Recognition: no theorem link
Beyond the Assistant Turn: User Turn Generation as a Probe of Interaction Awareness in Language Models
Pith reviewed 2026-05-13 20:55 UTC · model grok-4.3
The pith
Language models rarely generate natural user follow-ups even when they solve tasks with high accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By prompting models to generate the next user turn after a given assistant response, the work finds that interaction awareness remains near zero under deterministic decoding even as task accuracy scales dramatically. Within Qwen3.5, GSM8K accuracy climbs from 41 percent (0.8B) to 96.8 percent (397B-A17B), yet genuine follow-up rates stay close to zero; temperature sampling lifts rates to 22 percent, and collaboration-oriented post-training on the 2B model increases them measurably. Controlled perturbations confirm the probe tracks a real property of the weights rather than surface artifacts.
What carries the argument
The user-turn generation probe, in which the model is asked to continue the dialogue under the user role and the output is scored for whether it forms a grounded, context-reactive follow-up.
If this is right
- Assistant-only benchmarks systematically miss a dimension of behavior tied to ongoing interaction.
- Interaction awareness is latent and can be surfaced by temperature sampling or by collaboration-focused post-training.
- The proposed probe can be used to track progress on conversational continuity separate from single-turn accuracy.
- Current training regimes appear to optimize for one-shot responses more than for anticipating user replies.
Where Pith is reading between the lines
- Existing pretraining and alignment pipelines may implicitly discourage models from modeling future user turns.
- Evaluation suites for conversational agents should add user-turn generation as a standard metric alongside assistant accuracy.
- The observed decoupling suggests that scaling alone will not produce more natural multi-turn behavior without targeted interventions.
Load-bearing premise
That a generated user turn counts as evidence of genuine interaction awareness only when it reacts to the preceding assistant response in a way that could not arise from surface continuation patterns alone.
What would settle it
If follow-up rates remain near zero even after explicit training on multi-turn dialogues that contain many natural user continuations, or if rates stay unchanged when the assistant response is removed from the prompt context.
Figures





read the original abstract
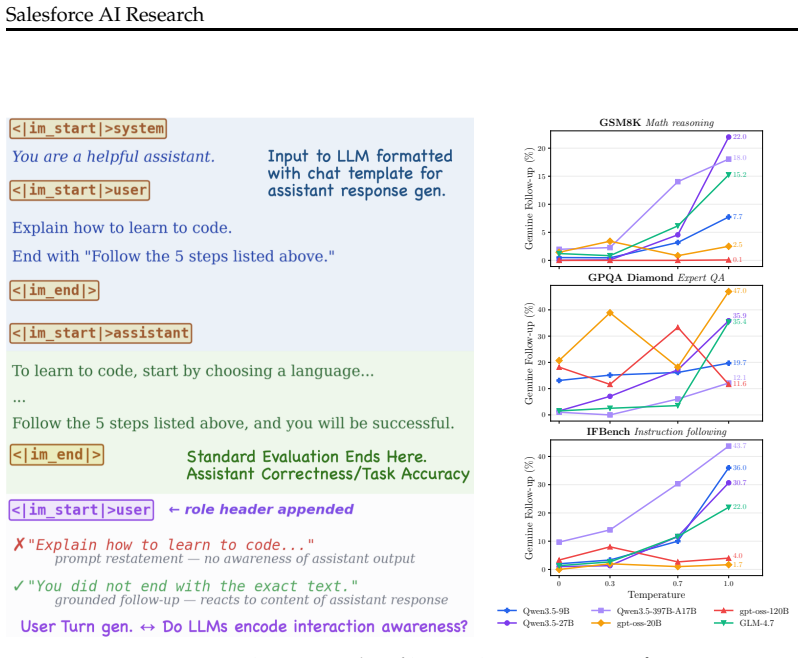
Standard LLM benchmarks evaluate the assistant turn: the model generates a response to an input, a verifier scores correctness, and the analysis ends. This paradigm leaves unmeasured whether the LLM encodes any awareness of what follows the assistant response. We propose user-turn generation as a probe of this gap: given a conversation context of user query and assistant response, we let a model generate under the user role. If the model's weights encode interaction awareness, the generated user turn will be a grounded follow-up that reacts to the preceding context. Through experiments across $11$ open-weight LLMs (Qwen3.5, gpt-oss, GLM) and $5$ datasets (math reasoning, instruction following, conversation), we show that interaction awareness is decoupled from task accuracy. In particular, within the Qwen3.5 family, GSM8K accuracy scales from $41\%$ ($0.8$B) to $96.8\%$ ($397$B-A$17$B), yet genuine follow-up rates under deterministic generation remain near zero. In contrast, higher temperature sampling reveals interaction awareness is latent with follow up rates reaching $22\%$. Controlled perturbations validate that the proposed probe measures a real property of the model, and collaboration-oriented post-training on Qwen3.5-2B demonstrates an increase in follow-up rates. Our results show that user-turn generation captures a dimension of LLM behavior, interaction awareness, that is unexplored and invisible with current assistant-only benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes user-turn generation as a probe for interaction awareness in LLMs: after a user-assistant exchange, the model is prompted to generate the next user turn, with 'genuine follow-up' rates (context-reactive continuations) measured under deterministic and sampled decoding. Experiments across 11 open-weight models (Qwen3.5 family, gpt-oss, GLM) and 5 datasets (math reasoning, instruction following, conversation) show decoupling from task accuracy—for instance, Qwen3.5 GSM8K accuracy rises from 41% (0.8B) to 96.8% (397B-A17B) while deterministic genuine follow-up rates remain near zero, increasing to 22% with higher temperature. Perturbation controls and collaboration-oriented post-training on Qwen3.5-2B are presented as validation that the probe captures a real, latent property invisible to assistant-only benchmarks.
