RESIST: Resilient Decentralized Learning Using Consensus Gradient Descent
Pith reviewed 2026-05-23 03:07 UTC · model grok-4.3
The pith
RESIST achieves full algorithmic and statistical convergence for decentralized ERM even when communication links suffer arbitrary man-in-the-middle tampering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RESIST overcomes the three listed limitations of earlier adversarially robust decentralized methods. It achieves algorithmic and statistical convergence for strongly convex, Polyak-Lojasiewicz, and nonconvex ERM problems by employing a multistep consensus gradient descent framework and robust statistics-based screening methods to mitigate the impact of MITM attacks.
What carries the argument
multistep consensus gradient descent framework combined with robust statistics-based screening methods that identify and neutralize arbitrarily altered updates
If this is right
- The iterates converge to the exact ERM solution rather than a neighborhood of it.
- Linear convergence holds for strongly convex objectives under the same attack model.
- Statistical consistency is recovered as the number of local samples grows.
- The same guarantees apply to nonconvex losses that satisfy the Polyak-Lojasiewicz condition.
Where Pith is reading between the lines
- The same screening-plus-consensus pattern might be tested on time-varying or directed graphs without changing the core argument.
- One could examine whether the screening thresholds remain effective when the fraction of attacked links approaches the theoretical breakdown point of the robust estimator.
- Combining RESIST with local differential privacy would be a direct next step to address both communication integrity and data privacy simultaneously.
Load-bearing premise
The screening procedures can reliably detect and discard any updates that have been arbitrarily altered by an attacker on the communication links.
What would settle it
An explicit construction of altered updates that pass every screening test yet drive the iterates away from the true ERM solution on a strongly convex problem.
Figures










read the original abstract
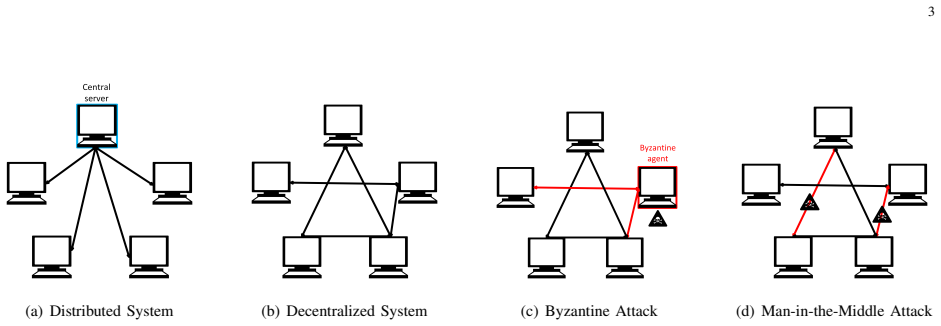
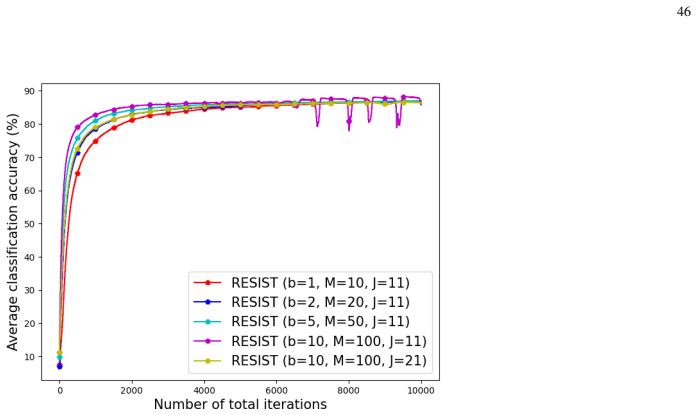
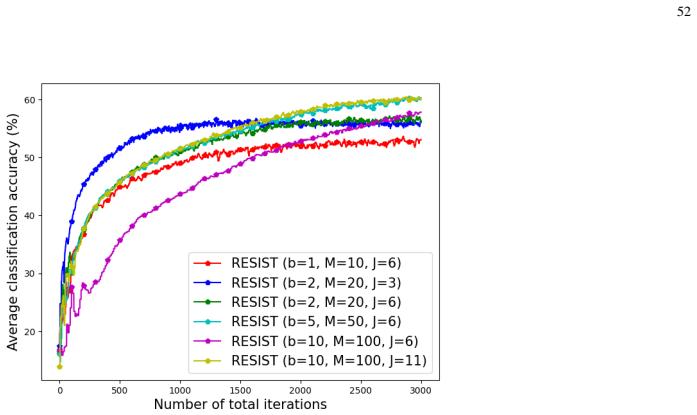
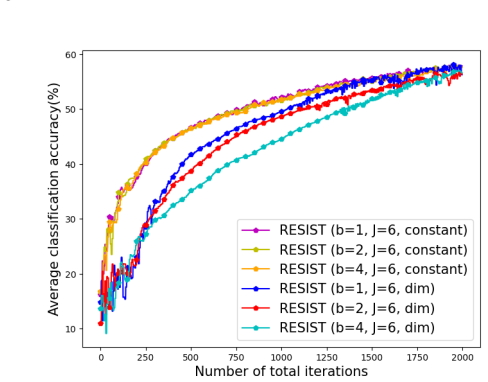
Empirical risk minimization (ERM) is a cornerstone of modern machine learning (ML), supported by advances in optimization theory that ensure efficient solutions with provable algorithmic and statistical learning rates. Privacy, memory, computation, and communication constraints necessitate data collection, processing, and storage across network-connected devices. In many applications, networks operate in decentralized settings where a central server cannot be assumed, requiring decentralized ML algorithms that are efficient and resilient. Decentralized learning, however, faces significant challenges, including an increased attack surface. This paper focuses on the man-in-the-middle (MITM) attack, wherein adversaries exploit communication vulnerabilities to inject malicious updates during training, potentially causing models to deviate from their intended ERM solutions. To address this challenge, we propose RESIST (Resilient dEcentralized learning using conSensus gradIent deScenT), an optimization algorithm designed to be robust against adversarially compromised communication links, where transmitted information may be arbitrarily altered before being received. Unlike existing adversarially robust decentralized learning methods, which often (i) guarantee convergence only to a neighborhood of the solution, (ii) lack