WiseMind: a knowledge-guided multi-agent framework for accurate and empathetic psychiatric diagnosis
Pith reviewed 2026-05-23 02:28 UTC · model grok-4.3
The pith
A multi-agent framework with a DSM-5 knowledge graph reaches 85.6% top-1 accuracy in psychiatric diagnosis while producing supportive responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
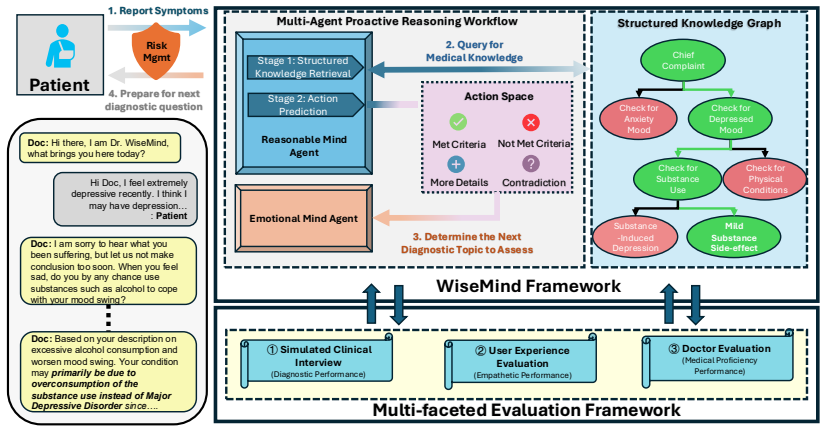
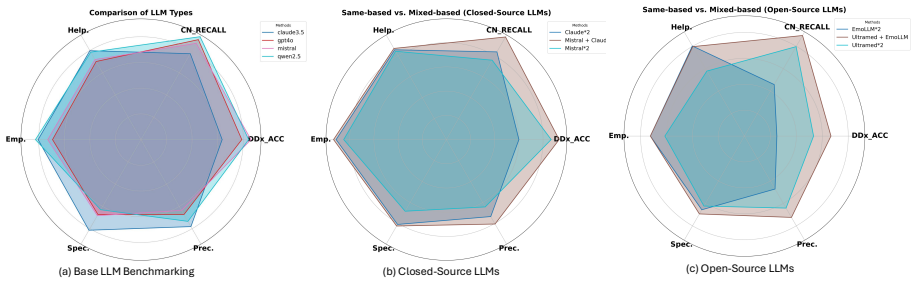
WiseMind is a multi-agent framework inspired by Dialectical Behavior Therapy that deploys a Reasonable Mind Agent for evidence-based logic and an Emotional Mind Agent for empathetic communication. The agents are steered by a DSM-5-guided Structured Knowledge Graph that directs diagnostic questions and reduces hallucinations. On three common psychiatric conditions, the system achieves 85.6% top-1 diagnostic accuracy across 1206 simulated conversations and 180 real user sessions, exceeds knowledge-enhanced single-agent baselines by 15-54 percentage points, and produces responses that board-certified psychiatrists judge as clinically sound and psychologically supportive.
