Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model
Pith reviewed 2026-05-19 12:55 UTC · model grok-4.3
The pith
Muddit integrates visual priors into a unified discrete diffusion transformer to match larger autoregressive models in multimodal generation quality and speed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Muddit is a unified discrete diffusion transformer that integrates strong visual priors from a pretrained text-to-image backbone with a lightweight text decoder. This enables fast and parallel generation across text and image modalities within a single architecture. Empirical results show that Muddit achieves competitive or superior performance compared to significantly larger autoregressive models in both quality and efficiency.
What carries the argument
The unified discrete diffusion transformer that reuses a pretrained text-to-image backbone to supply visual priors and adds a lightweight text decoder for text output.
If this is right
- Text and image tasks can run in parallel within one model instead of sequential token-by-token decoding.
- A single architecture can manage multiple modalities without separate specialized components.
- Strong pretrained visual backbones reduce the need for training very large models from scratch for unified tasks.
- Discrete diffusion becomes a scalable option for multimodal generation once equipped with existing visual priors.
Where Pith is reading between the lines
- The same reuse of pretrained priors could be tested on additional modalities such as audio or video to check for similar efficiency gains.
- Unified discrete diffusion models may reduce the hardware demands of running general-purpose generation systems in practice.
- Further experiments could measure how much the size of the text decoder affects overall quality to find minimal viable configurations.
Load-bearing premise
Adding a lightweight text decoder to a pretrained text-to-image backbone inside a discrete diffusion architecture will deliver high-quality multimodal generation without major losses in performance or flexibility.
What would settle it
Direct benchmark comparisons in which Muddit produces worse image quality scores or text coherence than the larger autoregressive models, or requires more total computation time, would falsify the performance claim.
Figures










read the original abstract
Unified generation models aim to handle diverse tasks across modalities -- such as text generation, image generation, and vision-language reasoning -- within a single architecture and decoding paradigm. Autoregressive unified models suffer from slow inference due to sequential decoding, and non-autoregressive unified models suffer from weak generalization due to limited pretrained backbones. We introduce the second-generation Meissonic: Muddit, a unified discrete diffusion transformer that enables fast and parallel generation across both text and image modalities. Unlike prior unified diffusion models trained from scratch, Muddit integrates strong visual priors from a pretrained text-to-image backbone with a lightweight text decoder, enabling flexible and high-quality multimodal generation under a unified architecture. Empirical results show that Muddit achieves competitive or superior performance compared to significantly larger autoregressive models in both quality and efficiency. The work highlights the potential of purely discrete diffusion, when equipped with strong visual priors, as a scalable and effective backbone for unified generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Muddit, a unified discrete diffusion transformer that integrates strong visual priors from a pretrained text-to-image backbone with a lightweight text decoder. This enables fast, parallel generation across text and image modalities within a single architecture and decoding paradigm, with empirical claims of competitive or superior performance relative to significantly larger autoregressive models in both quality and efficiency.
Significance. If the empirical results hold under scrutiny, the work demonstrates that purely discrete diffusion, when augmented with strong pretrained visual priors, can serve as an effective and scalable backbone for unified multimodal generation. This addresses slow sequential inference in autoregressive unified models and limited generalization in prior non-autoregressive approaches.
major comments (2)
- [§4] §4 (Experiments): The performance claims of competitive or superior results versus larger autoregressive models are presented without details on datasets, metrics (e.g., FID, perplexity), baseline configurations, model sizes, training data scale, or error bars/statistical controls. This directly undermines verification of the central empirical claim.
- [§3.2] §3.2 (Architecture): The integration of the pretrained text-to-image backbone with the lightweight text decoder is described at a high level but lacks concrete specification of the shared discrete diffusion process, tokenization scheme, or noise schedule across modalities. This is load-bearing for the no-major-trade-offs assumption.
minor comments (1)
- [Abstract] Abstract: The reference to 'second-generation Meissonic' lacks any explanation or citation to the first-generation model, leaving the incremental contribution unclear.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that enhance the manuscript's clarity and verifiability without altering its core contributions.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The performance claims of competitive or superior results versus larger autoregressive models are presented without details on datasets, metrics (e.g., FID, perplexity), baseline configurations, model sizes, training data scale, or error bars/statistical controls. This directly undermines verification of the central empirical claim.
