ENTER: Event Based Interpretable Reasoning for VideoQA
Pith reviewed 2026-05-23 04:57 UTC · model grok-4.3
The pith
ENTER turns videos into event graphs to generate code for interpretable VideoQA reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
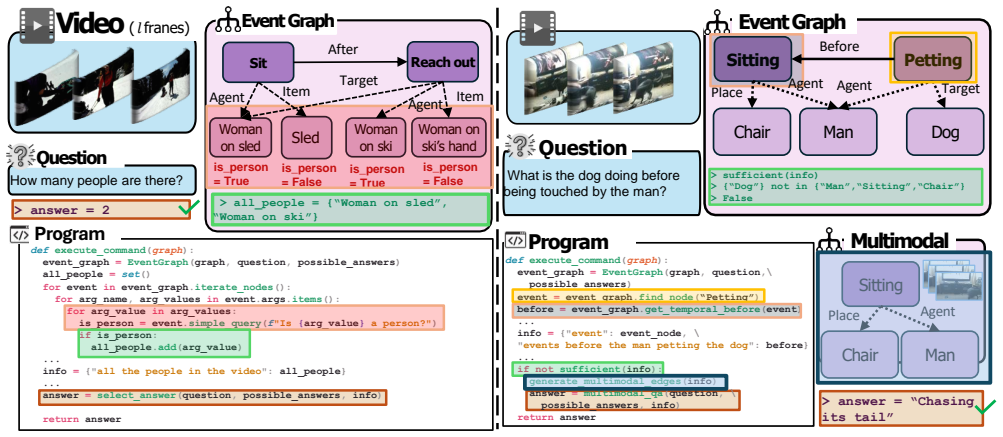
ENTER converts videos into event graphs, where video events form nodes and event-event relationships form edges, then generates code that parses the event graph to produce answers, enabling interpretable reasoning that includes contextual visual information and uses hierarchical iterative updates for robustness.
What carries the argument
Event graphs, with video events as nodes and temporal, causal, or hierarchical relationships as edges, parsed via generated code for reasoning.
If this is right
- Provides interpretable VideoQA by generating code that parses the event graph.
- Incorporates contextual visual information from event graphs into the reasoning process.
- Achieves robustness through hierarchical iterative update of the event graphs.
- Outperforms top-down approaches on NExT-QA, IntentQA, and EgoSchema while being competitive with bottom-up methods.
- Offers superior interpretability and explainability compared to existing systems.
Where Pith is reading between the lines
- Event graphs could potentially be used to improve reasoning in other multimodal tasks involving temporal data.
- If event extraction is accurate, this method might reduce errors in long video sequences by focusing on structured relationships.
- The code generation step might allow for easy debugging of incorrect answers by inspecting the parsed graph.
Load-bearing premise
Event graphs can be reliably extracted from raw video to capture low-level visual information, and the generated code can incorporate that context without losing accuracy or requiring post-hoc adjustments.
What would settle it
A test where event graph extraction misses critical events or relationships, leading to incorrect or non-interpretable answers on VideoQA benchmarks.
Figures








read the original abstract
In this paper, we present ENTER, an interpretable Video Question Answering (VideoQA) system based on event graphs. Event graphs convert videos into graphical representations, where video events form the nodes and event-event relationships (temporal/causal/hierarchical) form the edges. This structured representation offers many benefits: 1) Interpretable VideoQA via generated code that parses event-graph; 2) Incorporation of contextual visual information in the reasoning process (code generation) via event graphs; 3) Robust VideoQA via Hierarchical Iterative Update of the event graphs. Existing interpretable VideoQA systems are often top-down, disregarding low-level visual information in the reasoning plan generation, and are brittle. While bottom-up approaches produce responses from visual data, they lack interpretability. Experimental results on NExT-QA, IntentQA, and EgoSchema demonstrate that not only does our method outperform existing top-down approaches while obtaining competitive performance against bottom-up approaches, but more importantly, offers superior interpretability and explainability in the reasoning process.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ENTER, an interpretable VideoQA system that converts videos into event graphs (events as nodes, temporal/causal/hierarchical relations as edges). Reasoning proceeds via generated code that parses these graphs, incorporates low-level visual context during code generation, and applies hierarchical iterative updates for robustness. The work claims to outperform existing top-down interpretable methods while remaining competitive with bottom-up approaches, and to deliver superior interpretability and explainability, as demonstrated on NExT-QA, IntentQA, and EgoSchema.
