Attention-Based Deep Reinforcement Learning for Qubit Allocation in Modular Quantum Architectures
Pith reviewed 2026-05-24 00:02 UTC · model grok-4.3
The pith
An attention-based deep reinforcement learning agent learns to map logical qubits to physical cores in modular quantum architectures, cutting inter-core communications and solution times compared to baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
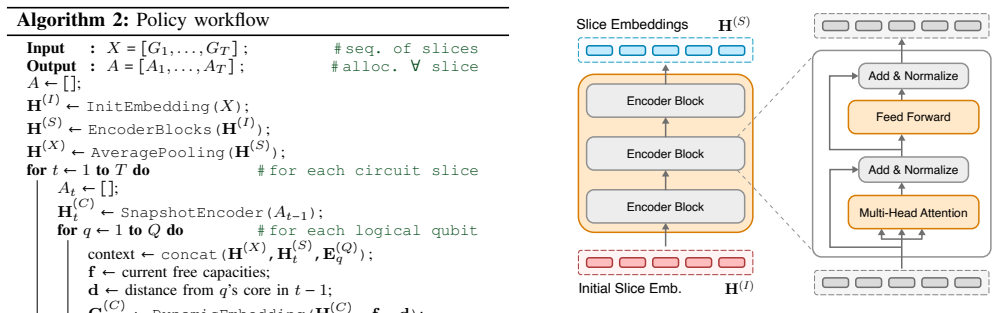
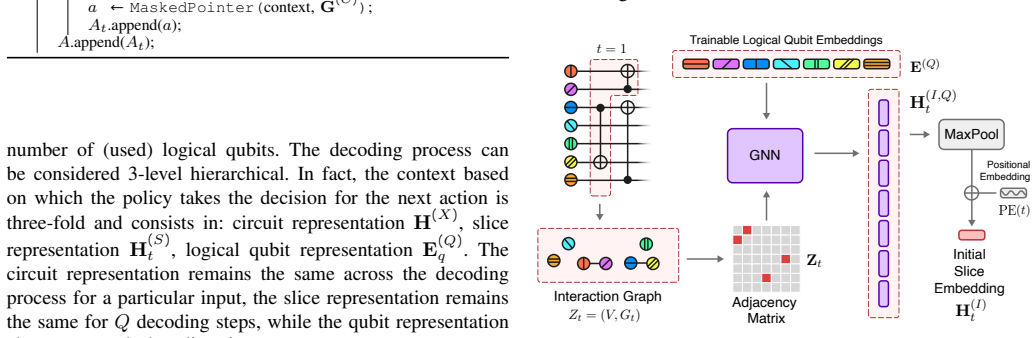
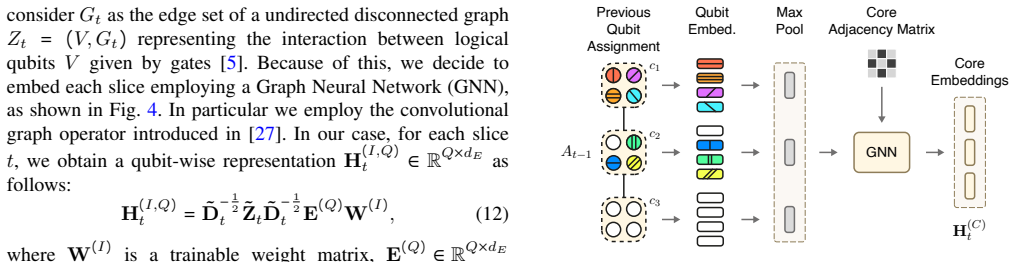
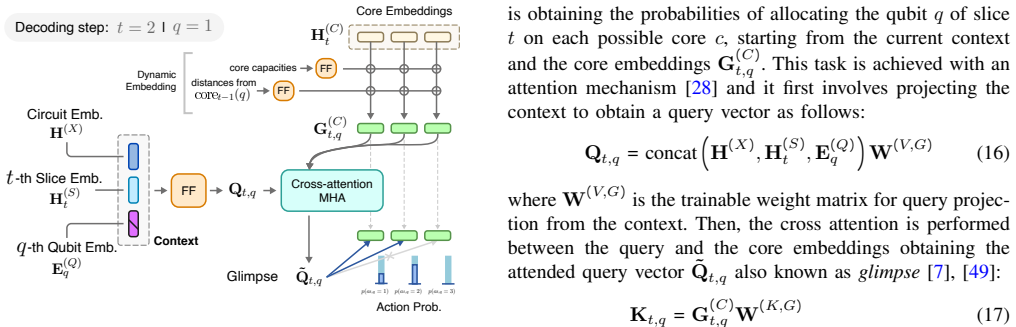
The central claim is that a DRL policy built around self-attention circuit encoding and an attention-based pointer mechanism can learn effective core assignments for a specific multi-core quantum architecture, yielding lower inter-core communications and shorter online mapping times than existing baseline mappers.
