WildFeedback: Aligning LLMs With In-situ User Interactions And Feedback
Pith reviewed 2026-05-23 22:36 UTC · model grok-4.3
The pith
WildFeedback creates LLM alignment datasets from real user feedback in conversations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WildFeedback leverages in-situ user feedback during conversations with LLMs to create preference datasets automatically. Given a corpus of multi-turn user-LLM conversation, it identifies and classifies user feedback to LLM responses between conversation turns to create examples of preferred and dispreferred responses according to users' preference. Experiments demonstrate that LLMs fine-tuned on the WildFeedback dataset exhibit significantly improved alignment with user preferences on traditional benchmarks and the proposed checklist-guided evaluation.
What carries the argument
WildFeedback, the framework that extracts and classifies in-situ user feedback from conversation turns to form preference pairs for dataset creation.
If this is right
- Fine-tuned models show improved performance on traditional alignment benchmarks.
- They also perform better under the checklist-guided evaluation.
- The method provides a scalable alternative to manual preference annotation.
- It helps avoid feedback loops that amplify model biases.
Where Pith is reading between the lines
- This could enable real-time preference updating as new conversations occur.
- Testing on diverse user populations would reveal if the extracted preferences are broadly representative.
- Integration with other alignment techniques might yield hybrid systems with even stronger results.
Load-bearing premise
User feedback in natural conversations can be reliably identified and classified into preferred versus dispreferred responses without introducing substantial noise or selection bias from the conversation corpus.
What would settle it
If applying the classification step to a held-out set of conversations produces labels that human reviewers disagree with at high rates, or if models trained on the data fail to show alignment gains in direct user tests.
Figures


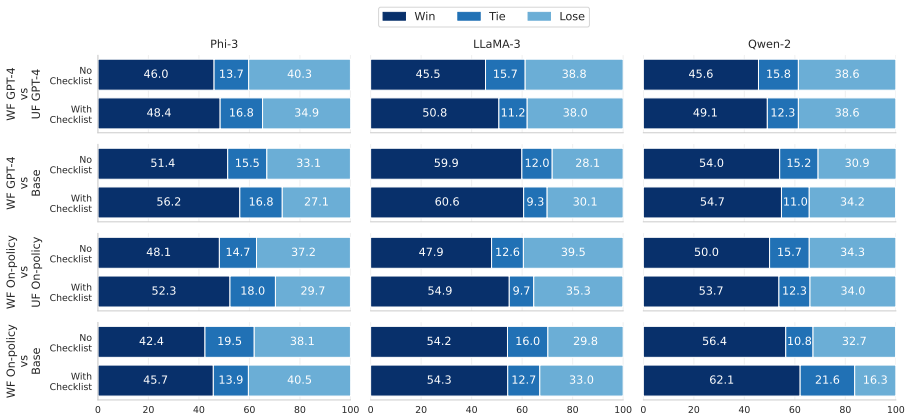


read the original abstract
As large language models (LLMs) continue to advance, aligning these models with human preferences has emerged as a critical challenge. Traditional alignment methods, relying on human or LLM annotated datasets, are limited by their resource-intensive nature, inherent subjectivity, misalignment with real-world user preferences, and the risk of feedback loops that amplify model biases. To overcome these limitations, we introduce WildFeedback, a novel framework that leverages in-situ user feedback during conversations with LLMs to create preference datasets automatically. Given a corpus of multi-turn user-LLM conversation, WildFeedback identifies and classifies user feedback to LLM responses between conversation turns. The user feedback is then used to create examples of preferred and dispreferred responses according to users' preference. Our experiments demonstrate that LLMs fine-tuned on WildFeedback dataset exhibit significantly improved alignment with user preferences, as evidenced by both traditional benchmarks and our proposed checklist-guided evaluation. By incorporating in-situ feedback from actual users, WildFeedback addresses the scalability, subjectivity, and bias challenges that plague existing approaches, marking a significant step toward developing LLMs that are more responsive to the diverse and evolving needs of their users.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WildFeedback, a framework that automatically constructs preference datasets from in-situ user feedback in multi-turn LLM conversations. It identifies and classifies user feedback between turns to generate preferred and dispreferred response pairs, then shows that fine-tuning LLMs on the resulting dataset yields significantly improved alignment with user preferences on both standard benchmarks and a proposed checklist-guided evaluation.
