Zero-shot Concept Bottleneck Models
Pith reviewed 2026-05-23 03:35 UTC · model grok-4.3
The pith
Zero-shot concept bottleneck models predict concepts and labels without training by retrieving from a web-scale concept bank.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
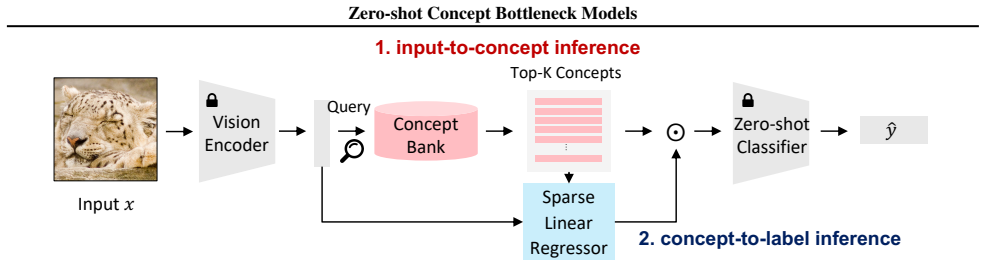
Z-CBMs predict concepts and labels in a fully zero-shot manner without training neural networks. They utilize a large-scale concept bank composed of millions of vocabulary items extracted from the web, map inputs to concepts via cross-modal concept retrieval, and infer labels via concept regression with sparse linear regression on the retrieved concepts.
What carries the argument
Large-scale web concept bank that supports dynamic retrieval of input-related concepts by cross-modal search followed by sparse linear regression to select essential concepts for label prediction.
If this is right
- Any new classification task can be addressed immediately without collecting or labeling a target dataset.
- The model outputs an explicit list of activated concepts that explain each prediction.
- A user can intervene by forcing selected concepts on or off and observe the changed label prediction.
- The same fixed concept bank and retrieval machinery works across multiple unrelated domains.
Where Pith is reading between the lines
- The approach could be combined with existing large vision-language models to improve the quality of the initial concept retrieval step.
- Domains with very fine-grained or technical terminology may require an expanded or curated bank beyond the general web extraction.
- Because no parameters are updated on the target task, the method sidesteps catastrophic forgetting when moving between tasks.
Load-bearing premise
A web-extracted bank of millions of vocabulary items is comprehensive and accurately searchable by cross-modal methods for arbitrary inputs in any domain.
What would settle it
On a specialized domain the retrieved concepts produce label predictions no better than chance or fail to match human-interpretable features that actually drive the label.
Figures






read the original abstract
Concept bottleneck models (CBMs) are inherently interpretable and intervenable neural network models, which explain their final label prediction by the intermediate prediction of high-level semantic concepts. However, they require target task training to learn input-to-concept and concept-to-label mappings, incurring target dataset collections and training resources. In this paper, we present zero-shot concept bottleneck models (Z-CBMs), which predict concepts and labels in a fully zero-shot manner without training neural networks. Z-CBMs utilize a large-scale concept bank, which is composed of millions of vocabulary extracted from the web, to describe arbitrary input in various domains. For the input-to-concept mapping, we introduce concept retrieval, which dynamically finds input-related concepts by the cross-modal search on the concept bank. In the concept-to-label inference, we apply concept regression to select essential concepts from the retrieved concepts by sparse linear regression. Through extensive experiments, we confirm that our Z-CBMs provide interpretable and intervenable concepts without any additional training. Code will be available at https://github.com/yshinya6/zcbm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes zero-shot concept bottleneck models (Z-CBMs) that achieve interpretable and intervenable predictions by constructing a large-scale web-extracted concept bank, performing input-to-concept mapping via cross-modal retrieval, and performing concept-to-label mapping via sparse linear regression, all without training any neural networks on the target task.
Significance. If the zero-shot claim can be sustained, the approach would eliminate the need for target-task data collection and NN training that standard CBMs require, enabling rapid deployment of concept-based models across domains while preserving intervention capabilities.
major comments (1)
- [Abstract] Abstract: the central claim that Z-CBMs operate 'in a fully zero-shot manner without training neural networks' and 'without any additional training' is directly contradicted by the concept regression step, which applies sparse linear regression to fit coefficients that predict class labels from retrieved concept activations; this fitting necessarily uses labeled target-task examples and therefore constitutes task-specific training.
minor comments (2)
- [Abstract] The description of the concept bank construction (millions of vocabulary items extracted from the web) lacks detail on filtering, deduplication, or domain coverage guarantees that would be needed to support the 'arbitrary input in various domains' claim.
- [Abstract] No quantitative comparison is provided in the abstract against baselines that also avoid NN training (e.g., zero-shot CLIP with post-hoc linear probes), making it difficult to isolate the contribution of the concept bank and retrieval steps.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for highlighting an important point of clarification regarding our zero-shot claims. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Z-CBMs operate 'in a fully zero-shot manner without training neural networks' and 'without any additional training' is directly contradicted by the concept regression step, which applies sparse linear regression to fit coefficients that predict class labels from retrieved concept activations; this fitting necessarily uses labeled target-task examples and therefore constitutes task-specific training.