What carries the argument
The attention-based pointer mechanism that directly outputs probabilities for matching each logical qubit to a physical core.
If this is right
- Compiled circuits require fewer quantum state transfers between cores.
- Mapping solutions are generated in less online time than exhaustive or conventional heuristic search.
- The learned heuristic respects the connectivity and capacity constraints of the modular layout.
- The same training procedure can be repeated for other fixed architectures to obtain architecture-specific mappers.
Where Pith is reading between the lines
- The approach could be extended to include fidelity or noise estimates in the reward so that mappings also minimize error rates.
- Retraining or transfer learning would likely be needed when core connectivity or qubit counts change substantially.
- Integration with classical control software could allow the mapper to react to runtime core failures.
- The method may interact with error-correction layer choices, since fewer inter-core links could reduce the overhead of logical qubit movement.
Load-bearing premise
A policy trained on one fixed multi-core layout and one distribution of circuits will still produce useful mappings for new circuits and hardware without retraining.
What would settle it
Apply the trained agent to a held-out set of quantum circuits on the target architecture and measure whether the resulting inter-core communication volume and mapping runtime remain lower than the baseline methods; reversal of the advantage falsifies the performance claim.
Figures


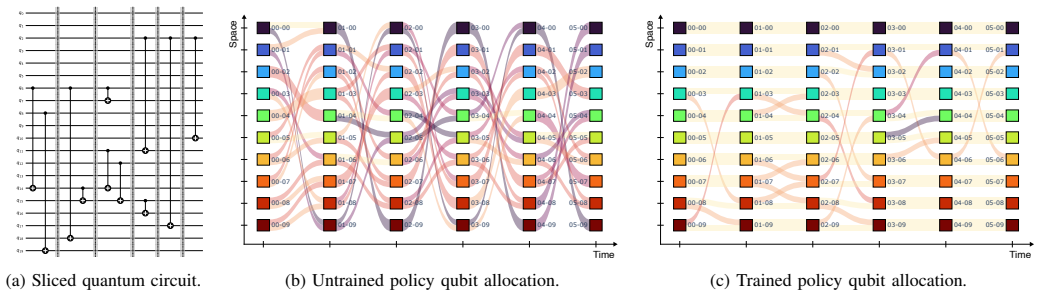

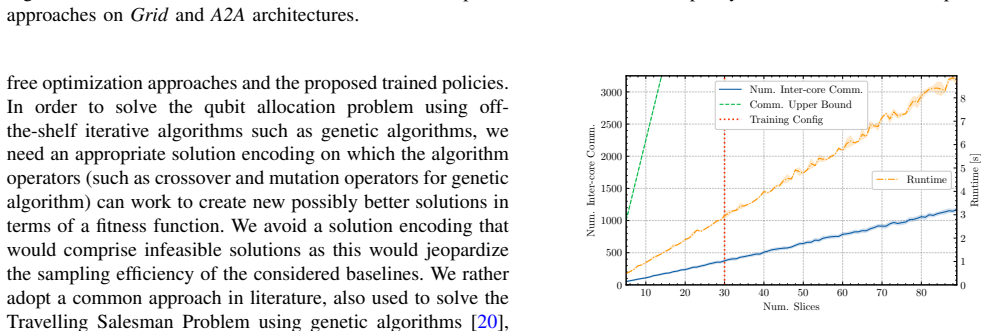
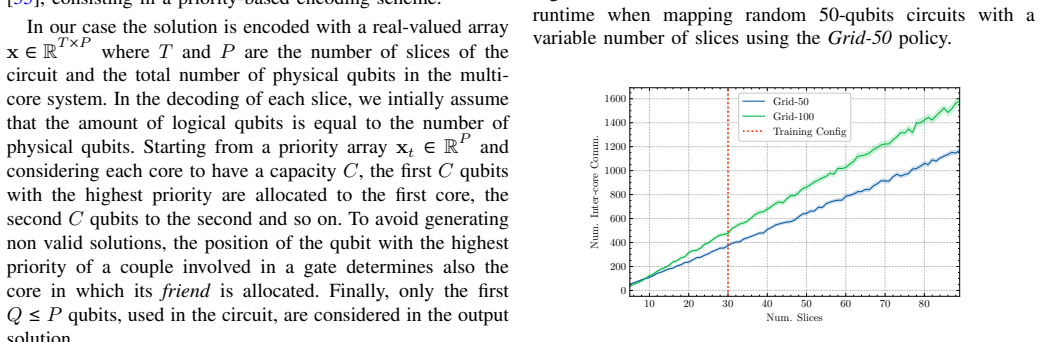

read the original abstract
Modular, distributed and multi-core architectures are currently considered a promising approach for scalability of quantum computing systems. The integration of multiple Quantum Processing Units necessitates classical and quantum-coherent communication, introducing challenges related to noise and quantum decoherence in quantum state transfers between cores. Optimizing communication becomes imperative, and the compilation and mapping of quantum circuits onto physical qubits must minimize state transfers while adhering to architectural constraints. The compilation process, inherently an NP-hard problem, demands extensive search times even with a small number of qubits to be solved to optimality. To address this challenge efficiently, we advocate for the utilization of heuristic mappers that can rapidly generate solutions. In this work, we propose a novel approach employing Deep Reinforcement Learning (DRL) methods to learn these heuristics for a specific multi-core architecture. Our DRL agent incorporates a Transformer encoder and Graph Neural Networks. It encodes quantum circuits using self-attention mechanisms and produce outputs through an attention-based pointer mechanism that directly signifies the probability of matching logical qubits with physical cores. This enables the selection of optimal cores for logical qubits efficiently. Experimental evaluations show that the proposed method can outperform baseline approaches in terms of reducing inter-core communications and minimizing online time-to-solution. This research contributes to the advancement of scalable quantum computing systems by introducing a novel learning-based heuristic approach for efficient quantum circuit compilation and mapping.