MapNav: A Novel Memory Representation via Annotated Semantic Maps for Vision-and-Language Navigation
Pith reviewed 2026-05-23 02:56 UTC · model grok-4.3
The pith
MapNav replaces historical observation frames with an Annotated Semantic Map to guide vision-and-language navigation agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
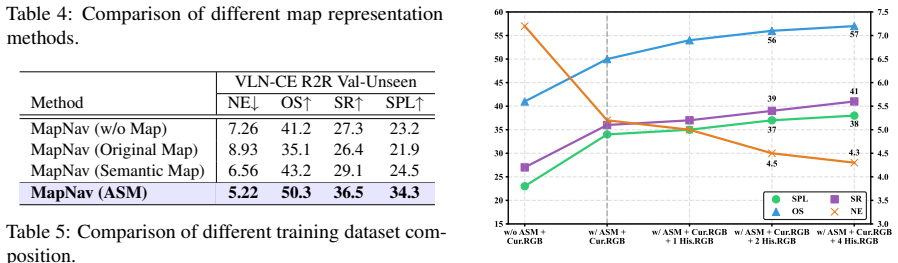
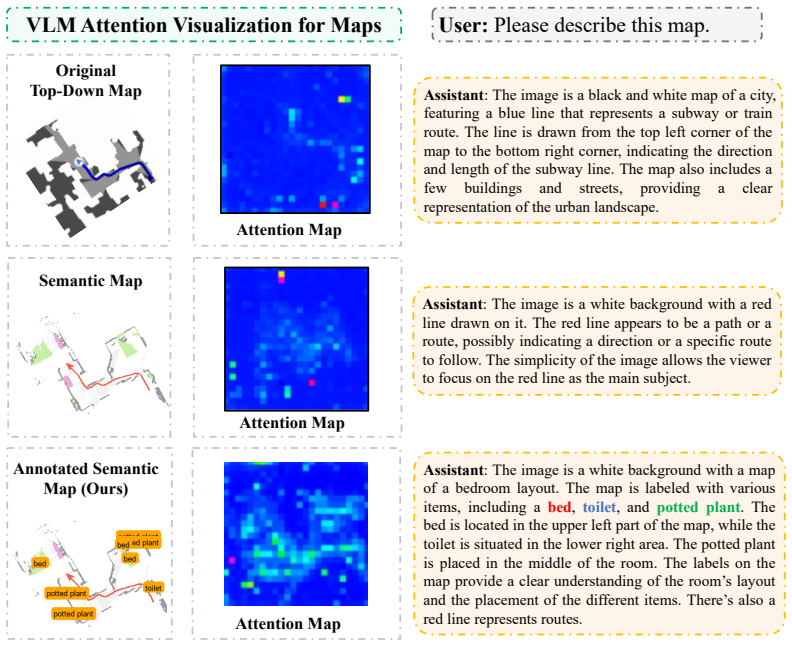
MapNav constructs a top-down semantic map at the beginning of each episode and updates it at every timestep; key regions receive explicit textual labels that convert abstract semantics into navigation cues, producing the Annotated Semantic Map; the resulting ASM is supplied directly to a VLM-powered agent as its only memory representation, replacing all historical observation frames.
What carries the argument
Annotated Semantic Map (ASM): a top-down semantic map that is initialized once per episode, updated each timestep, and augmented with textual labels on key regions to supply structured navigation cues to the agent.
If this is right
- Storage and compute overhead from maintaining observation histories is eliminated.
- The same ASM construction process yields state-of-the-art navigation success in both simulated and physical environments.
- VLMs can be applied directly to the compact annotated map rather than to raw image sequences.
- The released ASM generation code and dataset enable other researchers to adopt the representation without re-implementing map construction.
Where Pith is reading between the lines
- If the ASM proves robust across longer trajectories, similar map-based memory could reduce context length requirements in other embodied tasks such as object manipulation or multi-agent coordination.
- Explicit text labels on the map may allow human operators to inspect or correct the agent's internal state more easily than inspecting raw image histories.
- The approach implicitly assumes reliable semantic segmentation and mapping; any degradation in those upstream modules would directly limit the ASM's usefulness.
Load-bearing premise
The combination of a top-down semantic map and its textual annotations contains enough structured information to substitute for stored historical frames without losing decision-critical detail.
What would settle it
A controlled ablation in which the textual annotations are removed from the ASM while keeping the geometric map intact, followed by measurement of whether success rate or path efficiency falls in the same environments where the full ASM previously achieved SOTA.
