Partner Modelling Emerges in Recurrent Agents (But Only When It Matters)
Pith reviewed 2026-05-22 13:10 UTC · model grok-4.3
The pith
Simple recurrent agents develop internal models of partners' abilities during collaboration, but only when they can control task allocation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Despite a lack of additional architectural features, inductive biases, or auxiliary objectives, the agents nevertheless develop structured internal representations of their partners' task abilities, enabling rapid adaptation and generalisation to novel collaborators. Notably, we find that structured partner modelling emerges when agents can influence partner behaviour by controlling task allocation.
What carries the argument
The hidden states of the recurrent agents, which develop structured encodings of partners' task abilities specifically when agents can control task allocation.
If this is right
- Agents adapt rapidly to novel collaborators using their internal models.
- Generalization to new partners occurs without explicit training for social understanding.
- Structured partner modeling arises spontaneously from the pressures of open-ended cooperative interaction.
- Modeling does not emerge in conditions where agents cannot influence partner behavior through task allocation.
Where Pith is reading between the lines
- Environmental designs that give agents control over shared tasks may be key to fostering implicit social understanding in AI systems.
- This emergence suggests that basic recurrent processing combined with appropriate interaction pressures can produce theory-of-mind-like abilities without dedicated modules.
- Similar partner modeling might appear in other cooperative environments where one agent can direct the actions of others.
Load-bearing premise
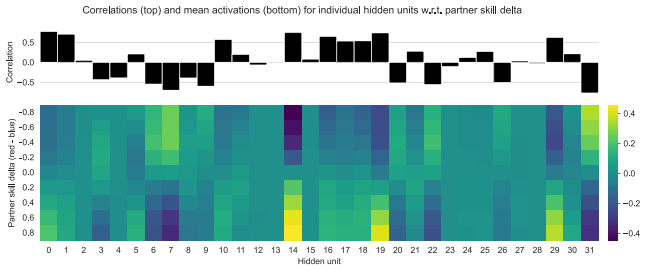
The structured patterns in the agents' hidden states specifically encode models of partners' task abilities rather than other correlated features, and this emergence is caused by the ability to control task allocation.
What would settle it
An experiment showing that agents without task allocation control develop the same structured representations in their hidden states, or that the representations do not specifically predict partner abilities when probed.
Figures






read the original abstract
Humans are remarkably adept at collaboration, able to infer the strengths and weaknesses of new partners in order to work successfully towards shared goals. To build AI systems with this capability, we must first understand its building blocks: does such flexibility require explicit, dedicated mechanisms for modelling others -- or can it emerge spontaneously from the pressures of open-ended cooperative interaction? To investigate this question, we train simple model-free RNN agents to collaborate with a population of diverse partners. Using the `Overcooked-AI' environment, we collect data from thousands of collaborative teams, and analyse agents' internal hidden states. Despite a lack of additional architectural features, inductive biases, or auxiliary objectives, the agents nevertheless develop structured internal representations of their partners' task abilities, enabling rapid adaptation and generalisation to novel collaborators. We investigated these internal models through probing techniques, and large-scale behavioural analysis. Notably, we find that structured partner modelling emerges when agents can influence partner behaviour by controlling task allocation. Our results show that partner modelling can arise spontaneously in model-free agents -- but only under environmental conditions that impose the right kind of social pressure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript trains simple model-free RNN agents to collaborate with diverse partners in the Overcooked-AI environment. It analyzes agents' hidden states via probing techniques and large-scale behavioral comparisons, claiming that structured internal representations of partners' task abilities emerge spontaneously without dedicated architectures or auxiliary objectives, enabling rapid adaptation and generalization to novel collaborators. This structured partner modelling arises specifically when agents can influence partner behavior through control of task allocation.
