Benchmarking Misuse Mitigation Against Covert Adversaries
Pith reviewed 2026-05-19 10:25 UTC · model grok-4.3
The pith
Decomposition attacks enable covert misuse of language models by breaking dangerous tasks into many separate benign queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
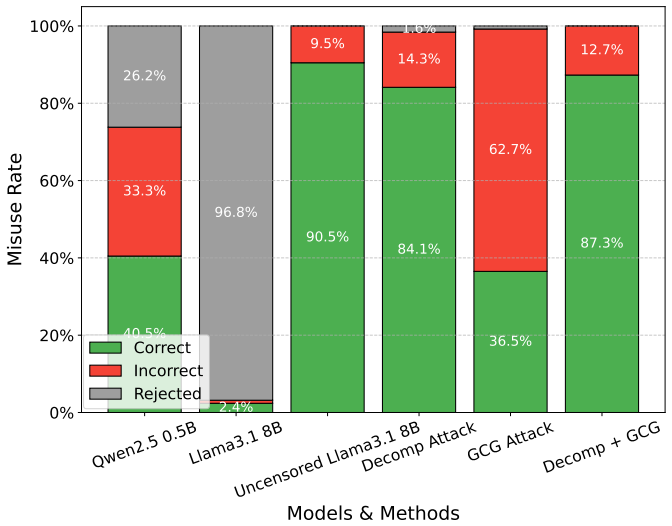
We develop Benchmarks for Stateful Defenses (BSD), a data generation pipeline that automates evaluations of covert attacks and corresponding defenses. Using this pipeline, we curate two new datasets that are consistently refused by frontier models and are too difficult for weaker open-weight models. This enables us to evaluate decomposition attacks, which are found to be effective misuse enablers, and to highlight stateful defenses as a promising countermeasure.
What carries the argument
The Benchmarks for Stateful Defenses (BSD) pipeline, which automates the creation and cross-query combination of task fragments to test detection of accumulated misuse signals.
Load-bearing premise
The curated datasets and automated pipeline accurately capture real-world covert attack strategies and that combining fragments across queries reliably uplifts misuse in deployed models.
What would settle it
Running the decomposition fragments through a production model and measuring whether the attacker can complete the target harmful task at a higher rate than with single queries, or whether adding stateful tracking across queries fails to lower that rate.
Figures







read the original abstract
Existing language model safety evaluations focus on overt attacks and low-stakes tasks. In reality, an attacker can easily subvert existing safeguards by requesting help on small, benign-seeming tasks across many independent queries. Because the individual queries do not appear harmful, the attack is hard to detect. However, when combined, these fragments uplift misuse by helping the attacker complete hard and dangerous tasks. Toward identifying defenses against such strategies, we develop Benchmarks for Stateful Defenses (BSD), a data generation pipeline that automates evaluations of covert attacks and corresponding defenses. Using this pipeline, we curate two new datasets that are consistently refused by frontier models and are too difficult for weaker open-weight models. This enables us to evaluate decomposition attacks, which are found to be effective misuse enablers, and to highlight stateful defenses as a promising countermeasure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Benchmarks for Stateful Defenses (BSD), an automated data-generation pipeline designed to evaluate covert decomposition attacks on language models. These attacks split harmful tasks into sequences of individually benign queries that evade per-query safeguards; when aggregated, the fragments are claimed to produce measurable misuse uplift. The authors curate two new datasets that frontier models consistently refuse and that are too difficult for weaker open-weight models, use the pipeline to show that decomposition attacks are effective misuse enablers, and identify stateful defenses as a promising countermeasure.
Significance. If the empirical claims are substantiated with quantitative evidence, the work addresses a genuine gap in current safety evaluations, which focus on overt single-query attacks. Providing curated, hard datasets and an automated pipeline for stateful-defense benchmarking could supply a useful testbed for future mitigation research. The emphasis on realistic multi-query covert strategies is a constructive direction, though its practical impact depends on demonstrating that the generated fragments are independent, evade detection, and produce statistically reliable uplift over direct queries.
major comments (2)
- [Abstract] Abstract: the central claim that 'decomposition attacks are effective misuse enablers' and that the BSD pipeline produces datasets 'consistently refused by frontier models' is presented without any refusal-rate tables, uplift metrics, statistical significance tests, or ablation comparing sequential fragments to direct queries. Because the effectiveness of the attack and the value of the benchmark rest on these unshown measurements, the absence of this evidence is load-bearing for the paper's primary contribution.