What carries the argument
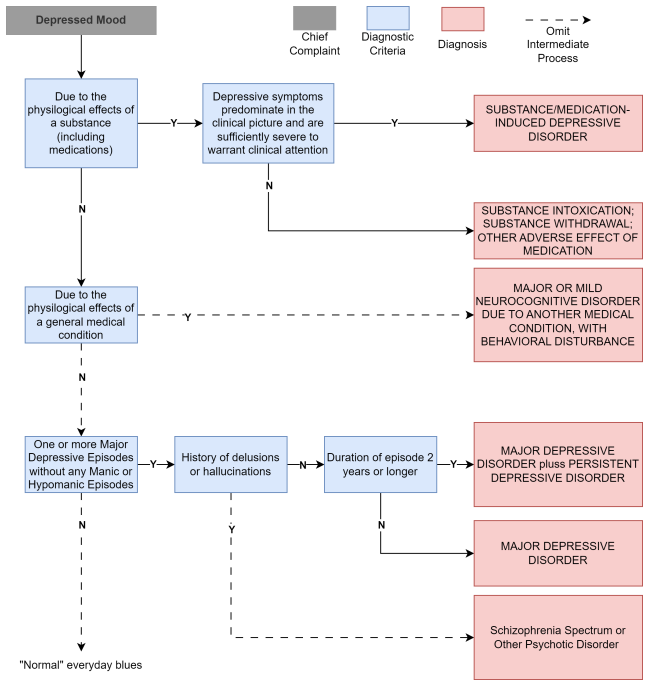
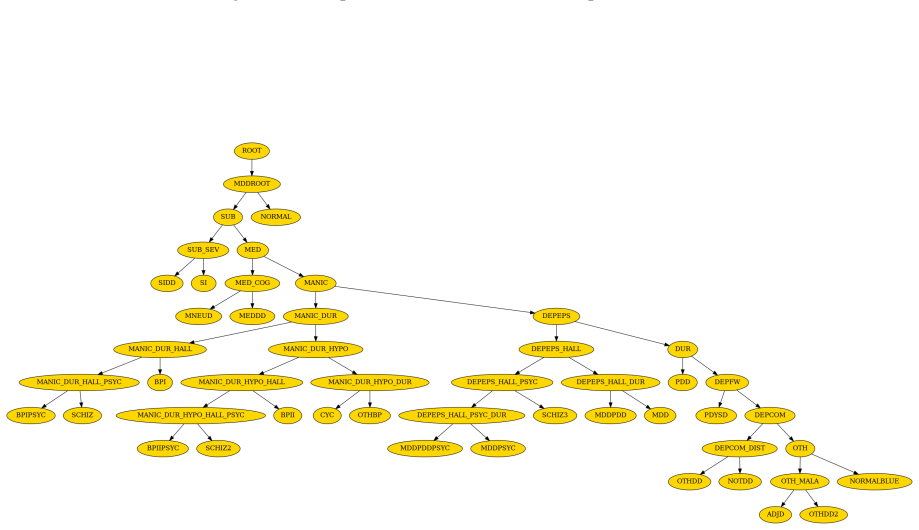
The DSM-5-guided Structured Knowledge Graph that coordinates the Reasonable Mind Agent and Emotional Mind Agent to combine diagnostic logic with empathetic responses.
If this is right
- More accurate identification of critical diagnostic nodes than state-of-the-art single-agent LLM methods.
- Higher rates of correct differential diagnoses across the three tested conditions.
- Generation of responses that psychiatrists rate as both accurate and psychologically supportive.
- Demonstration that AI agents can conduct psychiatric assessments under human oversight.
- Performance that approaches reported ranges for board-certified psychiatrists.
Where Pith is reading between the lines
- The same dual-agent plus knowledge-graph pattern could be adapted to other medical specialties that require both precision and rapport.
- Periodic updates to the knowledge graph would be needed to keep the system aligned with revisions to diagnostic manuals.
- Deployment in real clinics would likely require integration with electronic health records to maintain accuracy on rare or comorbid cases.
- The approach suggests a path for hybrid human-AI teams that could ease workload while preserving clinical judgment.
Load-bearing premise
The combination of virtual standard patients, simulated interactions, and the 180 real user sessions used for evaluation captures the variability, ambiguity, and emotional dynamics of actual clinical psychiatric encounters.
What would settle it
A new test set of several hundred real, unscripted psychiatric interviews with independently confirmed diagnoses where WiseMind's top-1 accuracy falls below 70% or expert-rated supportiveness drops markedly.
