A Survey on MLLM-based Visually Rich Document Understanding: Methods, Challenges, and Emerging Trends
Pith reviewed 2026-05-19 04:35 UTC · model grok-4.3
The pith
Multimodal large language models advance visually rich document understanding with both OCR-based and OCR-free methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
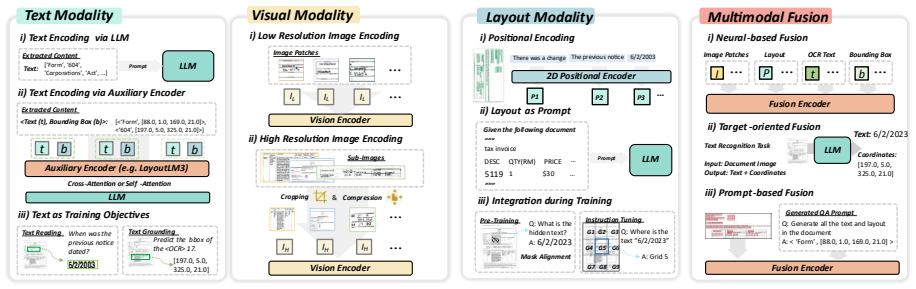
Visually Rich Document Understanding has become a pivotal area driven by the need to interpret documents with intricate visual, textual, and structural elements. Multimodal Large Language Models demonstrate significant promise in this domain through both OCR-based and OCR-free approaches for information extraction from document images. The survey reviews recent advances with a focus on techniques for representing and integrating textual, visual, and layout features and on training paradigms including pretraining, instruction tuning, and training strategies. It addresses challenges such as data scarcity, multi-page and multilingual documents, and integration of retrieval-augmented generation,
What carries the argument
Techniques for representing and integrating textual, visual, and layout features together with training paradigms of pretraining and instruction tuning.
Load-bearing premise
Focusing on feature representation and integration techniques plus training paradigms sufficiently captures the core advances and challenges in MLLM-based visually rich document understanding.
What would settle it
A high-performing VRDU system that relies on a paradigm outside feature integration and standard pretraining or instruction tuning would test whether the survey's two-aspect organization holds.
Figures

read the original abstract
Visually Rich Document Understanding (VRDU) has become a pivotal area of research, driven by the need to automatically interpret documents that contain intricate visual, textual, and structural elements. Recently, Multimodal Large Language Models (MLLMs) have demonstrated significant promise in this domain, including both OCR-based and OCR-free approaches for information extraction from document images. This survey reviews recent advances in MLLM-based VRDU, highlighting emerging trends and promising research directions with a focus on two key aspects: (1) techniques for representing and integrating textual, visual, and layout features; (2) training paradigms, including pretraining, instruction tuning, and training strategies. Moreover, we address challenges such as data scarcity, handling multi-page and multilingual documents, and integrating emerging trends such as Retrieval-Augmented Generation and agentic frameworks. Our analysis offers a roadmap for advancing MLLM-based VRDU toward more scalable, reliable, and adaptable systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a literature survey on Multimodal Large Language Models (MLLMs) applied to Visually Rich Document Understanding (VRDU). It organizes recent work around two axes—techniques for representing and fusing textual, visual, and layout features, and training paradigms (pretraining, instruction tuning, and related strategies)—while also covering challenges such as data scarcity, multi-page and multilingual documents, and emerging directions including Retrieval-Augmented Generation and agentic systems. The survey positions these elements as a roadmap toward more scalable and reliable MLLM-based VRDU systems, explicitly distinguishing OCR-based and OCR-free approaches.
Significance. If the coverage proves balanced and up-to-date, the survey would provide a timely organizing framework for a rapidly evolving intersection of multimodal models and document understanding. The explicit taxonomy around feature integration and training strategies, together with discussion of RAG and agentic trends, could help researchers identify gaps; the inclusion of both OCR-based and OCR-free lines of work is a constructive choice that avoids over-narrowing the scope.
major comments (2)
- [§4] §4 (Challenges): the treatment of data scarcity is largely descriptive and does not quantify the scale of existing VRDU benchmarks or systematically compare data-augmentation strategies across the cited MLLM works; this weakens the claim that the survey supplies a clear roadmap for overcoming the bottleneck.