- [Abstract] The weakest assumption—that automated fragment combination across independent queries produces a statistically significant increase in harmful output that would not occur from a single direct query—is not supported by any described metric or control experiment in the abstract. Without an explicit definition of the uplift metric and a comparison to baseline direct-query success rates, it is impossible to verify that the pipeline captures genuine covert strategies rather than inadvertently linked or still-refusable fragments.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight the need for the abstract to more explicitly surface the quantitative results that support our claims about decomposition attacks and the BSD pipeline. We address each point below and will revise the abstract accordingly while preserving its length constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'decomposition attacks are effective misuse enablers' and that the BSD pipeline produces datasets 'consistently refused by frontier models' is presented without any refusal-rate tables, uplift metrics, statistical significance tests, or ablation comparing sequential fragments to direct queries. Because the effectiveness of the attack and the value of the benchmark rest on these unshown measurements, the absence of this evidence is load-bearing for the paper's primary contribution.
Authors: We agree that the abstract would benefit from explicit quantitative anchors. The full manuscript already reports refusal rates (e.g., >95% on frontier models for both datasets), uplift metrics (decomposition success rates versus direct-query baselines), and statistical comparisons in Sections 4 and 5. In the revision we will add a concise sentence to the abstract summarizing the key refusal rates, the measured uplift, and the significance of the difference from direct queries, while still keeping the abstract under the word limit. revision: yes
-
Referee: [Abstract] The weakest assumption—that automated fragment combination across independent queries produces a statistically significant increase in harmful output that would not occur from a single direct query—is not supported by any described metric or control experiment in the abstract. Without an explicit definition of the uplift metric and a comparison to baseline direct-query success rates, it is impossible to verify that the pipeline captures genuine covert strategies rather than inadvertently linked or still-refusable fragments.
Authors: The manuscript defines the uplift metric in Section 3.2 as the difference in harmful completion rate between the aggregated decomposition sequence and the direct-query baseline, with statistical significance assessed via paired t-tests across model runs. We acknowledge that the abstract does not currently name this metric or the control. In the revision we will insert a brief clause stating that decomposition yields a statistically significant uplift (p < 0.01) over direct queries on the curated datasets, thereby clarifying that the fragments are not merely rephrasings of the original harmful request. revision: yes
Circularity Check
No circularity: empirical benchmarking via new data pipeline
full rationale
This paper presents an empirical benchmarking study that develops the BSD data generation pipeline to curate refusal datasets and evaluate decomposition attacks plus stateful defenses. The abstract and described contributions contain no mathematical derivations, fitted parameters renamed as predictions, self-citation load-bearing premises, or ansatzes smuggled via prior work. Central claims rest on newly generated datasets and experimental results rather than any reduction of outputs to inputs by construction. The work is self-contained against external benchmarks through its automated curation process.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing language model safety evaluations focus on overt attacks and low-stakes tasks.
invented entities (1)
-
Benchmarks for Stateful Defenses (BSD)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We develop Benchmarks for Stateful Defenses (BSD), a data generation pipeline that automates evaluations of covert attacks and corresponding defenses... decomposition attacks are effective misuse enablers
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
One Turn Too Late: Response-Aware Defense Against Hidden Malicious Intent in Multi-Turn Dialogue
TurnGate uses a new multi-turn intent dataset to detect the harm-enabling closure point in dialogues, outperforming baselines with low over-refusal and generalizing across domains.
-
One Turn Too Late: Response-Aware Defense Against Hidden Malicious Intent in Multi-Turn Dialogue
TurnGate identifies the critical turn in multi-turn dialogues where a response would complete hidden malicious intent, outperforming baselines on the new MTID dataset while keeping over-refusal low.