guarantees of linear convergence for strongly convex problems, or (iii) fail to ensure statistical consistency as sample sizes grow, RESIST overcomes all three limitations. It achieves algorithmic and statistical convergence for strongly convex, Polyak-Lojasiewicz, and nonconvex ERM problems by employing a multistep consensus gradient descent framework and robust statistics-based screening methods to mitigate the impact of MITM attacks. Experimental results demonstrate the robustness and scalability of RESIST across attack strategies, screening methods, and loss functions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RESIST, a decentralized ERM algorithm that combines multistep consensus gradient descent with robust-statistics screening to achieve algorithmic and statistical convergence under MITM attacks that arbitrarily alter transmitted updates. It claims to overcome three limitations of prior work by guaranteeing convergence (including linear rates for strongly convex and PL cases) to the true ERM solution for strongly convex, Polyak-Łojasiewicz, and nonconvex problems, with supporting experiments across attack strategies and loss functions.
Significance. If the screening procedure and its integration with the multistep consensus framework can be shown to preserve the unattacked convergence rates, the result would meaningfully advance resilient decentralized optimization by providing the first set of guarantees that simultaneously achieve linear algorithmic rates, statistical consistency, and robustness to arbitrary link alterations.
major comments (2)
- [Abstract and §4] Abstract and §4 (convergence analysis): the claim that robust-statistics screening 'mitigate[s] the impact of MITM attacks' and thereby retains the same algorithmic and statistical rates as the unattacked multistep consensus GD is load-bearing, yet the provided description supplies neither an explicit bound on the fraction of compromised links nor a proof that worst-case alterations cannot evade the screen while still biasing the aggregate; standard median/trimmed-mean estimators require a strict honest majority and fail under adaptive evasion.
- [§5] §5 (experiments): the reported robustness is demonstrated only for specific attack strategies and screening methods; without ablation on the fraction of compromised links approaching the theoretical threshold or on evasion attacks crafted to pass the screen, the empirical results do not substantiate the 'arbitrarily altered' guarantee asserted in the abstract.
minor comments (2)
- [§3] Notation for the multistep consensus operator and the screening threshold should be defined before the main theorems rather than inline.
- [Abstract] The abstract states convergence results but the main text should include a short proof sketch or reference to the key lemma establishing that screened updates remain within the honest convex hull.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below, clarifying our assumptions and indicating revisions to improve clarity and empirical support.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (convergence analysis): the claim that robust-statistics screening 'mitigate[s] the impact of MITM attacks' and thereby retains the same algorithmic and statistical rates as the unattacked multistep consensus GD is load-bearing, yet the provided description supplies neither an explicit bound on the fraction of compromised links nor a proof that worst-case alterations cannot evade the screen while still biasing the aggregate; standard median/trimmed-mean estimators require a strict honest majority and fail under adaptive evasion.