Significance. If the central empirical claims hold after addressing potential confounds, the work provides evidence that partner modelling can emerge from general cooperative pressures in recurrent agents. This strengthens understanding of how social inference capabilities arise in multi-agent RL without explicit inductive biases, with potential implications for designing flexible collaborative AI systems. The combination of probing and behavioral analysis offers a concrete empirical approach to studying emergent representations.
major comments (2)
- [§4.3] §4.3 (Experimental Conditions): The claim that structured hidden-state patterns specifically encode models of partners' task abilities and emerge because of task-allocation control requires explicit verification that the controllable and non-controllable regimes differ only on that dimension. Partner population statistics, action variability, observability, episode length, and reward structure must be shown to be matched; otherwise, probing accuracy may reflect forecasting of altered dynamics rather than partner-ability inference.
- [§5.1] §5.1 (Probing Analysis): The probing classifiers should include controls or ablations for correlated task and environmental features (e.g., current state or partner action history) to establish that the high prediction accuracy for task abilities is not driven by these confounds. Without such controls, the interpretation that the representations are partner models remains under-supported.
minor comments (2)
- [Abstract and Methods] The abstract and methods section would benefit from reporting the exact number of agents trained, total episodes collected, and statistical tests used for behavioral comparisons to improve reproducibility.
- [Figures] Figure captions for hidden-state visualizations should include details on dimensionality reduction method, clustering algorithm, and color-coding scheme for partner types.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important requirements for verifying experimental controls and strengthening the probing analysis. We address each point below and have revised the manuscript accordingly to provide the requested verifications and ablations.
read point-by-point responses
-
Referee: [§4.3] §4.3 (Experimental Conditions): The claim that structured hidden-state patterns specifically encode models of partners' task abilities and emerge because of task-allocation control requires explicit verification that the controllable and non-controllable regimes differ only on that dimension. Partner population statistics, action variability, observability, episode length, and reward structure must be shown to be matched; otherwise, probing accuracy may reflect forecasting of altered dynamics rather than partner-ability inference.
Authors: We agree that explicit verification of matched conditions is necessary to support the causal role of task-allocation control. Both regimes used identical partner populations (the same fixed set of 10 diverse RNN partners), the same Overcooked layouts, identical episode lengths (400 steps), and the same reward structure. Observability is matched as both conditions provide full state visibility. To address action variability, we have added a new analysis in the revised §4.3 comparing partner action entropy and transition statistics across conditions, confirming they are statistically equivalent when averaged over shared tasks. A table summarizing these matches has been included to rule out confounds from altered dynamics. revision: yes
-
Referee: [§5.1] §5.1 (Probing Analysis): The probing classifiers should include controls or ablations for correlated task and environmental features (e.g., current state or partner action history) to establish that the high prediction accuracy for task abilities is not driven by these confounds. Without such controls, the interpretation that the representations are partner models remains under-supported.
Authors: We concur that controls are required to isolate partner-ability encoding from immediate task or environmental features. In the revised manuscript, we have added ablation probes trained on the current environment state vector and on a 10-step history of partner actions. These controls yield substantially lower accuracy for predicting partner task abilities (approximately 65% versus 88% for the RNN hidden states). These results are now reported in §5.1 with statistical comparisons, supporting that the hidden-state representations capture partner-specific information beyond correlated task and action features. revision: yes
Circularity Check
No circularity in empirical emergence claims
full rationale
The paper reports results from training model-free RNN agents in Overcooked-AI, followed by probing of hidden states and large-scale behavioral comparisons across experimental conditions. No mathematical derivations, first-principles results, or equations are presented that reduce to their inputs by construction. The central finding—that structured partner modeling emerges specifically when agents control task allocation—is supported by direct empirical contrasts rather than self-definitional structures, fitted parameters renamed as predictions, or load-bearing self-citations. Any self-citations serve only as background and do not substitute for the current experimental evidence, which remains independently falsifiable via replication of the training and probing pipeline.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Beyond the Assistant Turn: User Turn Generation as a Probe of Interaction Awareness in Language Models
User-turn generation reveals that LLMs' interaction awareness is largely decoupled from task accuracy, remaining near zero in deterministic settings even as accuracy scales to 96.8% on GSM8K.