Authors: We agree that the experimental details require expansion for full reproducibility and verification. In the revised manuscript, we will update §4 to explicitly specify the datasets (including text and image benchmarks), metrics such as FID for image quality and perplexity for text, baseline model configurations with their parameter counts and training data scales, and report error bars from multiple runs or statistical controls. These additions will directly support the claims of competitive or superior performance relative to larger autoregressive models. revision: yes
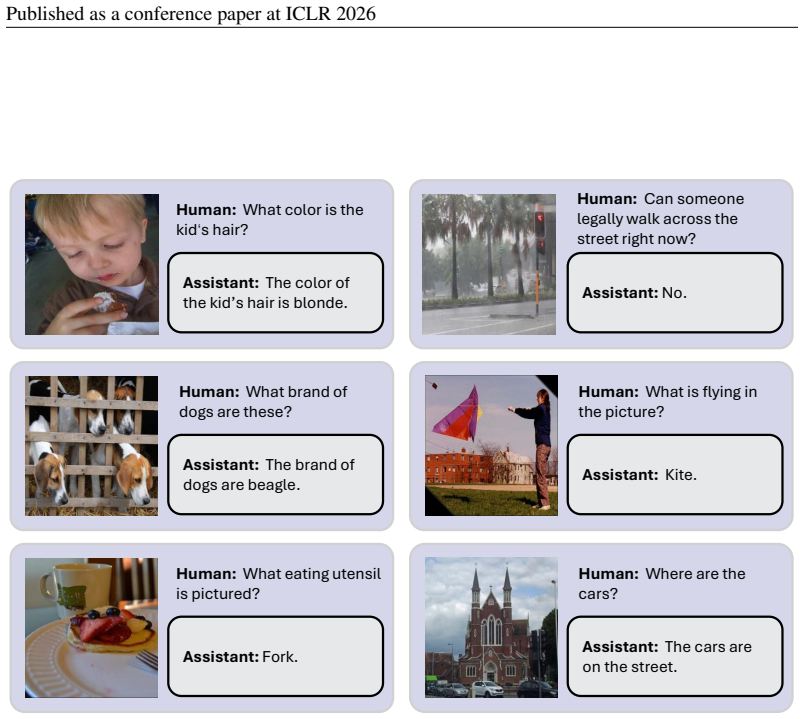
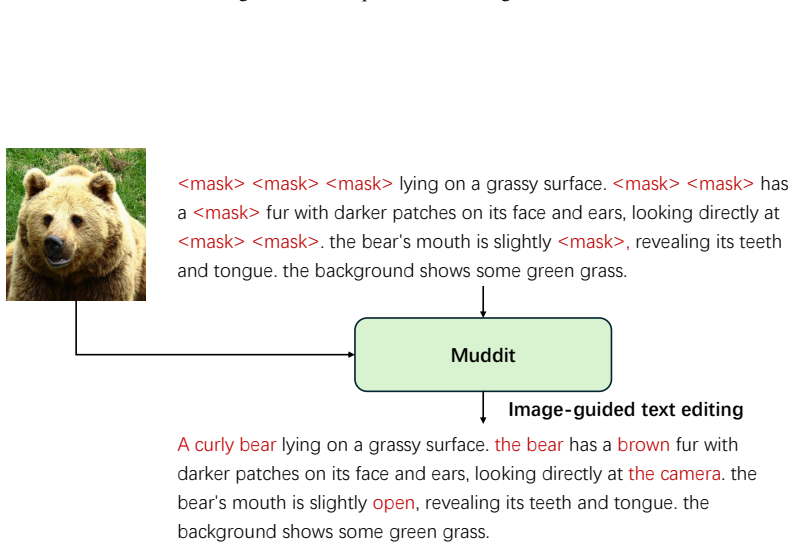
-
Referee: [§3.2] §3.2 (Architecture): The integration of the pretrained text-to-image backbone with the lightweight text decoder is described at a high level but lacks concrete specification of the shared discrete diffusion process, tokenization scheme, or noise schedule across modalities. This is load-bearing for the no-major-trade-offs assumption.