Significance. If the event-graph extraction and code-generation pipeline reliably preserves low-level visual details without accuracy loss, the approach could meaningfully advance VideoQA by offering a structured, code-based reasoning path that is both more accurate than typical top-down systems and more interpretable than bottom-up ones. The emphasis on hierarchical updates and explicit graph parsing provides a concrete mechanism for explainability that could influence future work on grounded, verifiable video reasoning.
major comments (2)
- [Abstract] The central performance and interpretability claims rest on the assumption that event graphs extracted from raw video faithfully retain low-level visual information for use in the code-generation step (Abstract). No quantitative evaluation of extraction fidelity, information retention, or comparison against direct visual features is described, which directly affects whether the method can outperform top-down baselines without reverting to their limitations.
- [Abstract] The experimental results are said to demonstrate both accuracy gains and 'superior interpretability and explainability' on NExT-QA, IntentQA, and EgoSchema (Abstract). Without reported metrics for interpretability (e.g., human evaluation of code explanations, faithfulness scores, or ablation removing the event-graph input to code generation), it is not possible to verify that the interpretability advantage is load-bearing or supported by the data.
minor comments (1)
- [Abstract] The abstract lists three benefits of event graphs but does not indicate how the hierarchical iterative update mechanism is implemented or evaluated, which would help readers assess the robustness claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of our claims regarding event-graph fidelity and interpretability. We address each point below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] The central performance and interpretability claims rest on the assumption that event graphs extracted from raw video faithfully retain low-level visual information for use in the code-generation step (Abstract). No quantitative evaluation of extraction fidelity, information retention, or comparison against direct visual features is described, which directly affects whether the method can outperform top-down baselines without reverting to their limitations.
Authors: We agree that the abstract does not present a dedicated quantitative study of extraction fidelity. The full manuscript details the event-graph construction pipeline, which extracts events and relations while conditioning code generation on the resulting graph to incorporate visual context. Performance improvements over top-down baselines on three datasets provide indirect support for information retention. To directly address the concern, we will add an ablation comparing code-generation accuracy and downstream VideoQA performance when using event graphs versus raw visual features or no graph input. revision: yes
-
Referee: [Abstract] The experimental results are said to demonstrate both accuracy gains and 'superior interpretability and explainability' on NExT-QA, IntentQA, and EgoSchema (Abstract). Without reported metrics for interpretability (e.g., human evaluation of code explanations, faithfulness scores, or ablation removing the event-graph input to code generation), it is not possible to verify that the interpretability advantage is load-bearing or supported by the data.
Authors: The manuscript supports the interpretability claim through the explicit generation of parsing code over event graphs and qualitative examples of reasoning traces. We acknowledge that no human evaluation scores or faithfulness metrics are reported in the current version. We will add a human study evaluating explanation quality and faithfulness, along with an ablation that removes the event-graph input during code generation, to provide quantitative backing for the interpretability advantage. revision: yes
Circularity Check
No circularity: empirical performance claims rest on external benchmarks, not self-defined quantities or self-citation chains
full rationale
The paper presents ENTER as an event-graph-based VideoQA system whose central claims are empirical: it outperforms top-down methods and is competitive with bottom-up ones on NExT-QA, IntentQA, and EgoSchema while providing superior interpretability. No equations, fitted parameters, or derivation steps appear in the abstract or described text that reduce any prediction to an input by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked to justify the method. The performance and interpretability results are presented as outcomes of experiments on public datasets rather than tautological restatements of the event-graph construction itself. This is the normal case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
UpstreamQA: A Modular Framework for Explicit Reasoning on Video Question Answering Tasks
UpstreamQA disentangles video reasoning by using LRMs for explicit upstream object identification and scene context before downstream LMM VideoQA, improving performance and interpretability on OpenEQA and NExTQA in so...