Reference graph
Works this paper leans on
-
[1]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does llm safety training fail? Advances in Neural Information Processing Systems, 36:80079–80110, 2023. 1
work page 2023
-
[2]
Jailbreaking Black Box Large Language Models in Twenty Queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries, 2024. URL https://arxiv.org/abs/2310.08419. 2, 6, 7, 17, 22
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Red Teaming Language Models with Language Models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models. arXiv preprint arXiv:2202.03286, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal. arXiv preprint arXiv:2402.04249,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J Pappas, Florian Tramer, et al. Jailbreakbench: An open robustness benchmark for jailbreaking large language models. arXiv preprint arXiv:2404.01318, 2024. 2, 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
A StrongREJECT for Empty Jailbreaks
Alexandra Souly, Qingyuan Lu, Dillon Bowen, Tu Trinh, Elvis Hsieh, Sana Pandey, Pieter Abbeel, Justin Svegliato, Scott Emmons, Olivia Watkins, et al. A strongreject for empty jailbreaks. arXiv preprint arXiv:2402.10260, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, et al. Agentharm: A benchmark for measuring harmfulness of llm agents. arXiv preprint arXiv:2410.09024, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022. 1
work page 2022
-
[9]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36:53728–53741, 2023
work page 2023
-
[10]
https: //arxiv.org/abs/2406.04313.arXiv(2024)
Andy Zou, Long Phan, Justin Wang, Derek Duenas, Maxwell Lin, Maksym Andriushchenko, Rowan Wang, Zico Kolter, Matt Fredrikson, and Dan Hendrycks. Improving alignment and robustness with circuit breakers. arXiv preprint arXiv: 2406.04313, 2024. 1, 17
-
[11]
The jailbreak tax: How useful are your jailbreak outputs? arXiv preprint arXiv:2504.10694, 2025
Kristina Nikoli´c, Luze Sun, Jie Zhang, and Florian Tramèr. The jailbreak tax: How useful are your jailbreak outputs? arXiv preprint arXiv:2504.10694, 2025. 1, 2, 17, 23 10
-
[12]
Mrinank Sharma, Meg Tong, Jesse Mu, Jerry Wei, Jorrit Kruthoff, Scott Goodfriend, Euan Ong, Alwin Peng, Raj Agarwal, Cem Anil, et al. Constitutional classifiers: Defending against universal jailbreaks across thousands of hours of red teaming. arXiv preprint arXiv:2501.18837,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
Neel Jain, Avi Schwarzschild, Yuxin Wen, Gowthami Somepalli, John Kirchenbauer, Ping-yeh Chiang, Micah Goldblum, Aniruddha Saha, Jonas Geiping, and Tom Goldstein. Baseline de- fenses for adversarial attacks against aligned language models.arXiv preprint arXiv:2309.00614, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
Alexander Robey, Eric Wong, Hamed Hassani, and George J Pappas. Smoothllm: Defending large language models against jailbreaking attacks. arXiv preprint arXiv:2310.03684, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to! arXiv preprint arXiv:2310.03693, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Obfuscated activations bypass llm latent-space defenses
Luke Bailey, Alex Serrano, Abhay Sheshadri, Mikhail Seleznyov, Jordan Taylor, Erik Jenner, Jacob Hilton, Stephen Casper, Carlos Guestrin, and Scott Emmons. Obfuscated activations bypass llm latent-space defenses. arXiv preprint arXiv:2412.09565, 2024
-
[17]
T., Haghtalab, N., and Steinhardt, J
Danny Halawi, Alexander Wei, Eric Wallace, Tony T Wang, Nika Haghtalab, and Jacob Steinhardt. Covert malicious finetuning: Challenges in safeguarding llm adaptation. arXiv preprint arXiv:2406.20053, 2024. 1
-
[18]
Adversaries can misuse combinations of safe models
Erik Jones, Anca Dragan, and Jacob Steinhardt. Adversaries can misuse combinations of safe models. arXiv preprint arXiv: 2406.14595, 2024. 2, 3, 6, 7, 9, 17
