Sparse Feature Coactivation Reveals Causal Semantic Modules in Large Language Models
Pith reviewed 2026-05-19 07:59 UTC · model grok-4.3
The pith
Coactivation of sparse features identifies causal semantic modules for concepts and relations in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
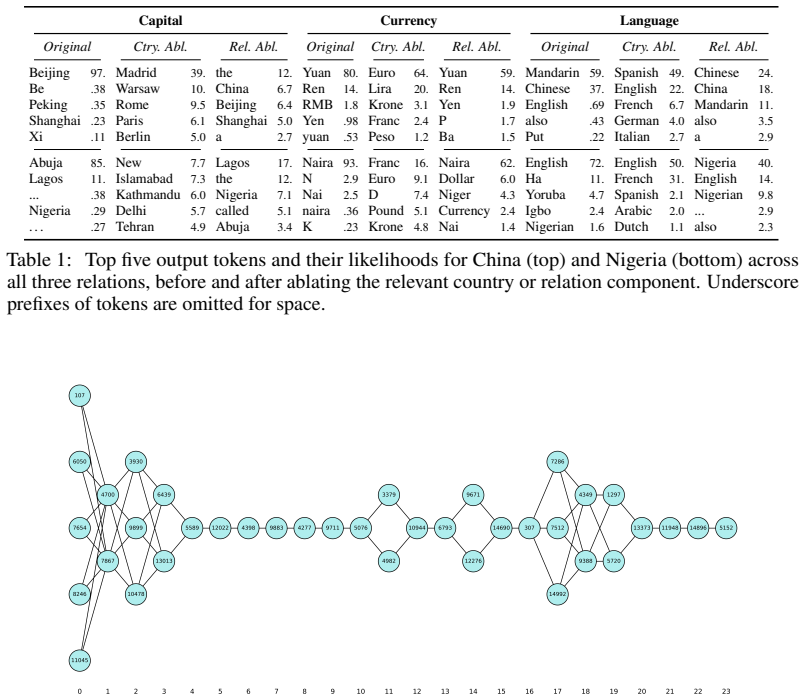
We identify semantically coherent, context-consistent network components in large language models using coactivation of sparse autoencoder features collected from just a handful of prompts. Focusing on concept-relation prediction tasks, we show that ablating these components for concepts and relations changes model outputs in predictable ways, while amplifying these components induces counterfactual responses. Notably, composing relation and concept components yields compound counterfactual outputs. Further analysis reveals that while most concept components emerge from the very first layer, more abstract relation components are concentrated in later layers. Extracted components more fully,
What carries the argument
Coactivation patterns among sparse autoencoder features collected from a handful of prompts, which identify the causal semantic modules for concepts and relations.
If this is right
- Ablating the identified components for a concept or relation changes the model's outputs for related predictions in a predictable manner.
- Amplifying the components leads to the model producing counterfactual responses.
- Composing components for a relation and a concept results in compound counterfactual outputs.
- Concept components tend to appear in early layers while more abstract relation components appear in later layers.
- The extracted components capture the relevant concepts and relations more comprehensively than individual features while remaining specific.
Where Pith is reading between the lines
- The same coactivation approach could be applied to other kinds of knowledge by selecting suitable prompt sets.
- If the modules operate independently, targeted changes to one piece of knowledge would leave unrelated pieces unaffected.
- The early appearance of concept modules and later appearance of relation modules suggests a possible order in which the model assembles factual information.
Load-bearing premise
The patterns of which features turn on together across prompts mark actual causal units in the model's processing of meaning rather than mere statistical coincidences.
What would settle it
Ablating the extracted component for a specific set of countries would fail to selectively impair the model's answers about their capitals while leaving unrelated knowledge intact.
Figures








read the original abstract
We identify semantically coherent, context-consistent network components in large language models (LLMs) using coactivation of sparse autoencoder (SAE) features collected from just a handful of prompts. Focusing on concept-relation prediction tasks, we show that ablating these components for concepts (e.g., countries and words) and relations (e.g., capital city and translation language) changes model outputs in predictable ways, while amplifying these components induces counterfactual responses. Notably, composing relation and concept components yields compound counterfactual outputs. Further analysis reveals that while most concept components emerge from the very first layer, more abstract relation components are concentrated in later layers. Lastly, we show that extracted components more comprehensively capture concepts and relations than individual features while maintaining specificity. Overall, our findings suggest a modular organization of knowledge and advance methods for efficient, targeted LLM manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to identify semantically coherent, context-consistent network components in LLMs by coactivating sparse autoencoder (SAE) features from a handful of prompts for concepts (e.g., countries, words) and relations (e.g., capital city, translation language). Ablating these components produces predictable output changes, amplifying them induces counterfactual responses, and composing concept and relation components yields compound counterfactuals. Concept components concentrate in early layers while relation components appear later; the extracted components capture concepts and relations more comprehensively than individual features while retaining specificity.