Reference graph
Works this paper leans on
-
[1]
Jacob Andreas, Marcus Rohrbach, Trevor Darrell, and Dan Klein. Neural module networks, 2017. 2
work page 2017
-
[2]
Hiervl: Learning hierarchical video-language embeddings, 2023
Kumar Ashutosh, Rohit Girdhar, Lorenzo Torresani, and Kris- ten Grauman. Hiervl: Learning hierarchical video-language embeddings, 2023. 2
work page 2023
-
[3]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agar- wal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz L...
work page 2020
-
[4]
Grounded multi- hop videoqa in long-form egocentric videos, 2024
Qirui Chen, Shangzhe Di, and Weidi Xie. Grounded multi- hop videoqa in long-form egocentric videos, 2024. 2
work page 2024
-
[5]
Rohan Choudhury, Koichiro Niinuma, Kris M. Kitani, and László A. Jeni. Zero-shot video question answering with procedural programs, 2023. 3, 5, 6, 2
work page 2023
-
[6]
The llama 3 herd of models, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava Spataru, Baptiste Roziere, Betha...
work page 2024
-
[7]
Videoagent: A memory-augmented multi- modal agent for video understanding, 2024
Yue Fan, Xiaojian Ma, Rujie Wu, Yuntao Du, Jiaqi Li, Zhi Gao, and Qing Li. Videoagent: A memory-augmented multi- modal agent for video understanding, 2024. 2
work page 2024
-
[8]
Video-of-thought: Step-by-step video reasoning from perception to cognition
Hao Fei, Shengqiong Wu, Wei Ji, Hanwang Zhang, Meishan Zhang, Mong-Li Lee, and Wynne Hsu. Video-of-thought: Step-by-step video reasoning from perception to cognition. In Forty-first International Conference on Machine Learning,
-
[9]
Visual program- ming: Compositional visual reasoning without training, 2022
Tanmay Gupta and Aniruddha Kembhavi. Visual program- ming: Compositional visual reasoning without training, 2022. 2, 3
work page 2022
-
[10]
Free video-llm: Prompt-guided visual perception for efficient training-free video llms, 2024
Kai Han, Jianyuan Guo, Yehui Tang, Wei He, Enhua Wu, and Yunhe Wang. Free video-llm: Prompt-guided visual perception for efficient training-free video llms, 2024. 3
work page 2024
-
[11]
Video recap: Recursive captioning of hour-long videos, 2024
Md Mohaiminul Islam, Ngan Ho, Xitong Yang, Tushar Na- garajan, Lorenzo Torresani, and Gedas Bertasius. Video recap: Recursive captioning of hour-long videos, 2024. 2
work page 2024
-
[12]
Dohwan Ko, Ji Soo Lee, Wooyoung Kang, Byungseok Roh, and Hyunwoo J. Kim. Large language models are temporal and causal reasoners for video question answering, 2023. 3
work page 2023
-
[13]
Intentqa: Context-aware video intent reasoning
Jiapeng Li, Ping Wei, Wenjuan Han, and Lifeng Fan. Intentqa: Context-aware video intent reasoning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11963–11974, 2023. 5
work page 2023
-
[14]
Intentqa: Context-aware video intent reasoning
Jiapeng Li, Ping Wei, Wenjuan Han, and Lifeng Fan. Intentqa: Context-aware video intent reasoning. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 11963–11974, 2023. 2
work page 2023
-
[15]
Videochat: Chat-centric video understanding, 2024
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding, 2024. 2
work page 2024
-
[16]
Mvbench: A comprehensive multi-modal video understanding benchmark, 2024
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, and Yu Qiao. Mvbench: A comprehensive multi-modal video understanding benchmark, 2024. 5, 2
work page 2024
-
[17]
End-to-end video question answering with frame scoring mechanisms and adaptive sam- pling, 2024
Jianxin Liang, Xiaojun Meng, Yueqian Wang, Chang Liu, Qun Liu, and Dongyan Zhao. End-to-end video question answering with frame scoring mechanisms and adaptive sam- pling, 2024. 3
work page 2024
-
[18]
Ruotong Liao, Max Erler, Huiyu Wang, Guangyao Zhai, Gengyuan Zhang, Yunpu Ma, and V olker Tresp. VideoIN- STA: Zero-shot long video understanding via informative spatial-temporal reasoning with LLMs. In Findings of the Association for Computational Linguistics: EMNLP 2024 , pages 6577–6602, Miami, Florida, USA, 2024. Association for Computational Linguist...