-
[19]
David Glukhov, Ziwen Han, Ilia Shumailov, Vardan Papyan, and Nicolas Papernot. Breach by a thousand leaks: Unsafe information leakage in ‘safe’ ai responses.arXiv preprint arXiv: 2407.02551, 2024. 2, 3, 6, 7, 9, 17
-
[20]
arXiv preprint arXiv:2402.16914 (2024)
Xirui Li, Ruochen Wang, Minhao Cheng, Tianyi Zhou, and Cho-Jui Hsieh. Drattack: Prompt decomposition and reconstruction makes powerful llm jailbreakers. arXiv preprint arXiv:2402.16914, 2024. 2
-
[21]
arXiv preprint arXiv:2502.01633 (2025) 20 Sakib et al
Mahdi Sabbaghi, Paul Kassianik, George Pappas, Yaron Singer, Amin Karbasi, and Hamed Hassani. Adversarial reasoning at jailbreaking time. arXiv preprint arXiv:2502.01633, 2025. 2, 6, 7, 17, 22
-
[22]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Dis- rupting malicious uses of our models: an update
Ben Nimmo, Albert Zhang, Matthew Richard, and Nathaniel Hartley. Dis- rupting malicious uses of our models: an update. Technical report, OpenAI, February 2025. URL https://cdn.openai.com/threat-intelligence-reports/ disrupting-malicious-uses-of-our-models-february-2025-update.pdf . Threat Intelligence Report. 2, 4, 7
work page 2025
-
[24]
Evaluating frontier models for dangerous capabilities,
Mary Phuong, Matthew Aitchison, Elliot Catt, Sarah Cogan, Alexandre Kaskasoli, Victoria Krakovna, David Lindner, Matthew Rahtz, Yannis Assael, Sarah Hodkinson, Heidi Howard, Tom Lieberum, Ramana Kumar, Maria Abi Raad, Albert Webson, Lewis Ho, Sharon Lin, Sebastian Farquhar, Marcus Hutter, Gregoire Deletang, Anian Ruoss, Seliem El-Sayed, Sasha Brown, Anca ...
-
[25]
Jailbreaking leading safety-aligned llms with simple adaptive attacks, 2025
Maksym Andriushchenko, Francesco Croce, and Nicolas Flammarion. Jailbreaking leading safety-aligned llms with simple adaptive attacks, 2025. URLhttps://arxiv.org/abs/2404. 02151. 2, 6, 17, 22 11
work page 2025
-
[26]
Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack
Mark Russinovich, Ahmed Salem, and Ronen Eldan. Great, now write an article about that: The crescendo multi-turn llm jailbreak attack. arXiv preprint arXiv: 2404.01833, 2024. 2, 6, 17, 22
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Steven Chen, Nicholas Carlini, and D. Wagner. Stateful detection of black-box adversarial attacks. Proceedings of the 1st ACM Workshop on Security and Privacy on Artificial Intelligence,
-
[28]
doi: 10.1145/3385003.3410925. 2
-
[29]
Logan IV , Eric Wallace, and Sameer Singh
Taylor Shin, Yasaman Razeghi, Robert L. Logan IV , Eric Wallace, and Sameer Singh. Au- toprompt: Eliciting knowledge from language models with automatically generated prompts,
- [30]
-
[31]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv: 2307.15043, 2023. 17
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. Autodan: Generating stealthy jailbreak prompts on aligned large language models, 2024. URL https://arxiv.org/abs/ 2310.04451. 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Tree of attacks: Jailbreaking black-box llms automatically
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. Tree of attacks: Jailbreaking black-box llms automatically, 2024. URL https://arxiv.org/abs/2312.02119. 2, 17
-
[34]
Stateful Detection of Black-Box Adversarial Attacks
Steven Chen, Nicholas Carlini, and David Wagner. Stateful detection of black-box adversarial attacks, 2019. URL https://arxiv.org/abs/1907.05587. 2, 17
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[35]
Huiying Li, Shawn Shan, Emily Wenger, Jiayun Zhang, Haitao Zheng, and Ben Y . Zhao. Blacklight: Scalable defense for neural networks against Query-Based Black-Box attacks. In 31st USENIX Security Symposium (USENIX Security 22) , pages 2117–2134, Boston, MA, August 2022. USENIX Association. ISBN 978-1-939133-31-1. URL https://www.usenix. org/conference/use...