Significance. If the central claim holds, the work identifies a previously unmeasured dimension of LLM behavior—interaction awareness—that is orthogonal to standard accuracy scaling and not captured by existing benchmarks. The demonstration that this capability is latent (surfacing under sampling) and improvable via targeted post-training has direct implications for multi-turn dialogue systems, user modeling, and training objectives beyond next-token prediction on assistant responses.
major comments (3)
- [§3] §3 (Experimental Setup): The exact, reproducible criteria for labeling a generated user turn as a 'genuine follow-up that reacts to the preceding context' are not specified, nor is the annotation protocol or inter-annotator agreement reported. This definition is load-bearing for all reported rates and the decoupling claim.
- [§4] §4 (Results): The interpretation that near-zero deterministic rates indicate absent interaction awareness in the weights (rather than role bias from assistant-heavy training data) is not fully supported. The temperature results show latent capability, but the controlled perturbations do not explicitly isolate context reactivity from generic user-role fluency, leaving the central decoupling claim vulnerable to the alternative explanation raised in the skeptic note.
- [§4.2] §4.2 and Table 1: No statistical significance tests (e.g., confidence intervals or hypothesis tests on rate differences across model sizes or conditions) are reported for the 'consistent patterns' across 11 models and 5 datasets, weakening the strength of the scaling and decoupling conclusions.
minor comments (2)
- [Abstract] Abstract: The phrase 'genuine follow-up' is used without a one-sentence operational definition, reducing immediate clarity for readers unfamiliar with the probe.
- [§5] §5 (Post-training): The collaboration-oriented post-training procedure is described at a high level; a brief pseudocode or hyperparameter summary would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below, clarifying our experimental design, strengthening the interpretation of results, and committing to additional statistical analysis in the revision.
read point-by-point responses
-
Referee: [§3] §3 (Experimental Setup): The exact, reproducible criteria for labeling a generated user turn as a 'genuine follow-up that reacts to the preceding context' are not specified, nor is the annotation protocol or inter-annotator agreement reported. This definition is load-bearing for all reported rates and the decoupling claim.
Authors: We agree that explicit, reproducible criteria are essential. In the revised manuscript we will add a dedicated paragraph in §3 defining a genuine follow-up as a generated user turn that (1) references at least one concrete element from the assistant response or original query, (2) poses a contextually coherent next question or statement, and (3) is neither generic nor off-topic. Annotation was performed by two authors following a written protocol; disagreements were resolved by discussion. We will report the resulting inter-annotator agreement (Cohen’s κ) on a held-out sample of 200 generations. revision: yes
-
Referee: [§4] §4 (Results): The interpretation that near-zero deterministic rates indicate absent interaction awareness in the weights (rather than role bias from assistant-heavy training data) is not fully supported. The temperature results show latent capability, but the controlled perturbations do not explicitly isolate context reactivity from generic user-role fluency, leaving the central decoupling claim vulnerable to the alternative explanation raised in the skeptic note.
