Privacy-Preserving Empathy Detection in Video Interactions
Pith reviewed 2026-05-22 20:46 UTC · model grok-4.3
The pith
Summary statistics of visual features suffice for subject-generalizable empathy detection under strong privacy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
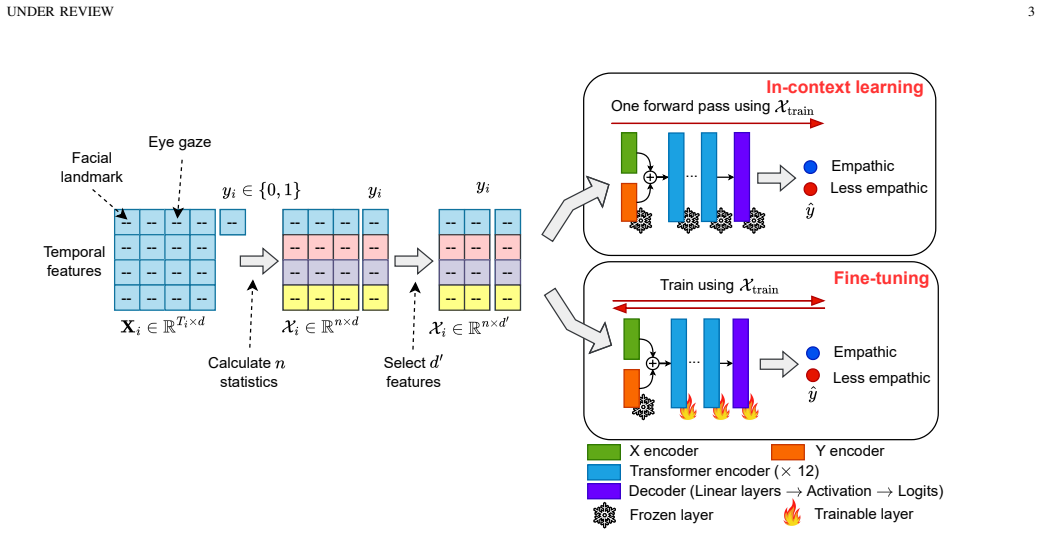
Strong, subject-generalisable empathy detection is achievable at the strong-privacy level. TFMPathy, built with tabular foundation models TabPFN v2 and TabICL under in-context learning and fine-tuning, reaches accuracy 0.730 and AUC 0.669 on a public human-robot interaction benchmark under a new cross-subject protocol, outperforming baselines while summary statistics suppress demographic information.
What carries the argument
TFMPathy, the application of tabular foundation models to summary statistics of temporal visual features for privacy-constrained prediction.
If this is right
- Empathy detection becomes feasible in settings that prohibit raw video sharing.
- Cross-subject protocols provide a stricter test of generalisation than prior splits.
- Feature aggregation aligns model training with data-minimisation rules by reducing identifiable cues.
- Tabular foundation models offer a practical method for behavioural prediction when only aggregates are available.
- The approach supports AI deployment under institutional or consent restrictions on video data.
Where Pith is reading between the lines
- The same summary-statistic pipeline could be applied to other behavioural signals such as engagement or stress in privacy-sensitive domains.
- Collaborative research might standardise on aggregate feature releases rather than raw or landmark streams.
- Testing on datasets with wider demographic range would check whether cue suppression holds beyond the current benchmark.
- Combining the tabular models with other modalities could further improve utility without relaxing privacy constraints.
Load-bearing premise
The summary statistics of temporal visual features retain enough signal for empathy prediction across subjects after aggregation removes most individual detail.
What would settle it
A new cross-subject test on the same or similar benchmark where no model using only summary statistics exceeds chance-level accuracy would falsify the central claim.