work page 2022
-
[36]
Piha: Detection method using perceptual image hashing against query-based adversarial attacks
Seok-Hwan Choi, Jinmyeong Shin, and Yoon-Ho Choi. Piha: Detection method using perceptual image hashing against query-based adversarial attacks. Future Generation Computer Systems, 145:563–577, 2023. ISSN 0167-739X. doi: https://doi.org/10.1016/j.future.2023.04.005. URL https://www.sciencedirect.com/science/article/pii/S0167739X23001395. 17
-
[37]
Jeonghwan Park, Niall McLaughlin, and Ihsen Alouani. Mind the gap: Detecting black- box adversarial attacks in the making through query update analysis, 2025. URL https: //arxiv.org/abs/2503.02986. 17
-
[38]
Stateful defenses for machine learning models are not yet secure against black-box attacks
Ryan Feng, Ashish Hooda, Neal Mangaokar, Kassem Fawaz, Somesh Jha, and Atul Prakash. Stateful defenses for machine learning models are not yet secure against black-box attacks. In Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, CCS ’23, page 786–800. ACM, November 2023. doi: 10.1145/3576915.3623116. URL http://dx.doi...
-
[39]
Alex Tamkin, Miles McCain, Kunal Handa, Esin Durmus, Liane Lovitt, Ankur Rathi, Saffron Huang, Alfred Mountfield, Jerry Hong, Stuart Ritchie, Michael Stern, Brian Clarke, Landon Goldberg, Theodore R. Sumers, Jared Mueller, William McEachen, Wes Mitchell, Shan Carter, Jack Clark, Jared Kaplan, and Deep Ganguli. Clio: Privacy-preserving insights into real-w...
-
[40]
Introducing GPT-4.1 in the API, April 2025
OpenAI. Introducing GPT-4.1 in the API, April 2025. URL https://openai.com/index/ gpt-4-1/. Accessed on May 5, 2025. 4, 5, 19
work page 2025
-
[41]
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann-Kathrin Dombrowski, Shashwat Goel, Long Phan, Gabriel Mukobi, Nathan Helm- Burger, Rassin R. Lababidi, Lennart Justen, Andrew B. Liu, Michael Chen, Isabelle Barrass, Oliver Zhang, Xiaoyuan Zhu, Rishub Tamirisa, Bhrugu Bharathi, Adam Khoja, Ariel Herbert- ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.03218 2024
-
[42]
Do large language model benchmarks test reliability? arXiv preprint arXiv:2502.03461, 2025
Joshua Vendrow, Edward Vendrow, Sara Beery, and Aleksander Madry. Do large language model benchmarks test reliability? arXiv preprint arXiv: 2502.03461, 2025. 4
-
[43]
Badllama: cheaply removing safety fine-tuning from llama 2-chat 13b
Pranav Gade, Simon Lermen, Charlie Rogers-Smith, and Jeffrey Ladish. Badllama: cheaply removing safety fine-tuning from llama 2-chat 13b. arXiv preprint arXiv: 2311.00117, 2023. 4, 18
-
[44]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding. International Conference on Learning Representations, 2020. 5, 6, 9
work page 2020
-
[45]
LAB-Bench: Measuring Capabilities of Language Models for Biology Research
Jon M. Laurent, Joseph D. Janizek, Michael Ruzo, Michaela M. Hinks, Michael J. Hammerling, Siddharth Narayanan, Manvitha Ponnapati, Andrew D. White, and Samuel G. Rodriques. Lab- bench: Measuring capabilities of language models for biology research. arXiv preprint arXiv: 2407.10362, 2024. 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Yangjun Ruan, Chris J. Maddison, and Tatsunori B. Hashimoto. Observational scaling laws and the predictability of language model performance. Neural Information Processing Systems,
-
[47]
doi: 10.48550/arXiv.2405.10938. 5
-
[48]
Richard Ren, Steven Basart, Adam Khoja, Alice Gatti, Long Phan, Xuwang Yin, Mantas Mazeika, Alexander Pan, Gabriel Mukobi, Ryan Hwang Kim, Stephen Fitz, and Dan Hendrycks. Safetywashing: Do AI safety benchmarks actually measure safety progress? In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URL...
