EDUMATH: Generating Standards-aligned Educational Math Word Problems
Pith reviewed 2026-05-18 09:33 UTC · model grok-4.3
The pith
Teacher-annotated data lets smaller open LLMs generate standards-aligned math word problems that match larger models and appeal to students.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a teacher-annotated dataset of standards-aligned math word problems, created through joint human-LLM evaluation, provides sufficient signal to train open LLMs that generate problems more similar to human-written ones, enable smaller models to match larger ones, and produce content students like as much as or more than traditional problems while preserving educational quality.
What carries the argument
The teacher-annotated dataset of evaluated math word problems, which supplies the training signal for fine-tuning LLMs and for building a quality classifier.
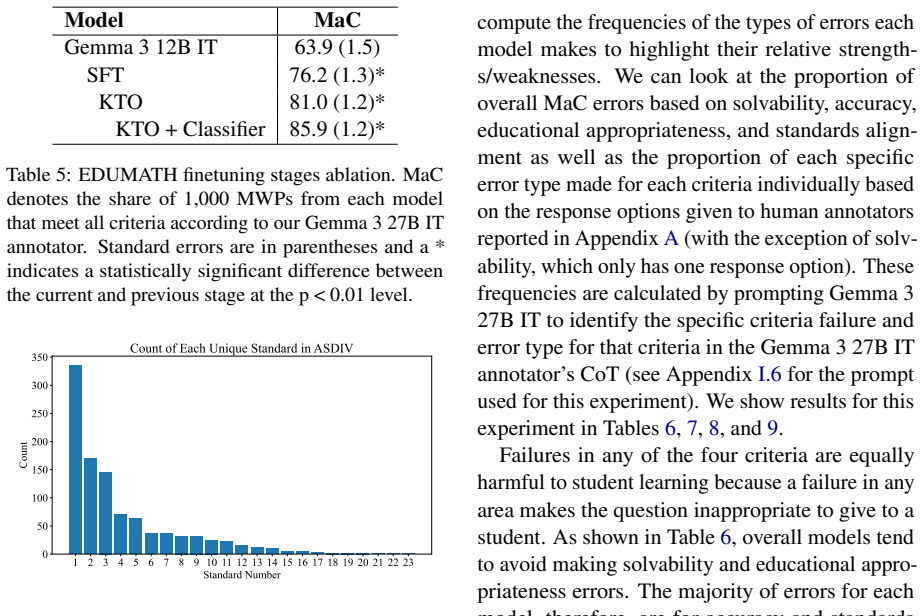
If this is right
- A 12B open model fine-tuned on the dataset matches the generation quality of larger and more capable open models.
- A text classifier trained on the teacher-annotated data lets a 30B open LLM outperform existing closed baselines without any additional training on the target task.
- The problems produced by the trained models are measurably more similar to human-written math word problems than those from prior generation methods.
- Grade-school students achieve similar accuracy on the model-generated problems as on human-written ones but report a consistent preference for the versions customized to their interests.
Where Pith is reading between the lines
- If the dataset is released, it could serve as a public resource for other groups to build educational generators without repeating the large-scale annotation effort.
- The same annotation and training pipeline might be adapted to generate customized problems in science or reading comprehension with only modest additional labeling.
- Widespread adoption could shift classroom time from problem creation toward individualized review and discussion.
- Longer-term classroom trials could test whether the observed student preference translates into measurable gains in math engagement or retention.
Load-bearing premise
The joint human expert and LLM judging process reliably identifies which generated math word problems meet standards for educational quality, alignment, and appropriateness.
What would settle it
If a larger controlled classroom study shows that students score significantly lower on the model-generated problems than on matched human-written problems, or if teachers systematically rate the generated problems as misaligned with standards, the performance claims would be undermined.