- [§2.2] §2.2 (Feature Integration): the subsection on layout-aware fusion cites several architectures but does not include a comparative table of input representations (e.g., bounding-box tokens vs. grid features vs. graph-based layouts); without such a summary the reader cannot easily assess which fusion approaches dominate recent performance gains.
minor comments (3)
- [Abstract and §2] The abstract states that the survey addresses 'both OCR-based and OCR-free approaches' yet the main text does not consistently tag each reviewed method with its OCR dependency; adding a column or icon in the method overview table would improve clarity.
- [§3] Several citations in §3 (Training Paradigms) refer to arXiv preprints without indicating whether the works have since appeared in peer-reviewed venues; updating these references would strengthen the survey's archival value.
- [Figure 1] Figure 1 (taxonomy diagram) uses overlapping boxes for 'pretraining' and 'instruction tuning' without an explicit legend; a short caption clarifying the distinction would prevent misinterpretation.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our survey and the recommendation for minor revision. We have carefully reviewed the major comments and provide point-by-point responses below. We agree with both suggestions and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Challenges): the treatment of data scarcity is largely descriptive and does not quantify the scale of existing VRDU benchmarks or systematically compare data-augmentation strategies across the cited MLLM works; this weakens the claim that the survey supplies a clear roadmap for overcoming the bottleneck.
Authors: We agree that the current treatment of data scarcity in §4 remains largely descriptive. In the revised version, we will add quantitative information on the scale of major VRDU benchmarks (e.g., number of documents, pages, and annotations in datasets such as DocVQA, FUNSD, CORD, and SROIE) and include a systematic comparison of data-augmentation strategies used across the cited MLLM works, such as synthetic data generation, layout-aware perturbations, and few-shot prompting. These additions will provide a more concrete roadmap for addressing the data bottleneck. revision: yes
-
Referee: [§2.2] §2.2 (Feature Integration): the subsection on layout-aware fusion cites several architectures but does not include a comparative table of input representations (e.g., bounding-box tokens vs. grid features vs. graph-based layouts); without such a summary the reader cannot easily assess which fusion approaches dominate recent performance gains.
Authors: We thank the referee for this helpful suggestion. We will insert a new comparative table in §2.2 that summarizes input representations for layout-aware fusion, covering bounding-box tokens, grid features, graph-based layouts, and related variants. The table will list key characteristics, computational trade-offs, and representative MLLM works for each approach, enabling readers to more readily identify which methods have driven recent performance improvements. revision: yes
Circularity Check
No significant circularity; standard survey taxonomy
full rationale
This is a literature review paper whose central structure partitions prior work on MLLM-based VRDU into two high-level categories—techniques for representing/integrating textual/visual/layout features and training paradigms (pretraining, instruction tuning)—plus discussion of challenges and trends. These categories are drawn from and justified by citations to external prior publications rather than any self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation chain. No equations, derivations, or quantitative claims are present that could reduce to the paper's own inputs by construction. The organizing premise is a conventional and externally grounded taxonomy for a survey, with all substantive content traceable to cited literature.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
This survey reviews recent advances in MLLM-based VRDU, highlighting emerging trends ... with a focus on two key aspects: (1) techniques for representing and integrating textual, visual, and layout features; (2) training paradigms, including pretraining, instruction tuning, and training strategies.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
methods for encoding and fusing textual, visual, and layout features
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Visual Late Chunking: An Empirical Study of Contextual Chunking for Efficient Visual Document Retrieval
ColChunk adaptively chunks visual document patches into contextual multi-vectors via clustering, cutting storage by over 90% while raising average nDCG@5 by 9 points.