Significance. If the automated extraction produces low-noise preference data, the approach could scale alignment data collection while reducing reliance on expensive human annotation and synthetic feedback, directly incorporating real user signals.
major comments (2)
- [Abstract and experimental results section] Abstract and experimental results section: the claim of 'significantly improved alignment' is asserted without reporting dataset size, feedback classification accuracy, baseline comparisons, statistical significance tests, or error propagation from misclassified feedback; these details are required to evaluate whether observed gains reflect genuine preference signals.
- [Method description (likely §3)] Method description (likely §3): no quantitative validation (e.g., precision/recall, inter-annotator agreement, or ablation on extraction error rates) is provided for the rule-based or LLM-based classifier that turns raw multi-turn logs into preferred/dispreferred pairs; because natural feedback is often implicit or multi-intent, this verification is load-bearing for the central claim that the dataset captures authentic user preferences.
minor comments (1)
- The abstract would be strengthened by including at least one concrete quantitative result (e.g., win-rate delta or benchmark score).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in reporting and validation. We will revise the manuscript to incorporate the suggested details and quantitative analyses.
read point-by-point responses
-
Referee: [Abstract and experimental results section] Abstract and experimental results section: the claim of 'significantly improved alignment' is asserted without reporting dataset size, feedback classification accuracy, baseline comparisons, statistical significance tests, or error propagation from misclassified feedback; these details are required to evaluate whether observed gains reflect genuine preference signals.
Authors: We agree that the abstract and results sections require additional quantitative context to substantiate the alignment improvements. In the revised version, we will explicitly report the WildFeedback dataset size, the accuracy of the feedback classification step (obtained via manual annotation on a held-out sample), direct comparisons against relevant baselines, results of statistical significance tests on the benchmark gains, and a brief error-propagation analysis estimating the impact of potential misclassifications on downstream performance. These additions will allow readers to better assess the strength of the preference signals. revision: yes
-
Referee: [Method description (likely §3)] Method description (likely §3): no quantitative validation (e.g., precision/recall, inter-annotator agreement, or ablation on extraction error rates) is provided for the rule-based or LLM-based classifier that turns raw multi-turn logs into preferred/dispreferred pairs; because natural feedback is often implicit or multi-intent, this verification is load-bearing for the central claim that the dataset captures authentic user preferences.
Authors: We concur that rigorous validation of the feedback identification and classification component is essential, particularly given the challenges of implicit or multi-intent user feedback. Although the original manuscript describes the classification rules and LLM-assisted procedure, it does not include the requested quantitative metrics. In the revision, we will add a new subsection under Methods that reports precision/recall on a manually annotated validation set, inter-annotator agreement statistics, and an ablation examining how varying extraction error rates affect the quality of the resulting preference pairs. This will directly address concerns about the fidelity of the automatically constructed dataset. revision: yes
Circularity Check
No circularity: procedural data construction with independent evaluation
full rationale
The paper describes a procedural pipeline for extracting preference pairs from raw conversation logs and fine-tuning LLMs, followed by benchmark evaluation. No equations, fitted parameters, or derivations are present. No self-citation is invoked as a load-bearing uniqueness theorem or ansatz. The central claim (improved alignment after fine-tuning on the constructed dataset) rests on external benchmarks and a proposed checklist, not on any reduction to the extraction rules themselves. This is a standard empirical workflow with no self-referential collapse.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Co-Constructing Alignment: A Participatory Approach to Situate AI Values
Misalignments appear in practice as unexpected responses and task breakdowns, with users proposing roles such as adjusting model output, interpreting behavior, or deliberate non-use to co-construct alignment.
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, Sébastien Bubeck, Qin Cai, Martin Cai, Caio César Teodoro Mendes, Weizhu Chen, Vishrav Chaudhary, Dong Chen, Dongdong Chen, Yen-Chun Chen, Yi-Ling Chen...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
The claude 3 model family: Opus, sonnet, haiku, 2023
Anthropic. The claude 3 model family: Opus, sonnet, haiku, 2023. URL https://api.semanticscholar.org/CorpusID:268232499
work page 2023
-
[3]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, K...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Collin Burns, Pavel Izmailov, Jan Hendrik Kirchner, Bowen Baker, Leo Gao, Leopold Aschenbrenner, Yining Chen, Adrien Ecoffet, Manas Joglekar, Jan Leike, Ilya Sutskever, and Jeff Wu. Weak-to-strong generalization: Eliciting strong capabilities with weak supervision, 2023. URL https://arxiv.org/abs/2312.09390
-
[6]
Scaling Instruction-Finetuned Language Models
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping H...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
ULTRAFEEDBACK : Boosting language models with scaled AI feedback
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, Zhiyuan Liu, and Maosong Sun. ULTRAFEEDBACK : Boosting language models with scaled AI feedback. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp (eds.), Proceeding...