Authors: Our convergence analysis in §4 relies on the standard robust-statistics assumption that the fraction of compromised links lies strictly below the breakdown point of the chosen estimator (e.g., <50% for coordinate-wise median). Under this condition the screening step produces an aggregate whose bias is provably bounded, allowing the multistep consensus iteration to recover the same linear (strongly convex/PL) or sublinear (nonconvex) rates as the unattacked case. The proof proceeds by showing that the screened gradient deviates from the true average by at most a term proportional to the maximum honest gradient norm, which is then absorbed into the existing convergence bounds. We agree that the abstract and the opening of §4 should state this fraction bound explicitly. We will revise the manuscript to include the bound together with a concise sketch of why adaptive evasion cannot produce unbounded bias when the fraction condition holds. revision: yes
-
Referee: [§5] §5 (experiments): the reported robustness is demonstrated only for specific attack strategies and screening methods; without ablation on the fraction of compromised links approaching the theoretical threshold or on evasion attacks crafted to pass the screen, the empirical results do not substantiate the 'arbitrarily altered' guarantee asserted in the abstract.
Authors: Section 5 already evaluates several representative attacks (sign-flipping, gradient ascent, and random) together with multiple screening rules. To strengthen the empirical support for the theoretical claims, we will add ablation plots that sweep the compromised-link fraction up to the breakdown threshold and include results for adaptive evasion attempts that attempt to mimic honest statistics. These additional experiments will appear in the revised version. revision: yes
Circularity Check
No circularity; claims rest on proposed multistep consensus + screening construction without reduction to self-definition or fitted inputs
full rationale
The abstract presents RESIST as a new algorithm achieving convergence via multistep consensus gradient descent combined with robust-statistics screening. No equations, fitted parameters, or self-citations appear in the provided text that would make any prediction equivalent to its inputs by construction. The convergence claims for strongly convex/PL/nonconvex ERM are stated as following from the algorithmic framework itself rather than from renaming known results or importing uniqueness via author self-citation. This is the normal case of an independent algorithmic proposal; no load-bearing step reduces to a tautology or statistical forcing.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RESIST … multistep consensus gradient descent framework and robust statistics-based screening methods … coordinate-wise trimmed mean (CWTM) … mixing matrix Yk(pt) … geometric mixing rate … Qk(ps) … inexact averaging operator … Theorems 5.5, 6.4, 6.6 on geometric/sublinear rates
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Assumption 3.3 … filtered graph topologies TF … source component cardinality >1 … β=α^{4b} … τ=|TF| … (1−β^τM)^{⌊(J−2)/τM⌋}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Vapnik, The Nature of Statistical Learning Theory , 2nd ed
V . Vapnik, The Nature of Statistical Learning Theory , 2nd ed. New York, NY: Springer-Verlag, 1999
work page 1999
-
[2]
Machine learning in automated text categorization,
F. Sebastiani, “Machine learning in automated text categorization,” ACM Computing Surveys , vol. 34, no. 1, pp. 1–47, 2002
work page 2002
-
[3]
Supervised machine learning: A review of classification techniques,
S. B. Kotsiantis, I. Zaharakis, and P. Pintelas, “Supervised machine learning: A review of classification techniques,” Emerging Artificial Intell. Applicat. Comput. Eng. , vol. 160, pp. 3–24, 2007
work page 2007
-
[4]
Learning deep architectures for AI,
Y . Bengio, “Learning deep architectures for AI,” Found. and Trends Mach. Learning , vol. 2, no. 1, pp. 1–127, 2009
work page 2009
- [5]
-
[6]