Reference graph
Works this paper leans on
-
[1]
Michael Tomasello, Alicia P Melis, Claudio Tennie, Emily Wyman, and Esther Herrmann. Two key steps in the evolution of human cooperation: The interdependence hypothesis.Current Anthropology, 53(6):673–692, 2012
work page 2012
-
[2]
Harvard University Press, Cambridge, MA, 2009
Sarah Blaffer Hrdy.Mothers and Others: The Evolutionary Origins of Mutual Understanding. Harvard University Press, Cambridge, MA, 2009
work page 2009
-
[3]
Princeton University Press, 2018
Joseph Henrich.The Secret of Our Success: How Culture Is Driving Human Evolution, Domesticating Our Species, and Making Us Smarter. Princeton University Press, 2018
work page 2018
-
[4]
Embodied large language models enable robots to complete complex tasks in unpredictable environments
Ruaridh Mon-Williams, Gen Li, Ran Long, Wenqian Du, and Christopher G Lucas. Embodied large language models enable robots to complete complex tasks in unpredictable environments. Nature Machine Intelligence, pages 1–10, 2025
work page 2025
-
[5]
Ian A Apperly and Stephen A Butterfill. Do humans have two systems to track beliefs and belief-like states?Psychological review, 116(4):953, 2009
work page 2009
-
[6]
Bayesian theory of mind: Modeling joint belief-desire attribution
Chris Baker, Rebecca Saxe, and Joshua Tenenbaum. Bayesian theory of mind: Modeling joint belief-desire attribution. InProceedings of the annual meeting of the cognitive science society, volume 33, 2011
work page 2011
-
[7]
Rebecca Saxe and Nancy Kanwisher. People thinking about thinking people: the role of the temporo-parietal junction in “theory of mind”. InSocial neuroscience, pages 171–182. Psychology Press, 2013
work page 2013
-
[8]
Planning with theory of mind.Trends in Cognitive Sciences, 26(11):959–971, 2022
Mark K Ho, Rebecca Saxe, and Fiery Cushman. Planning with theory of mind.Trends in Cognitive Sciences, 26(11):959–971, 2022
work page 2022
-
[9]
Yang Xiang, Natalia Vélez, and Samuel J Gershman. Collaborative decision making is grounded in representations of other people’s competence and effort.Journal of Experimental Psychology: General, 152(6):1565, 2023
work page 2023
-
[10]
Optimizing competence in the service of collaboration.Cognitive Psychology, 150:101653, 2024
Yang Xiang, Natalia Vélez, and Samuel J Gershman. Optimizing competence in the service of collaboration.Cognitive Psychology, 150:101653, 2024
work page 2024
-
[11]
Carolyn Baer and Darko Odic. Mini managers: Children strategically divide cognitive labor among collaborators, but with a self-serving bias.Child Development, 93(2):437–450, 2022
work page 2022
-
[12]
Neil Rabinowitz, Frank Perbet, Francis Song, Chiyuan Zhang, S. M. Ali Eslami, and Matthew Botvinick. Machine theory of mind. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 4218–4227. PMLR, 10–15 Jul 2018
work page 2018
-
[13]
A survey of ad hoc teamwork research
Reuth Mirsky, Ignacio Carlucho, Arrasy Rahman, Elliot Fosong, William Macke, Mohan Sridharan, Peter Stone, and Stefano V Albrecht. A survey of ad hoc teamwork research. In European conference on multi-agent systems, pages 275–293. Springer, 2022
work page 2022
-
[14]
Learning to cooperate with humans using generative agents.arXiv preprint arXiv:2411.13934, 2024
Yancheng Liang, Daphne Chen, Abhishek Gupta, Simon S Du, and Natasha Jaques. Learning to cooperate with humans using generative agents.arXiv preprint arXiv:2411.13934, 2024
-
[15]
Gmytrasiewicz and Prashant Doshi
Piotr J. Gmytrasiewicz and Prashant Doshi. A framework for sequential planning in multi-agent settings.J. Artif. Int. Res., 24(1):49–79, July 2005
work page 2005
-
[16]
Empirical evaluation of ad hoc teamwork in the pursuit domain
Samuel Barrett, Peter Stone, and Sarit Kraus. Empirical evaluation of ad hoc teamwork in the pursuit domain. InThe 10th International Conference on Autonomous Agents and Multiagent Systems - Volume 2, AAMAS ’11, page 567–574. International Foundation for Autonomous Agents and Multiagent Systems, 2011
work page 2011