work page 2024
-
[19]
Vx2text: End-to-end learning of video-based text generation from multimodal in- puts
Xudong Lin, Gedas Bertasius, Jue Wang, Shih-Fu Chang, Devi Parikh, and Lorenzo Torresani. Vx2text: End-to-end learning of video-based text generation from multimodal in- puts. In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 7005–7015, 2021. 2
work page 2021
-
[20]
Towards fast adaptation of pretrained contrastive models for multi-channel video-language retrieval
Xudong Lin, Simran Tiwari, Shiyuan Huang, Manling Li, Mike Zheng Shou, Heng Ji, and Shih-Fu Chang. Towards fast adaptation of pretrained contrastive models for multi-channel video-language retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 14846–14855, 2023. 2
work page 2023
-
[21]
Training-free deep concept injection enables lan- guage models for video question answering
Xudong Lin, Manling Li, Richard Zemel, Heng Ji, and Shih- Fu Chang. Training-free deep concept injection enables lan- guage models for video question answering. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 22399–22416, 2024
work page 2024
-
[22]
Hair: Hierarchical visual-semantic relational reasoning for video question answering
Fei Liu, Jing Liu, Weining Wang, and Hanqing Lu. Hair: Hierarchical visual-semantic relational reasoning for video question answering. In 2021 IEEE/CVF International Con- ference on Computer Vision (ICCV), pages 1678–1687, 2021. 2
work page 2021
-
[23]
Video-chatgpt: Towards detailed video understanding via large vision and language models, 2024
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models, 2024. 2
work page 2024
-
[24]
Egoschema: A diagnostic benchmark for very long- form video language understanding, 2023
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long- form video language understanding, 2023. 2, 5
work page 2023
-
[25]
Morevqa: Exploring modular reasoning models for video question answering
Juhong Min, Shyamal Buch, Arsha Nagrani, Minsu Cho, and Cordelia Schmid. Morevqa: Exploring modular reasoning models for video question answering. arxiv, 2024. 1, 2, 3, 5, 6
work page 2024
-
[26]
Question-instructed visual descriptions for zero-shot video answering
David Mogrovejo and Thamar Solorio. Question-instructed visual descriptions for zero-shot video answering. InFindings of the Association for Computational Linguistics: ACL 2024, pages 9329–9339, Bangkok, Thailand, 2024. Association for Computational Linguistics. 3
work page 2024
-
[27]
WonJun Moon, Sangeek Hyun, SuBeen Lee, and Jae-Pil Heo. Correlation-guided query-dependency calibration in video representation learning for temporal grounding. arXiv preprint arXiv:2311.08835, 2023. 5
-
[28]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anad- kat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Bal- com, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett- Shapiro, Christopher B...