Z. Yang, A. Gang, and W. U. Bajwa, “Adversary-resilient distributed and decentralized statistical inference and machine learning: An overview of recent advances under the Byzantine threat model,” IEEE Signal Process. Mag. , vol. 37, no. 3, pp. 146–159, May 2020
work page 2020
-
[7]
Distributed learning in wireless sensor networks,
J. B. Predd, S. B. Kulkarni, and H. V . Poor, “Distributed learning in wireless sensor networks,” IEEE Signal Process. Mag. , vol. 23, no. 4, pp. 56–69, 2006
work page 2006
-
[8]
S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein, “Distributed optimization and statistical learning via the alternating direction method of multipliers,” Found. and Trends Mach. Learning , vol. 3, no. 1, pp. 1–122, 2011
work page 2011
-
[9]
Adaptation, learning, and optimization over networks,
A. H. Sayed, “Adaptation, learning, and optimization over networks,” Found. and Trends Mach. Learning , vol. 7, no. 4-5, pp. 311–801, 2014
work page 2014
-
[10]
Network topology and communication-computation tradeoffs in decentralized optimization,
A. Nedi ´c, A. Olshevsky, and M. G. Rabbat, “Network topology and communication-computation tradeoffs in decentralized optimization,” Proceedings of the IEEE , vol. 106, no. 5, pp. 953–976, 2018
work page 2018
-
[11]
Scaling-up distributed processing of data streams for machine learning,
M. Nokleby, H. Raja, and W. U. Bajwa, “Scaling-up distributed processing of data streams for machine learning,” Proceedings of the IEEE, vol. 108, no. 11, pp. 1984–2012, 2020
work page 1984
-
[12]
Decentralized federated averaging,
T. Sun, D. Li, and B. Wang, “Decentralized federated averaging,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 45, no. 4, pp. 4289–4301, 2023
work page 2023
-
[13]
Byzantine fault tolerance, from theory to reality,
K. Driscoll, B. Hall, H. Sivencrona, and P. Zumsteq, “Byzantine fault tolerance, from theory to reality,” in Proc. Int. Conf. Computer Safety, Reliability, and Security (SAFECOMP’03), 2003, pp. 235–248
work page 2003
-
[14]
From Byzantine consensus to BFT state machine replication: A latency-optimal transformation,
J. Sousa and A. Bessani, “From Byzantine consensus to BFT state machine replication: A latency-optimal transformation,” in Proc. 9th Euro. Dependable Computing Conf.(EDCC’12), 2012, pp. 37–48
work page 2012
-
[15]
Byzantine vector consensus in complete graphs,
N. H. Vaidya and V . K. Garg, “Byzantine vector consensus in complete graphs,” in Proc. 2016 ACM Symp. Principles of Distributed Computing, 2013, pp. 65–73
work page 2016
-
[16]
Multi-agent optimization in the presence of Byzantine adversaries: Fundamental limits,
L. Su and N. Vaidya, “Multi-agent optimization in the presence of Byzantine adversaries: Fundamental limits,” in Proc. American Control Conference (ACC), 2016, pp. 7183–7188
work page 2016
-
[17]
Byzantine Multi-Agent Optimization: Part II
——, “Byzantine multi-agent optimization: Part II,” arXiv preprint arXiv:1507.01845 , 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[18]
Byzantine-robust distributed learning: Towards optimal statistical rates,
D. Yin, Y . Chen, K. Ramchandran, and P. Bartlett, “Byzantine-robust distributed learning: Towards optimal statistical rates,” in Proc. 35th Intl. Conf. Machine Learning , Jul. 2018, pp. 5650–5659. February 13, 2025 DRAFT 96
work page 2018
-
[19]
Byzantine-resilient distributed large-scale matrix completion,
F. Lin, Q. Ling, and Z. Xiong, “Byzantine-resilient distributed large-scale matrix completion,” in Proc. IEEE Int. Conf. Acoust. Speech and Signal Process. (ICASSP’19), 2019, pp. 8167–8171
work page 2019
-
[20]
H. Yang, X. zhong Zhang, M. Fang, and J. Liu, “Byzantine-resilient stochastic gradient descent for distributed learning: A Lipschitz- inspired coordinate-wise median approach,” Proc. IEEE Conference on Decision and Control (CDC) , pp. 5832–5837, 2019
work page 2019
-
[21]
Byzantine-resilient distributed optimization of multi-dimensional functions,
K. Kuwaranancharoen, L. Xin, and S. Sundaram, “Byzantine-resilient distributed optimization of multi-dimensional functions,” in Proc. American Control Conference (ACC) , 2020, pp. 4399–4404