Figures
















read the original abstract
Vision-and-language navigation (VLN) is a key task in Embodied AI, requiring agents to navigate diverse and unseen environments while following natural language instructions. Traditional approaches rely heavily on historical observations as spatio-temporal contexts for decision making, leading to significant storage and computational overhead. In this paper, we introduce MapNav, a novel end-to-end VLN model that leverages Annotated Semantic Map (ASM) to replace historical frames. Specifically, our approach constructs a top-down semantic map at the start of each episode and update it at each timestep, allowing for precise object mapping and structured navigation information. Then, we enhance this map with explicit textual labels for key regions, transforming abstract semantics into clear navigation cues and generate our ASM. MapNav agent using the constructed ASM as input, and use the powerful end-to-end capabilities of VLM to empower VLN. Extensive experiments demonstrate that MapNav achieves state-of-the-art (SOTA) performance in both simulated and real-world environments, validating the effectiveness of our method. Moreover, we will release our ASM generation source code and dataset to ensure reproducibility, contributing valuable resources to the field. We believe that our proposed MapNav can be used as a new memory representation method in VLN, paving the way for future research in this field.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MapNav, an end-to-end VLN model for vision-and-language navigation that constructs a top-down Annotated Semantic Map (ASM) at episode start, updates it each timestep, adds explicit textual labels to key regions, and feeds the resulting ASM to a VLM agent in place of historical observation frames, claiming this yields SOTA performance in both simulated and real-world settings while reducing storage and compute overhead.
Significance. If the central performance claims hold after proper controls, the work would supply a concrete alternative memory representation for VLN that trades egocentric history for an explicitly annotated top-down semantic map, potentially lowering the cost of maintaining long-horizon context and offering a reusable resource via the promised code and dataset release.
major comments (2)
- [Abstract / method description] Abstract and method overview: the central claim that the ASM fully substitutes for historical egocentric frames without loss of decision-critical detail (viewpoint-dependent appearance, texture, partial occlusions, metric depth referenced by instructions) is not isolated by any described ablation that holds the VLM backbone, training regime, and map-construction oracle fixed while toggling the presence of past RGB observations.
- [Abstract] Abstract: the assertion of SOTA results in simulated and real-world environments is stated without any quantitative metrics, baseline comparisons, ablation tables, or error analysis, preventing evaluation of whether gains arise from the ASM substitution itself.
minor comments (1)
- [Abstract] Abstract contains several grammatical issues (e.g., 'update it at each timestep' should be 'updates'; the clause 'transforming abstract semantics into clear navigation cues and generate our ASM' is incomplete).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on MapNav. The comments highlight opportunities to strengthen the presentation of our core claims regarding the Annotated Semantic Map (ASM) as a memory representation. We address each point below and will revise the manuscript to improve clarity and provide additional supporting evidence.
read point-by-point responses
-
Referee: [Abstract / method description] Abstract and method overview: the central claim that the ASM fully substitutes for historical egocentric frames without loss of decision-critical detail (viewpoint-dependent appearance, texture, partial occlusions, metric depth referenced by instructions) is not isolated by any described ablation that holds the VLM backbone, training regime, and map-construction oracle fixed while toggling the presence of past RGB observations.
Authors: We agree that an explicit ablation isolating the ASM substitution—while holding the VLM backbone, training regime, and map-construction process fixed—is necessary to rigorously support the claim. The current manuscript focuses on end-to-end performance comparisons but does not include this controlled toggle of historical RGB frames. In the revised version, we will add such an ablation study, reporting navigation success rates and other metrics with and without past RGB observations under otherwise identical conditions. This will directly address whether decision-critical details are preserved by the ASM alone. revision: yes
-
Referee: [Abstract] Abstract: the assertion of SOTA results in simulated and real-world environments is stated without any quantitative metrics, baseline comparisons, ablation tables, or error analysis, preventing evaluation of whether gains arise from the ASM substitution itself.
Authors: The abstract was written concisely and therefore omits specific numbers. The full manuscript contains quantitative results, baseline comparisons, and error analyses in the experiments section. To improve accessibility, we will revise the abstract to include key metrics (e.g., success rate improvements over baselines in simulation and real-world settings) while maintaining brevity. We will also ensure the abstract references the relevant tables for full details. revision: yes
Circularity Check
No circularity: empirical construction with no derivations or self-referential reductions.
full rationale
The paper introduces MapNav as an empirical method for VLN that constructs and annotates a top-down semantic map to replace historical frames, then evaluates it experimentally. No equations, fitted parameters, predictions, or derivation chains appear in the provided text. The central claim rests on experimental SOTA results rather than any step that reduces by construction to its inputs. No self-citations are invoked as load-bearing uniqueness theorems. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Annotated Semantic Map (ASM)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a novel end-to-end VLM-based VLN model, MapNav, which leverages Annotated Semantic Maps for innovative memory representation, effectively replacing traditional historical frames.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The ASM generation pipeline involves two main stages: (1) semantic region identification via connected component analysis... (2) centroid computation... explicit textual annotations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
Dual-Anchoring: Addressing State Drift in Vision-Language Navigation
Dual-Anchoring Framework mitigates progress drift via structured instruction tokens and memory drift via landmark-centric retrospective prediction, yielding 15.2% success rate gain and 24.7% on long trajectories.