Authors: We acknowledge that greater specificity is warranted to substantiate the unified architecture. We will revise §3.2 to provide concrete details on the shared discrete diffusion process, the unified tokenization scheme applied across text and image modalities, and the noise schedule. These clarifications will demonstrate how the pretrained visual priors are integrated with the text decoder without introducing major trade-offs in the unified discrete diffusion framework. revision: yes
Circularity Check
No circularity detected; claims rest on empirical evaluation
full rationale
The manuscript introduces Muddit as a unified discrete diffusion transformer that combines a pretrained text-to-image backbone with a lightweight text decoder. Its central claim of competitive or superior performance versus larger autoregressive models is explicitly framed as an empirical outcome from training and benchmarking, not as a mathematical derivation or prediction obtained by construction from fitted parameters. No equations, uniqueness theorems, or ansatzes are presented that reduce any result to self-definition, self-citation load-bearing, or renaming of known patterns. The architecture description relies on external pretrained components and standard diffusion training, which are independently verifiable outside the paper's own fitted values. This is a standard empirical ML contribution whose validity can be assessed against external benchmarks and reproduction, yielding no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adopt a cosine scheduling strategy... γ_t = 2/π (1−(1−t)^2)−1/2
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LNELBO = E[∫ α'_t/(1−α_t) log(x_θ(xt,α_t)·x) dt]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 7 Pith papers
-
FlashAR: Efficient Post-Training Acceleration for Autoregressive Image Generation
FlashAR achieves up to 22.9x speedup in 512x512 autoregressive image generation by post-training a pre-trained model with a complementary vertical head and dynamic fusion using only 0.05% of original training data.
-
FlashAR: Efficient Post-Training Acceleration for Autoregressive Image Generation
FlashAR accelerates autoregressive image generation up to 22.9x by post-training a pre-trained raster-scan model with a complementary vertical head and dynamic fusion for two-way next-token prediction.
-
Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation
Tuna-2 shows that direct pixel embeddings can replace vision encoders in unified multimodal models, achieving competitive generation and stronger understanding at scale.
-
SynerMedGen: Synergizing Medical Multimodal Understanding with Generation via Task Alignment
SynerMedGen introduces generation-aligned understanding tasks and a two-stage training strategy that enables strong zero-shot medical image synthesis performance and outperforms specialized models when generation trai...
-
Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation
Tuna-2 shows pixel embeddings can replace vision encoders in unified multimodal models, achieving competitive or superior results on understanding and generation benchmarks.
-
Show-o2: Improved Native Unified Multimodal Models
Show-o2 unifies text, image, and video understanding and generation in a single autoregressive-plus-flow-matching model built on 3D causal VAE representations.
-
Evolution of Video Generative Foundations
This survey traces video generation technology from GANs to diffusion models and then to autoregressive and multimodal approaches while analyzing principles, strengths, and future trends.
Reference graph
Works this paper leans on
-
[1]
URLhttp://papers.nips.cc/paper_files/paper/2022/hash/ 960a172bc7fbf0177ccccbb411a7d800-Abstract-Conference.html. Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zit- nick, and Devi Parikh. Vqa: Visual question answering. InProceedings of the IEEE international conference on computer vision, pp. 2425–2433,