work page 2024
-
[29]
Retrieving-to-answer: Zero-shot video question answering with frozen large lan- guage models, 2023
Junting Pan, Ziyi Lin, Yuying Ge, Xiatian Zhu, Renrui Zhang, Yi Wang, Yu Qiao, and Hongsheng Li. Retrieving-to-answer: Zero-shot video question answering with frozen large lan- guage models, 2023. 3
work page 2023
-
[30]
Jongwoo Park, Kanchana Ranasinghe, Kumara Kahatapitiya, Wonjeong Ryoo, Donghyun Kim, and Michael S. Ryoo. Too many frames, not all useful:efficient strategies for long-form video qa, 2024. 5, 6, 2
work page 2024
-
[31]
Micap: A unified model for identity- aware movie descriptions, 2024
Haran Raajesh, Naveen Reddy Desanur, Zeeshan Khan, and Makarand Tapaswi. Micap: A unified model for identity- aware movie descriptions, 2024. 3
work page 2024
-
[32]
Traveler: A modular multi-lmm agent framework for video question-answering, 2024
Chuyi Shang, Amos You, Sanjay Subramanian, Trevor Dar- rell, and Roei Herzig. Traveler: A modular multi-lmm agent framework for video question-answering, 2024. 3, 5, 6, 2
work page 2024
-
[33]
Kim, Bilge Soran, Raghuraman Krishnamoorthi, Mohamed Elhoseiny, and Vikas Chandra
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Bal- akrishnan Varadarajan, Florian Bordes, Zhuang Liu, Hu Xu, Hyunwoo J. Kim, Bilge Soran, Raghuraman Krishnamoorthi, Mohamed Elhoseiny, and Vikas Chandra. Longvu: Spa- tiotemporal adaptive compression for long video-language understanding, 2024. 3
work page 2024
-
[34]
Progprompt: Generating situated robot task plans using large language models, 2022
Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, and Animesh Garg. Progprompt: Generating situated robot task plans using large language models, 2022. 3
work page 2022
-
[35]
Moviechat: From dense token to sparse memory for long video understanding, 2024
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, Yan Lu, Jenq-Neng Hwang, and Gaoang Wang. Moviechat: From dense token to sparse memory for long video understanding, 2024. 1
work page 2024
-
[36]
Modular visual question answering via code generation, 2023
Sanjay Subramanian, Medhini Narasimhan, Kushal Khangaonkar, Kevin Yang, Arsha Nagrani, Cordelia Schmid, Andy Zeng, Trevor Darrell, and Dan Klein. Modular visual question answering via code generation, 2023. 2
work page 2023
-
[37]
Vipergpt: Visual inference via python execution for reasoning
Dídac Surís, Sachit Menon, and Carl V ondrick. Vipergpt: Visual inference via python execution for reasoning. Proceed- ings of IEEE International Conference on Computer Vision (ICCV), 2023. 1, 2, 4, 5
work page 2023
-
[38]
Videoagent: Long-form video understanding with large language model as agent, 2024
Xiaohan Wang, Yuhui Zhang, Orr Zohar, and Serena Yeung- Levy. Videoagent: Long-form video understanding with large language model as agent, 2024. 2
work page 2024
-
[39]
Internvideo: General video foundation models via generative and discriminative learning, 2022
Yi Wang, Kunchang Li, Yizhuo Li, Yinan He, Bingkun Huang, Zhiyu Zhao, Hongjie Zhang, Jilan Xu, Yi Liu, Zun Wang, Sen Xing, Guo Chen, Junting Pan, Jiashuo Yu, Yali Wang, Limin Wang, and Yu Qiao. Internvideo: General video foundation models via generative and discriminative learning, 2022. 1, 2
work page 2022
-
[40]
Yueqian Wang, Yuxuan Wang, Kai Chen, and Dongyan Zhao. Stair: Spatial-temporal reasoning with auditable intermediate results for video question answering, 2024. 3
work page 2024
-
[41]
Videotree: Adaptive tree-based video representation for llm reasoning on long videos, 2024