work page 2024
-
[8]
S3-dst: Structured open-domain dialogue segmentation and state tracking in the era of llms, 2023
Sarkar Snigdha Sarathi Das, Chirag Shah, Mengting Wan, Jennifer Neville, Longqi Yang, Reid Andersen, Georg Buscher, and Tara Safavi. S3-dst: Structured open-domain dialogue segmentation and state tracking in the era of llms, 2023. URL https://arxiv.org/abs/2309.08827
-
[9]
Learning from naturally occurring feedback, 2024
Shachar Don-Yehiya, Leshem Choshen, and Omri Abend. Learning from naturally occurring feedback, 2024. URL https://arxiv.org/abs/2407.10944
-
[10]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. The faiss library, 2024
work page 2024
-
[11]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava Spataru, Baptiste Roziere, Bethany...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B. Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators, 2024. URL https://arxiv.org/abs/2404.04475
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Beavertails: Towards improved safety alignment of llm via a human-preference dataset, 2023
Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Chi Zhang, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. Beavertails: Towards improved safety alignment of llm via a human-preference dataset, 2023. URL https://arxiv.org/abs/2307.04657
-
[14]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023. URL https://arxi...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
o pf, Yannic Kilcher, Dimitri von R \
Andreas K \"o pf, Yannic Kilcher, Dimitri von R \"u tte, Sotiris Anagnostidis, Zhi Rui Tam, Keith Stevens, Abdullah Barhoum, Duc Minh Nguyen, Oliver Stanley, Rich \'a rd Nagyfi, Shahul ES, Sameer Suri, David Alexandrovich Glushkov, Arnav Varma Dantuluri, Andrew Maguire, Christoph Schuhmann, Huu Nguyen, and Alexander Julian Mattick. Openassistant conversat...
work page 2023
-
[16]
RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, and Sushant Prakash. Rlaif: Scaling reinforcement learning from human feedback with ai feedback, 2023. URL https://arxiv.org/abs/2309.00267
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Minzhi Li, Taiwei Shi, Caleb Ziems, Min-Yen Kan, Nancy Chen, Zhengyuan Liu, and Diyi Yang. C o A nnotating: Uncertainty-guided work allocation between human and large language models for data annotation. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 1487--1...
-
[18]
From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline, 2024. URL https://arxiv.org/abs/2406.11939
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [19]
-
[20]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step, 2023. URL https://arxiv.org/abs/2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Wildbench: Benchmarking llms with challenging tasks from real users in the wild, 2024 a
Bill Yuchen Lin, Yuntian Deng, Khyathi Chandu, Faeze Brahman, Abhilasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, and Yejin Choi. Wildbench: Benchmarking llms with challenging tasks from real users in the wild, 2024 a . URL https://arxiv.org/abs/2406.04770
-
[22]
Ying-Chun Lin, Jennifer Neville, Jack W. Stokes, Longqi Yang, Tara Safavi, Mengting Wan, Scott Counts, Siddharth Suri, Reid Andersen, Xiaofeng Xu, Deepak Gupta, Sujay Kumar Jauhar, Xia Song, Georg Buscher, Saurabh Tiwary, Brent Hecht, and Jaime Teevan. Interpretable user satisfaction estimation for conversational systems with large language models, 2024 b...
