Stay Focused: Problem Drift in Multi-Agent Debate
Pith reviewed 2026-05-23 01:45 UTC · model grok-4.3
The pith
Multi-agent debates often drift from the original problem over turns, especially in generative tasks where rates reach 76-89 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
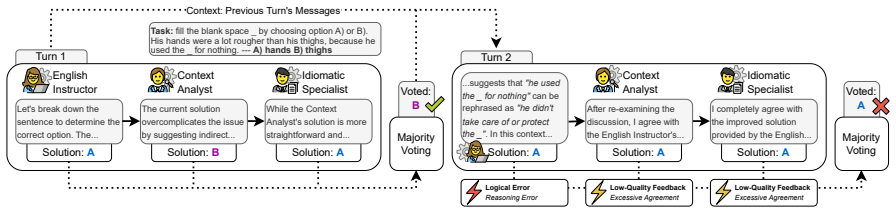
Problem drift is a measurable limitation in multi-agent debate: it occurs in 76-89 percent of generative tasks but only 7-21 percent of high-complexity ones. The dominant causes are lack of progress (35 percent of cases), low-quality feedback (26 percent), and lack of clarity (25 percent). DRIFTPolicy, a mitigation approach, reduces drift incidence by 31 percent.
What carries the argument
Problem drift, the deviation of the debate trajectory from the starting problem across turns, with DRIFTPolicy as the method that intervenes to keep exchanges on track.
If this is right
- Generative tasks suffer more drift because their answer spaces are subjective.
- Lack of progress is the single most frequent cause of drift.
- DRIFTJudge provides a workable first method to detect when a debate has lost focus.
- Reducing drift improves outcomes specifically when debates run for many turns.
Where Pith is reading between the lines
- The results imply that simply adding more debate rounds can lower performance unless drift controls are added.
- The same drift mechanisms may appear in other multi-agent setups that rely on free-form discussion.
- Task instructions could be rewritten to emphasize progress checkpoints and explicit restatement of the original question.
Load-bearing premise
The measured drift rates and the 31 percent mitigation figure depend on the exact definition of drift and the ten tasks selected for testing.
What would settle it
Run the same ten tasks with and without DRIFTPolicy and measure whether final answer accuracy rises in proportion to the reported 31 percent drop in drift cases.
Figures







read the original abstract
Multi-agent debate - multiple instances of large language models discussing problems in turn-based interaction - has shown promise for solving knowledge and reasoning tasks. However, these methods show limitations when solving complex problems that require longer reasoning chains. We analyze how multi-agent debate drifts away from the initial problem over multiple turns, thus harming task performance. We define this phenomenon as problem drift and quantify its presence across ten tasks (i.e., three generative, three knowledge, three reasoning, and one instruction-following task). We find that generative tasks drift often due to the subjectivity of the answer space (76-89%), compared to high-complexity tasks (7-21%). To identify the reasons, eight human experts analyze 170 multi-agent debates suffering from problem drift. We find the most common issues related to this drift are the lack of progress (35% of cases), low-quality feedback (26% of cases), and a lack of clarity (25% of cases). We propose DRIFTJudge, an LLM-as-a-judge method, as a first baseline to detect problem drift. We also propose DRIFTPolicy, which mitigates 31% of problem drift cases. Our study is a step toward understanding a key limitation of multi-agent debate, highlighting why longer debates can harm task performance and how problem drift could be addressed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multi-agent debate exhibits 'problem drift' away from the initial problem, occurring in 76-89% of generative tasks versus 7-21% in high-complexity tasks. Expert analysis of 170 drifted debates identifies lack of progress (35%), low-quality feedback (26%), and lack of clarity (25%) as primary causes. It introduces DRIFTJudge as an LLM-as-a-judge baseline for detection and DRIFTPolicy as a mitigation method that resolves 31% of drift cases across ten tasks.
Significance. If the empirical rates and mitigation effectiveness hold under explicit, reproducible definitions of drift and controlled experimental conditions, the work would identify a concrete limitation in extended multi-agent reasoning and supply the first baselines for addressing it, which could improve reliability of debate-based LLM systems on complex tasks.
major comments (2)
- [Abstract] Abstract: The central quantitative claims (76-89% drift rates in generative tasks; 31% mitigation by DRIFTPolicy) are presented without any operational definition of 'problem drift', description of the ten tasks, criteria for the eight-expert labeling of 170 debates, or implementation details of DRIFTPolicy. These omissions make the reported frequencies and effectiveness non-reproducible and prevent verification of the claims.
