LLMEval-Fair: A Large-Scale Longitudinal Study on Robust and Fair Evaluation of Large Language Models
Pith reviewed 2026-05-19 00:35 UTC · model grok-4.3
The pith
A dynamic evaluation framework sampling from a fixed 220k-question bank shows leading LLMs reach a performance ceiling on knowledge recall while static benchmarks miss contamination.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
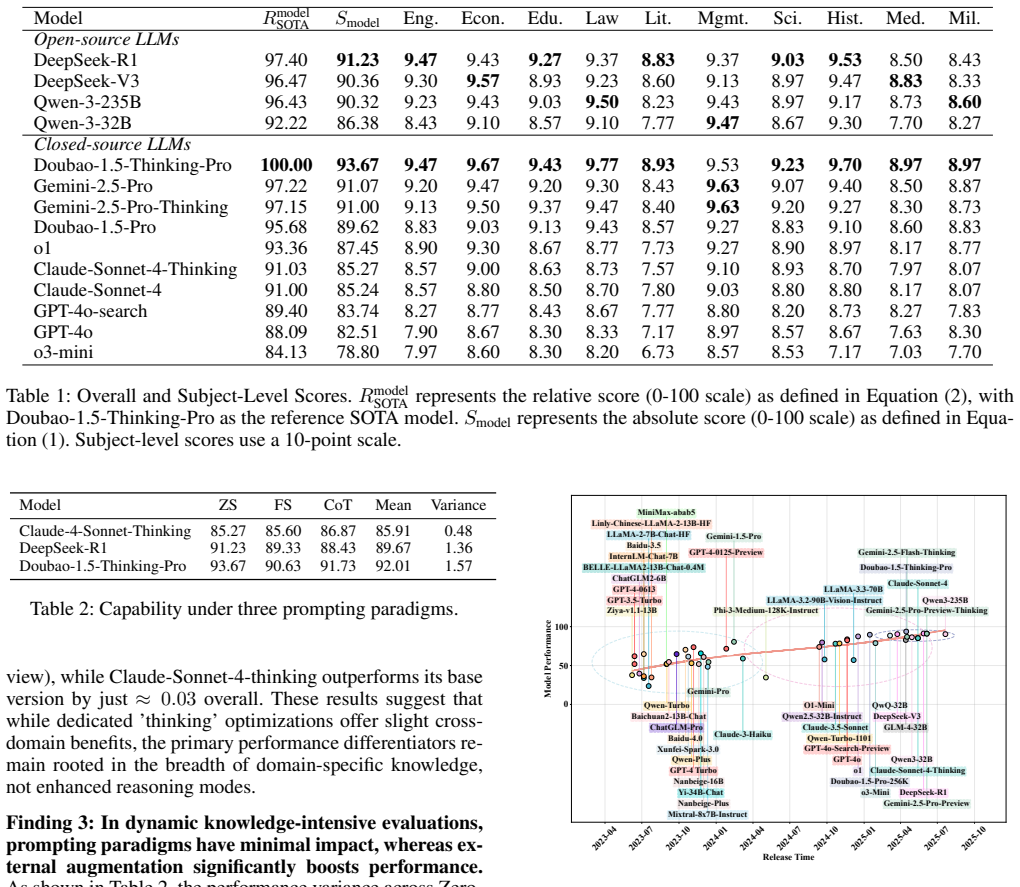
LLMEval-Fair dynamically samples unseen questions from a 220k-question bank for each run, applies contamination-resistant curation and an anti-cheating architecture, then uses a calibrated LLM-as-a-judge with 90 percent human agreement plus relative ranking to produce stable, fair comparisons; the resulting 30-month longitudinal data on nearly 60 models shows a clear performance ceiling on knowledge memorization and reveals contamination that static benchmarks leave undetected.
What carries the argument
The LLMEval-Fair framework, which draws fresh test sets from a fixed 220k-question bank and routes them through an automated pipeline of contamination checks, anti-cheating safeguards, and an LLM judge calibrated to 90 percent human agreement.
If this is right
- Models hit a measurable ceiling on knowledge-memorization tasks once contamination is removed.
- Static benchmarks systematically underestimate contamination that dynamic sampling detects.
- Ranking stability remains high across repeated dynamic evaluations, supporting the method's consistency.