Figures









read the original abstract
Large Language Models (LLMs) offer promising opportunities to support mental healthcare workflows, yet they often lack the structured clinical reasoning needed for reliable diagnosis and may struggle to provide the emotionally attuned communication essential for patient trust. Here, we introduce WiseMind, a novel multi-agent framework inspired by the theory of Dialectical Behavior Therapy designed to facilitate psychiatric assessment. By integrating a "Reasonable Mind" Agent for evidence-based logic and an "Emotional Mind" Agent for empathetic communication, WiseMind effectively bridges the gap between instrumental accuracy and humanistic care. Our framework utilizes a Diagnostic and Statistical Manual of Mental Disorders, Fifth Edition (DSM-5)-guided Structured Knowledge Graph to steer diagnostic inquiries, significantly reducing hallucinations compared to standard prompting methods. Using a combination of virtual standard patients, simulated interactions, and real human interaction datasets, we evaluate WiseMind across three common psychiatric conditions. WiseMind outperforms state-of-the-art LLM methods in both identifying critical diagnostic nodes and establishing accurate differential diagnoses. Across 1206 simulated conversations and 180 real user sessions, the system achieves 85.6% top-1 diagnostic accuracy, approaching reported diagnostic performance ranges of board-certified psychiatrists and surpassing knowledge-enhanced single-agent baselines by 15-54 percentage points. Expert review by psychiatrists further validates that WiseMind generates responses that are not only clinically sound but also psychologically supportive, demonstrating the feasibility of empathetic, reliable AI agents to conduct psychiatric assessments under appropriate human oversight.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WiseMind, a multi-agent LLM framework with a Reasonable Mind agent for evidence-based reasoning and an Emotional Mind agent for empathy, steered by a DSM-5 Structured Knowledge Graph. It claims superior performance over baselines in identifying diagnostic nodes and differential diagnoses, with 85.6% top-1 accuracy across 1206 simulated conversations and 180 real user sessions for three psychiatric conditions, plus positive expert psychiatrist ratings for clinical soundness and supportiveness.
Significance. If the evaluation holds, the multi-agent design combined with explicit DSM-5 knowledge guidance offers a concrete step toward reliable AI support for psychiatric assessment that balances diagnostic accuracy with empathetic communication, potentially useful under human oversight in mental health workflows.
major comments (2)
- [Abstract] Abstract and evaluation paragraph: the 85.6% top-1 accuracy aggregates 1206 simulated conversations (where ground truth is known by construction) with 180 real user sessions, yet the manuscript provides no description of how reference diagnoses for the real sessions were obtained (independent clinician review, blinded panel, follow-up, or otherwise) or whether raters were blinded to system outputs. This directly undermines interpretability of the accuracy number and the claim of outperforming baselines by 15-54 points.
- [Evaluation] Evaluation section: no statistical tests, confidence intervals, or inter-rater reliability metrics are reported for the expert psychiatrist reviews or the accuracy comparisons, and exclusion criteria for the real-user dataset are absent; these omissions make it impossible to assess whether the reported gains are robust or sensitive to post-hoc choices.
minor comments (2)
- [Abstract] Abstract: specify the three psychiatric conditions evaluated and the exact definition of 'top-1 diagnostic accuracy' (primary diagnosis only, or including differentials).
- [Methods] The description of the knowledge graph construction and how it reduces hallucinations would benefit from a concrete example or pseudocode.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify key areas where additional methodological detail will strengthen the manuscript. We address each point below and will incorporate the suggested clarifications in the revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation paragraph: the 85.6% top-1 accuracy aggregates 1206 simulated conversations (where ground truth is known by construction) with 180 real user sessions, yet the manuscript provides no description of how reference diagnoses for the real sessions were obtained (independent clinician review, blinded panel, follow-up, or otherwise) or whether raters were blinded to system outputs. This directly undermines interpretability of the accuracy number and the claim of outperforming baselines by 15-54 points.
Authors: We agree that the current manuscript lacks an explicit description of how reference diagnoses were established for the 180 real user sessions and whether blinding was applied. In the revised manuscript we will add a dedicated paragraph in the Evaluation section detailing the ground-truth acquisition process for real sessions (including the role of independent clinicians and any blinding procedures). This addition will directly address the interpretability concern without altering the reported numbers. revision: yes
-
Referee: [Evaluation] Evaluation section: no statistical tests, confidence intervals, or inter-rater reliability metrics are reported for the expert psychiatrist reviews or the accuracy comparisons, and exclusion criteria for the real-user dataset are absent; these omissions make it impossible to assess whether the reported gains are robust or sensitive to post-hoc choices.