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a deep reinforcement learning agent that combines a Transformer encoder with Graph Neural Networks and an attention-based pointer mechanism to map logical qubits to physical cores in a specific multi-core quantum architecture. The goal is to minimize inter-core communications while satisfying architectural constraints; the central claim is that this learned heuristic outperforms baseline mappers on inter-core communication reduction and online time-to-solution.
Significance. If the experimental outperformance holds under proper controls, the work supplies a practical learning-based heuristic for an NP-hard compilation subproblem that arises in modular quantum hardware. The explicit use of self-attention for circuit encoding and a pointer network for core selection is a technically coherent design choice that could be reproduced if code and circuit benchmarks are released.
major comments (2)
- [Abstract and §4] Abstract and §4 (experimental evaluations): the claim that the method 'can outperform baseline approaches' is load-bearing for the contribution, yet the manuscript provides no definition of the baseline mappers, no description of the circuit ensemble (gate counts, depth, entanglement structure), and no statistical test or variance reported across runs; without these, the outperformance cannot be verified.
- [§3 and §4] §3 (method) and §4: the DRL policy is trained on one fixed multi-core topology and one circuit distribution; the paper does not report results on circuits whose size, depth, or entanglement pattern lie outside the training distribution, nor on a different core connectivity, which directly undermines the claim that the approach yields useful mappings for practical modular systems.
minor comments (2)
- [§3] The notation for the attention-based pointer output (probability of matching logical qubits to cores) is introduced only descriptively; an explicit equation would improve clarity.
- Figure captions should state the exact number of training and test circuits and the precise metric (e.g., total inter-core swaps or communication volume) plotted on each axis.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, indicating revisions where appropriate to enhance clarity and verifiability while maintaining the scope of the presented work.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (experimental evaluations): the claim that the method 'can outperform baseline approaches' is load-bearing for the contribution, yet the manuscript provides no definition of the baseline mappers, no description of the circuit ensemble (gate counts, depth, entanglement structure), and no statistical test or variance reported across runs; without these, the outperformance cannot be verified.