work page 2020
-
[22]
Byzantine-resilient high-dimensional SGD with local iterations on heterogeneous data,
D. Data and S. Diggavi, “Byzantine-resilient high-dimensional SGD with local iterations on heterogeneous data,” in Proc. 38th Int. Conf. Machine Learning, ser. Proceedings of Machine Learning Research, M. Meila and T. Zhang, Eds., vol. 139. PMLR, 18–24 Jul 2021, pp. 2478–2488
work page 2021
-
[23]
Byzantine-robust decentralized stochastic optimization over static and time-varying networks,
J. Peng, W. Li, and Q. Ling, “Byzantine-robust decentralized stochastic optimization over static and time-varying networks,” Signal Processing, vol. 183, p. 108020, 2021
work page 2021
-
[24]
Byzantine-Resilient Decentralized Policy Evaluation With Linear Function Approximation,
Z. Wu, H. Shen, T. Chen, and Q. Ling, “Byzantine-Resilient Decentralized Policy Evaluation With Linear Function Approximation,” IEEE Transactions on Signal Processing , vol. 69, pp. 3839–3853, Jan. 2021
work page 2021
-
[25]
Byzantine-robust decentralized learning via self-centered clipping,
L. He, S. P. Karimireddy, and M. Jaggi, “Byzantine-robust decentralized learning via self-centered clipping,” arXiv preprint arXiv:2202.01545, 2022
-
[26]
BRIDGE: Byzantine-resilient decentralized gradient descent,
C. Fang, Z. Yang, and W. U. Bajwa, “BRIDGE: Byzantine-resilient decentralized gradient descent,” IEEE Transactions on Signal and Information Processing over Networks , vol. 8, pp. 610–626, 2022
work page 2022
-
[27]
Une propri ´et´e topologique des sous-ensembles analytiques r ´eels,
S. Lojasiewicz, “Une propri ´et´e topologique des sous-ensembles analytiques r ´eels,” Les ´equations aux d ´eriv´ees partielles , vol. 117, pp. 87–89, 1963
work page 1963
-
[28]
Scaling distributed machine learning with the parameter server,
M. Li, D. G. Andersen, J. W. Park, A. J. Smola, A. Ahmed, V . Josifovski, J. Long, E. J. Shekita, and B.-Y . Su, “Scaling distributed machine learning with the parameter server,” in Proc. 11th USENIX Symp. Operating Systems Design and Implementation (OSDI’14) , Broomfield, CO, Oct. 2014, pp. 583–598
work page 2014
-
[29]
Federated learning: Strategies for improving communication efficiency,
J. Kone ˇcn´y, H. B. McMahan, F. X. Yu, P. Richtarik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communication efficiency,” in Proc. NeurIPS Workshop on Private Multi-Party Machine Learning , 2016
work page 2016
-
[30]
Machine learning with adversaries: Byzantine tolerant gradient descent,
P. Blanchard, R. Guerraoui, and J. Stainer, “Machine learning with adversaries: Byzantine tolerant gradient descent,” in Proc. Advances in Neural Inf. Process. Syst. , 2017, pp. 118–128
work page 2017
-
[31]
DRACO: Byzantine-resilient distributed training via redundant gradients,
L. Chen, H. Wang, Z. Charles, and D. Papailiopoulos, “DRACO: Byzantine-resilient distributed training via redundant gradients,” in Proc. 35th Intl. Conf. Machine Learning (ICML) , 2018, pp. 903–912
work page 2018
-
[32]
Robust distributed gradient descent with arbitrary number of Byzantine attackers,
X. Cao and L. Lai, “Robust distributed gradient descent with arbitrary number of Byzantine attackers,” in Proc. IEEE Int. Conf. Acoust. Speech and Signal Process. (ICASSP’19) , 2018, pp. 6373–6377
work page 2018
-
[33]
Asynchronous Byzantine machine learning (the case of SGD),
G. Damaskinos, E. E. Mhamdi, R. Guerraoui, R. Patra, and M. Taziki, “Asynchronous Byzantine machine learning (the case of SGD),” in Proc. 35th Int. Conf. Machine Learning , 2018, pp. 1145–1154
work page 2018
-
[34]
The hidden vulnerability of distributed learning in Byzantium,
E. E. Mhamdi, R. Guerraoui, and S. Rouault, “The hidden vulnerability of distributed learning in Byzantium,” in Proc. 35th Int. Conf. Machine Learning, 2018, pp. 3521–3530
work page 2018
-
[35]
Generalized Byzantine-tolerant SGD
C. Xie, O. Koyejo, and I. Gupta, “Generalized Byzantine-tolerant SGD,” arXiv preprint arXiv:1802.10116 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Phocas: dimensional Byzantine-resilient stochastic gradient descent