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. http://arxiv.org/abs/2308.12966 Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [2]
-
[3]
Galal M Binmakhashen and Sabri A Mahmoud. 2019. Document layout analysis: a comprehensive survey. ACM Computing Surveys (CSUR), 52(6):1--36
work page 2019
-
[4]
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Marcella Cornia, and Rita Cucchiara. 2024. The revolution of multimodal large language models: A survey. In Findings of the Association for Computational Linguistics: ACL 2024, pages 13590--13618
work page 2024
-
[5]
Wenhu Chen, Han Zhu, Wenhao Wang, Kai-Wei Chang, William Yang Zhang, and William Wang. 2020. Tabfact: A large-scale dataset for table-based fact verification. In International Conference on Learning Representations (ICLR)
work page 2020
- [6]
- [7]
- [8]
-
[9]
Yihao Ding, Soyeon Caren Han, Zechuan Li, and Hyunsuk Chung. 2024 a . https://doi.org/10.48550/arXiv.2410.01609 David: Domain adaptive visually-rich document understanding with synthetic insights . arXiv preprint arXiv:2410.01609
-
[10]
Yihao Ding, Jean Lee, and Soyeon Caren Han. 2024 b . https://doi.org/10.48550/arXiv.2408.01287 Deep learning based visually rich document content understanding: A survey . arXiv preprint arXiv:2408.01287
-
[11]
Yihao Ding, Siqu Long, Jiabin Huang, Kaixuan Ren, Xingxiang Luo, Hyunsuk Chung, and Soyeon Caren Han. 2023. https://doi.org/10.1145/3539618.3591886 Form-nlu: Dataset for the form natural language understanding . In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2807--2816. ACM
-
[12]
Yihao Ding, Kaixuan Ren, Jiabin Huang, Siwen Luo, and Soyeon Caren Han. 2024 c . https://www.ijcai.org/proceedings/2024/690 Mmvqa: A comprehensive dataset for investigating multipage multimodal information retrieval in pdf-based visual question answering . In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI,...
work page 2024
-
[13]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, G Heigold, S Gelly, et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations
work page 2020
-
[14]
Hao Feng, Qi Liu, Hao Liu, Jingqun Tang, Wengang Zhou, Houqiang Li, and Can Huang. 2024. https://doi.org/10.48550/arXiv.2311.11810 Docpedia: Unleashing the power of large multimodal model in the frequency domain for versatile document understanding . Science China Information Sciences, 67(12):1--14
- [15]
-
[16]
Pranay Gupta, Minesh Mathew, C.V. Jawahar, and Marcus Liwicki. 2022. Infovqa: Visual question answering on infographics with a multi-modal entity graph. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
work page 2022
- [17]
-
[18]
Adam W Harley, Alex Ufkes, and Konstantinos G Derpanis. 2015. https://doi.org/10.1109/ICDAR.2015.7333910 Evaluation of deep convolutional nets for document image classification and retrieval . In 2015 13th International Conference on Document Analysis and Recognition (ICDAR), pages 991--995. IEEE
-
[19]
Jiabang He, Lei Wang, Yi Hu, Ning Liu, Hui Liu, Xing Xu, and Heng Tao Shen. 2023. https://doi.org/10.1109/ICCV51070.2023.01785 Icl-d3ie: In-context learning with diverse demonstrations updating for document information extraction . In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 19485--19494. IEEE
-
[20]
Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, and Sungrae Park. 2022. https://doi.org/10.1609/aaai.v36i10.21322 Bros: A pre-trained language model focusing on text and layout for better key information extraction from documents . In Proceedings of the AAAI Conference on Artificial Intelligence, pages 10767--10775
-
[21]
Anwen Hu, Haiyang Xu, Jiabo Ye, Ming Yan, Liang Zhang, Bo Zhang, Ji Zhang, Qin Jin, Fei Huang, and Jingren Zhou. 2024 a . https://aclanthology.org/2024.findings-emnlp.175 mplug-docowl 1.5: Unified structure learning for ocr-free document understanding . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 3096--3120
work page 2024
- [22]
-
[23]
Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, and Furu Wei. 2022. https://doi.org/10.1145/3503161.3548112 Layoutlmv3: Pre-training for document ai with unified text and image masking . In Proceedings of the 30th ACM International Conference on Multimedia, pages 4083--4091. ACM
-
[24]
Guillaume Jaume, Hazim Kemal Ekenel, and Jean-Philippe Thiran. 2019. https://doi.org/10.1109/ICDARW.2019.10029 Funsd: A dataset for form understanding in noisy scanned documents . In 2019 International Conference on Document Analysis and Recognition Workshops (ICDARW), volume 2, pages 1--6. IEEE
-
[25]
Mengzhao Jia, Wenhao Yu, Kaixin Ma, Tianqing Fang, Zhihan Zhang, Siru Ouyang, Hongming Zhang, Meng Jiang, and Dong Yu. 2024. https://doi.org/10.48550/arXiv.2410.01744 Leopard: A vision language model for text-rich multi-image tasks . arXiv preprint arXiv:2410.01744
-
[26]
Anoop R Katti, Christian Reisswig, Cordula Guder, Sebastian Brarda, Steffen Bickel, Johannes H \"o hne, and Jean Baptiste Faddoul. 2018. https://aclanthology.org/D18-1476/ Chargrid: Towards understanding 2d documents . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4459--4469. Association for Computational...