work page 2022
-
[2]
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
URLhttps: //arxiv.org/abs/2308.01390. Jinbin Bai, Yu Lei, Hecong Wu, Yuchen Zhu, Shufan Li, Yi Xin, Xiangtai Li, Molei Tao, Aditya Grover, and Ming-Hsuan Yang. From masks to worlds: A hitchhiker’s guide to world models. arXiv preprint arXiv:2510.20668, 2025a. Jinbin Bai, Tian Ye, Wei Chow, Enxin Song, Qing-Guo Chen, Xiangtai Li, Zhen Dong, Lei Zhu, and Sh...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
URLhttps://arxiv.org/abs/2308.12966. Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Guiming Hardy Chen, Shunian Chen, Ruifei Zhang, Junying Chen, Xiangbo Wu, Zhiyi Zhang, Zhi- hong Chen, Jianquan Li, Xiang Wan, and Benyou Wang. Allava: Harnessing gpt4v-synthesized data for a lite vision-language model, 2024a. Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, Le X...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Dreamllm: Synergistic multimodal comprehension and creation.arXiv preprint arXiv:2309.11499, 2023
Runpei Dong, Chunrui Han, Yuang Peng, Zekun Qi, Zheng Ge, Jinrong Yang, Liang Zhao, Jianjian Sun, Hongyu Zhou, Haoran Wei, et al. Dreamllm: Synergistic multimodal comprehension and creation.arXiv preprint arXiv:2309.11499,
-
[6]
Fluid: Scaling autoregressive text-to-image generative models with continuous tokens
Lijie Fan, Tianhong Li, Siyang Qin, Yuanzhen Li, Chen Sun, Michael Rubinstein, Deqing Sun, Kaiming He, and Yonglong Tian. Fluid: Scaling autoregressive text-to-image generative models with continuous tokens.arXiv preprint arXiv:2410.13863,
-
[7]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
SEED-X: Multimodal Models with Unified Multi-granularity Comprehension and Generation
Yuying Ge, Sijie Zhao, Jinguo Zhu, Yixiao Ge, Kun Yi, Lin Song, Chen Li, Xiaohan Ding, and Ying Shan. Seed-x: Multimodal models with unified multi-granularity comprehension and generation. arXiv preprint arXiv:2404.14396,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2402.03749 , year=
Jianyuan Guo, Hanting Chen, Chengcheng Wang, Kai Han, Chang Xu, and Yunhe Wang. Vi- sion superalignment: Weak-to-strong generalization for vision foundation models.arXiv preprint arXiv:2402.03749,
-
[10]
Accessed: 2025- 05-16. 12 Published as a conference paper at ICLR 2026 Shankar Kantharaj, Rixie Tiffany Leong, Xiang Lin, Ahmed Masry, Megh Thakkar, Enamul Hoque, and Shafiq Joty. Chart-to-text: A large-scale benchmark for chart summarization. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (eds.),Proceedings of the 60th Annual Meet- ing of th...
work page 2025
-
[11]
Announcing black forest labs, 2024.https://blackforestlabs.ai/ announcing-black-forest-labs/
Black Forest Labs. Announcing black forest labs, 2024.https://blackforestlabs.ai/ announcing-black-forest-labs/. Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. BLIP-2: bootstrapping language- image pre-training with frozen image encoders and large language models. InICML, volume 202 ofProceedings of Machine Learning Research, pp. 19730–19742. PMLR,
work page 2024
-
[12]
Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He
URLhttps: //proceedings.mlr.press/v202/li23q.html. Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. Autoregressive image generation without vector quantization.Advances in Neural Information Processing Systems, 37: 56424–56445, 2024a. Zijie Li, Henry Li, Yichun Shi, Amir Barati Farimani, Yuval Kluger, Linjie Yang, and Peng Wang. Dual diff...
-
[13]
Dongyang Liu, Shitian Zhao, Le Zhuo, Weifeng Lin, Yu Qiao, Hongsheng Li, and Peng Gao. Lumina-mgpt: Illuminate flexible photorealistic text-to-image generation with multimodal gener- ative pretraining, 2024a. URLhttps://arxiv.org/abs/2408.02657. Hao Liu, Wilson Yan, Matei Zaharia, and Pieter Abbeel. World model on million-length video and language with ri...