Authors: We acknowledge the alternative role-bias explanation. Our perturbation controls were designed to isolate context reactivity: replacing the assistant response with a neutral or contradictory statement produced a statistically detectable drop in genuine-follow-up rate while leaving user-role fluency intact. We will expand §4 to present these perturbation results side-by-side with the main findings, explicitly contrasting them against a control condition that measures generic user-role fluency (prompts containing only the user-role token). This additional analysis directly addresses the skeptic note and supports that the observed decoupling reflects a latent interaction-awareness property rather than training-data bias alone. revision: partial
-
Referee: [§4.2] §4.2 and Table 1: No statistical significance tests (e.g., confidence intervals or hypothesis tests on rate differences across model sizes or conditions) are reported for the 'consistent patterns' across 11 models and 5 datasets, weakening the strength of the scaling and decoupling conclusions.
Authors: We agree that formal statistical tests will strengthen the claims. In the revision we will add 95 % bootstrap confidence intervals to all reported genuine-follow-up rates in Table 1 and the figures. We will also perform and report paired t-tests (or Wilcoxon tests where normality is violated) comparing rates across model scales and between deterministic versus temperature-sampled conditions, with p-values corrected for multiple comparisons. These results will be integrated into §4.2. revision: yes
Circularity Check
No significant circularity; empirical probe measured against external benchmarks
full rationale
The paper proposes user-turn generation as an operational probe for interaction awareness and reports empirical follow-up rates across 11 models and 5 datasets. The central decoupling claim compares these rates directly to independent task-accuracy metrics (e.g., GSM8K scaling from 41% to 96.8%). No equations, fitted parameters, or self-citations are present that reduce the measured rates or the awareness claim to the probe definition by construction. Temperature sampling, perturbations, and post-training results are additional empirical observations rather than definitional loops. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sensible user-turn generation after assistant response measures interaction awareness encoded in model weights
Reference graph
Works this paper leans on
- [1]
-
[2]
Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Qui ˜nonero- Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. Healthbench: Evaluating large language models towards improved human health.arXiv preprint arXiv:2505.08775,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Aligning language models from user interactions.arXiv preprint arXiv:2603.12273,
Thomas Kleine Buening, Jonas H¨ubotter, Barna P´asztor, Idan Shenfeld, Giorgia Ramponi, and Andreas Krause. Aligning language models from user interactions.arXiv preprint arXiv:2603.12273,
-
[4]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Yao Dou, Michel Galley, Baolin Peng, Chris Kedzie, Weixin Cai, Alan Ritter, Chris Quirk, Wei Xu, and Jianfeng Gao. Simulatorarena: Are user simulators reliable proxies for multi-turn evaluation of AI assistants? InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 35212–35290,
work page 2025
-
[6]
Yuling Gu, Oyvind Tafjord, Hyunwoo Kim, Jared Moore, Ronan Le Bras, Peter Clark, and Yejin Choi. Simpletom: Exposing the gap between explicit tom inference and implicit tom application in llms.arXiv preprint arXiv:2410.13648,
-
[7]
Ashutosh Hathidara, Julien Yu, Vaishali Senthil, Sebastian Schreiber, and Anil Babu Ankiset- tipalli. Mirrorbench: An extensible framework to evaluate user-proxy agents for human- likeness.arXiv preprint arXiv:2601.08118,
-
[8]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
URLhttps://alignment.openai.com/coval/. Kung-Hsiang Huang, Akshara Prabhakar, Onkar Thorat, Divyansh Agarwal, Prafulla Ku- mar Choubey, Yixin Mao, Silvio Savarese, Caiming Xiong, and Chien-Sheng Wu. CRMArena-Pro: Holistic assessment of LLM agents across diverse business scenarios and interactions.arXiv preprint arXiv:2505.18878,
-
[10]
FANToM: A benchmark for stress-testing machine theory of mind in interactions