- Trustworthy assessment of LLM capabilities requires moving beyond fixed public test sets.
Where Pith is reading between the lines
- Evaluation practices may need to treat question banks as consumable resources that must be refreshed or protected over time.
- Training pipelines could shift emphasis from maximizing scores on public tests toward generalization that survives fresh sampling.
- Similar dynamic approaches might apply to other domains where public benchmarks risk rapid obsolescence.
Load-bearing premise
The 220k-question bank stays free of contamination across 30 months and the LLM judge measures genuine capabilities rather than introducing its own systematic biases.
What would settle it
A later run showing continued score gains on the dynamic sets without bound, or direct evidence that training corpora have incorporated questions from the bank.
Figures









read the original abstract
Existing evaluation of Large Language Models (LLMs) on static benchmarks is vulnerable to data contamination and leaderboard overfitting, critical issues that obscure true model capabilities. To address this, we introduce LLMEval-Fair, a framework for dynamic evaluation of LLMs. LLMEval-Fair is built on a proprietary bank of 220k graduate-level questions, from which it dynamically samples unseen test sets for each evaluation run. Its automated pipeline ensures integrity via contamination-resistant data curation, a novel anti-cheating architecture, and a calibrated LLM-as-a-judge process achieving 90% agreement with human experts, complemented by a relative ranking system for fair comparison. A 30-month longitudinal study of nearly 60 leading models reveals a performance ceiling on knowledge memorization and exposes data contamination vulnerabilities undetectable by static benchmarks. The framework demonstrates exceptional robustness in ranking stability and consistency, providing strong empirical validation for the dynamic evaluation paradigm. LLMEval-Fair offers a robust and credible methodology for assessing the true capabilities of LLMs beyond leaderboard scores, promoting the development of more trustworthy evaluation standards. Our code and data are publicly available at https://github.com/llmeval/LLMEval-Fair.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LLMEval-Fair, a dynamic evaluation framework for LLMs built on a proprietary bank of 220k graduate-level questions. It dynamically samples unseen test sets per run, incorporates contamination-resistant curation and a novel anti-cheating architecture, and employs a calibrated LLM-as-a-judge achieving 90% agreement with human experts alongside a relative ranking system. A 30-month longitudinal study of nearly 60 leading models is presented to demonstrate a performance ceiling on knowledge memorization, reveal data contamination vulnerabilities undetectable by static benchmarks, and validate the framework's robustness in ranking stability and consistency.
Significance. If the central empirical claims hold, the work supplies large-scale longitudinal evidence favoring dynamic over static evaluation for LLMs, highlighting contamination risks and a memorization ceiling while offering a reproducible pipeline that could shift community standards toward more trustworthy assessments.
major comments (3)
- [Methodology and Longitudinal Study sections] The central claims of a knowledge-memorization ceiling and undetectable contamination exposure rest on the assumption that the proprietary 220k-question bank remains fully uncontaminated across all 30 months and all dynamically sampled sets. The manuscript describes an anti-cheating architecture but provides no public contamination audit logs, per-run verification details, or external audit results, leaving this load-bearing premise unverifiable.
- [LLM-as-a-Judge Calibration subsection] The LLM-as-a-judge process is reported to achieve 90% agreement with humans, yet the manuscript lacks per-model-family agreement breakdowns and any analysis of whether judge-model similarity correlates with score inflation over the study period. This directly affects the claim that scores reflect true capabilities rather than judge-specific biases.
- [Results on Ranking Robustness] The reported ranking stability and consistency advantages over static benchmarks depend on every sampled test set remaining unseen by the evaluated models. Without quantitative evidence (e.g., contamination detection rates or temporal leakage metrics) for the full model cohort, the superiority claim is difficult to interpret.
minor comments (2)
- [Framework Architecture] Clarify the exact sampling procedure and anti-cheating checks in the methods to allow readers to assess reproducibility from the public code release.
- [Experimental Setup] The abstract states 'nearly 60 leading models'; provide the precise count and selection criteria in the experimental setup for transparency.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We address each major comment point by point below, with honest indications of where revisions will be made and where proprietary constraints limit further disclosure.
read point-by-point responses
-
Referee: [Methodology and Longitudinal Study sections] The central claims of a knowledge-memorization ceiling and undetectable contamination exposure rest on the assumption that the proprietary 220k-question bank remains fully uncontaminated across all 30 months and all dynamically sampled sets. The manuscript describes an anti-cheating architecture but provides no public contamination audit logs, per-run verification details, or external audit results, leaving this load-bearing premise unverifiable.