work page 2018
-
[27]
Geewook Kim, Teakgyu Hong, Moonbin Yim, JeongYeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, and Seunghyun Park. 2022. https://doi.org/10.1007/978-3-031-19815-1\_29 Ocr-free document understanding transformer . In Computer Vision--ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23--27, 2022, Proceedings, Par...
-
[28]
Sungnyun Kim, Haofu Liao, Srikar Appalaraju, Peng Tang, Zhuowen Tu, Ravi Kumar Satzoda, R Manmatha, Vijay Mahadevan, and Stefano Soatto. 2024. https://aclanthology.org/2024.emnlp-main.185 Dockd: Knowledge distillation from llms for open-world document understanding models . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Pro...
work page 2024
-
[29]
Marcel Lamott, Yves-Noel Weweler, Adrian Ulges, Faisal Shafait, Dirk Krechel, and Darko Obradovic. 2024. https://doi.org/10.1007/978-3-031-70546-5\_9 Lapdoc: Layout-aware prompting for documents . In International Conference on Document Analysis and Recognition, pages 142--159. Springer
-
[30]
David D Lewis, Gady Agam, Shlomo Argamon, Ophir Frieder, David Grossman, and James Heard. 2006. Building a test collection for complex document information processing. In Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval, pages 665--666
work page 2006
-
[31]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International Conference on Machine Learning (ICML)
work page 2023
-
[32]
Xin Li, Yunfei Wu, Xinghua Jiang, Zhihao Guo, Mingming Gong, Haoyu Cao, Yinsong Liu, Deqiang Jiang, and Xing Sun. 2024. https://doi.org/10.1109/CVPR52733.2024.01472 Enhancing visual document understanding with contrastive learning in large visual-language models . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages ...
-
[33]
Wenhui Liao, Jiapeng Wang, Hongliang Li, Chengyu Wang, Jun Huang, and Lianwen Jin. 2024. https://doi.org/10.48550/arXiv.2408.15045 Doclayllm: An efficient and effective multi-modal extension of large language models for text-rich document understanding . arXiv preprint arXiv:2408.15045
-
[34]
Chaohu Liu, Kun Yin, Haoyu Cao, Xinghua Jiang, Xin Li, Yinsong Liu, Deqiang Jiang, Xing Sun, and Linli Xu. 2024 a . https://doi.org/10.1109/CVPR52733.2024.01471 Hrvda: High-resolution visual document assistant . In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15534--15545
-
[35]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2024 b . http://papers.nips.cc/paper\_files/paper/2023/hash/6dcf277ea32ce3288914faf369fe6de0-Abstract-Conference.html Visual instruction tuning . Advances in neural information processing systems, 36
work page 2024
- [36]
- [37]
-
[38]
Chuwei Luo, Yufan Shen, Zhaoqing Zhu, Qi Zheng, Zhi Yu, and Cong Yao. 2024. https://doi.org/10.1109/CVPR52733.2024.01480 Layoutllm: Layout instruction tuning with large language models for document understanding . In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024 , pages 15630--15640. IEEE
- [39]
-
[40]
Pengyuan Lyu, Yulin Li, Hao Zhou, Weihong Ma, Xingyu Wan, Qunyi Xie, Liang Wu, Chengquan Zhang, Kun Yao, Errui Ding, et al. 2024. https://doi.org/10.48550/arXiv.2405.21013 Structextv3: An efficient vision-language model for text-rich image perception, comprehension, and beyond . arXiv preprint arXiv:2405.21013
-
[41]