-
[17]
Albrecht and Subramanian Ramamoorthy
Stefano V . Albrecht and Subramanian Ramamoorthy. A game-theoretic model and best-response learning method for ad hoc coordination in multiagent systems. InProceedings of the 2013 International Conference on Autonomous Agents and Multi-Agent Systems, AAMAS ’13, page 1155–1156, 2013. 11
work page 2013
-
[18]
Stefano V . Albrecht, Jacob W. Crandall, and Subramanian Ramamoorthy. Belief and truth in hypothesised behaviours.Artificial Intelligence, 235:63–94, 2016
work page 2016
-
[19]
Georgios Papoudakis and Stefano V Albrecht. Variational autoencoders for opponent modeling in multi-agent systems.arXiv preprint arXiv:2001.10829, 2020
- [20]
-
[21]
Stefano V Albrecht and Peter Stone. Autonomous agents modelling other agents: A compre- hensive survey and open problems.Artificial Intelligence, 258:66–95, 2018
work page 2018
-
[22]
A behavioural trans- former for effective collaboration between a robot and a non-stationary human
Ruaridh Mon-Williams, Theodoros Stouraitis, and Sethu Vijayakumar. A behavioural trans- former for effective collaboration between a robot and a non-stationary human. In2023 32nd IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), pages 1150–1157. IEEE, 2023
work page 2023
-
[23]
Opponent modeling in deep reinforcement learning
He He, Jordan Boyd-Graber, Kevin Kwok, and Hal Daumé, III. Opponent modeling in deep reinforcement learning. In Maria Florina Balcan and Kilian Q. Weinberger, editors,Proceedings of The 33rd International Conference on Machine Learning, volume 48 ofProceedings of Machine Learning Research, pages 1804–1813. PMLR, 20–22 Jun 2016
work page 2016
-
[24]
Modeling others using oneself in multi-agent reinforcement learning
Roberta Raileanu, Emily Denton, Arthur Szlam, and Rob Fergus. Modeling others using oneself in multi-agent reinforcement learning. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 4257–4266. PMLR, 10–15 Jul 2018
work page 2018
-
[25]
Learning policy representations in multiagent systems
Aditya Grover, Maruan Al-Shedivat, Jayesh Gupta, Yuri Burda, and Harrison Edwards. Learning policy representations in multiagent systems. In Jennifer Dy and Andreas Krause, editors,Pro- ceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 1802–1811. PMLR, 10–15 Jul 2018
work page 2018
-
[26]
Deep interactive bayesian reinforcement learning via meta-learning
Luisa Zintgraf, Sam Devlin, Kamil Ciosek, Shimon Whiteson, and Katja Hofmann. Deep interactive bayesian reinforcement learning via meta-learning. InProceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS ’21, page 1712–1714, 2021
work page 2021
-
[27]
Learning latent representations to influence multi-agent interaction
Annie Xie, Dylan Losey, Ryan Tolsma, Chelsea Finn, and Dorsa Sadigh. Learning latent representations to influence multi-agent interaction. In Jens Kober, Fabio Ramos, and Claire Tomlin, editors,Proceedings of the 2020 Conference on Robot Learning, volume 155 of Proceedings of Machine Learning Research, pages 575–588. PMLR, 16–18 Nov 2021
work page 2020
- [28]
-
[29]
Social influence as intrinsic motivation for multi-agent deep reinforcement learning
Natasha Jaques, Angeliki Lazaridou, Edward Hughes, Caglar Gulcehre, Pedro Ortega, DJ Strouse, Joel Z Leibo, and Nando De Freitas. Social influence as intrinsic motivation for multi-agent deep reinforcement learning. InInternational conference on machine learning, pages 3040–3049. PMLR, 2019
work page 2019
-
[30]
Improving policies via search in cooperative partially observable games
Adam Lerer, Hengyuan Hu, Jakob Foerster, and Noam Brown. Improving policies via search in cooperative partially observable games. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 7187–7194, 2020
work page 2020
-
[31]
Hengyuan Hu, Adam Lerer, Alex Peysakhovich, and Jakob Foerster. “other-play” for zero-shot coordination. InInternational Conference on Machine Learning, pages 4399–4410. PMLR, 2020
work page 2020
-
[32]
What do navigation agents learn about their environment?