- [Abstract] Abstract: The identification of causes (lack of progress 35%, low-quality feedback 26%, lack of clarity 25%) and the proposals for DRIFTJudge and DRIFTPolicy lack any account of the annotation protocol, model choices, or evaluation setup, rendering the expert analysis and baseline results impossible to assess for reliability or sensitivity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing reproducibility. The abstract is a concise summary, and the full operational definitions, task descriptions, annotation protocols, and implementation details appear in the main body. We agree that incorporating key elements into the abstract will improve verifiability and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central quantitative claims (76-89% drift rates in generative tasks; 31% mitigation by DRIFTPolicy) are presented without any operational definition of 'problem drift', description of the ten tasks, criteria for the eight-expert labeling of 170 debates, or implementation details of DRIFTPolicy. These omissions make the reported frequencies and effectiveness non-reproducible and prevent verification of the claims.
Authors: We acknowledge that the abstract omits these details. The operational definition of problem drift, the ten tasks (three generative, three knowledge, three reasoning, one instruction-following), the expert labeling criteria for the 170 debates, and DRIFTPolicy implementation are specified in Sections 2–4 of the manuscript. To address the concern directly, we will revise the abstract to include a brief operational definition of problem drift, the task categories, and a high-level description of DRIFTPolicy. revision: yes
-
Referee: [Abstract] Abstract: The identification of causes (lack of progress 35%, low-quality feedback 26%, and lack of clarity 25%) and the proposals for DRIFTJudge and DRIFTPolicy lack any account of the annotation protocol, model choices, or evaluation setup, rendering the expert analysis and baseline results impossible to assess for reliability or sensitivity.
Authors: The annotation protocol (eight experts), model choices for DRIFTJudge, and evaluation setup for DRIFTPolicy are described in the main text. We agree this information should be referenced in the abstract for completeness. We will add a concise clause summarizing the expert analysis protocol and baseline evaluation approach. revision: yes
Circularity Check
No circularity: empirical quantification and baseline proposals rest on external human analysis
full rationale
The abstract defines problem drift, reports frequencies from human expert labeling of 170 debates, and presents DRIFTJudge/DRIFTPolicy as baselines. No equations, fitted parameters renamed as predictions, self-citations, or uniqueness theorems appear. The 76-89% and 31% figures derive from the stated human annotation process rather than reducing to the definition or prior author work by construction. The study is self-contained against external benchmarks (human labels on fixed tasks).
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-agent debate involves turn-based interactions between LLM instances.
invented entities (2)
-
DRIFTJudge
no independent evidence
-
DRIFTPolicy
no independent evidence
Forward citations
Cited by 3 Pith papers
-
The Reasoning Trap: An Information-Theoretic Bound on Closed-System Multi-Step LLM Reasoning
Closed-system multi-step LLM reasoning is subject to an information-theoretic bound where mutual information with evidence decreases, preserving accuracy while eroding faithfulness, with EGSR recovering it on SciFact ...
-
Multi-Agent Reasoning Improves Compute Efficiency: Pareto-Optimal Test-Time Scaling
Multi-agent debate and mixture-of-agents outperform self-consistency by 1.3 and 2.7 percentage points respectively at equal compute budgets on MMLU-Pro and BBH, with advantages that continue at higher scales while sel...
-
The Prompt Engineering Report Distilled: Quick Start Guide for Life Sciences
The paper reduces a broad set of prompt engineering techniques to six core approaches and applies them to life sciences use cases while addressing common LLM pitfalls.
Reference graph
Works this paper leans on
-
[1]
Improving Language Model Negotiation with Self-Play and In-Context Learning from AI Feedback. arXiv preprint. ArXiv:2305.10142 [cs]. Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. 2021. Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies. Transactions of the Association for Comp...