Ziyang Wang, Shoubin Yu, Elias Stengel-Eskin, Jaehong Yoon, Feng Cheng, Gedas Bertasius, and Mohit Bansal. Videotree: Adaptive tree-based video representation for llm reasoning on long videos, 2024. 2, 3, 5, 6
work page 2024
-
[42]
Freeva: Offline mllm as training-free video assistant, 2024
Wenhao Wu. Freeva: Offline mllm as training-free video assistant, 2024. 3
work page 2024
-
[43]
Next-qa:next phase of question-answering to explaining tem- poral actions, 2021
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa:next phase of question-answering to explaining tem- poral actions, 2021. 1, 2
work page 2021
-
[44]
Next-qa:next phase of question-answering to explaining tem- poral actions, 2021
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa:next phase of question-answering to explaining tem- poral actions, 2021. 5
work page 2021
-
[45]
Slowfast-llava: A strong training-free baseline for video large language models, 2024
Mingze Xu, Mingfei Gao, Zhe Gan, Hong-You Chen, Zhengfeng Lai, Haiming Gang, Kai Kang, and Afshin De- hghan. Slowfast-llava: A strong training-free baseline for video large language models, 2024. 3
work page 2024
-
[46]
Panoptic video scene graph generation, 2023
Jingkang Yang, Wenxuan Peng, Xiangtai Li, Zujin Guo, Liangyu Chen, Bo Li, Zheng Ma, Kaiyang Zhou, Wayne Zhang, Chen Change Loy, and Ziwei Liu. Panoptic video scene graph generation, 2023. 2
work page 2023
-
[47]
Mm-react: Prompting chatgpt for multimodal reasoning and action, 2023
Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Mm-react: Prompting chatgpt for multimodal reasoning and action, 2023. 2
work page 2023
-
[48]
Ayyubi, Kai-Wei Chang, and Shih-Fu Chang
Haoxuan You, Rui Sun, Zhecan Wang, Long Chen, Gengyu Wang, Hammad A. Ayyubi, Kai-Wei Chang, and Shih-Fu Chang. Idealgpt: Iteratively decomposing vision and language reasoning via large language models, 2023. 4
work page 2023
-
[49]
Self-chained image-language model for video localization and question answering, 2023
Shoubin Yu, Jaemin Cho, Prateek Yadav, and Mohit Bansal. Self-chained image-language model for video localization and question answering, 2023. 5, 2
work page 2023
-
[50]
Activitynet-qa: A dataset for understanding complex web videos via question answering,
Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yueting Zhuang, and Dacheng Tao. Activitynet-qa: A dataset for understanding complex web videos via question answering,
-
[51]
A simple llm framework for long-range video question-answering, 2024
Ce Zhang, Taixi Lu, Md Mohaiminul Islam, Ziyang Wang, Shoubin Yu, Mohit Bansal, and Gedas Bertasius. A simple llm framework for long-range video question-answering, 2024. 2, 6, 7
work page 2024
-
[52]
A simple llm framework for long-range video question-answering, 2024
Ce Zhang, Taixi Lu, Md Mohaiminul Islam, Ziyang Wang, Shoubin Yu, Mohit Bansal, and Gedas Bertasius. A simple llm framework for long-range video question-answering, 2024. 3, 5, 2
work page 2024
-
[53]
Video-llama: An instruction-tuned audio-visual language model for video un- derstanding, 2023
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video un- derstanding, 2023. 2
work page 2023
-
[54]
Zhicheng Zheng, Xin Yan, Zhenfang Chen, Jingzhou Wang, Qin Zhi Eddie Lim, Joshua B. Tenenbaum, and Chuang Gan. Contphy: Continuum physical concept learning and reasoning from videos, 2024. 2 ENTER: Event Based Interpretable Reasoning for VideoQA Supplementary Material We provide additional details in this section which further elucidate the claims and con...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.