Authors: We concur that the absence of statistical tests, confidence intervals, inter-rater reliability metrics, and explicit exclusion criteria limits evaluation of robustness. The revised manuscript will include (i) appropriate statistical tests for accuracy comparisons, (ii) 95% confidence intervals on all reported metrics, (iii) inter-rater reliability statistics (e.g., Cohen’s kappa) for the psychiatrist reviews, and (iv) a clear statement of exclusion criteria applied to the real-user dataset. These additions will be placed in the Evaluation section. revision: yes
Circularity Check
No circularity: empirical metrics from external held-out evaluations
full rationale
The paper describes an empirical system evaluation rather than a mathematical derivation chain. Accuracy figures (85.6% top-1) are obtained by direct comparison of WiseMind outputs against known ground-truth labels on 1206 simulated conversations (labels known by construction) and 180 real sessions (labels obtained externally). No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. The DSM-5 knowledge graph and DBT inspiration are external references, not internal fits. The central performance claims therefore remain independent of the framework's own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A DSM-5-derived structured knowledge graph can steer LLM diagnostic inquiries so that hallucinations are substantially reduced relative to standard prompting
- domain assumption Separating logical reasoning and empathetic communication into distinct agents improves both diagnostic accuracy and perceived supportiveness
Reference graph
Works this paper leans on
-
[1]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Neil Krishan Aggarwal. 2024. The cultural formulation interview in case formulations: A state-of-the-science review. Behavior Therapy
work page 2024
-
[4]
American Psychiatric Association . 2013. Diagnostic and Statistical Manual of Mental Disorders: DSM-5, 5 edition. American Psychiatric Publishing, Arlington, VA
work page 2013
-
[5]
Anthropic. 2023. https://www.anthropic.com/ The claude 3 model family: Opus, sonnet, haiku . Technical report, Anthropic. Accessed: 2025-02-15
work page 2023
-
[6]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng X...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Tracy Butryn, Leah Bryant, Christine Marchionni, and Farhad Sholevar. 2017. The shortage of psychiatrists and other mental health providers: causes, current state, and potential solutions. International Journal of Academic Medicine, 3(1):5--9
work page 2017
-
[8]
Daniel J Carlat. 2005. The psychiatric interview: A practical guide. Lippincott Williams & Wilkins
work page 2005
-
[9]
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. 2024. Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70):1--53
work page 2024
-
[10]
Jan Clusmann, Fiona R. Kolbinger, Hannah S. Muti, Zunamys I. Carrero, Jan-Niklas Eckardt, Narmin Ghaffari Laleh, Chiara M. L. Löffler, Sophie-Caroline Schwarzkopf, Michaela Unger, Gregory P. Veldhuizen, Sophia J. Wagner, and Jakob Nikolas Kather. 2023. https://doi.org/10.1038/s43856-023-00370-1 The future landscape of large language models in medicine . C...
-
[11]
Eleanor Croxford, Yu Gao, Nicholas Pellegrino, et al. 2025. https://doi.org/10.1038/s44401-024-00011-2 Current and future state of evaluation of large language models for medical summarization tasks . npj Health Systems, 2(6)
-
[12]
Jane Dacre, Mike Besser, Patricia White, et al. 2003. Mrcp (uk) part 2 clinical examination (paces): a review of the first four examination sessions (june 2001--july 2002). Clinical Medicine, 3(5):452--459
work page 2003
-
[13]
Kusal K Das. 2023. Graduate medical education: variation of program and training duration. Korean Journal of Medical Education, 35(4):421
work page 2023
-
[14]
Steeves Demazeux and Patrick Singy. 2015. The DSM-5 in perspective. Springer
work page 2015
-
[15]
Michael B First. 2013. DSM-5-TR Handbook of Differential Diagnosis . American Psychiatric Pub
work page 2013
-
[16]