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. 2021. https://doi.org/10.1109/WACV48630.2021.00225 Docvqa: A dataset for vqa on document images . In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2200--2209. IEEE
- [42]
-
[43]
OpenAI . 2024. Hello gpt-4o. https://openai.com/index/hello-gpt-4o/
work page 2024
-
[44]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730--27744
work page 2022
-
[45]
Jaeyoo Park, Jin Young Choi, Jeonghyung Park, and Bohyung Han. 2024. Hierarchical visual feature aggregation for ocr-free document understanding. Advances in Neural Information Processing Systems, 37:105972--105996
work page 2024
-
[46]
Seunghyun Park, Seung Shin, Bado Lee, Junyeop Lee, Jaeheung Surh, Minjoon Seo, and Hwalsuk Lee. 2019. https://openreview.net/pdf?id=SJl3z659UH Cord: a consolidated receipt dataset for post-ocr parsing . In Workshop on Document Intelligence at NeurIPS 2019
work page 2019
-
[47]
Panupong Pasupat and Percy Liang. 2015. Compositional semantic parsing on semi-structured tables. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics (ACL)
work page 2015
-
[48]
Vincent Perot, Kai Kang, Florian Luisier, Guolong Su, Xiaoyu Sun, Ramya Sree Boppana, Zilong Wang, Zifeng Wang, Jiaqi Mu, Hao Zhang, et al. 2024. https://doi.org/10.18653/v1/2024.findings-acl.899 Lmdx: Language model-based document information extraction and localization . In Findings of the Association for Computational Linguistics ACL 2024, pages 15140--15168
-
[49]
Minenobu Seki, Masakazu Fujio, Takeshi Nagasaki, Hiroshi Shinjo, and Katsumi Marukawa. 2007. https://doi.org/10.1109/ICDAR.2007.4377003 Information management system using structure analysis of paper/electronic documents and its applications . In Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), volume 2, pages 689--693. IEEE
- [50]
-
[51]
Maxim Sidorov, Amanpreet Singh, Yu Li, Jianfeng Liao, Ming Liao, Yaxing Wang, Lichao Wang, Shouling Gong, Chen Change Loy, and Xiang Bai. 2020. Textcaps: A dataset for image captioning with reading. In Proceedings of the European Conference on Computer Vision (ECCV)
work page 2020
-
[52]
Amanpreet Singh, Vedanuj Natarajan, Yu Jiang, Xinlei Chen, Meet Shah, Marcus Rohrbach, Dhruv Batra, Devi Parikh, and Aniruddha Krishnamurthy. 2019. Textvqa: Visual question answering with reading. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
work page 2019
-
[53]
Ryota Tanaka, Taichi Iki, Kyosuke Nishida, Kuniko Saito, and Jun Suzuki. 2024. https://doi.org/10.1609/aaai.v38i17.29874 Instructdoc: A dataset for zero-shot generalization of visual document understanding with instructions . In Proceedings of the AAAI conference on artificial intelligence, pages 19071--19079. AAAI Press
-
[54]
Rub \`e n Tito, Dimosthenis Karatzas, and Ernest Valveny. 2023. https://doi.org/10.1016/j.patcog.2023.109834 Hierarchical multimodal transformers for multipage docvqa . Pattern Recognition, 144:109834
-
[55]
Dongsheng Wang, Natraj Raman, Mathieu Sibue, Zhiqiang Ma, Petr Babkin, Simerjot Kaur, Yulong Pei, Armineh Nourbakhsh, and Xiaomo Liu. 2024 a . https://doi.org/10.18653/v1/2024.acl-long.463 Docllm: A layout-aware generative language model for multimodal document understanding . In Proceedings of the 62nd Annual Meeting of the Association for Computational ...