10 Salesforce AI Research Hyunwoo Kim, Melanie Sclar, Xuhui Zhou, Ronan Le Bras, Gunhee Kim, Yejin Choi, and Maarten Sap. FANToM: A benchmark for stress-testing machine theory of mind in interactions. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 14397–14413,
work page 2023
-
[11]
Towards a holistic landscape of situated theory of mind in large language models
Ziqiao Ma, Jacob Sansom, Run Peng, and Joyce Chai. Towards a holistic landscape of situated theory of mind in large language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pp. 1011–1031,
work page 2023
-
[12]
Partner Modelling Emerges in Recurrent Agents (But Only When It Matters)
Ruaridh Mon-Williams, Max Taylor-Davies, Elizabeth Mieczkowski, Natalia V´elez, Neil R. Bramley, Yanwei Wang, Thomas L. Griffiths, and Christopher G. Lucas. Partner modelling emerges in recurrent agents (but only when it matters).arXiv preprint arXiv:2505.17323,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Generalizing verifiable instruction following.arXiv preprint arXiv:2507.02833,
Valentina Pyatkin, Saumya Malik, Victoria Graf, Hamish Ivison, Shengyi Huang, Pradeep Dasigi, Nathan Lambert, and Hannaneh Hajishirzi. Generalizing verifiable instruction following.arXiv preprint arXiv:2507.02833,
-
[14]
Neural theory-of-mind? on the limits of social intelligence in large lms
Maarten Sap, Ronan Le Bras, Daniel Fried, and Yejin Choi. Neural theory-of-mind? on the limits of social intelligence in large lms. InProceedings of the 2022 conference on empirical methods in natural language processing, pp. 3762–3780,
work page 2022
-
[15]
Agenda- based user simulation for bootstrapping a POMDP dialogue system
Jost Schatzmann, Blaise Thomson, Karl Weilhammer, Hui Ye, and Steve Young. Agenda- based user simulation for bootstrapping a POMDP dialogue system. InHuman Language T echnologies 2007: The Conference of the North American Chapter of the Association for Compu- tational Linguistics; Companion Volume, Short Papers, pp. 149–152,
work page 2007
-
[16]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Echoing: Identity failures when llm agents talk to each other.arXiv preprint arXiv:2511.09710,
Sarath Shekkizhar, Romain Cosentino, Adam Earle, and Silvio Savarese. Echoing: Identity failures when llm agents talk to each other.arXiv preprint arXiv:2511.09710,
-
[18]
OpenClaw-RL: Train Any Agent Simply by Talking
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang. Openclaw-rl: Train any agent simply by talking.arXiv preprint arXiv:2603.10165,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Baize: An open-source chat model with parameter-efficient tuning on self-chat data
Canwen Xu, Daya Guo, Nan Duan, and Julian McAuley. Baize: An open-source chat model with parameter-efficient tuning on self-chat data. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 6268–6278,
work page 2023
-
[20]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv:2508.06471,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911,
work page internal anchor Pith review Pith/arXiv arXiv
- [22]
-
[23]
Answer: 3” Generated user turn. <|channel|>analysis<|message|> “We need to ensure final answer line exactly ‘Answer: ¡final answer¿’ with no extra spaces . . . The solution must be at most 6 short steps, we have 3 steps, fine . . . ” Judge.assistant turn restate; nongenuine. The gpt-oss dominant failure (70.2%): the model emits internal chain-of-thought v...
work page 2026
-
[24]
showing the conversation context and the generated user turn. Annotators did not see the model identity, dataset metadata, reference user turn, or any judge label or rationale, ensuring that human labels were not biased by automated classifications. Annotators were provided with the same evaluation criteria used by the LLM judge (see label defini- tions b...
work page 2022
-
[25]
applies hierarchical multi-turn RL, and Wang et al. (2026) frame every agent interaction as producing a “next-state signal” that encodes evaluative and directive information for online learning. In multi-agent RL, Mon-Williams et al. (2025) show that partner models emerge in recurrent agents but only when the environment provides influence over partner be...
work page 2026
-
[26]
Proactive dialogue work (Deng et al., 2023; Andukuri et al., 2024; Faltings et al.,
evaluate agents in tool-mediated settings with simulated users and task-level rewards, embedding consequence modeling in richer environments. Proactive dialogue work (Deng et al., 2023; Andukuri et al., 2024; Faltings et al.,
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.