-
[14]
dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781, 2025
Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781,
-
[15]
2025.doi:10.48550/arXiv.2411.07975
Yiyang Ma, Xingchao Liu, Xiaokang Chen, Wen Liu, Chengyue Wu, Zhiyu Wu, Zizheng Pan, Zhenda Xie, Haowei Zhang, Liang Zhao, et al. Janusflow: Harmonizing autoregression and recti- fied flow for unified multimodal understanding and generation.arXiv preprint arXiv:2411.07975,
-
[16]
Deepart: Learning joint representations of visual arts
13 Published as a conference paper at ICLR 2026 Hui Mao, Ming Cheung, and James She. Deepart: Learning joint representations of visual arts. InProceedings of the 25th ACM international conference on Multimedia, pp. 1183–1191. ACM,
work page 2026
-
[17]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data
URLhttps://openai. com/index/gpt-4o-image-generation-system-card-addendum/. Accessed: 2025-04-02. Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your absorbing discrete diffusion secretly models the conditional distributions of clean data. arXiv preprint arXiv:2406.03736,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Transfer between Modalities with MetaQueries
Xichen Pan, Satya Narayan Shukla, Aashu Singh, Zhuokai Zhao, Shlok Kumar Mishra, Jialiang Wang, Zhiyang Xu, Jiuhai Chen, Kunpeng Li, Felix Juefei-Xu, et al. Transfer between modalities with metaqueries.arXiv preprint arXiv:2504.06256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text- conditional image generation with clip latents.arXiv preprint arXiv:2204.06125,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Kevin Rojas, Yuchen Zhu, Sichen Zhu, Felix X-F Ye, and Molei Tao. Diffuse everything: Multi- modal diffusion models on arbitrary state spaces.arXiv preprint arXiv:2506.07903,
-
[23]
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias
Ac- cessed: 2025-09-25. Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias. Simplified and general- ized masked diffusion for discrete data.Advances in neural information processing systems, 37: 103131–103167,
work page 2025
-
[24]
Rectok: Reconstruction distillation along rectified flow.arXiv preprint arXiv:2512.13421,
Qingyu Shi, Size Wu, Jinbin Bai, Kaidong Yu, Yujing Wang, Yunhai Tong, Xiangtai Li, and Xuelong Li. Rectok: Reconstruction distillation along rectified flow.arXiv preprint arXiv:2512.13421,
-
[25]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Emu: Generative Pretraining in Multimodality
14 Published as a conference paper at ICLR 2026 Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, Yueze Wang, Hongcheng Gao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Generative pretraining in multimodality.arXiv preprint arXiv:2307.05222,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Unified multimodal discrete diffusion.arXiv preprint arXiv:2503.20853, 2025
Alexander Swerdlow, Mihir Prabhudesai, Siddharth Gandhi, Deepak Pathak, and Katerina Fragki- adaki. Unified multimodal discrete diffusion.arXiv preprint arXiv:2503.20853, 2025a. Alexander Swerdlow, Mihir Prabhudesai, Siddharth Gandhi, Deepak Pathak, and Katerina Fragki- adaki. Unified multimodal discrete diffusion.arXiv preprint arXiv:2503.20853, 2025b. d...
-
[28]
MetaMorph: Multimodal Understanding and Generation via Instruction Tuning
Shengbang Tong, David Fan, Jiachen Zhu, Yunyang Xiong, Xinlei Chen, Koustuv Sinha, Michael Rabbat, Yann LeCun, Saining Xie, and Zhuang Liu. Metamorph: Multimodal understanding and generation via instruction tuning.arXiv preprint arXiv:2412.14164,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth ´ee Lacroix, Baptiste Rozi `ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Illume: Illuminating your llms to see, draw, and self-enhance.arXiv preprint arXiv:2412.06673, 2024a
Chunwei Wang, Guansong Lu, Junwei Yang, Runhui Huang, Jianhua Han, Lu Hou, Wei Zhang, and Hang Xu. Illume: Illuminating your llms to see, draw, and self-enhance.arXiv preprint arXiv:2412.06673, 2024a. Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token predic...