Figures














read the original abstract
Math word problems (MWPs) are critical K-12 educational tools, and customizing them to students' interests and ability levels can enhance learning. However, teachers struggle to find time to customize MWPs for students given large class sizes and increasing burnout. We propose that LLMs can support math education by generating MWPs customized to student interests and math education standards. We use a joint human expert-LLM judge approach to evaluate over 11,000 MWPs generated by open and closed LLMs and develop the first teacher-annotated dataset for standards-aligned educational MWP generation. We show the value of our data by using it to train a 12B open model that matches the performance of larger and more capable open models. We also use our teacher-annotated data to train a text classifier that enables a 30B open LLM to outperform existing closed baselines without any training. Next, we show our models' MWPs are more similar to human-written MWPs than those from existing models. We conclude by conducting the first study of customized LLM-generated MWPs with grade school students, finding they perform similarly on our models' MWPs relative to human-written MWPs but consistently prefer our customized MWPs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EDUMATH for generating standards-aligned math word problems (MWPs) customized to student interests using LLMs. It describes a joint human expert-LLM judge to evaluate over 11,000 MWPs from open and closed models, yielding the first teacher-annotated dataset for this task. The authors train a 12B open model on this data that matches larger open models, and a text classifier enabling a 30B open LLM to outperform closed baselines without further training. They also report that their models produce MWPs more similar to human-written ones and conduct a grade-school student study finding comparable performance but consistent preference for the customized MWPs.
Significance. If the evaluation methodology holds, the work provides a valuable open dataset and models for educational MWP generation, with practical demonstrations of data-driven improvements to smaller open models and initial evidence from a student preference study. The creation of teacher-annotated data and the first student study on customized LLM MWPs are notable contributions to AI-assisted education research.
major comments (2)
- [Abstract and Evaluation section] Abstract and Evaluation section: The joint human expert-LLM judge is central to all headline results (12B model matching larger models, 30B classifier outperformance, and student preference findings), yet the manuscript provides no inter-rater reliability statistics, no calibration study against pure human experts, no exact scoring rubrics, and no breakdown of disagreement cases between human and LLM judges. This undermines confidence that the filtered training data and downstream claims rest on reliable assessments of standards alignment and educational quality.
- [Student study section] Student study section: The claim of similar performance but consistent preference for customized MWPs lacks reported statistical significance tests, sample size details, or controls for order effects and prior exposure; these omissions make it difficult to assess whether the preference result is robust or generalizable.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from clearer definitions of 'standards alignment' and 'customization' early on to set expectations for the evaluation criteria.
- [Results] Figure or table presenting the 11,000+ MWP evaluation results should include per-model breakdowns of human-LLM agreement rates if available.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. We address each major point below and indicate where revisions will be made to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: The joint human expert-LLM judge is central to all headline results (12B model matching larger models, 30B classifier outperformance, and student preference findings), yet the manuscript provides no inter-rater reliability statistics, no calibration study against pure human experts, no exact scoring rubrics, and no breakdown of disagreement cases between human and LLM judges. This undermines confidence that the filtered training data and downstream claims rest on reliable assessments of standards alignment and educational quality.
Authors: We agree that additional transparency on the joint human expert-LLM judge would strengthen confidence in the results. In the revised manuscript we will add inter-rater reliability statistics (agreement rate and Cohen's kappa), the precise scoring rubrics for standards alignment and educational quality, and a summary breakdown of disagreement cases. A dedicated calibration study comparing the joint judge against multiple independent human experts was not performed owing to the substantial expert annotation cost; we will instead elaborate on the design rationale and any internal consistency checks that were conducted. revision: partial
-
Referee: [Student study section] Student study section: The claim of similar performance but consistent preference for customized MWPs lacks reported statistical significance tests, sample size details, or controls for order effects and prior exposure; these omissions make it difficult to assess whether the preference result is robust or generalizable.