Authors: We agree that the phrasing in the abstract is imprecise and could be misleading. The sparse linear regression step for concept-to-label mapping does require fitting coefficients on labeled target-task examples and therefore represents task-specific training (albeit a lightweight linear model rather than a neural network). The input-to-concept mapping via cross-modal retrieval on the web-scale concept bank requires no target-task training or neural network optimization, which is the primary distinction from standard CBMs. We will revise the abstract (and related claims in the introduction) to state that Z-CBMs require no neural network training on the target task while explicitly noting the use of sparse linear regression on target labels for the final mapping. This revision will be incorporated in the next version. revision: yes
Circularity Check
No circularity: derivation uses external web data and standard off-the-shelf components without self-referential reduction
full rationale
The paper's Z-CBM pipeline consists of (1) retrieving concepts from a web-scale external bank via cross-modal search and (2) applying sparse linear regression on retrieved activations to predict labels. Neither step is defined in terms of the other, nor does any claimed 'prediction' reduce by construction to a parameter fitted from the target result itself. No self-citation chain, uniqueness theorem, or ansatz smuggling is invoked to justify the core mappings. The method is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- sparsity regularization strength in concept regression
axioms (1)
- domain assumption Cross-modal similarity search on the web concept bank reliably surfaces input-relevant concepts
Forward citations
Cited by 1 Pith paper
-
Sparse Concept Anchoring for Interpretable and Controllable Neural Representations
Sparse Concept Anchoring biases neural latent spaces toward targeted concepts using under 0.1% labels per concept, enabling reversible steering via projection and permanent removal via weight ablation with minimal sid...
Reference graph
Works this paper leans on
-
[1]
Nltk: the natural language toolkit
Bird, S. Nltk: the natural language toolkit. In Proceedings of the COLING/ACL 2006 Interactive Presentation Sessions, pp. 69–72,
work page 2006
-
[2]
Douze, M., Guzhva, A., Deng, C., Johnson, J., Szilvasy, G., Mazar´e, P.-E., Lomeli, M., Hosseini, L., and J´egou, H. The faiss library. arXiv preprint arXiv:2401.08281,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Clipscore: A reference-free evaluation metric for im- age captioning
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., and Choi, Y . Clipscore: A reference-free evaluation metric for im- age captioning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 7514–7528,
work page 2021
-
[4]
Discover- then-name: Task-agnostic concept bottlenecks via auto- mated concept discovery
Rao, S., Mahajan, S., B¨ohle, M., and Schiele, B. Discover- then-name: Task-agnostic concept bottlenecks via auto- mated concept discovery. InProceedings of the European Conference on Computer Vision, 2024a. Rao, S., Mahajan, S., B ¨ohle, M., and Schiele, B. Discover-then-name: Task-agnostic concept bottlenecks via automated concept discovery. arXiv prepr...
-
[5]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Soomro, K. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Vlg-cbm: Train- ing concept bottleneck models with vision-language guid- ance
Srivastava, D., Yan, G., and Weng, T.-W. Vlg-cbm: Train- ing concept bottleneck models with vision-language guid- ance. arXiv preprint arXiv:2408.01432,
-
[7]
Explain via any concept: Concept bottleneck model with open vocabulary concepts
Tan, A., Zhou, F., and Chen, H. Explain via any concept: Concept bottleneck model with open vocabulary concepts. arXiv preprint arXiv:2408.02265,
-
[8]
skscope: Fast sparsity- constrained optimization in python
10 Zero-shot Concept Bottleneck Models Wang, Z., Zhu, J., Chen, P., Peng, H., Zhang, X., Wang, A., Zheng, Y ., Zhu, J., and Wang, X. skscope: Fast sparsity- constrained optimization in python. arXiv preprint arXiv:2403.18540,
-
[9]
A., Oliva, A., and Torralba, A
Xiao, J., Hays, J., Ehinger, K. A., Oliva, A., and Torralba, A. Sun database: Large-scale scene recognition from abbey to zoo. In 2010 IEEE computer society conference on computer vision and pattern recognition, pp. 3485–3492. IEEE,
work page 2010
-
[10]
11 Zero-shot Concept Bottleneck Models Table 7: CLIP-Score on 12 classification datasets. We compute the averaged CLIP-Scores between images and concepts with top-10 absolute coefficients. Method Air Bird Cal Car DTD Euro Flo Food IN Pet SUN UCF Avg. Label-free CBM 0.6824 0.7818 0.7023 0.7106 0.6552 0.6179 0.6988 0.6959 0.7202 0.7119 0.7327 0.6688 0.6982 ...
work page 2023
-
[11]
3 with quantitative and qualitative evaluations
To confirm this, we conduct a deeper analysis of the effects of Z-CBMs on the modality gap 12 Zero-shot Concept Bottleneck Models 0.8 0.6 0.4 0.2 0.0 0.2 0.3 0.2 0.1 0.0 0.1 0.2 0.3 0.4 Concept Features Image Features Label Features Reconstructed Features Figure 6: PCA feature visualization of Z-CBMs 1e-3 1e-4 1e-5 1e-6 1e-7 1e-8 Lasso λ 0 10 20 30 40 50 ...
work page 2022
-
[12]
if the data source can be biased. Reproducibility Statement. As described in Sec. 4 and 5 , the implementation of the proposed method uses a publicly available code base. For example, the VLMs backbones are publicly available in the OpenAI CLIP 2 and Open CLIP 3 GitHub repositories. All datasets are also available on the web; see the references in Sec. 5....
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.