Figures


read the original abstract
Detecting empathy from video interactions has emerging applications, yet raw videos that could be used for training AI models are rarely available due to privacy and ethical constraints. Public benchmarks are consequently released only as pre-extracted features, creating a privacy-constrained learning regime whose privacy-utility trade-off is poorly characterised. We formalise three levels of privacy for video-based behavioural prediction -- no privacy (raw video), partial privacy (temporal visual features such as facial landmarks, action units and eye gaze) and strong privacy (summary statistics of those features) -- and ask whether strong, subject-generalisable empathy detection is achievable at the strong-privacy level. We propose TFMPathy, instantiated with two recent Tabular Foundation Models (TFMs) (TabPFN v2 and TabICL), under both in-context learning and fine-tuning paradigms. On a public human-robot interaction benchmark, TFMPathy achieves strong utility under strong privacy, outperforming established baselines by a substantial margin. To assess robustness and facilitate fair, safe deployment, we introduce a cross-subject evaluation protocol that was previously lacking in this benchmark. Under this protocol, TFM fine-tuning improves generalisation capacity substantially (accuracy: $0.590 \rightarrow 0.730$; AUC: $0.564 \rightarrow 0.669$). Aggregating temporal features into summary statistics also suppresses subject-specific and demographic cues, aligning TFMPathy with data-minimisation principles. TFMPathy, therefore, offers a practical route to building AI systems that depend on human-centred video when governance, consent or institutional policies restrict the sharing of raw video. Code will be released upon acceptance at https://github.com/hasan-rakibul/TFMPathy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formalizes three privacy levels for video-based empathy detection (no privacy: raw video; partial: temporal visual features; strong: summary statistics of landmarks/AUs/gaze) and proposes TFMPathy, which applies recent tabular foundation models (TabPFN v2, TabICL) under in-context learning and fine-tuning. On a public human-robot interaction benchmark it reports that fine-tuning yields accuracy gains from 0.590 to 0.730 and AUC gains from 0.564 to 0.669 under a newly introduced cross-subject protocol, while the aggregation step suppresses subject-specific and demographic cues.
Significance. If the reported gains are robust, the work would demonstrate that strong-privacy summary statistics can support subject-generalizable empathy prediction, providing a practical route for affective computing under data-minimisation constraints. The cross-subject protocol and use of tabular foundation models are timely contributions; explicit code release would further strengthen reproducibility.
major comments (2)
- [strong-privacy definition and results paragraph] The central claim that summary statistics preserve enough cross-subject empathy signal (abstract, strong-privacy definition) is load-bearing for the utility results. The manuscript should include an ablation or variance decomposition showing how much empathy-related variance remains after aggregation versus subject-specific components; without it the 0.140 accuracy and 0.105 AUC lifts cannot be confidently attributed to retained temporal dynamics rather than benchmark idiosyncrasies.
- [evaluation and results sections] Baseline implementations, dataset subject count, statistical significance tests, and exact aggregation functions (means, variances, etc.) are not detailed enough to reproduce or interpret the 'substantial margin' over established baselines. These omissions directly affect whether the cross-subject protocol improvements are generalizable.
minor comments (2)
- [abstract and introduction] Define all acronyms (TFM, AUC, TFMPathy) on first use and ensure consistent notation for the three privacy levels throughout.
- [results] Clarify whether the reported numbers are from a single run or averaged over multiple seeds; add error bars or confidence intervals to the accuracy/AUC figures.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects for strengthening the manuscript's claims and reproducibility. We respond to each major comment below.
read point-by-point responses
-
Referee: [strong-privacy definition and results paragraph] The central claim that summary statistics preserve enough cross-subject empathy signal (abstract, strong-privacy definition) is load-bearing for the utility results. The manuscript should include an ablation or variance decomposition showing how much empathy-related variance remains after aggregation versus subject-specific components; without it the 0.140 accuracy and 0.105 AUC lifts cannot be confidently attributed to retained temporal dynamics rather than benchmark idiosyncrasies.
Authors: We agree that stronger evidence is needed to attribute the gains specifically to retained empathy signals. The manuscript demonstrates suppression of subject-specific and demographic cues via aggregation, which correlates with the observed cross-subject improvements. However, a dedicated variance decomposition was not included. We will add an ablation comparing aggregated vs. non-aggregated features and a discussion of variance components based on the available benchmark data. This constitutes a partial revision, as a complete decomposition may require supplementary experiments beyond the current scope. revision: partial
-
Referee: [evaluation and results sections] Baseline implementations, dataset subject count, statistical significance tests, and exact aggregation functions (means, variances, etc.) are not detailed enough to reproduce or interpret the 'substantial margin' over established baselines. These omissions directly affect whether the cross-subject protocol improvements are generalizable.