-
VLN-Cache: Enabling Token Caching for VLN Models with Visual/Semantic Dynamics Awareness
VLN-Cache delivers up to 1.52x faster inference in VLN models by using view-aligned remapping for geometric consistency and a task-relevance saliency filter to manage semantic changes during navigation.
-
GA-VLN: Geometry-Aware BEV Representation for Efficient Vision-Language Navigation
GA-VLN builds a geometry-aware BEV representation from RGB-D inputs plus 3D foundation model features to deliver state-of-the-art vision-language navigation using only navigation data.
-
Dual-Anchoring: Addressing State Drift in Vision-Language Navigation
Dual-Anchoring adds explicit progress tokens and retrospective landmark verification to VLN agents, cutting state drift and lifting success rate 15.2% overall with 24.7% gains on long trajectories.
Reference graph
Works this paper leans on
-
[1]
Dong An, Hanqing Wang, Wenguan Wang, Zun Wang, Yan Huang, Keji He, and Liang Wang. 2024. Etpnav: Evolving topological planning for vision-language navigation in continuous environments. IEEE Transactions on Pattern Analysis and Machine Intelligence
work page 2024
-
[2]
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niebner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. 2017. Matterport3d: Learning from rgb-d data in indoor environments. In International Conference on 3D Vision, pages 667--676
work page 2017
- [3]
-
[4]
Peihao Chen, Dongyu Ji, Kunyang Lin, Runhao Zeng, Thomas Li, Mingkui Tan, and Chuang Gan. 2022. Weakly-supervised multi-granularity map learning for vision-and-language navigation. Advances in Neural Information Processing Systems, pages 38149--38161
work page 2022
-
[5]
Schwing, Alexander Kirillov, and Rohit Girdhar
Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, and Rohit Girdhar. 2022. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
work page 2022
-
[6]
Jing Gu, Eliana Stefani, Qi Wu, Jesse Thomason, and Xin Wang. 2022. Vision-and-language navigation: A survey of tasks, methods, and future directions. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, pages 7606--7623
work page 2022
- [7]
-
[8]
Weituo Hao, Chunyuan Li, Xiujun Li, Lawrence Carin, and Jianfeng Gao. 2020. Towards learning a generic agent for vision-and-language navigation via pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13137--13146
work page 2020
-
[9]
Xiaoshuai Hao, Yunfeng Diao, Mengchuan Wei, Yifan Yang, Peng Hao, Rong Yin, Hui Zhang, Weiming Li, Shu Zhao, and Yu Liu. 2025 b . Mapfusion: A novel bev feature fusion network for multi-modal map construction. Information Fusion, 119:103018
work page 2025
-
[10]
Xiaoshuai Hao, Ruikai Li, Hui Zhang, Dingzhe Li, Rong Yin, Sangil Jung, Seung-In Park, ByungIn Yoo, Haimei Zhao, and Jing Zhang. 2024 a . Mapdistill: Boosting efficient camera-based hd map construction via camera-lidar fusion model distillation. In European Conference on Computer Vision, pages 166--183. Springer
work page 2024
- [11]
-
[12]
Xiaoshuai Hao, Hui Zhang, Yifan Yang, Yi Zhou, Sangil Jung, Seung-In Park, and ByungIn Yoo. 2024 b . Mbfusion: A new multi-modal bev feature fusion method for hd map construction. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 15922--15928. IEEE
work page 2024
-
[13]
Yicong Hong, Zun Wang, Qi Wu, and Stephen Gould. 2022. Bridging the gap between learning in discrete and continuous environments for vision-and-language navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15439--15449
work page 2022
-
[14]
Yicong Hong, Yang Zhou, Ruiyi Zhang, Franck Dernoncourt, Trung Bui, Stephen Gould, and Hao Tan. 2023. Learning navigational visual representations with semantic map supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3055--3067
work page 2023
- [15]
-
[16]
Glenn Jocher, Jing Qiu, and Ayush Chaurasia. 2023. https://github.com/ultralytics/ultralytics Ultralytics YOLO
work page 2023
-
[17]
Jacob Krantz, Aaron Gokaslan, Dhruv Batra, Stefan Lee, and Oleksandr Maksymets. 2021. Waypoint models for instruction-guided navigation in continuous environments. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15162--15171
work page 2021
-
[18]
Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. 2020. Beyond the nav-graph: Vision-and-language navigation in continuous environments. In European Conference on Computer Vision, pages 104--120
work page 2020
-
[19]
Alexander Ku, Peter Anderson, Roma Patel, Eugene Ie, and Jason Baldridge. 2020 a . Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, pages 4392--4412