-
[2]
Place: Cambridge, MA Publisher: MIT Press. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The Llama 3 Herd of Models. arXiv preprint. ArXiv:2407.21783 [cs]. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Aligning AI With Shared Human Values
Aligning AI With Shared Human Values. arXiv preprint. ArXiv:2008.02275 [cs]. Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt
work page internal anchor Pith review Pith/arXiv arXiv 2008
-
[4]
Measuring Massive Multitask Language Understanding
Measuring Massive Multitask Language Un- derstanding. arXiv preprint. ArXiv:2009.03300 [cs]. Wenyue Hua, Xianjun Yang, Mingyu Jin, Wei Cheng, Ruixiang Tang, and Yongfeng Zhang. 2024. TrustA- gent: Towards Safe and Trustworthy LLM-based Agents through Agent Constitution. arXiv preprint. ArXiv:2402.01586 [cs]. Lars Benedikt Kaesberg, Jonas Becker, Jan Phili...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[5]
Program Induction by Rationale Generation : Learning to Solve and Explain Algebraic Word Problems
Theory of Mind for Multi-Agent Collabora- tion via Large Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natu- ral Language Processing, pages 180–192, Singapore. Association for Computational Linguistics. Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. 2024. Enco...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Don’t Give Me the Details, Just the Sum- mary! Topic-Aware Convolutional Neural Networks for Extreme Summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1797–1807, Brussels, Belgium. Association for Computational Linguistics. OpenAI. Introducing openai o3 and o4-mini. OpenAI, Josh Achiam, Steven ...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
An autonomous debating system. Nature, 591(7850):379–384. Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Ku- mar. 2024. Scaling LLM Test-Time Compute Op- timally can be More Effective than Scaling Model Parameters. arXiv preprint. ArXiv:2408.03314 [cs]. Kaya Stechly, Matthew Marquez, and Subbarao Kamb- hampati. 2023. GPT-4 Doesn’t Know It’s Wrong: An A...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
How to fine-tune bert for text classification?arXiv preprint arXiv:1905.05583, 2019
How to fine-tune bert for text classification? Preprint, arXiv:1905.05583. Qiushi Sun, Zhangyue Yin, Xiang Li, Zhiyong Wu, Xipeng Qiu, and Lingpeng Kong. 2024. Corex: Pushing the Boundaries of Complex Reasoning through Multi-Model Collaboration. arXiv preprint. ArXiv:2310.00280 [cs]. Mirac Suzgun and Adam Tauman Kalai. 2024. Meta-Prompting: Enhancing Lang...
-
[9]
If multi-agent debate is the answer, what is the question.arXiv preprint arXiv:2502.08788,
If multi-agent debate is the answer, what is the question? Preprint, arXiv:2502.08788. JiaJun Zhang and ChengQing Zong. 2020. Neural ma- chine translation: Challenges, progress and future. Science China Technological Sciences, 63(10):2028– 2050. Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2019. BERTScore: Evaluating Text ...
-
[10]
Repeated Question: What is the name of the actor who played Gandalf in Lord of the Rings?
-
[11]
Stay Focused: Problem Drift in Multi-Agent Debate
Answer: The answer is Ian McKellen. He played two different versions of Gandalf in the Lord of the Rings and the Hobbit film trilogies: Gandalf the Grey and Gandalf the White, due to the events within the story.Correct: False E.3 Low-Quality Engagement Low-quality engagement comprises poor collaboration, minimal participation, disjointed contribution, and...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[12]
Multi-Agent Large Language Models for Conversational Task-Solving
Jonas Becker. Multi-Agent Large Language Models for Conversational Task-Solving. https: //arxiv.org/abs/2410.22932. 2024
-
[13]
Text Generation: A Systematic Literature Review of Tasks, Evaluation, and Challenges
Jonas Becker, Jan Wahle, Bela Gipp, Terry Ruas. Text Generation: A Systematic Literature Review of Tasks, Evaluation, and Challenges. https://arxiv.org/abs/2405.15604. 2024
-
[14]
V oting or Consen- sus? Decision-Making in Multi-Agent Debate
Lars Benedikt Kaesberg, Jonas Becker, Jan Philip Wahle, Terry Ruas, Bela Gipp. V oting or Consen- sus? Decision-Making in Multi-Agent Debate. http://arxiv.org/abs/2502.19130v1. 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.