Significance. If the causal claims hold after appropriate controls, the work would provide evidence for modular organization of semantic knowledge in LLMs and a practical method for targeted, compositional manipulation using limited prompts. The compositional counterfactual results and layer-wise distribution analysis are potentially valuable contributions to mechanistic interpretability, especially if they demonstrate effects beyond what individual high-magnitude features already achieve.
major comments (2)
- [Experiments / Ablation and Amplification Results] The experimental design lacks a control that compares the coactivation-derived component against a matched set of features chosen by activation magnitude or by random sampling from the same SAE layer while preserving total intervention strength. Without this, it remains unclear whether the reported predictable changes and compositional effects arise from a genuine modular structure identified by coactivation or simply from intervening on individually important features (as the paper already shows for single features). This directly bears on the central claim that coactivation reveals causal semantic modules.
- [Methods / Prompt and Feature Selection] The prompts used to compute coactivation patterns for feature grouping appear to overlap with or closely resemble the prompts used to evaluate ablation, amplification, and composition effects. This setup risks the observed output changes being specific to the selection examples rather than demonstrating context-consistent causal modules across varied inputs.
minor comments (2)
- [Methods] Clarify the exact coactivation threshold or grouping criterion (mentioned as a free parameter) and report sensitivity analyses showing how results vary with this choice.
- [Results] Add explicit statistical tests, baseline comparisons (e.g., against random or magnitude-based interventions), and details on variance across runs or models to support the causal claims.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We have carefully considered each major comment and provide point-by-point responses below. Revisions have been made to address the concerns where possible.
read point-by-point responses
-
Referee: [Experiments / Ablation and Amplification Results] The experimental design lacks a control that compares the coactivation-derived component against a matched set of features chosen by activation magnitude or by random sampling from the same SAE layer while preserving total intervention strength. Without this, it remains unclear whether the reported predictable changes and compositional effects arise from a genuine modular structure identified by coactivation or simply from intervening on individually important features (as the paper already shows for single features). This directly bears on the central claim that coactivation reveals causal semantic modules.
Authors: We agree that a matched control for intervention strength is important for isolating the contribution of coactivation-based grouping. The original manuscript compared effects to single high-magnitude features but did not include a multi-feature baseline matched by magnitude or random selection. In the revised manuscript, we have added these control experiments: for each coactivation-derived component, we constructed matched sets consisting of the top-k features by activation magnitude and a random sample of the same cardinality from the same SAE layer, with total intervention strength preserved (via equivalent summed activation or feature count). Results show that coactivation components produce more consistent, semantically coherent, and context-generalizable output changes than either baseline. These new results are reported in an expanded Experiments section with additional figures, directly supporting the claim of modular structure identified via coactivation. revision: yes
-
Referee: [Methods / Prompt and Feature Selection] The prompts used to compute coactivation patterns for feature grouping appear to overlap with or closely resemble the prompts used to evaluate ablation, amplification, and composition effects. This setup risks the observed output changes being specific to the selection examples rather than demonstrating context-consistent causal modules across varied inputs.