Authors: We acknowledge these omissions limit reproducibility. In the revised version we will expand the evaluation and results sections to specify: baseline implementations in full detail, the exact subject count in the benchmark, statistical significance tests (e.g., McNemar's test or paired t-tests on the reported metrics), and the precise aggregation functions (means, variances, and any other statistics). The planned code release will provide the exact implementations for verification. revision: yes
Circularity Check
No circularity: empirical results on public benchmark are independent of inputs
full rationale
The paper presents an empirical evaluation of TFMPathy on a public human-robot interaction benchmark, reporting performance gains under a cross-subject protocol (accuracy 0.590→0.730, AUC 0.564→0.669) after defining privacy levels and applying tabular foundation models to summary statistics. No equations, derivations, or self-citations reduce these results to quantities defined by the paper's own fitted parameters or inputs by construction. The formalization of strong-privacy aggregation and the choice of in-context learning/fine-tuning are external modeling decisions tested against held-out subject splits, leaving the central claim falsifiable on the benchmark rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Summary statistics of temporal visual features preserve enough information for subject-generalizable empathy detection.
invented entities (1)
-
TFMPathy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Modeling user empathy elicited by a robot storyteller,
L. Mathur, M. Spitale, H. Xi, J. Li, and M. J. Matari ´c, “Modeling user empathy elicited by a robot storyteller,” in 2021 9th International Conference on Affective Computing and Intelligent Interaction (ACII) , 2021, pp. 1–8. DOI: 10.1109/ACII52823.2021.9597416
-
[2]
M. H. Davis, Empathy: A Social Psychological Approach , 1st. Rout- ledge, 1996. DOI: 10.4324/9780429493898
-
[3]
M. L. Hoffman, Empathy and Moral Development: Implications for Caring and Justice . Cambridge University Press, 2000. DOI: 10.1017/ CBO9780511805851
work page 2000
-
[4]
Empathy training in health sciences: A systematic review,
P. Bas-Sarmiento, M. Fern ´andez-Guti´errez, M. Baena-Ba ˜nos, A. Correro-Bermejo, P. S. Soler-Martins, and S. de la Torre-Moyano, “Empathy training in health sciences: A systematic review,” Nurse Education in Practice , vol. 44, p. 102 739, 2020. DOI: 10 . 1016 / j . nepr.2020.102739
-
[5]
M. R. Hasan, M. Z. Hossain, S. Ghosh, A. Krishna, and T. Gedeon, “Empathy detection from text, audiovisual, audio or physiological signals: A systematic review of task formulations and machine learning methods,” IEEE Transactions on Affective Computing, pp. 1–20, 2025. DOI: 10.1109/TAFFC.2025.3590107
-
[6]
Modeling empathy and distress in reaction to news stories,
S. Buechel, A. Buffone, B. Slaff, L. Ungar, and J. Sedoc, “Modeling empathy and distress in reaction to news stories,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Pro- cessing, Brussels, Belgium: Association for Computational Linguistics, Oct. 2018, pp. 4758–4765. DOI: 10.18653/v1/D18-1507
-
[7]
Modeling empathic similarity in personal narratives,
J. Shen, M. Sap, P. Colon-Hernandez, H. Park, and C. Breazeal, “Modeling empathic similarity in personal narratives,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds., Singapore: Association for Computational Linguistics, Dec. 2023, pp. 6237–6252. DOI: 10.18653/v1/2023.emnlp-main.383
-
[8]
The omg-empathy dataset: Evaluating the impact of affective behavior in storytelling,
P. Barros, N. Churamani, A. Lim, and S. Wermter, “The omg-empathy dataset: Evaluating the impact of affective behavior in storytelling,” in 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII) , IEEE, 2019, pp. 1–7. DOI: 10 . 1109 / ACII.2019.8925530
-
[9]
It takes two to empathize: One to seek and one to provide,
M. Hosseini and C. Caragea, “It takes two to empathize: One to seek and one to provide,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, 2021, pp. 13 018–13 026. DOI: 10.1609/ aaai.v35i14.17539
work page 2021
-
[10]
A theory of narrative empathy,
S. Keen, “A theory of narrative empathy,” Narrative, vol. 14, no. 3, pp. 207–236, 2006
work page 2006
-
[11]
Socially assistive robots as storytellers that elicit empathy,
M. Spitale, S. Okamoto, M. Gupta, H. Xi, and M. J. Matari ´c, “Socially assistive robots as storytellers that elicit empathy,” ACM Transactions on Human-Robot Interaction, vol. 11, no. 4, Sep. 2022. DOI: 10.1145/ 3538409. UNDER REVIEW 9
work page 2022
-
[12]
Tabpfn: A transformer that solves small tabular classification problems in a second,
N. Hollmann, S. M ¨uller, K. Eggensperger, and F. Hutter, “Tabpfn: A transformer that solves small tabular classification problems in a second,” in Proceedings of the International Conference on Learning Representations (ICLR’23), 2023
work page 2023
-
[13]
Accurate predictions on small data with a tab- ular foundation model.Nature, 637(8045):319–326, 2025
N. Hollmann, S. M ¨uller, L. Purucker, et al., “Accurate predictions on small data with a tabular foundation model,”Nature, vol. 637, no. 8045, pp. 319–326, 2025. DOI: 10.1038/s41586-024-08328-6
-
[14]
Tabllm: Few-shot classification of tabular data with large language models,
S. Hegselmann, A. Buendia, H. Lang, M. Agrawal, X. Jiang, and D. Sontag, “Tabllm: Few-shot classification of tabular data with large language models,” in Proceedings of the 26th International Conference on Artificial Intelligence and Statistics, F. Ruiz, J. Dy, and J.-W. van de Meent, Eds., ser. Proceedings of Machine Learning Research, vol. 206, PMLR, Ap...