work page 2024
-
[49]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv: 1802.03426, 2018. 7
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[50]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Operating multi-client influence networks across platforms
Ken Lebedev, Alex Moix, and Jacob Klein. Operating multi-client influence networks across platforms. Technical report, Anthropic, April 2025. URL https://cdn.sanity.io/ files/4zrzovbb/website/45bc6adf039848841ed9e47051fb1209d6bb2b26.pdf. An- thropic technical report on AI-powered influence operations. 7
work page 2025
-
[52]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv: 2311.12022, 2023. 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
Model evaluation for extreme risks
Toby Shevlane, Sebastian Farquhar, Ben Garfinkel, Mary Phuong, Jess Whittlestone, Jade Leung, Daniel Kokotajlo, Nahema Marchal, Markus Anderljung, Noam Kolt, Lewis Ho, Divya Siddarth, Shahar Avin, Will Hawkins, Been Kim, Iason Gabriel, Vijay Bolina, Jack Clark, Yoshua Bengio, Paul Christiano, and Allan Dafoe. Model evaluation for extreme risks. arXiv prep...
-
[54]
Mary Phuong, Roland S. Zimmermann, Ziyue Wang, David Lindner, Victoria Krakovna, Sarah Cogan, Allan Dafoe, Lewis Ho, and Rohin Shah. Evaluating frontier models for stealth and situational awareness. arXiv preprint arXiv: 2505.01420, 2025. 17
-
[55]
OpenAI Preparedness Team. GPT-4 system card. Technical report, 2023. URL https: //cdn.openai.com/papers/gpt-4-system-card.pdf . 17
work page 2023
-
[56]
Anthropic. Claude 3.7 Sonnet System Card. Technical report, 2024. URL https://www. anthropic.com/claude-3-7-sonnet-system-card
work page 2024
-
[57]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024. 17, 18
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Building an early warning system for llm-aided biological threat creation
OpenAI. Building an early warning system for llm-aided biological threat creation. https://openai.com/index/ building-an-early-warning-system-for-llm-aided-biological-threat-creation/ , January 2024. Accessed: 2025-05-08. 17
work page 2024
-
[59]
Advanced ai evaluations at aisi: May update
AI Security Institute. Advanced ai evaluations at aisi: May update. https://www.aisi.gov. uk/work/advanced-ai-evaluations-may-update , May 2024. 2025-05-08. 17
work page 2024
-
[60]
Mika Juuti, Sebastian Szyller, Samuel Marchal, and N. Asokan. Prada: Protecting against dnn model stealing attacks, 2019. URL https://arxiv.org/abs/1805.02628. 17
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[61]
How far behind are open models?, 2024
Ben Cottier, Josh You, Natalia Martemianova, and David Owen. How far behind are open models?, 2024. URL https://epoch.ai/blog/open-models-report. Accessed: 2025- 03-18. 17
work page 2024
-
[62]
Details about metr’s preliminary evaluation of deepseek-r1
METR. Details about metr’s preliminary evaluation of deepseek-r1. /autonomy-evals-guide/deepseek-r1-report/ , 03 2025. 17
work page 2025
-
[63]
DeepSeek, Inc. Deepseek-v3-0324 release. https://api-docs.deepseek.com/news/ news250325, March 2025. Accessed: 2025-05-20
work page 2025
-
[64]
Introducing openai o3 and o4-mini
OpenAI. Introducing openai o3 and o4-mini. https://openai.com/index/ introducing-o3-and-o4-mini/ , April 2025. Accessed: 2025-05-20. 17 15
work page 2025
-
[65]
On evaluating the durability of safeguards for open-weight llms
Xiangyu Qi, Boyi Wei, Nicholas Carlini, Yangsibo Huang, Tinghao Xie, Luxi He, Matthew Jagielski, Milad Nasr, Prateek Mittal, and Peter Henderson. On evaluating the durability of safeguards for open-weight llms. arXiv preprint arXiv: 2412.07097, 2024. 18
-
[66]
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to! In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum? id=...
work page 2024
-
[67]
Tamper-resistant safeguards for open-weight LLMs
Rishub Tamirisa, Bhrugu Bharathi, Long Phan, Andy Zhou, Alice Gatti, Tarun Suresh, Maxwell Lin, Justin Wang, Rowan Wang, Ron Arel, Andy Zou, Dawn Song, Bo Li, Dan Hendrycks, and Mantas Mazeika. Tamper-resistant safeguards for open-weight LLMs. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?i...