Authors: We thank the referee for highlighting this methodological point. The coactivation patterns were derived from a small number of seed prompts (typically 5–10 per concept or relation) chosen to reliably elicit the target behavior. Evaluation of ablation, amplification, and composition used a substantially larger and more varied collection of test prompts, including many that differ in phrasing and content from the seed set. To strengthen the demonstration of context-consistency, the revised manuscript now explicitly documents the separation between selection and evaluation prompts, includes the complete prompt lists in an appendix, and reports additional results on a set of fully held-out prompts never used for component identification. These held-out evaluations reproduce the original effects, indicating that the modules generalize beyond the selection examples. revision: yes
Circularity Check
No circularity: claims rest on ablation experiments independent of component selection
full rationale
The paper defines components via coactivation of SAE features on a small prompt set for specific concepts and relations, then reports that ablating or amplifying these groups produces predictable output changes and compositional counterfactuals. This is an empirical intervention result, not a definitional equivalence or a fitted parameter renamed as a prediction. No equations or steps reduce the central causal-modularity claim to the input coactivation data by construction. No self-citation chains, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing justification. The derivation is therefore self-contained against external benchmarks of intervention effects.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of prompts
- coactivation threshold or grouping criterion
axioms (1)
- domain assumption Sparse autoencoder features capture interpretable semantic information
invented entities (1)
-
causal semantic modules
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify semantically coherent, context-consistent network components in large language models (LLMs) using coactivation of sparse autoencoder (SAE) features collected from just a handful of prompts.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By filtering out dense features that activate across diverse contexts, we identify semantically coherent connected components within these networks.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Minimizing Collateral Damage in Activation Steering
Activation steering is cast as constrained optimization that minimizes collateral damage by weighting perturbations according to the empirical second-moment matrix of activations instead of assuming isotropy.
Reference graph
Works this paper leans on
-
[1]
Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L. Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, Andrew Persic, Zhenyi Qi, T. Ben Thompson, Sam Zimmerman, Kelley Rivo...
work page 2025
-
[2]
Finding transformer circuits with edge pruning
Adithya Bhaskar, Alexander Wettig, Dan Friedman, and Danqi Chen. Finding transformer circuits with edge pruning. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[3]
Joseph Bloom, Curt Tigges, Anthony Duong, and David Chanin. Saelens. https://github. com/jbloomAus/SAELens, 2024
work page 2024
-
[4]
Identifying functionally important features with end-to-end sparse dictionary learning
Dan Braun, Jordan Taylor, Nicholas Goldowsky-Dill, and Lee Sharkey. Identifying functionally important features with end-to-end sparse dictionary learning. Advances in Neural Information Processing Systems, 37:107286–107325, 2024
work page 2024
-
[5]
Towards monosemanticity: Decomposing language models with dictionary learning
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Con- erly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, and ...
work page 2023
-
[6]
Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso
Arthur Conmy, Augustine N. Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso. Towards automated circuit discovery for mechanistic interpretability. In Thirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[7]
Knowledge neurons in pretrained transformers
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. Knowledge neurons in pretrained transformers. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8493–8502, 2022
work page 2022
-
[8]
Editing factual knowledge in language models
Nicola De Cao, Wilker Aziz, and Ivan Titov. Editing factual knowledge in language models. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors, Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6491–6506, Online and Punta Cana, Dominican Republic, November 2021. Association for C...
work page 2021
-
[9]
Transcoders find interpretable LLM feature circuits
Jacob Dunefsky, Philippe Chlenski, and Neel Nanda. Transcoders find interpretable LLM feature circuits. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 9
work page 2024
-
[10]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition. Transformer Circuits Thread , 2022. https://transformer- circuits.pub/2022...
work page 2022
-
[11]
A mathematical framework for transformer circuits
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
-
[12]
https://transformer-circuits.pub/2021/framework/index.html
work page 2021
-
[13]
Dissecting recall of factual associations in auto-regressive language models
Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. Dissecting recall of factual associations in auto-regressive language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12216–12235, 2023
work page 2023
-
[14]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors, Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, Online and Punta Cana, Dominican Republic, November ...