——, “Phocas: Dimensional Byzantine-resilient stochastic gradient descent,” arXiv preprint arXiv:1805.09682 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
Distributed training with heterogeneous data: Bridging median- and mean-based algorithms,
X. Chen, T. Chen, H. Sun, S. Wu, and M. Hong, “Distributed training with heterogeneous data: Bridging median- and mean-based algorithms,” in Proc. Advances in Neural Information Processing Systems , 2020, pp. 21 616–21 626
work page 2020
-
[38]
DETOX: A redundancy-based framework for faster and more robust gradient aggregation,
S. Rajput, H. Wang, Z. Charles, and D. Papailiopoulos, “DETOX: A redundancy-based framework for faster and more robust gradient aggregation,” in Proc. Advances in Neural Information Processing Systems , 2019
work page 2019
-
[39]
Distributed Byzantine tolerant stochastic gradient descent in the era of big data,
R. Jin, X. He, and H. Dai, “Distributed Byzantine tolerant stochastic gradient descent in the era of big data,” in Proc. IEEE Intl. Conf. Communications (ICC), 2019, pp. 1–6
work page 2019
-
[40]
Data encoding for Byzantine-resilient distributed optimization,
D. Data, L. Song, and S. N. Diggavi, “Data encoding for Byzantine-resilient distributed optimization,” IEEE Transactions on Information Theory, vol. 67, no. 2, pp. 1117–1140, 2021
work page 2021
-
[41]
Genuinely distributed Byzantine machine learning,
E.-M. El-Mhamdi, R. Guerraoui, A. Guirguis, L. N. Hoang, and S. Rouault, “Genuinely distributed Byzantine machine learning,” in Proceedings of the 39th Symposium on Principles of Distributed Computing , ser. PODC ’20. Association for Computing Machinery, 2020, p. 355–364
work page 2020
-
[42]
Fast and robust distributed learning in high dimension,
E.-M. El-Mhamdi, R. Guerraoui, and S. Rouault, “Fast and robust distributed learning in high dimension,” in 2020 International Symposium on Reliable Distributed Systems (SRDS) , 2020, pp. 71–80. February 13, 2025 DRAFT 97
work page 2020
-
[43]
Byzantine-robust and communication-efficient distributed non-convex learning over non-IID data,
X. He, H. Zhu, and Q. Ling, “Byzantine-robust and communication-efficient distributed non-convex learning over non-IID data,” in ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2022, pp. 5223–5227
work page 2022
-
[44]
Asynchronous distributed ADMM for consensus optimization,
R. Zhang and J. Kwok, “Asynchronous distributed ADMM for consensus optimization,” in Proc. 31th Int. Conf. Machine Learning , ser. Proceedings of Machine Learning Research, E. P. Xing and T. Jebara, Eds., vol. 32, no. 2. Bejing, China: PMLR, 22–24 Jun 2014, pp. 1701–1709
work page 2014
-
[45]
T.-H. Chang, M. Hong, W.-C. Liao, and X. Wang, “Asynchronous distributed ADMM for large-scale optimization—part i: Algorithm and convergence analysis,” IEEE Transactions on Signal Processing , vol. 64, no. 12, pp. 3118–3130, 2016
work page 2016
-
[46]
DP-ADMM: ADMM-based distributed learning with differential privacy,
Z. Huang, R. Hu, Y . Guo, E. Chan-Tin, and Y . Gong, “DP-ADMM: ADMM-based distributed learning with differential privacy,” IEEE Transactions on Information Forensics and Security , vol. 15, pp. 1002–1012, 2020
work page 2020
-
[47]
FedDANE: A federated Newton-type method,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smithy, “FedDANE: A federated Newton-type method,” in 2019 53rd Asilomar Conference on Signals, Systems, and Computers , 2019, pp. 1227–1231
work page 2019
-
[48]
Communication efficient distributed approximate Newton method,
A. Ghosh, R. K. Maity, A. Mazumdar, and K. Ramchandran, “Communication efficient distributed approximate Newton method,” in 2020 IEEE International Symposium on Information Theory (ISIT) , 2020, pp. 2539–2544
work page 2020
-
[49]
DONE: Distributed approximate Newton-type method for federated edge learning,
C. T. Dinh, N. H. Tran, T. D. Nguyen, W. Bao, A. R. Balef, B. B. Zhou, and A. Y . Zomaya, “DONE: Distributed approximate Newton-type method for federated edge learning,” IEEE Transactions on Parallel and Distributed Systems , vol. 33, no. 11, pp. 2648–2660, 2022