-
[31]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Yi Xin, Siqi Luo, Qi Qin, Haoxing Chen, Kaiwen Zhu, Zhiwei Zhang, Yangfan He, Rongchao Zhang, Jinbin Bai, Shuo Cao, et al. dmllm-tts: Self-verified and efficient test-time scaling for diffusion multi-modal large language models.arXiv preprint arXiv:2512.19433, 2025a. Yi Xin, Qi Qin, Siqi Luo, Kaiwen Zhu, Juncheng Yan, Yan Tai, Jiayi Lei, Yuewen Cao, Keqi ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Chuyang Zhao, Yuxing Song, Wenhao Wang, Haocheng Feng, Errui Ding, Yifan Sun, Xinyan Xiao, and Jingdong Wang. Monoformer: One transformer for both diffusion and autoregression.arXiv preprint arXiv:2409.16280,
-
[34]
Adapt without for- getting: Distill proximity from dual teachers in vision-language models
15 Published as a conference paper at ICLR 2026 Mengyu Zheng, Yehui Tang, Zhiwei Hao, Kai Han, Yunhe Wang, and Chang Xu. Adapt without for- getting: Distill proximity from dual teachers in vision-language models. InEuropean Conference on Computer Vision, pp. 109–125. Springer,
work page 2026
-
[35]
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Chunting Zhou, Lili Yu, Arun Babu, Kushal Tirumala, Michihiro Yasunaga, Leonid Shamis, Jacob Kahn, Xuezhe Ma, Luke Zettlemoyer, and Omer Levy. Transfusion: Predict the next token and diffuse images with one multi-modal model.arXiv preprint arXiv:2408.11039,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
It is organized as follows: •Related Work(Sec
16 Published as a conference paper at ICLR 2026 APPENDIX APPENDIXOVERVIEW This appendix provides additional discussions, results, and analyses to complement the main paper. It is organized as follows: •Related Work(Sec. A): We review unified multimodal models for understanding and gen- eration, with a focus on autoregressive and diffusion-based paradigms,...
work page 2026
-
[37]
or discrete diffusion (Xie et al., 2024). Though visually strong, these models are not truly unified, as they rely on separate architectures and token spaces. Image Diffusion, Text Discrete Diffusion: Emerging models experiment with discrete diffusion for text and images (Li et al., 2024c), though many, like Dual-Diffusion (Li et al., 2024c), still use co...
work page 2024
-
[38]
model represents a significant advance as a unified mul- timodal generative system. However, its closed-source nature obscures critical architectural and training details, and its success may be largely attributable to scale rather than architectural nov- elty (Chen et al., 2025c). A.2 MASKEDIMAGEMODELING Masked Image Modeling (MIM) has emerged as a power...
work page 2018
-
[39]
and plays a critical role in modern unified models. We will introduce discrete diffusion in the next section. A.3 RELATIONSHIP TOCONCURRENTWORK Our main contribution is to demonstrate that a unified,visual-priorfully discrete diffusion model can be both effective and data-efficient for image understanding tasks, rather than just text-to-image generation t...
work page 2026
-
[40]
and do not support visual question answering tasks (Antol et al., 2015). In contrast, Muddit is the first unified discrete diffusion model built on top of a pretrained high-resolution text-to-image backbone (Bai et al., 2025b), with a lightweight text decoder on top. This visual prior is not an implementation detail: it improves the scalability and genera...
work page 2015
-
[41]
blonde” hair), object categories (e.g., “bea- gle
Muddit reliably identifies fine-grained attributes (e.g., “blonde” hair), object categories (e.g., “bea- gle”), and physical affordances (e.g., answering “No” to crossing at a red light). Notably, it also handles commonsense reasoning and spatial localization, such as inferring traffic legality or locat- ing vehicles on the street. Image-guided text editi...
work page 2026
-
[42]
6 =O(L 3D) Autoregressive (AR) with KV Cache: 19 Published as a conference paper at ICLR 2026 Table 9: Ablation study on the effect of classifier-free guidance (CFG) scale. Dataset CFG = 1 CFG = 1.5 CFG = 2 CFG = 2.5 CFG = 3 MS-COCO 57.2 59.9 58.2 51.3 47.2 VQAv2 65.8 68.2 64.7 55.4 49.2 Table 10: Comparison of model efficiency across different resolution...
work page 2026
-
[43]
• Per-step attention FLOPs:O(L 2D)
2 =O(L 2D) Discrete Diffusion: • Each step updates the full sequence (lengthL) in parallel. • Per-step attention FLOPs:O(L 2D). • Total FLOPs: T·O(L 2D) =O(T L 2D), T≪L While discrete diffusion may appear less efficient than autoregressive (AR) models with KV caching in terms of theoretical FLOPs, it offers a significant advantage over AR without caching—...
work page 2025
-
[44]
G DISCUSSION G.1 LIMITATIONS While Muddit advances discrete diffusion for unified multimodal generation, it still has several limi- tations. First, due to its token-level discrete representation, the model may underperform continuous diffusion models in generating photorealistic or high-resolution images. Second, Muddit is initial- ized from a pretrained ...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.