Authors: We acknowledge that full public contamination audit logs and external audit results cannot be released due to the proprietary status of the 220k-question bank. The anti-cheating architecture, dynamic sampling of unseen sets, and contamination-resistant curation are described in the Methodology section; the 30-month longitudinal results provide supporting evidence via the observed performance ceiling, which would be inconsistent with widespread undetected contamination. We will add a new subsection with internal per-run verification procedures and anonymized temporal checks to improve transparency. revision: partial
-
Referee: [LLM-as-a-Judge Calibration subsection] The LLM-as-a-judge process is reported to achieve 90% agreement with humans, yet the manuscript lacks per-model-family agreement breakdowns and any analysis of whether judge-model similarity correlates with score inflation over the study period. This directly affects the claim that scores reflect true capabilities rather than judge-specific biases.
Authors: We agree that these details would strengthen the calibration section. The revised manuscript will include per-model-family agreement breakdowns in an expanded table and a new analysis of judge-model similarity (via embedding overlap) versus score trends across the study period. Internal checks show no significant correlation supporting bias-driven inflation, and this will be documented formally. revision: yes
-
Referee: [Results on Ranking Robustness] The reported ranking stability and consistency advantages over static benchmarks depend on every sampled test set remaining unseen by the evaluated models. Without quantitative evidence (e.g., contamination detection rates or temporal leakage metrics) for the full model cohort, the superiority claim is difficult to interpret.
Authors: We will expand the Results section to report quantitative outputs from the anti-cheating system, including contamination detection rates across the ~60-model cohort and temporal leakage metrics demonstrating stable performance without upward drift on repeated question themes. These additions will directly support the ranking robustness claims. revision: yes
- Release of full public contamination audit logs or external audit results for the proprietary question bank
Circularity Check
No significant circularity; empirical results rest on external evaluations and public release
full rationale
The paper describes a dynamic evaluation framework and reports longitudinal observations from running it on ~60 models over 30 months. Central claims (performance ceiling, contamination exposure, ranking stability) are presented as direct outcomes of the sampled test sets and LLM-as-a-judge scores rather than any fitted parameter renamed as a prediction, self-definitional loop, or load-bearing self-citation. The 220k bank and anti-cheating architecture are described as inputs to the process, not derived from the reported results. Public code release further separates the reported findings from internal construction. No equations or uniqueness theorems are invoked that reduce the conclusions to the paper's own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An LLM-as-a-judge process can be calibrated to reach 90% agreement with human experts for reliable scoring.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
proprietary bank of 220k graduate-level questions... dynamically samples unseen test sets... two-layer anti-cheating architecture... LLM-as-a-Judge... relative ranking system
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Cohen’s κ... 90% agreement with human experts... Spearman’s ρ... negligible variance under multi-round resampling
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Coordinates of Capability: A Unified MTMM-Geometric Framework for LLM Evaluation
A new MTMM-geometric framework unifies LLM evaluation metrics into three latent dimensions to separate method variance from true capabilities.
-
DynT2I-Eval: A Dynamic Evaluation Framework for Text-to-Image Models
DynT2I-Eval creates fresh prompts via dimension decomposition and dynamic sampling to evaluate text-to-image models on text alignment, quality, and aesthetics while maintaining a stable leaderboard.
-
Coordinates of Capability: A Unified MTMM-Geometric Framework for LLM Evaluation
A systematization of knowledge unifies nine LLM metrics into three orthogonal latent dimensions via an MTMM-geometric framework to improve construct validity in evaluation.