work page 2023
-
[15]
Large language models (llms) on tabular data: Prediction, generation, and understanding - A survey,
X. Fang, W. Xu, F. A. Tan, et al., “Large language models (llms) on tabular data: Prediction, generation, and understanding - A survey,” Transactions on Machine Learning Research , vol. 2024, 2024
work page 2024
-
[16]
Transformers can do bayesian inference,
S. M ¨uller, N. Hollmann, S. Pineda-Arango, J. Grabocka, and F. Hutter, “Transformers can do bayesian inference,” in Proceedings of the Tenth International Conference on Learning Representations (ICLR’22), OpenReview.net, 2022
work page 2022
-
[17]
J. Qu, D. Holzm ¨uller, G. Varoquaux, and M. L. Morvan, Tabicl: A tabular foundation model for in-context learning on large data , 2025
work page 2025
-
[18]
An empirical study of gpt-3 for few-shot knowledge-based vqa,
Z. Yang, Z. Gan, J. Wang, et al. , “An empirical study of gpt-3 for few-shot knowledge-based vqa,” Proceedings of the AAAI Conference on Artificial Intelligence , vol. 36, no. 3, pp. 3081–3089, Jun. 2022. DOI: 10.1609/aaai.v36i3.20215
-
[19]
Emotion recognition toolkit (ertk): Standardising tools for emotion recognition research,
A. Keesing, Y . S. Koh, V . Yogarajan, and M. Witbrock, “Emotion recognition toolkit (ertk): Standardising tools for emotion recognition research,” in Proceedings of the 31st ACM International Conference on Multimedia , New York, NY , USA: Association for Computing Machinery, 2023, pp. 9693–9696. DOI: 10.1145/3581783.3613459
-
[20]
M. R. Hasan, M. Z. Hossain, T. Gedeon, S. Soon, and S. Rahman, “Curtin OCAI at W ASSA 2023 empathy, emotion and personality shared task: Demographic-aware prediction using multiple transform- ers,” in Proceedings of the 13th Workshop on Computational Ap- proaches to Subjectivity, Sentiment, & Social Media Analysis , Toronto, Canada: Association for Comput...
work page 2023
-
[21]
DOI: 10.18653/v1/2023.wassa-1.47
-
[22]
Identifying empathetic messages in online health communities,
H. Khanpour, C. Caragea, and P. Biyani, “Identifying empathetic messages in online health communities,” in Proceedings of the Eighth International Joint Conference on Natural Language Processing (Vol- ume 2: Short Papers) , Taipei, Taiwan: Asian Federation of Natural Language Processing, Nov. 2017, pp. 246–251
work page 2017
-
[23]
LeadEmpathy: An expert annotated German dataset of empathy in written leadership communication,
D. Sedefoglu, A. C. Lahnala, J. Wagner, L. Flek, and S. Ohly, “LeadEmpathy: An expert annotated German dataset of empathy in written leadership communication,” in Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , N. Calzolari, M.-Y . Kan, V . Hoste, A. Lenci, S. Sakt...
work page 2024
-
[24]
Empathizing with virtual agents: The effect of personification and general empathic tendencies,
K. Kroes, I. Saccardi, and J. Masthoff, “Empathizing with virtual agents: The effect of personification and general empathic tendencies,” in 2022 IEEE International Conference on Artificial Intelligence and Virtual Reality (AIVR) , IEEE, 2022, pp. 73–81. DOI: 10 . 1109 / AIVR56993.2022.00017
-
[25]
Multimodal learning for identifying opportunities for em- pathetic responses,
L. Tavabi, K. Stefanov, S. Nasihati Gilani, D. Traum, and M. So- leymani, “Multimodal learning for identifying opportunities for em- pathetic responses,” in 2019 International Conference on Multimodal Interaction, 2019, pp. 95–104. DOI: 10.1145/3340555.3353750
-
[26]
Y . Pan, J. Wu, R. Ju, et al., “A multimodal framework for automated teaching quality assessment of one-to-many online instruction videos,” in 2022 26th International Conference on Pattern Recognition (ICPR) , IEEE, 2022, pp. 1777–1783. DOI: 10.1109/icpr56361.2022.9956185
-
[27]
A learning system to support social and empathy disor- ders diagnosis through affective avatars,
R. Herv ´as, E. Johnson, C. G. L. de la Franca, J. Bravo, and T. Mond´ejar, “A learning system to support social and empathy disor- ders diagnosis through affective avatars,” in 2016 15th International Conference on Ubiquitous Computing and Communications and 2016 International Symposium on Cyberspace and Security (IUCC-CSS) , IEEE, 2016, pp. 93–100. DOI:...