work page 2021
-
[15]
Localizing model behavior with path patching, 2023
Nicholas Goldowsky-Dill, Chris MacLeod, Lucas Sato, and Aryaman Arora. Localizing model behavior with path patching, 2023
work page 2023
-
[16]
Michael Hanna, Ollie Liu, and Alexandre Variengien. How does gpt-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model. Advances in Neural Information Processing Systems, 36:76033–76060, 2023
work page 2023
-
[17]
Linearity of relation decoding in transformer language models
Evan Hernandez, Arnab Sen Sharma, Tal Haklay, Kevin Meng, Martin Wattenberg, Jacob Andreas, Yonatan Belinkov, and David Bau. Linearity of relation decoding in transformer language models. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[18]
Efficient automated circuit discovery in transformers using contextual decomposition
Aliyah R Hsu, Georgia Zhou, Yeshwanth Cherapanamjeri, Yaxuan Huang, Anobel Odisho, Pe- ter R Carroll, and Bin Yu. Efficient automated circuit discovery in transformers using contextual decomposition. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[19]
Sparse autoencoders find highly interpretable features in language models
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[20]
Yuxiao Li, Eric J. Michaud, David D. Baek, Joshua Engels, Xiaoqing Sun, and Max Tegmark. The geometry of concepts: Sparse autoencoder feature structure. Entropy, 27(4), 2025
work page 2025
-
[21]
Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2, 2024
Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, János Kramár, Anca Dragan, Rohin Shah, and Neel Nanda. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2, 2024
work page 2024
-
[22]
Neuronpedia: Interactive reference and tooling for analyzing neural networks,
Johnny Lin. Neuronpedia: Interactive reference and tooling for analyzing neural networks,
-
[23]
Software available from neuronpedia.org
-
[24]
Sparse feature circuits: Discovering and editing interpretable causal graphs in language models
Samuel Marks, Can Rager, Eric J Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[25]
Locating and editing factual associations in GPT
Kevin Meng, David Bau, Alex J Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022
work page 2022
-
[26]
Language models implement simple Word2Vec-style vector arithmetic
Jack Merullo, Carsten Eickhoff, and Ellie Pavlick. Language models implement simple Word2Vec-style vector arithmetic. In Kevin Duh, Helena Gomez, and Steven Bethard, editors, Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 5030–504...
work page 2024
-
[27]
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D Manning. Fast model editing at scale. In International Conference on Learning Representations, 2022
work page 2022
-
[28]
Neel Nanda and Joseph Bloom. Transformerlens. https://github.com/ TransformerLensOrg/TransformerLens, 2022
work page 2022
-
[29]
Zoom in: An introduction to circuits
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An introduction to circuits. Distill, 2020. https://distill.pub/2020/circuits/zoom-in
work page 2020
-
[30]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads. arXiv preprint arXiv:2209.11895, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
OpenAI, :, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander M ˛ adry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov, Alexi Christakis, A...
work page 2024
-
[32]
How do llms acquire new knowledge? a knowledge circuits perspective on continual pre-training, 2025
Yixin Ou, Yunzhi Yao, Ningyu Zhang, Hui Jin, Jiacheng Sun, Shumin Deng, Zhenguo Li, and Huajun Chen. How do llms acquire new knowledge? a knowledge circuits perspective on continual pre-training, 2025
work page 2025
-
[33]
Improving dictionary learning with gated sparse autoencoders, 2024
Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, and Neel Nanda. Improving dictionary learning with gated sparse autoencoders, 2024
work page 2024
-
[34]
Jumping ahead: Improving reconstruction fidelity with jumprelu sparse autoencoders, 2024
Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy, Vikrant Varma, János Kramár, and Neel Nanda. Jumping ahead: Improving reconstruction fidelity with jumprelu sparse autoencoders, 2024
work page 2024
-
[35]
Lee Sharkey, Bilal Chughtai, Joshua Batson, Jack Lindsey, Jeff Wu, Lucius Bushnaq, Nicholas Goldowsky-Dill, Stefan Heimersheim, Alejandro Ortega, Joseph Bloom, Stella Biderman, Adria Garriga-Alonso, Arthur Conmy, Neel Nanda, Jessica Rumbelow, Martin Wattenberg, Nandi Schoots, Joseph Miller, Eric J. Michaud, Stephen Casper, Max Tegmark, William Saunders, D...
work page 2025
-
[36]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, Johan Ferret, Peter Liu, Pouya Tafti, Abe Friesen, Michelle Casbon, Sabela Ramos, Ravin Kumar, Charline Le Lan, Sammy Jerome, Anton Tsitsulin, Nino Vieillard, Piotr Stanczyk, Sertan Girgin, ...
work page 2024
-
[37]
Interpretability in the wild: a circuit for indirect object identification in GPT-2 small
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[38]
Transformers: State-of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. Transformers: State-of-the-art na...
work page 2020
-
[39]
Knowledge circuits in pretrained transformers
Yunzhi Yao, Ningyu Zhang, Zekun Xi, Mengru Wang, Ziwen Xu, Shumin Deng, and Huajun Chen. Knowledge circuits in pretrained transformers. In A. Globerson, L. Mackey, D. Bel- grave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 118571–118602. Curran Associates, Inc., 2024. 13 Country ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.