Authors: We agree that explicit definitions of the baseline mappers, a detailed characterization of the circuit ensemble (including gate counts, depth, and entanglement structure), and reporting of variance across runs with appropriate statistical tests would strengthen the experimental section. We will revise §4 and the abstract to incorporate these elements in the next version of the manuscript. revision: yes
-
Referee: [§3 and §4] §3 (method) and §4: the DRL policy is trained on one fixed multi-core topology and one circuit distribution; the paper does not report results on circuits whose size, depth, or entanglement pattern lie outside the training distribution, nor on a different core connectivity, which directly undermines the claim that the approach yields useful mappings for practical modular systems.
Authors: The manuscript explicitly frames the contribution around a specific multi-core architecture and representative circuit distribution, as noted in the abstract and §3. We will revise the text to more clearly delineate this scope and avoid any implication of broad generalization. While additional experiments on out-of-distribution cases would be valuable, they fall outside the current study’s focus and would require substantial new computational effort. revision: partial
Circularity Check
No circularity; standard DRL training on external data
full rationale
The paper trains a Transformer+GNN DRL policy with attention pointer on circuit instances drawn from a training distribution for one fixed multi-core architecture, then reports experimental outperformance on inter-core communication and time-to-solution. No equation or claim reduces by construction to a fitted parameter renamed as prediction, no self-citation supplies a load-bearing uniqueness theorem, and no ansatz is smuggled via prior work. The derivation chain consists of standard RL training plus empirical evaluation and is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
CO-MAP: A Reinforcement Learning Approach to the Qubit Allocation Problem
Reinforcement learning policy for qubit mapping reduces SWAP overhead by 65-85% versus standard quantum compilers on MQTBench and Queko benchmark circuits.
-
Learning-Optimized Qubit Mapping and Reuse to Minimize Inter-Core Communication in Modular Quantum Architectures
QARMA applies transformer-augmented reinforcement learning to qubit allocation and reuse in modular quantum systems, reporting up to 86% average reduction in inter-core communications versus optimized Qiskit baselines.
-
TeleSABRE: Layout Synthesis in Multi-Core Quantum Systems with Teleport Interconnect
TeleSABRE extends SABRE to combine intra-core SWAPs with inter-core teleportation, reporting a 28% reduction in inter-core operations on benchmarks for multi-core quantum architectures.
Reference graph
Works this paper leans on
-
[1]
Aaronson, Quantum computing since Democritus
S. Aaronson, Quantum computing since Democritus . Cambridge University Press, 2013
work page 2013
-
[2]
Ketgpt–dataset aug- mentation of quantum circuits using transformers,
B. Apak, M. Bandic, A. Sarkar, and S. Feld, “Ketgpt–dataset aug- mentation of quantum circuits using transformers,” arXiv preprint arXiv:2402.13352, 2024
-
[3]
Quantum supremacy using a programmable superconducting processor,
F. Arute, K. Arya, R. Babbush, D. Bacon, J. C. Bardin, R. Barends, R. Biswas, S. Boixo, F. G. Brandao, D. A. Buell et al. , “Quantum supremacy using a programmable superconducting processor,” Nature, vol. 574, no. 7779, pp. 505–510, 2019
work page 2019
-
[4]
Time-sliced quantum circuit partitioning for modular architectures,
J. M. Baker, C. Duckering, A. Hoover, and F. T. Chong, “Time-sliced quantum circuit partitioning for modular architectures,” in Proceedings of the 17th ACM International Conference on Computing Frontiers , 2020, pp. 98–107
work page 2020
-
[5]
Mapping quantum circuits to modular architectures with qubo,