-
[23]
Jie Liu, Zhanhui Zhou, Jiaheng Liu, Xingyuan Bu, Chao Yang, Han-Sen Zhong, and Wanli Ouyang. Iterative length-regularized direct preference optimization: A case study on improving 7b language models to gpt-4 level, 2024 a . URL https://arxiv.org/abs/2406.11817
-
[24]
Llms as narcissistic evaluators: When ego inflates evaluation scores, 2024 b
Yiqi Liu, Nafise Sadat Moosavi, and Chenghua Lin. Llms as narcissistic evaluators: When ego inflates evaluation scores, 2024 b . URL https://arxiv.org/abs/2311.09766
-
[25]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback, 2023. URL https://arxiv.org/abs/2303.17651
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. Webgpt: Browser-assisted question-answering with human feedback, 2022. URL https://a...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Reuse, don't retrain: A recipe for continued pretraining of language models, 2024
Jupinder Parmar, Sanjev Satheesh, Mostofa Patwary, Mohammad Shoeybi, and Bryan Catanzaro. Reuse, don't retrain: A recipe for continued pretraining of language models, 2024. URL https://arxiv.org/abs/2407.07263
-
[30]
Potato: The portable text annotation tool
Jiaxin Pei, Aparna Ananthasubramaniam, Xingyao Wang, Naitian Zhou, Apostolos Dedeloudis, Jackson Sargent, and David Jurgens. Potato: The portable text annotation tool. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2022
work page 2022
-
[31]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=HPuSIXJaa9
work page 2023
-
[32]
Safer-instruct: Aligning language models with automated preference data
Taiwei Shi, Kai Chen, and Jieyu Zhao. Safer-instruct: Aligning language models with automated preference data. In Kevin Duh, Helena Gomez, and Steven Bethard (eds.), Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp.\ 7636--7651, Mexico...
-
[33]
Weiyan Shi, Emily Dinan, Kurt Shuster, Jason Weston, and Jing Xu. When life gives you lemons, make cherryade: Converting feedback from bad responses into good labels, 2022. URL https://arxiv.org/abs/2210.15893
-
[34]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, Johan Ferret, Peter Liu, Pouya Tafti, Abe Friesen, Michelle Casbon, Sabela Ramos, Ravin Kumar, Charline Le Lan, Sammy Jerome, Anton Tsitsulin, Nino Vieillard, Piotr Stanczyk, Sertan Girgin, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Aman Singh Thakur, Kartik Choudhary, Venkat Srinik Ramayapally, Sankaran Vaidyanathan, and Dieuwke Hupkes. Judging the judges: Evaluating alignment and vulnerabilities in llms-as-judges, 2024. URL https://arxiv.org/abs/2406.12624
-
[36]
Zephyr: Direct Distillation of LM Alignment
Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, Nathan Sarrazin, Omar Sanseviero, Alexander M. Rush, and Thomas Wolf. Zephyr: Direct distillation of lm alignment, 2023. URL https://arxiv.org/abs/2310.16944
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Super- N atural I nstructions: Generalization via declarative instructions on 1600+ NLP tasks
Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Atharva Naik, Arjun Ashok, Arut Selvan Dhanasekaran, Anjana Arunkumar, David Stap, Eshaan Pathak, Giannis Karamanolakis, Haizhi Lai, Ishan Purohit, Ishani Mondal, Jacob Anderson, Kirby Kuznia, Krima Doshi, Kuntal Kumar Pal, Maitreya Patel, Mehrad Moradshahi, Mihir Parma...
-
[38]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pap...
-
[39]
Recursively Summarizing Books with Human Feedback
Jeff Wu, Long Ouyang, Daniel M. Ziegler, Nisan Stiennon, Ryan Lowe, Jan Leike, and Paul Christiano. Recursively summarizing books with human feedback, 2021. URL https://arxiv.org/abs/2109.10862
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[40]
WizardLM: Empowering large pre-trained language models to follow complex instructions
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. Wizardlm: Empowering large language models to follow complex instructions, 2023. URL https://arxiv.org/abs/2304.12244
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
WildChat: 1M ChatGPT Interaction Logs in the Wild
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. Wildchat: 1m chatgpt interaction logs in the wild, 2024. URL https://arxiv.org/abs/2405.01470
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Advances in Neural Information Processing Syst...
work page 2023
-
[43]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023 b . URL https://arxiv.org/abs/2306.05685
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. Llamafactory: Unified efficient fine-tuning of 100+ language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Bangkok, Thailand, 2024. Association for Computational Linguist...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[46]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[47]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[48]
a]ԯ+ Z-Z / ^2:N Psf-:S f+ ꩀk N|&cj_Sɟzc3JVv @v ֥ IFf 3*,+YZ[s UZ zNxy q^M1@ JUp [ V3czvP#f
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.