Reference graph
Works this paper leans on
-
[1]
The Vulnera- bility of Language Model Benchmarks: Do They Accurately Reflect True LLM Performance? CoRR, abs/2412.03597. Chang, Y .; Wang, X.; Wang, J.; Wu, Y .; Zhu, K.; Chen, H.; Yang, L.; Yi, X.; Wang, C.; Wang, Y .; Ye, W.; Zhang, Y .; Chang, Y .; Yu, P. S.; Yang, Q.; and Xie, X
-
[2]
A survey on evaluation of large language models
A Survey on Evaluation of Large Language Models. CoRR, abs/2307.03109. Chen, S.; Pusarla, P.; and Ray, B
-
[3]
Dynamic Bench- marking of Reasoning Capabilities in Code Large Language Models Under Data Contamination. CoRR, abs/2503.04149. Chiang, W.-L.; Zheng, L.; Sheng, Y .; Angelopoulos, A. N.; Li, T.; Li, D.; Zhu, B.; Zhang, H.; Jordan, M.; Gonzalez, J. E.; and Stoica, I
-
[4]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems. CoRR, abs/2110.14168. Dekoninck, J.; M ¨uller, M. N.; Baader, M.; Fischer, M.; and Vechev, M. T
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2402.02823 , year=
Evading Data Contamination Detection for Language Models is (too) Easy. CoRR, abs/2402.02823. Deng, C.; Zhao, Y .; Tang, X.; Gerstein, M.; and Cohan, A. 2024a. Investigating Data Contamination in Modern Bench- marks for Large Language Models. In Duh, K.; G ´omez- Adorno, H.; and Bethard, S., eds., Proceedings of the 2024 Conference of the North American C...
-
[6]
https://github.com/ tatsu-lab/alpaca eval
AlpacaEval: An Automatic Evaluator for Instruction-following Language Models. https://github.com/ tatsu-lab/alpaca eval. Accessed: 2025-07-31. Laskar, M. T. R.; Alqahtani, S.; Bari, M. S.; Rahman, M.; Khan, M. A. M.; Khan, H.; Jahan, I.; Bhuiyan, A.; Tan, C.; Parvez, M. R.; Hoque, E.; Joty, S.; and Huang, J
work page 2025
-
[7]
A Systematic Survey and Critical Review on Evaluating Large Language Models: Challenges, Limitations, and Rec- ommendations. In Al-Onaizan, Y .; Bansal, M.; and Chen, Y ., eds.,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024, 13785–13816. As- sociation for Computation...
work page 2024
-
[8]
The Scales of Justitia: A Com- prehensive Survey on Safety Evaluation of LLMs. CoRR, abs/2506.11094. Liu, Y .; Iter, D.; Xu, Y .; Wang, S.; Xu, R.; and Zhu, C
-
[9]
G-Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. In Bouamor, H.; Pino, J.; and Bali, K., eds.,Pro- ceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2511–2522. Singapore: As- sociation for Computational Linguistics. OpenAI
work page 2023
-
[10]
Con- structing Domain-Specific Evaluation Sets for LLM-as-a- judge. arXiv:2408.08808. Xu, C.; Guan, S.; Greene, D.; and Kechadi, M.-T. 2024a. Benchmark Data Contamination of Large Language Mod- els: A Survey. arXiv:2406.04244. Xu, R.; Wang, Z.; Fan, R.-Z.; and Liu, P. 2024b. Bench- marking Benchmark Leakage in Large Language Models. arXiv:2404.18824. Zhan...
-
[11]
AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models. In Duh, K.; G ´omez-Adorno, H.; and Bethard, S., eds., Findings of the Association for Computational Linguis- tics: NAACL 2024, Mexico City, Mexico, June 16-21, 2024, 2299–2314. Association for Computational Linguistics. A Dataset This section provides supplementary information on our LL...
work page 2024
-
[12]
C LLMEval-3 Leaderboard This section presents comprehensive evaluation results from our longitudinal study tracking over 50 LLMs from late 2023 to mid-2025. We provide complete performance rank- ings and analyze the consistency of model capabilities across different prompting paradigms. We tracked over 50 LLMs from late 2023 to mid-2025. Here, we present ...
work page 2023
-
[13]
The models we selected in main paper was evaluated across three prompting paradigms: Zero-Shot (ZS), Few- Shot (FS), and Chain-of-Thought (CoT). As shown in Ta- ble 8, the performance variance across these paradigms re- mains below 1.6 points for all evaluated models, indicating that core capabilities are not significantly influenced by the prompting form...
work page 2000
-
[14]
the nature of state-owned commercial banks limits their willingness for autonomous investment. Question: Why can the results of animal experiments not be fully applied to clinical practice? Answer: Because there are differences between humans and animals not only in cellular morphology and metabolism, but also fundamentally due to the highly developed hum...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.