M. Bandic, L. Prielinger, J. N ¨ußlein, A. Ovide, S. Rodrigo, S. Abadal, H. van Someren, G. Vardoyan, E. Alarcon, C. G. Almudever et al. , “Mapping quantum circuits to modular architectures with qubo,” in 2023 IEEE International Conference on Quantum Computing and Engineer- ing (QCE) , vol. 1. IEEE, 2023, pp. 790–801
work page 2023
-
[6]
Elementary gates for quantum computation,
A. Barenco, C. H. Bennett, R. Cleve, D. P. DiVincenzo, N. Margolus, P. Shor, T. Sleator, J. A. Smolin, and H. Weinfurter, “Elementary gates for quantum computation,” Physical review A , vol. 52, no. 5, p. 3457, 1995
work page 1995
-
[7]
Neural Combinatorial Optimization with Reinforcement Learning
I. Bello, H. Pham, Q. V . Le, M. Norouzi, and S. Bengio, “Neural combinatorial optimization with reinforcement learning,” arXiv preprint arXiv:1611.09940, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
RL4CO: a unified reinforcement learning for combinatorial optimization library,
F. Berto, C. Hua, J. Park, M. Kim, H. Kim, J. Son, H. Kim, J. Kim, and J. Park, “RL4CO: a unified reinforcement learning for combinatorial optimization library,” in NeurIPS 2023 Workshop: New Frontiers in Graph Learning , 2023, https://github.com/ai4co/rl4co
work page 2023
-
[9]
Complexity of token swap- ping and its variants,
´E. Bonnet, T. Miltzow, and P. Rzazewski, “Complexity of token swap- ping and its variants,” Algorithmica, vol. 80, pp. 2656–2682, 2018
work page 2018
-
[10]
On the complexity of quan- tum circuit compilation,
A. Botea, A. Kishimoto, and R. Marinescu, “On the complexity of quan- tum circuit compilation,” in Proceedings of the International Symposium on Combinatorial Search , vol. 9, no. 1, 2018, pp. 138–142
work page 2018
-
[11]
Attention-based deep reinforcement learning for edge user allocation,
J. Chang, J. Wang, B. Li, Y . Zhao, and D. Li, “Attention-based deep reinforcement learning for edge user allocation,” IEEE Transactions on Network and Service Management , 2023
work page 2023
-
[12]
E. Charbon, M. Babaie, A. Vladimirescu, and F. Sebastiano, “Cryogenic cmos circuits and systems: Challenges and opportunities in designing the electronic interface for quantum processors,” IEEE Microwave Magazine, vol. 22, no. 1, pp. 60–78, 2020
work page 2020
-
[13]
Decision transformer: Reinforcement learning via sequence modeling,
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch, “Decision transformer: Reinforcement learning via sequence modeling,” Advances in neural information pro- cessing systems , vol. 34, pp. 15 084–15 097, 2021
work page 2021
-
[14]
R. Chen, W. Li, and H. Yang, “A deep reinforcement learning framework based on an attention mechanism and disjunctive graph embedding for the job-shop scheduling problem,” IEEE Transactions on Industrial Informatics, vol. 19, no. 2, pp. 1322–1331, 2022
work page 2022
-
[15]
Optimized compiler for distributed quantum computing,
D. Cuomo, M. Caleffi, K. Krsulich, F. Tramonto, G. Agliardi, E. Prati, and A. S. Cacciapuoti, “Optimized compiler for distributed quantum computing,” ACM Transactions on Quantum Computing , vol. 4, no. 2, pp. 1–29, 2023
work page 2023
-
[16]
On the analysis of the (1+ 1) evolutionary algorithm,
S. Droste, T. Jansen, and I. Wegener, “On the analysis of the (1+ 1) evolutionary algorithm,” Theoretical Computer Science , vol. 276, no. 1-2, pp. 51–81, 2002
work page 2002
-
[17]
Hungarian qubit assignment for optimized mapping of quantum circuits on multi-core architectures,
P. Escofet, A. Ovide, C. G. Almudever, E. Alarc ´on, and S. Abadal, “Hungarian qubit assignment for optimized mapping of quantum circuits on multi-core architectures,” IEEE Computer Architecture Letters , 2023
work page 2023
-
[18]
Revisiting the mapping of quantum circuits: Entering the multi-core era,
P. Escofet, A. Ovide, M. Bandic, L. Prielinger, H. van Someren, S. Feld, E. Alarc ´on, S. Abadal, and C. G. Almud ´ever, “Revisiting the mapping of quantum circuits: Entering the multi-core era,” ACM Transactions on Quantum Computing , 2024
work page 2024
-
[19]
Fast graph representation learning with PyTorch Geometric,
