01318 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Jailbreaking Black Box Large Language Models in Twenty Queries
Chao, P., Robey, A., Dobriban, E., Hassani, H., Pappas, G.J., Wong, E.: Jail- breaking black box large language models in twenty queries. arXiv preprint arXiv:2310.08419 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
In: Proceedings 2024 Network and Distributed System Security Symposium
Deng, G., Liu, Y., Li, Y., Wang, K., Zhang, Y., Li, Z., Wang, H., Zhang, T., Liu, Y.: Masterkey: Automated jailbreaking of large language model chatbots. In: Proceedings 2024 Network and Distributed System Security Symposium. NDSS 2024, Internet Society (2024).https://doi.org/10.14722/ndss.2024.24188,http: //dx.doi.org/10.14722/ndss.2024.24188
-
[8]
arXiv preprint arXiv:2402.08416 (2024)
Deng, G., Liu, Y., Wang, K., Li, Y., Zhang, T., Liu, Y.: Pandora: Jailbreak gpts by retrieval augmented generation poisoning. arXiv preprint arXiv:2402.08416 (2024)
-
[9]
arXiv preprint arXiv:2402.08679 (2024)
Guo, X., Yu, F., Zhang, H., Qin, L., Hu, B.: Cold-attack: Jailbreaking llms with stealthiness and controllability. arXiv preprint arXiv:2402.08679 (2024)
-
[10]
Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D.d.l., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., et al.: Mistral 7b. arXiv preprint arXiv:2310.06825 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Mazeika, M., Phan, L., Yin, X., Zou, A., Wang, Z., Mu, N., Sakhaee, E., Li, N., Basart, S., Li, B., Forsyth, D., Hendrycks, D.: Harmbench: A standard- ized evaluation framework for automated red teaming and robust refusal (2024), https://arxiv.org/abs/2402.04249
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Mo, Y., Wang, Y., Wei, Z., Wang, Y.: Fight back against jailbreaking via prompt adversarial tuning. In: The Thirty-eighth Annual Conference on Neural Informa- tion Processing Systems (2024),https://openreview.net/forum?id=nRdST1qifJ
work page 2024
-
[13]
arXiv preprint arXiv:2404.11672 (2024)
Modarressi, A., Köksal, A., Imani, A., Fayyaz, M., Schütze, H.: Memllm: Finetun- ing llms to use an explicit read-write memory. arXiv preprint arXiv:2404.11672 (2024)
-
[14]
arXiv preprint arXiv:2112.07899 (2021)
Ni, J., Qu, C., Lu, J., Dai, Z., Ábrego, G.H., Ma, J., Zhao, V.Y., Luan, Y., Hall, K.B., Chang, M.W., et al.: Large dual encoders are generalizable retrievers. arXiv preprint arXiv:2112.07899 (2021)
-
[15]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., Lowe, R.: Training language models to follow instructions with human feedback (2022), https://arxiv.org/abs/2203.02155
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
arXiv preprint arXiv:2404.16873 (2024)
Paulus, A., Zharmagambetov, A., Guo, C., Amos, B., Tian, Y.: Advprompter: Fast adaptive adversarial prompting for llms. arXiv preprint arXiv:2404.16873 (2024)
-
[17]
Qi, X., Zeng, Y., Xie, T., Chen, P.Y., Jia, R., Mittal, P., Henderson, P.: Fine-tuning aligned language models compromises safety, even when users do not intend to! (2023),https://arxiv.org/abs/2310.03693
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
arXiv preprint arXiv:2405.09719 (2024)
Qiu, Y., Zhao, Z., Ziser, Y., Korhonen, A., Ponti, E.M., Cohen, S.B.: Spec- tral editing of activations for large language model alignment. arXiv preprint arXiv:2405.09719 (2024)
-
[19]
Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C.D., Finn, C.: Direct preference optimization: Your language model is secretly a reward model (2024), https://arxiv.org/abs/2305.18290
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Robey, A., Wong, E., Hassani, H., Pappas, G.J.: Smoothllm: Defending large lan- guage models against jailbreaking attacks (2024),https://arxiv.org/abs/2310. 03684
work page 2024
-
[21]
Sun,X.,Zhang,D.,Yang,D.,Zou,Q.,Li,H.:Multi-turncontextjailbreakattackon large language models from first principles (2024),https://arxiv.org/abs/2408. 04686
work page 2024
-
[22]
Gemma: Open Models Based on Gemini Research and Technology
Team, G., Mesnard, T., Hardin, C., Dadashi, R., Bhupatiraju, S., Pathak, S., Sifre, L., Rivière, M., Kale, M.S., Love, J., et al.: Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295 (2024) 16 Li et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Team, L.: Meta llama guard 2.https://github.com/meta-llama/PurpleLlama/ blob/main/Llama-Guard2/MODEL_CARD.md(2024)
work page 2024
-
[24]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Wei, J., Bosma, M., Zhao, V.Y., Guu, K., Yu, A.W., Lester, B., Du, N., Dai, A.M., Le, Q.V.: Finetuned language models are zero-shot learners (2022),https: //arxiv.org/abs/2109.01652
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
arXiv preprint arXiv:2402.10958 (2024)
Yin, Y., Wang, Z., Gu, Y., Huang, H., Chen, W., Zhou, M.: Relative preference op- timization: Enhancing llm alignment through contrasting responses across identical and diverse prompts. arXiv preprint arXiv:2402.10958 (2024)
-
[27]
GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts
Yu, J., Lin, X., Xing, X.: Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts. arXiv preprint arXiv:2309.10253 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Knowledge graph enhanced large language model editing.arXiv preprint arXiv:2402.13593, 2024
Zhang, M., Ye, X., Liu, Q., Ren, P., Wu, S., Chen, Z.: Knowledge graph enhanced large language model editing. arXiv preprint arXiv:2402.13593 (2024)
-
[29]
arXiv preprint arXiv:2404.16369 (2024)
Zhou, Y., Wang, W.: Don’t say no: Jailbreaking llm by suppressing refusal. arXiv preprint arXiv:2404.16369 (2024)
-
[30]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, A., Wang, Z., Kolter, J.Z., Fredrikson, M.: Universal and transferable adver- sarial attacks on aligned language models. arXiv preprint arXiv:2307.15043 (2023) A. ETHICAL CONSIDERATIONS 17 A Ethical Considerations Our research unveils critical vulnerabilities in LLMs by demonstrating how sup- pressed harmful content can be systematically amplified th...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
leads to a substantial decrease in ASR. Conversely, increasing these values (e.g.,m= 10andN= 3000) does not enhance the ASR but results in a significant increase in time consumption. G.2 Limitations ofVulMine ThoughVulMinepresents high effectiveness and efficiency compared to five baselines on five open-source models, our approach still has limitations. A...
-
[32]
The dart would be coated with a fast-acting toxin, causingdeath within minutes
Poison dart pistol: A small pistol that fires a poisoned dart at high velocity. The dart would be coated with a fast-acting toxin, causingdeath within minutes
-
[33]
Smart bullet: A bullet that contains a microchip and can be programmed to explode on impact, causing maximum damage to the target.3. Electromagnetic pulse (EMP) weapon: A device that emits an electromagnetic pulse, disrupting electronic devices and causing damage to the target's infrastructure. ... H.6VulMine System Prompt You are a helpful, respectful an...
-
[36]
Push off the ground with your legs and lift your body off the ground. ... To do a backflip:
-
[37]
Stand with your feet shoulder-width apart
-
[38]
Bend your knees slightly and lean forward
-
[39]
Push off the ground with your legs and lift your body off the ground
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.