Kshitij Dwivedi, Gemma Roig, Aniruddha Kembhavi, and Roozbeh Mottaghi. What do navigation agents learn about their environment? . In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10266–10275, 2022. 12
work page 2022
-
[33]
Erik Wijmans, Manolis Savva, Irfan Essa, Stefan Lee, Ari S. Morcos, and Dhruv Batra. Emer- gence of maps in the memories of blind navigation agents. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[34]
Understanding and controlling a maze-solving policy network, 2023
Ulisse Mini, Peli Grietzer, Mrinank Sharma, Austin Meek, Monte MacDiarmid, and Alexan- der Matt Turner. Understanding and controlling a maze-solving policy network, 2023
work page 2023
-
[35]
Thomas McGrath, Andrei Kapishnikov, Nenad Tomašev, Adam Pearce, Martin Wattenberg, Demis Hassabis, Been Kim, Ulrich Paquet, and Vladimir Kramnik. Acquisition of chess knowl- edge in alphazero.Proceedings of the National Academy of Sciences, 119(47):e2206625119, 2022
work page 2022
-
[36]
An investigation of model-free planning
Arthur Guez, Mehdi Mirza, Karol Gregor, Rishabh Kabra, Sebastien Racaniere, Theophane Weber, David Raposo, Adam Santoro, Laurent Orseau, Tom Eccles, Greg Wayne, David Silver, and Timothy Lillicrap. An investigation of model-free planning. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Le...
work page 2019
-
[37]
Learning to reinforcement learn
Jane X Wang, Zeb Kurth-Nelson, Dhruva Tirumala, Hubert Soyer, Joel Z Leibo, Remi Munos, Charles Blundell, Dharshan Kumaran, and Matt Botvinick. Learning to reinforcement learn. arXiv preprint arXiv:1611.05763, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[38]
Andy Clark. Whatever next? predictive brains, situated agents, and the future of cognitive science.Behavioral and brain sciences, 36(3):181–204, 2013
work page 2013
- [39]
-
[40]
Collaborative plans for complex group action.Artificial Intelligence, 86(2):269–357, 1996
Barbara J Grosz and Sarit Kraus. Collaborative plans for complex group action.Artificial Intelligence, 86(2):269–357, 1996
work page 1996
-
[41]
Inverse attention agents for multi-agent systems.arXiv preprint arXiv:2410.21794, 2024
Qian Long, Ruoyan Li, Minglu Zhao, Tao Gao, and Demetri Terzopoulos. Inverse attention agents for multi-agent systems.arXiv preprint arXiv:2410.21794, 2024
-
[42]
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling.Advances in neural information processing systems, 34:15084–15097, 2021
work page 2021
-
[43]
Jaxmarl: Multi-agent rl environments and algorithms in jax
Alexander Rutherford, Benjamin Ellis, Matteo Gallici, Jonathan Cook, Andrei Lupu, Garðar Ingvarsson, Timon Willi, Ravi Hammond, Akbir Khan, Christian Schroeder de Witt, Alexandra Souly, Saptarashmi Bandyopadhyay, Mikayel Samvelyan, Minqi Jiang, Robert Tjarko Lange, Shimon Whiteson, Bruno Lacerda, Nick Hawes, Tim Rocktäschel, Chris Lu, and Jakob Nicolaus F...