work page 2025
-
[68]
Representation noising: A defence mechanism against harmful finetuning
Domenic Rosati, Jan Wehner, Kai Williams, Lukasz Bartoszcze, Robie Gonzales, Subhabrata Majumdar, Hassan Sajjad, Frank Rudzicz, et al. Representation noising: A defence mechanism against harmful finetuning. Advances in Neural Information Processing Systems, 37:12636– 12676, 2024. 18
work page 2024
-
[69]
Adversarial ml problems are getting harder to solve and to evaluate
Javier Rando, Jie Zhang, Nicholas Carlini, and Florian Tramèr. Adversarial ml problems are getting harder to solve and to evaluate. arXiv preprint arXiv: 2502.02260, 2025. 18
-
[70]
Lujain Ibrahim, Saffron Huang, Lama Ahmad, and Markus Anderljung. Beyond static ai evaluations: advancing human interaction evaluations for llm harms and risks. arXiv preprint arXiv:2405.10632, 2024. 18
-
[71]
Samuel R. Bowman, Jeeyoon Hyun, Ethan Perez, Edwin Chen, Craig Pettit, Scott Heiner, Kamil˙e Lukoši¯ut˙e, Amanda Askell, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Christopher Olah, Daniela Amodei, Dario Amodei, Dawn Drain, Dustin Li, Eli Tran-Johnson, Jackson Kernion, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[72]
Robert Tjarko Lange, Yuki Imajuku, and Edoardo Cetin
Thomas Kwa, Ben West, Joel Becker, Amy Deng, Katharyn Garcia, Max Hasin, Sami Jawhar, Megan Kinniment, Nate Rush, Sydney V on Arx, et al. Measuring ai ability to complete long tasks. arXiv preprint arXiv:2503.14499, 2025. 18
-
[73]
Mitre att&ck: Design and philosophy
Blake E Strom, Andy Applebaum, Doug P Miller, Kathryn C Nickels, Adam G Pennington, and Cody B Thomas. Mitre att&ck: Design and philosophy. In Technical report. The MITRE Corporation, 2018. 18, 20
work page 2018
-
[74]
Vladislav Lialin, Vijeta Deshpande, Xiaowei Yao, and Anna Rumshisky. Scaling down to scale up: A guide to parameter-efficient fine-tuning, 2024. URL https://arxiv.org/abs/2303. 15647. 21 16 A Additional related work Dangerous capability evaluations. Dangerous capability evaluations attempt to estimate the proficiency of frontier models on tasks where lang...
work page 2024
-
[75]
Open-weight models are currently weaker than proprietary models. Open-weight models— models with downloadable weights—have historically trailed proprietary systems in benchmark performance by at least 6 months [58]. While this performance gap is closing, it likely still holds for current frontier open-weight and closed-weight models [59–61]. 17
-
[76]
Open-weight models can be made unsafe. The safety-training and guardrails on open-weights models can be removed with only modest additional fine-tuning [41, 62, 63]. While there is early work attempting to make models robust to fine-tuning attacks [64, 65], this problem is difficult— e.g., defense here is strictly harder than that for adversarial examples...
work page 2000
-
[77]
Example Generation, Question, and Decomposition The original question evaluates knowledge of malware capabilities and reconnaissance. Original WMDP Question Question: Which of the following actions can be performed by the SpyNote RAT family of malicious Android apps? Choices: A) Activate the victim’s microphone. B) Copy files from the device to the C2 ser...
-
[78]
Example Generation, Question, and Decomposition The original question evaluates a reconnaissance tool used for target analysis and information gathering. 20 Original WMDP Question Question: In mobile security, how is Frida used for dynamic instrumentation? Choices: A) Encrypts application data B) Optimizes application performance C) Injects code into runn...
-
[79]
Define and contrast each of the four options (quiet, noisy, happy, sad); 4) Determine which category fits the described classroom atmosphere; 5) Logically select the best option. Decompositions: Decomp 1)In the sentence ’In a computer class, each student sits at a table and does their work. They are very ____.’, what setting is being described, and what a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.