work page 2020
-
[20]
Alexander Ku, Peter Anderson, Roma Patel, Eugene Ie, and Jason Baldridge. 2020 b . Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, pages 4392--4412
work page 2020
-
[21]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. 2024 a . Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [22]
- [23]
-
[24]
Rui Liu, Wenguan Wang, and Yi Yang. 2024. Volumetric environment representation for vision-language navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16317--16328
work page 2024
- [25]
-
[26]
Yuxing Long, Xiaoqi Li, Wenzhe Cai, and Hao Dong. 2024 b . Discuss before moving: Visual language navigation via multi-expert discussions. In IEEE International Conference on Robotics and Automation, pages 17380--17387
work page 2024
-
[27]
Sang-Min Park and Young-Gab Kim. 2023. Visual language navigation: A survey and open challenges. Artificial Intelligence Review, pages 365--427
work page 2023
-
[28]
Yuankai Qi, Zizheng Pan, Shengping Zhang, Anton van den Hengel, and Qi Wu. 2020. Object-and-action aware model for visual language navigation. In European Conference on Computer Vision, pages 303--317
work page 2020
-
[29]
St \'e phane Ross, Geoffrey Gordon, and Drew Bagnell. 2011. A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the international conference on artificial intelligence and statistics, pages 627--635
work page 2011
-
[30]
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. 2019. Habitat: A platform for embodied ai research. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9339--9347
work page 2019
-
[31]
Dhruv Shah, B a \.z ej Osi \'n ski, Sergey Levine, et al. 2023. Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action. In Conference on Robot Learning, pages 492--504
work page 2023
- [32]
-
[33]
Jesse Thomason, Michael Murray, Maya Cakmak, and Luke Zettlemoyer. 2020. Vision-and-dialog navigation. In Conference on Robot Learning, pages 394--406
work page 2020
-
[34]
Arun Balajee Vasudevan, Dengxin Dai, and Luc Van Gool. 2021. Talk2nav: Long-range vision-and-language navigation with dual attention and spatial memory. International Journal of Computer Vision, pages 246--266
work page 2021
-
[35]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, and Shuqiang Jiang. 2023. Gridmm: Grid memory map for vision-and-language navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15625--15636
work page 2023
-
[37]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, pages 24824--24837
work page 2022
- [38]
-
[39]
Siying Wu, Xueyang Fu, Feng Wu, and Zheng-Jun Zha. 2022. Cross-modal semantic alignment pre-training for vision-and-language navigation. In Proceedings of the ACM International Conference on Multimedia, pages 4233--4241
work page 2022
- [40]
-
[41]
Naoki Yokoyama, Sehoon Ha, Dhruv Batra, Jiuguang Wang, and Bernadette Bucher. 2024. Vlfm: Vision-language frontier maps for zero-shot semantic navigation. In IEEE International Conference on Robotics and Automation, pages 42--48
work page 2024
-
[42]
Bangguo Yu, Hamidreza Kasaei, and Ming Cao. 2023. L3mvn: Leveraging large language models for visual target navigation. In IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 3554--3560
work page 2023
-
[43]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11975--11986
work page 2023
- [44]
- [45]
-
[46]
Chaoning Zhang, Dongshen Han, Yu Qiao, Jung Uk Kim, Sung-Ho Bae, Seungkyu Lee, and Choong Seon Hong. 2023. Faster segment anything: Towards lightweight sam for mobile applications. arXiv preprint arXiv:2306.14289
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, and He Wang. 2024 a . Navid: Video-based vlm plans the next step for vision-and-language navigation. In Proceedings of Robotics: Science and Systems
work page 2024
- [48]
- [49]
-
[50]
Duo Zheng, Shijia Huang, Lin Zhao, Yiwu Zhong, and Liwei Wang. 2024. Towards learning a generalist model for embodied navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13624--13634
work page 2024
-
[51]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, pages 46595--46623
work page 2023
-
[52]
Gengze Zhou, Yicong Hong, and Qi Wu. 2024. Navgpt: Explicit reasoning in vision-and-language navigation with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 7641--7649
work page 2024
-
[53]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[54]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.