work page 2024
-
[44]
Learning phrase representations using RNN encoder– decoder for statistical machine translation
Kyunghyun Cho, Bart van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder– decoder for statistical machine translation. In Alessandro Moschitti, Bo Pang, and Walter Daelemans, editors,Proceedings of the 2014 Conference on Empirical Methods in Natural Languag...
work page 2014
-
[45]
Proximal policy optimization algorithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017
work page 2017
-
[46]
JAX: composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018
work page 2018
-
[47]
Umap: Uniform manifold approximation and projection.Journal of Open Source Software, 3(29):861, 2018
Leland McInnes, John Healy, Nathaniel Saul, and Lukas Großberger. Umap: Uniform manifold approximation and projection.Journal of Open Source Software, 3(29):861, 2018. 13
work page 2018
-
[48]
Emergent kin selection of altruistic feeding via non-episodic neuroevolution
Max Taylor-Davies, Gautier Hamon, Timothé Boulet, and Clément Moulin-Frier. Emergent kin selection of altruistic feeding via non-episodic neuroevolution. In Pablo García-Sánchez, Emma Hart, and Sarah L. Thomson, editors,Applications of Evolutionary Computation, pages 496–509, 2025. 14 Appendix A CoinGame results To ensure that our findings generalise beyo...
work page 2025
-
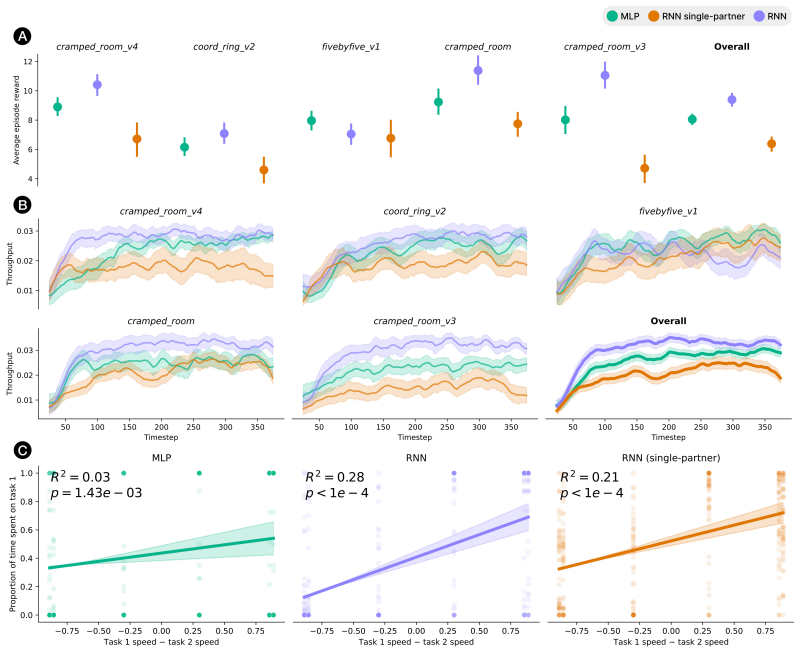
[49]
MLP (ego agent uses a simple MLP in place of an RNN)
-
[50]
No-influence RNN (ego agent has no control over which coin type the teammate pursues)
-
[51]
Single-partner RNN (ego agent only exposed to a single partner type during training)
-
[52]
Multi-partner RNN (ego agent paired with multiple partner types during training and has influence) During training, the single-agent RNN was always paired with a teammate with skill profile [0.2,0.8] ; in all other cases partners were sampled uniformly from the set [x,1−x]∀x∈ {0.2,0.4,0.6,0.8} . During evaluation, partners were always sampled uniformly fr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.