M. Fey and J. E. Lenssen, “Fast graph representation learning with PyTorch Geometric,” in ICLR Workshop on Representation Learning on Graphs and Manifolds , 2019
work page 2019
-
[20]
Genetic algorithms for solving shortest path problems,
M. Gen, R. Cheng, and D. Wang, “Genetic algorithms for solving shortest path problems,” in Proceedings of 1997 IEEE International Conference on Evolutionary Computation (ICEC’97) . IEEE, 1997, pp. 401–406
work page 1997
-
[21]
A tutorial on optimal control and reinforcement learning methods for quantum technologies,
L. Giannelli, P. Sgroi, J. Brown, G. S. Paraoanu, M. Paternostro, E. Pal- adino, and G. Falci, “A tutorial on optimal control and reinforcement learning methods for quantum technologies,” Physics Letters A, vol. 434, p. 128054, 2022
work page 2022
-
[22]
A fast quantum mechanical algorithm for database search,
L. K. Grover, “A fast quantum mechanical algorithm for database search,” in Proceedings of the twenty-eighth annual ACM symposium on Theory of computing , 1996, pp. 212–219
work page 1996
-
[23]
Gurobi Optimizer Reference Manual,
Gurobi Optimization, LLC, “Gurobi Optimizer Reference Manual,”
- [24]
-
[25]
The compact genetic algorithm,
G. R. Harik, F. G. Lobo, and D. E. Goldberg, “The compact genetic algorithm,” IEEE transactions on evolutionary computation , vol. 3, no. 4, pp. 287–297, 1999
work page 1999
-
[26]
H. Jnane, B. Undseth, Z. Cai, S. C. Benjamin, and B. Koczor, “Multicore quantum computing,” Physical Review Applied, vol. 18, no. 4, p. 044064, 2022
work page 2022
-
[27]
Devformer: A sym- metric transformer for context-aware device placement,
H. Kim, M. Kim, F. Berto, J. Kim, and J. Park, “Devformer: A sym- metric transformer for context-aware device placement,” in International Conference on Machine Learning . PMLR, 2023, pp. 16 541–16 566
work page 2023
-
[28]
Semi-Supervised Classification with Graph Convolutional Networks
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” arXiv preprint arXiv:1609.02907 , 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[29]
Attention, Learn to Solve Routing Problems!
W. Kool, H. Van Hoof, and M. Welling, “Attention, learn to solve routing problems!” arXiv preprint arXiv:1803.08475 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
Tackling the qubit mapping problem for nisq-era quantum devices,
G. Li, Y . Ding, and Y . Xie, “Tackling the qubit mapping problem for nisq-era quantum devices,” in Proceedings of the Twenty-F ourth International Conference on Architectural Support for Programming Languages and Operating Systems , 2019, pp. 1001–1014
work page 2019
-
[31]
A survey on trans- formers in reinforcement learning,
W. Li, H. Luo, Z. Lin, C. Zhang, Z. Lu, and D. Ye, “A survey on trans- formers in reinforcement learning,” arXiv preprint arXiv:2301.03044 , 2023
-
[32]
Scalable optimal layout synthesis for nisq quantum processors,
W.-H. Lin, J. Kimko, B. Tan, N. Bjørner, and J. Cong, “Scalable optimal layout synthesis for nisq quantum processors,” in 2023 60th ACM/IEEE Design Automation Conference (DAC) . IEEE, 2023, pp. 1–6
work page 2023
-
[33]
Quantum algorithms: an overview,
A. Montanaro, “Quantum algorithms: an overview,” npj Quantum Infor- mation, vol. 2, no. 1, pp. 1–8, 2016
work page 2016
-
[34]
Optimal qubit assignment and routing via integer programming,
G. Nannicini, L. S. Bishop, O. G ¨unl¨uk, and P. Jurcevic, “Optimal qubit assignment and routing via integer programming,” ACM Transactions on Quantum Computing , vol. 4, no. 1, pp. 1–31, 2022
work page 2022
-
[35]
M. A. Nielsen and I. L. Chuang, Quantum computation and quantum information. Cambridge university press, 2010
work page 2010
-
[36]
R. J. Nowling and H. Mauch, “Priority encoding scheme for solving per- mutation and constraint problems with genetic algorithms and simulated annealing,” in 2011 Eighth International Conference on Information Technology: New Generations . IEEE, 2011, pp. 810–815
work page 2011
-
[37]
Mapping quantum algorithms to multi-core quantum computing architectures,