Kathleen Kara Fitzpatrick, Alison Darcy, and Molly Vierhile. 2017. Delivering cognitive behavior therapy to young adults with symptoms of depression and anxiety using a fully automated conversational agent (woebot): a randomized controlled trial. JMIR mental health, 4(2):e7785
work page 2017
-
[17]
Centre for Addiction and Mental Health. 2025. https://www.camh.ca/-/media/education-files/clinical-psychology-practicum-program-brochure.pdf Clinical practicum training program in psychology . Accessed: 2025-02-13
work page 2025
-
[18]
Sebastian Freidel and Emanuel Schwarz. 2025. Knowledge graphs in psychiatric research: Potential applications and future perspectives. Acta Psychiatrica Scandinavica, 151(3):180--191
work page 2025
-
[19]
Thomas F Hughes. 1992. The importance of being empathic. JAMA, 267(3):366--366
work page 1992
-
[20]
Becky Inkster, Shubhankar Sarda, Vinod Subramanian, et al. 2018. An empathy-driven, conversational artificial intelligence agent (wysa) for digital mental well-being: real-world data evaluation mixed-methods study. JMIR mHealth and uHealth, 6(11):e12106
work page 2018
-
[21]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. https://arxiv.org/abs/2310.0...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Elma Kerz, Sourabh Zanwar, Yu Qiao, and Daniel Wiechmann. 2023. Toward explainable ai (xai) for mental health detection based on language behavior. Frontiers in psychiatry, 14:1219479
work page 2023
-
[23]
Yubin Kim, Chanwoo Park, Hyewon Jeong, Yik S Chan, Xuhai Xu, Daniel McDuff, Hyeonhoon Lee, Marzyeh Ghassemi, Cynthia Breazeal, and Hae W Park. 2024. Mdagents: An adaptive collaboration of llms for medical decision-making. Advances in Neural Information Processing Systems, 37:79410--79452
work page 2024
-
[24]
Ann King and Ruth B Hoppe. 2013. “best practice” for patient-centered communication: a narrative review. Journal of graduate medical education, 5(3):385--393
work page 2013
-
[25]
Marsha M. Linehan. 1993. Cognitive–Behavioral Treatment of Borderline Personality Disorder. Guilford Press, New York, NY
work page 1993
-
[26]
Ming Y Lu, Bowen Chen, Drew FK Williamson, Richard J Chen, Melissa Zhao, Aaron K Chow, Kenji Ikemura, Ahrong Kim, Dimitra Pouli, Ankush Patel, et al. 2024. A multimodal generative ai copilot for human pathology. Nature, 634(8033):466--473
work page 2024
-
[27]
Kaining Mao, Deborah Baofeng Wang, Tiansheng Zheng, Rongqi Jiao, Yanhui Zhu, Bin Wu, Lei Qian, Wei Lyu, Jie Chen, and Minjie Ye. 2023. Analysis of automated clinical depression diagnosis in a chinese corpus. IEEE Transactions on Biomedical Circuits and Systems, 17(5):1135--1152
work page 2023
-
[28]
Daniel McDuff, Mike Schaekermann, Tao Tu, Anil Palepu, Amy Wang, Jake Garrison, Karan Singhal, Yash Sharma, Shekoofeh Azizi, Kavita Kulkarni, et al. 2025. Towards accurate differential diagnosis with large language models. Nature, pages 1--7
work page 2025
-
[29]
u ller, Oliver Hinz, and Max M \
Christian Meurisch, Cristina A Mihale-Wilson, Adrian Hawlitschek, Florian Giger, Florian M \"u ller, Oliver Hinz, and Max M \"u hlh \"a user. 2020. Exploring user expectations of proactive ai systems. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 4(4):1--22
work page 2020
-
[30]
Julie Nordgaard, Louis A Sass, and Josef Parnas. 2013. The psychiatric interview: validity, structure, and subjectivity. European archives of psychiatry and clinical neuroscience, 263:353--364
work page 2013
-
[31]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Travis J Pashak and Michael R Heron. 2022. Build rapport and collect data: A teaching resource on the clinical interviewing intake. Discover Psychology, 2(1):20
work page 2022
-
[33]
Darrel A Regier, Emily A Kuhl, and David J Kupfer. 2013 a . The dsm-5: Classification and criteria changes. World psychiatry, 12(2):92--98
work page 2013
-
[34]
Darrel A. Regier, William E. Narrow, Diana E. Clarke, Helena C. Kraemer, S. Janet Kuramoto, Emily A. Kuhl, and David J. Kupfer. 2013 b . https://doi.org/10.1176/appi.ajp.2012.12070999 Dsm-5 field trials in the united states and canada, part ii: Test-retest reliability of selected categorical diagnoses . American Journal of Psychiatry, 170(1):59--70. PMID:...