Authors: We appreciate the referee's emphasis on statistical rigor. The revised manuscript will report the exact sample size (number of students and problems), include appropriate statistical significance tests for both performance and preference outcomes, and describe the experimental controls for order effects (counterbalancing) and prior exposure. These details were inadvertently omitted and will be added to allow readers to evaluate robustness and generalizability. revision: yes
Circularity Check
No significant circularity; empirical work is self-contained
full rationale
The paper is an empirical study that collects a new teacher-annotated dataset of over 11,000 MWPs via a hybrid human-LLM judge, trains models on this fresh data, compares them to external baselines, and validates via a grade-school student study. No equations, parameter fits, or derivations are presented as predictions; central claims rest on newly gathered annotations and external comparisons rather than reducing to inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the provided text. The work therefore qualifies as self-contained against external benchmarks with no circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models can produce text that is suitable for K-12 educational math word problems
- domain assumption A joint human expert and LLM judge can reliably assess standards alignment and educational quality
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use a joint human expert-LLM judge approach to evaluate over 11,000 MWPs... develop the first teacher-annotated dataset... train a 12B open model... train a text classifier that enables a 30B open LLM...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We evaluate MWPs on four criteria: Solvability, Accuracy, Educational Appropriateness, and Standards Alignment.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
A Multi-Agent Approach to Validate and Refine LLM-Generated Personalized Math Problems
A multi-agent generate-validate-revise framework reduces failures in realism and authenticity for LLM-personalized math problems, with one iteration helping and different strategies varying by criterion.
-
Mathematics Teachers Interactions with a Multi-Agent System for Personalized Problem Generation
Eight teachers used a four-agent LLM system to create 212 personalized middle-school math problems; final versions had few realism or hallucination problems noted by users even though agents flagged realism issues dur...
Reference graph
Works this paper leans on
-
[1]
Jeanne Sternlicht Chall and Edgar Dale
Place: US Publisher: American Psychological Association. Jeanne Sternlicht Chall and Edgar Dale. 1995.Read- ability Revisited: The New Dale-Chall Readabil- ity Formula. Brookline Books. Google-Books-ID: 2nbuAAAAMAAJ. Bryan R Christ, Jonathan Kropko, and Thomas Hartvigsen. 2024. MATHWELL: Generating Ed- ucational Math Word Problems Using Teacher An- notati...
work page 1995
-
[2]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Prob- lems.arXiv preprint. ArXiv:2110.14168 [cs]. Scott A. Crossley, Jerry Greenfield, and Danielle S. McNAMARA. 2008. Assessing Text Read- ability Using Cognitively Based Indices. TESOL Quarterly, 42(3):475–493. _eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1002/j.1545- 7249.2008.tb00142.x. Scott A. Crossley, S...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1002/j.1545- 2008
-
[3]
Publisher: [Wiley, International Reading Asso- ciation]. Meta. Llama 3.3 Model Cards and Prompt formats. Shen-yun Miao, Chao-Chun Liang, and Keh-Yih Su
-
[4]
A Diverse Corpus for Evaluating and Develop- ing English Math Word Problem Solvers. InProceed- ings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 975–984, Online. Association for Computational Linguistics. Swaroop Mishra, Matthew Finlayson, Pan Lu, Leonard Tang, Sean Welleck, Chitta Baral, Tanmay Rajpuro- hit, Oyvind T...
-
[5]
Are NLP Models really able to Solve Simple Math Word Problems?
Are NLP Models really able to Solve Simple Math Word Problems?arXiv preprint. ArXiv:2103.07191 [cs]. Daniel Pearce, Faye Bruun, Kim Skinner, and Claricia Lopez-Mohler. 2013. What teachers say about stu- dent difficulties solving mathematical word problems in grades 2-5.International Electronic Journal of Mathematics Education, 8:3–19. Nichole Pinkard, C. ...
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[6]
Interactive Learning Environments 29, 618–633
Equitable approaches: opportunities for computational thinking with emphasis on creative production and connections to com- munity.Interactive Learning Environments, 28(3):347–361. Publisher: Routledge _eprint: https://doi.org/10.1080/10494820.2019.1636070. 10 Longhu Qin, Jiayu Liu, Zhenya Huang, Kai Zhang, Qi Liu, Binbin Jin, and Enhong Chen. 2023. A Mat...