A. Ovide, S. Rodrigo, M. Bandic, H. Van Someren, S. Feld, S. Abadal, E. Alarcon, and C. G. Almudever, “Mapping quantum algorithms to multi-core quantum computing architectures,” in 2023 IEEE Interna- tional Symposium on Circuits and Systems (ISCAS) , 2023, pp. 1–5
work page 2023
-
[38]
Algorithms for partitioning a graph,
T. Park and C. Y . Lee, “Algorithms for partitioning a graph,” Computers & Industrial Engineering , vol. 28, no. 4, pp. 899–909, 1995
work page 1995
-
[39]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga et al. , “Pytorch: An imperative style, high-performance deep learning library,” Advances in neural information processing systems , vol. 32, 2019
work page 2019
-
[40]
Qiskit: An open-source framework for quantum computing,
Qiskit contributors, “Qiskit: An open-source framework for quantum computing,” 2023
work page 2023
-
[41]
Mqt bench: Benchmarking software and design automation tools for quantum computing,
N. Quetschlich, L. Burgholzer, and R. Wille, “Mqt bench: Benchmarking software and design automation tools for quantum computing,” Quan- tum, vol. 7, p. 1062, 2023
work page 2023
-
[42]
S. Rodrigo, S. Abadal, C. G. Almud ´ever, and E. Alarc ´on, “Mod- elling short-range quantum teleportation for scalable multi-core quantum 12 computing architectures,” in Proceedings of the Eight Annual ACM International Conference on Nanoscale Computing and Communication , 2021, pp. 1–7
work page 2021
-
[43]
Detecting crosstalk errors in quantum information processors,
M. Sarovar, T. Proctor, K. Rudinger, K. Young, E. Nielsen, and R. Blume-Kohout, “Detecting crosstalk errors in quantum information processors,” Quantum, vol. 4, p. 321, 2020
work page 2020
-
[44]
Self-Attention with Relative Position Representations
P. Shaw, J. Uszkoreit, and A. Vaswani, “Self-attention with relative position representations,” arXiv preprint arXiv:1803.02155 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[45]
Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer,
P. W. Shor, “Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer,”SIAM review, vol. 41, no. 2, pp. 303–332, 1999
work page 1999
-
[46]
M. Y . Siraichi, V . F. d. Santos, C. Collange, and F. M. Q. Pereira, “Qubit allocation,” in Proceedings of the 2018 International Symposium on Code Generation and Optimization , 2018, pp. 113–125
work page 2018
-
[47]
Scaling super- conducting quantum computers with chiplet architectures,
K. N. Smith, G. S. Ravi, J. M. Baker, and F. T. Chong, “Scaling super- conducting quantum computers with chiplet architectures,” in 2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO) . IEEE, 2022, pp. 1092–1109
work page 2022
-
[48]
R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction . MIT press, 2018
work page 2018
-
[49]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems , vol. 30, 2017
work page 2017
-
[50]
Order Matters: Sequence to sequence for sets
O. Vinyals, S. Bengio, and M. Kudlur, “Order matters: Sequence to sequence for sets,” arXiv preprint arXiv:1511.06391 , 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[51]
O. Vinyals, M. Fortunato, and N. Jaitly, “Pointer networks,” Advances in neural information processing systems , vol. 28, 2015
work page 2015
-
[52]
Deep reinforcement learning: a survey,
H.-n. Wang, N. Liu, Y .-y. Zhang, D.-w. Feng, F. Huang, D.-s. Li, and Y .-m. Zhang, “Deep reinforcement learning: a survey,” Frontiers of Information Technology & Electronic Engineering , vol. 21, no. 12, pp. 1726–1744, 2020
work page 2020
-
[53]
Simple statistical gradient-following algorithms for connectionist reinforcement learning,
R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,” Machine learning , vol. 8, pp. 229–256, 1992
work page 1992
-
[54]
Compilation for quantum computing on chiplets,
H. Zhang, K. Yin, A. Wu, H. Shapourian, A. Shabani, and Y . Ding, “Compilation for quantum computing on chiplets,” arXiv preprint arXiv:2305.05149, 2023. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.