work page 2022
-
[50]
Communication efficient distributed Newton method with fast convergence rates,
C. Liu, L. Chen, L. Luo, and J. C. Lui, “Communication efficient distributed Newton method with fast convergence rates,” in Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , ser. KDD ’23. Association for Computing Machinery, 2023, p. 1406–1416
work page 2023
-
[51]
Distributed subgradient methods for multi-agent optimization,
A. Nedic and A. Ozdaglar, “Distributed subgradient methods for multi-agent optimization,” IEEE Trans. Autom. Control , vol. 54, no. 1, pp. 48–61, 2009
work page 2009
-
[52]
Distributed stochastic subgradient projection algorithms for convex optimization,
S. S. Ram, A. Nedi ´c, and V . Veeravalli, “Distributed stochastic subgradient projection algorithms for convex optimization,” J. Optim. Theory and Appl. , vol. 147, no. 3, pp. 516–545, 2010
work page 2010
-
[53]
Distributed optimization over time-varying directed graphs,
A. Nedi ´c and A. Olshevsky, “Distributed optimization over time-varying directed graphs,” IEEE Trans. Autom. Control , vol. 60, no. 3, pp. 601–615, 2015
work page 2015
-
[54]
Distributed stochastic gradient tracking methods,
S. Pu and A. Nedi ´c, “Distributed stochastic gradient tracking methods,” Mathematical Programming, vol. 187, pp. 409–457, 2021
work page 2021
-
[55]
Consensus-based distributed support vector machines,
P. A. Forero, A. Cano, and G. B. Giannakis, “Consensus-based distributed support vector machines,” J. Mach. Learning Research, vol. 11, pp. 1663–1707, 2010
work page 2010
-
[56]
D-ADMM: A communication-efficient distributed algorithm for separable optimization,
J. F. Mota, J. M. Xavier, P. M. Aquiar, and M. Puschel, “D-ADMM: A communication-efficient distributed algorithm for separable optimization,” IEEE Trans. Signal Process. , vol. 61, no. 10, pp. 2718–2723, 2013
work page 2013
-
[57]
On the linear convergence of the ADMM in decentralized consensus optimization,
W. Shi, Q. Ling, K. Yuan, G. Wu, and W. Yin, “On the linear convergence of the ADMM in decentralized consensus optimization,” IEEE Trans. Signal Process., vol. 62, no. 7, pp. 1750–1761, 2014
work page 2014
-
[58]
Convergence rate of distributed ADMM over networks,
A. Makhdoumi and A. Ozdaglar, “Convergence rate of distributed ADMM over networks,” IEEE Transactions on Automatic Control , vol. 62, no. 10, pp. 5082–5095, 2017
work page 2017
-
[59]
A distributed Newton method for network optimization,
A. Jadbabaie, A. Ozdaglar, and M. Zargham, “A distributed Newton method for network optimization,” in Proceedings of the 48h IEEE Conference on Decision and Control (CDC) held jointly with 2009 28th Chinese Control Conference , 2009, pp. 2736–2741
work page 2009
-
[60]
A distributed Newton method for network utility maximization–i: Algorithm,
E. Wei, A. Ozdaglar, and A. Jadbabaie, “A distributed Newton method for network utility maximization–i: Algorithm,” IEEE Transactions on Automatic Control , vol. 58, no. 9, pp. 2162–2175, 2013
work page 2013
-
[61]
A decentralized second-order method with exact linear convergence rate for consensus optimization,
A. Mokhtari, W. Shi, Q. Ling, and A. Ribeiro, “A decentralized second-order method with exact linear convergence rate for consensus optimization,” IEEE Trans. Signal Inf. Process. Netw. , vol. 2, no. 4, pp. 507–522, 2016
work page 2016
-
[62]
Network Newton distributed optimization methods,
A. Mokhtari, Q. Ling, and A. Ribeiro, “Network Newton distributed optimization methods,” IEEE Trans. Signal Process., vol. 65, no. 1, pp. 146–161, 2017
work page 2017
-
[63]
Distributed Newton method for large-scale consensus optimization,
R. Tutunov, H. Bou-Ammar, and A. Jadbabaie, “Distributed Newton method for large-scale consensus optimization,” IEEE Transactions on Automatic Control , vol. 64, no. 10, pp. 3983–3994, 2019
work page 2019
- [64]
-
[65]
Distributed detection in the presence of Byzantine attacks,
S. Marano, V . Matta, and L. Tong, “Distributed detection in the presence of Byzantine attacks,” IEEE Transactions on Signal Processing, vol. 57, no. 1, pp. 16–29, 2009