-
[35]
Christopher Robertson, Andrew Woods, Kelly Bergstrand, Jess Findley, Cayley Balser, and Marvin J Slepian. 2023. Diverse patients’ attitudes towards artificial intelligence (ai) in diagnosis. PLOS Digital Health, 2(5):e0000237
work page 2023
-
[36]
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. 2023. Large language models encode clinical knowledge. Nature, 620(7972):172--180
work page 2023
-
[37]
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R Pfohl, Heather Cole-Lewis, et al. 2025. Toward expert-level medical question answering with large language models. Nature Medicine, pages 1--8
work page 2025
-
[38]
Christopher R Thomas and CHARLES E HOLZER III. 2006. The continuing shortage of child and adolescent psychiatrists. Journal of the American Academy of Child & Adolescent Psychiatry, 45(9):1023--1031
work page 2006
-
[39]
Eric J. Topol. 2019. https://doi.org/10.1038/s41591-018-0300-7 High-performance medicine: the convergence of human and artificial intelligence . Nature Medicine, 25(1):44--56
-
[40]
Geng Tu, Jun Wang, Zhenyu Li, Shiwei Chen, Bin Liang, Xi Zeng, Min Yang, and Ruifeng Xu. 2024. Multiple knowledge-enhanced interactive graph network for multimodal conversational emotion recognition. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 3861--3874
work page 2024
-
[41]
Tao Tu, Mike Schaekermann, Anil Palepu, Khaled Saab, Jan Freyberg, Ryutaro Tanno, Amy Wang, Brenna Li, Mohamed Amin, Yong Cheng, et al. 2025. Towards conversational diagnostic artificial intelligence. Nature, pages 1--9
work page 2025
-
[42]
Wilson, Andrea Forte, Grace Huynh, et al
Stephen L. Wilson, Andrea Forte, Grace Huynh, et al. 2021. https://doi.org/10.1016/S2589-7500(21)00160-1 Ethical principles for artificial intelligence in health . The Lancet Digital Health, 3(6):e425--e427
-
[43]
Honghan Wu, Meng Wang, Jinming Wu, and et al. 2022. https://doi.org/10.1038/s41746-022-00730-6 A survey on clinical natural language processing in the united kingdom from 2007 to 2022 . npj Digital Medicine, 5:186
-
[44]
Yuqi Wu, Jie Chen, Kaining Mao, and Yanbo Zhang. 2023. Automatic post-traumatic stress disorder diagnosis via clinical transcripts: a novel text augmentation with large language models. In 2023 IEEE Biomedical Circuits and Systems Conference (BioCAS), pages 1--5. IEEE
work page 2023
-
[45]
Yuqi Wu, Kaining Mao, Yanbo Zhang, and Jie Chen. 2024. Callm: Enhancing clinical interview analysis through data augmentation with large language models. IEEE Journal of Biomedical and Health Informatics
work page 2024
-
[46]
Chonghua Xue, Sahana S Kowshik, Diala Lteif, Shreyas Puducheri, Varuna H Jasodanand, Olivia T Zhou, Anika S Walia, Osman B Guney, J Diana Zhang, Serena T Pham, et al. 2024. Ai-based differential diagnosis of dementia etiologies on multimodal data. Nature Medicine, 30(10):2977--2989
work page 2024
- [47]
-
[48]
Rui Yang, Ting Fang Tan, Wei Lu, Arun J. Thirunavukarasu, Daniel S. W. Ting, and Nan Liu. 2023. https://doi.org/10.1002/hcs2.61 Large language models in health care: Development, applications, and challenges . Health Care Science, 2(4):255--263
-
[49]
Kaiyan Zhang, Ning Ding, Biqing Qi, Sihang Zeng, Haoxin Li, Xuekai Zhu, Zhang-Ren Chen, and Bowen Zhou. 2024. Ultramedical: Building specialized generalists in biomedicine. https://github.com/TsinghuaC3I/UltraMedical
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.