-
[7]
Virginia Department of Education
Publisher: Springer ERIC Number: EJ1243930. Virginia Department of Education. K-12 standards & instruction. https://www.doe.virginia.gov/ teaching-learning-assessment/instruction. Accessed: 2025-04-07. Candace Walkington, Virginia Clinton, and Pooja Shiv- raj. 2018. How readability factors are differentially associated with performance for students of dif...
-
[8]
MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning
MAmmoTH: Building Math Generalist Mod- els through Hybrid Instruction Tuning.arXiv preprint. ArXiv:2309.05653 [cs]. Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. Bertscore: Evaluating text generation with bert.Preprint, arXiv:1904.09675. Qingyu Zhou and Danqing Huang. 2019. Towards Gen- erating Math Word Problems from...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[9]
It does not address important parts of the stan- dard(s), 3) It does not address the standard(s) at all, or 4) It requires the use of additional math top- ics beyond those listed in the standard(s), each of which would be equally harmful to student learning. Table 9 shows the majority of standards alignment errors for each model are for MWPs that are miss...
work page 2024
-
[10]
They were tasked to collect different materials and create useful things from those
Marcus and his friends are starting a recycling project to help the school raise some money for charity. They were tasked to collect different materials and create useful things from those. If Marcus was able to gather 25 milk bottles, and John was able to gather 20 milk bottles, how many milk bottles do they have available for recycling?
-
[11]
Superman needs to collect some dog bones for his best friend Krypto. If he found 15 dog bones in the Fortress of Solitude and 25 dog bones at the Daily Planet, how many dog bones does he have for Krypto? Which word problem did you like best? Why did you like that word problem the best? Figure 7: Sample student worksheet for first experimental condition in...
-
[15]
the question may include OTHER TOPIC,
It is inappropriate for a different reason Standards alignment: A standards aligned question is one that adequately addresses important elements from EACH pre-specified numbered math topic. If more than one math topic is listed, then the question should incorporate important elements of EACH numbered math topic. If only one math topic is included, then it...
-
[17]
It does not address some important parts of the numbered topic(s) or one or more of the numbered topic(s)
-
[19]
It requires additional math topics or operations that are not listed in the specified math topic(s) Here are some examples of successful evaluations: {25-shot examples} Now evaluate this word problem and remember to answer "Yes." or "No." followed by your reasoning. Grade Level: {insert grade level} Math Topics: {insert math topics} Question: {insert ques...
-
[20]
It cannot be solved with the information present
-
[21]
It contains a mathematical scenario that is impossible Accuracy: An accurate solution is one where the final answer and intermediate reasoning are both correct. A solution is inaccurate if:
-
[22]
The final answer is wrong
-
[23]
The final answer is correct but the intermediate reasoning is wrong, does not make sense, is unnecessarily repetitive, and/or is too complicated for a student/teacher to read Educational Appropriateness: An educationally appropriate question is one you would feel comfortable giving to a student in a 3rd-5th grade school setting. Educationally appropriate ...
-
[24]
It contains material inappropriate for a school setting (e.g., language about harming someone)
-
[25]
It is strange, confusing, contains conflicting information, and/or is not based in reality (e.g., contains misinformation)
-
[26]
It requires no mathematical operations to solve because it gives the answer away
-
[27]
There are four main reasons why a question would not be standards aligned:
It is inappropriate for a different reason Standards alignment: A standards aligned question is one that adequately addresses important elements from EACH pre-specified numbered math topic. There are four main reasons why a question would not be standards aligned:
-
[28]
It is too hard for the given topic(s)
-
[29]
It does not address some important parts of the numbered topic(s) or one or more of the 29 numbered topic(s)
-
[30]
It does not address the numbered topic(s) at all
-
[31]
It requires additional math topics or operations that are not listed in the specified math topic(s) Here are some examples of successful evaluations: {8-shot examples} Now evaluate this word problem and remember to both identify which criteria the problem failed to incorporate using the "Error Type:" heading and the specific error it made for that criteri...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.