-
[56]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. 2024 b . https://doi.org/10.48550/arXiv.2409.12191 Qwen2-vl: Enhancing vision-language model's perception of the world at any ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.12191 2024
-
[57]
Wenhai Wang, Enze Xie, Xiang Li, Wenbo Hou, Tong Lu, Gang Yu, and Shuai Shao. 2019. Shape robust text detection with progressive scale expansion network. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9336--9345
work page 2019
- [58]
- [59]
-
[60]
Toyohide Watanabe, Qin Luo, and Noboru Sugie. 1995. https://doi.org/10.1109/34.385976 Layout recognition of multi-kinds of table-form documents . IEEE Transactions on Pattern Analysis and Machine Intelligence, 17(4):432--445
-
[61]
Haoran Wei, Lingyu Kong, Jinyue Chen, Liang Zhao, Zheng Ge, Jinrong Yang, Jianjian Sun, Chunrui Han, and Xiangyu Zhang. 2024. Vary: Scaling up the vision vocabulary for large vision-language model. In European Conference on Computer Vision, pages 408--424. Springer
work page 2024
-
[62]
Xudong Xie, Hao Yan, Liang Yin, Yang Liu, Jing Ding, Minghui Liao, Yuliang Liu, Wei Chen, and Xiang Bai. 2025. http://arxiv.org/abs/2410.05970 Pdf-wukong: A large multimodal model for efficient long pdf reading with end-to-end sparse sampling
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, et al. 2021. https://doi.org/10.18653/v1/2021.acl-long.201 Layoutlmv2: Multi-modal pre-training for visually-rich document understanding . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 1...
-
[64]
Xiao Yang, Ersin Yumer, Paul Asente, Mike Kraley, Daniel Kifer, and C Lee Giles. 2017. https://doi.org/10.1109/CVPR.2017.462 Learning to extract semantic structure from documents using multimodal fully convolutional neural networks . In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5315--5324. IEEE Computer Society
- [65]
-
[66]
Jiabo Ye, Anwen Hu, Haiyang Xu, Qinghao Ye, Ming Yan, Guohai Xu, Chenliang Li, Junfeng Tian, Qi Qian, Ji Zhang, et al. 2023 b . https://doi.org/10.18653/v1/2023.findings-emnlp.187 Ureader: Universal ocr-free visually-situated language understanding with multimodal large language model . In Findings of the Association for Computational Linguistics: EMNLP 2...
-
[67]
Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. 2023 c . mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [68]
- [69]
-
[70]
Jiaxin Zhang, Wentao Yang, Songxuan Lai, Zecheng Xie, and Lianwen Jin. 2024 a . https://doi.org/10.48550/arXiv.2406.19101 Dockylin: A large multimodal model for visual document understanding with efficient visual slimming . arXiv preprint arXiv:2406.19101
- [71]
-
[72]
Ruiyi Zhang, Yufan Zhou, Jian Chen, Jiuxiang Gu, Changyou Chen, and Tong Sun. 2024 c . https://doi.org/10.48550/arXiv.2407.19185 Llava-read: Enhancing reading ability of multimodal language models . arXiv preprint arXiv:2407.19185
- [73]
-
[74]
Xu Zhong, Jianbin Tang, and Antonio Jimeno Yepes. 2019. https://doi.org/10.1109/ICDAR.2019.00166 Publaynet: largest dataset ever for document layout analysis . In 2019 International Conference on Document Analysis and Recognition (ICDAR), pages 1015--1022. IEEE
-
[75]
Yuke Zhu, Yue Zhang, Dongdong Liu, Chi Xie, Zihua Xiong, Bo Zheng, and Sheng Guo. 2025 a . https://openreview.net/forum?id=Dj9a4zQsSl Enhancing document understanding with group position embedding: A novel approach to incorporate layout information . In The Thirteenth International Conference on Learning Representations
work page 2025
- [76]
-
[77]
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[78]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.