work page 2009
-
[66]
Distributed inference with Byzantine data: State-of-the-art review on data falsification attacks,
A. Vempaty, L. Tong, and P. Varshney, “Distributed inference with Byzantine data: State-of-the-art review on data falsification attacks,” IEEE Signal Process. Mag. , vol. 30, no. 5, pp. 65–75, May 2013. February 13, 2025 DRAFT 98
work page 2013
-
[67]
Audit bit based distributed Bayesian detection in the presence of Byzantines,
W. Hashlamoun, S. Brahma, and P. K. Varshney, “Audit bit based distributed Bayesian detection in the presence of Byzantines,” IEEE Transactions on Signal and Information Processing over Networks , vol. 4, no. 4, pp. 643–655, 2018
work page 2018
-
[68]
Securing Distributed Gradient Descent in High Dimensional Statistical Learning
L. Su and J. Xu, “Securing distributed machine learning in high dimensions,” arXiv preprint arXiv:1804.10140 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[69]
Defending against saddle point attack in Byzantine-robust distributed learning,
D. Yin, Y . Chen, R. Kannan, and P. Bartlett, “Defending against saddle point attack in Byzantine-robust distributed learning,” in Proc. 36th Intl. Conf. Machine Learning , Jun. 2019, pp. 7074–7084
work page 2019
-
[70]
Byzantine stochastic gradient descent,
D. Alistarh, Z. Allen-Zhu, and J. Li, “Byzantine stochastic gradient descent,” in Proc. Advances in Neural Information Processing Systems, 2018, pp. 4618–4628
work page 2018
-
[71]
L. Li, W. Xu, T. Chen, G. Giannakis, and Q. Ling, “RSA: Byzantine-robust stochastic aggregation methods for distributed learning from heterogeneous datasets,” in Proc. AAAI Conference on Artificial Intelligence , vol. 33, 2019, pp. 1544–1551
work page 2019
-
[72]
Zeno: Distributed Stochastic Gradient Descent with Suspicion-based Fault-tolerance
C. Xie, O. Koyejo, and I. Gupta, “Zeno: Byzantine-suspicious stochastic gradient descent,” arXiv preprint arXiv:1805.10032 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[73]
Zeno++: Robust fully asynchronous SGD,
C. Xie, S. Koyejo, and I. Gupta, “Zeno++: Robust fully asynchronous SGD,” in Proc. 37th Intl. Conf. Machine Learning , Jul. 2020, pp. 10 495–10 503
work page 2020
-
[74]
Resilient asymptotic consensus in robust networks,
H. J. LeBlanc, H. Zhang, X. Koutsoukos, and S. Sundaram, “Resilient asymptotic consensus in robust networks,” IEEE J. Sel. Areas in Commun., vol. 31, no. 4, pp. 766–781, 2013
work page 2013
-
[75]
Iterative Byzantine vector consensus in incomplete graphs,
N. H. Vaidya, L. Tseng, and G. Liang, “Iterative Byzantine vector consensus in incomplete graphs,” in Proc. 15th Int. Conf. Distributed Computing and Networking , 2014, pp. 14–28
work page 2014
-
[76]
Fault-tolerant multi-agent optimization: Optimal iterative distributed algorithms,
L. Su and N. H. Vaidya, “Fault-tolerant multi-agent optimization: Optimal iterative distributed algorithms,” in Proc. ACM Symp. Principles of Distributed Computing , 2016, pp. 425–434
work page 2016
-
[77]
Distributed optimization under adversarial nodes,
S. Sundaram and B. Gharesifard, “Distributed optimization under adversarial nodes,” IEEE Trans. Autom. Control , vol. 64, no. 3, pp. 1063–1076, 2019
work page 2019
-
[78]
RD-SVM: A resilient distributed support vector machine,
Z. Yang and W. U. Bajwa, “RD-SVM: A resilient distributed support vector machine,” in Proc. IEEE Int. Conf. Acoust. Speech and Signal Process. (ICASSP’16), 2016, pp. 2444–2448
work page 2016
-
[79]
Robust decentralized dynamic optimization at presence of malfunctioning agents,
W. Xu, Z. Li, and Q. Ling, “Robust decentralized dynamic optimization at presence of malfunctioning agents,” Signal Process., vol. 153, pp. 24–33, 2018
work page 2018
-
[80]
A. Mitra, J. Richards, S. Bagchi, and S. Sundaram, “Resilient distributed state estimation with mobile agents: Overcoming Byzantine adversaries, communication losses, and intermittent measurements,” Autonomous Robots, vol. 43, no. 3, pp. 743–768, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.