-
[28]
MEDIC: A multimodal empathy dataset in counseling,
Z. Zhu, C. Li, J. Pan, et al., “MEDIC: A multimodal empathy dataset in counseling,” in Proceedings of the 31st ACM International Conference on Multimedia , New York, NY , USA: Association for Computing Machinery, 2023, pp. 6054–6062. DOI: 10.1145/3581783.3612346
-
[29]
EmpathicStories++: A multimodal dataset for empathy towards personal experiences,
J. Shen, Y . Kim, M. Hulse, et al., “EmpathicStories++: A multimodal dataset for empathy towards personal experiences,” in Findings of the Association for Computational Linguistics: ACL 2024 , L.-W. Ku, A. Martins, and V . Srikumar, Eds., Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 4525–4536. DOI: 10.18653/ v1/2024.finding...
work page 2024
-
[30]
M. R. Hasan, Y . Yao, M. Z. Hossain, et al., Labels generated by large language models help measure people’s empathy in vitro , 2025
work page 2025
-
[31]
RU at W ASSA 2024 shared task: Task-aligned prompt for predicting empathy and distress,
H. Kong and S. Moon, “RU at W ASSA 2024 shared task: Task-aligned prompt for predicting empathy and distress,” inProceedings of the 14th Workshop on Computational Approaches to Subjectivity, Sentiment, & Social Media Analysis, O. De Clercq, V . Barriere, J. Barnes, R. Klinger, J. Sedoc, and S. Tafreshi, Eds., Bangkok, Thailand: Association for Computation...
work page 2024
-
[32]
M. R. Hasan, M. Z. Hossain, T. Gedeon, and S. Rahman, “LLM- GEm: Large language model-guided prediction of people’s empathy levels towards newspaper article,” in Findings of the Association for Computational Linguistics: EACL 2024 , Y . Graham and M. Purver, Eds., St. Julian’s, Malta: Association for Computational Linguistics, Mar. 2024, pp. 2215–2231
work page 2024
-
[33]
HIT-SCIR at W ASSA 2023: Empathy and emotion analysis at the utterance-level and the essay-level,
X. Lu, Z. Li, Y . Tong, Y . Zhao, and B. Qin, “HIT-SCIR at W ASSA 2023: Empathy and emotion analysis at the utterance-level and the essay-level,” in Proceedings of the 13th Workshop on Computational Approaches to Subjectivity, Sentiment, & Social Media Analysis , Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 574–580. DOI: 10.1...
-
[34]
R. Frick and M. Steinebach, “Fraunhofer SIT at W ASSA 2024 empathy and personality shared task: Use of sentiment transformers and data augmentation with fuzzy labels to predict emotional reactions in conversations and essays,” in Proceedings of the 14th Workshop on Computational Approaches to Subjectivity, Sentiment, & Social Media Analysis, O. De Clercq,...
-
[35]
van Rijn, Bernd Bischl, and Luis Torgo
J. Vanschoren, J. N. van Rijn, B. Bischl, and L. Torgo, “Openml: Networked science in machine learning,” SIGKDD Explor. Newsl. , vol. 15, no. 2, pp. 49–60, Jun. 2014. DOI: 10.1145/2641190.2641198
-
[36]
OpenFace: A general-purpose face recognition library with mobile applications,
B. Amos, B. Ludwiczuk, M. Satyanarayanan, et al. , “OpenFace: A general-purpose face recognition library with mobile applications,” CMU School of Computer Science , vol. 6, no. 2, p. 20, 2016
work page 2016
-
[37]
Optuna: A next-generation hyperparameter optimization framework,
T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama, “Optuna: A next-generation hyperparameter optimization framework,” in Proceed- ings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining , 2019, pp. 2623–2631. DOI: 10 . 1145 / 3292500.3330701
-
[38]
A. Defazio, X. Yang, H. Mehta, K. Mishchenko, A. Khaled, and A. Cutkosky, The road less scheduled , 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.