When Identity Skews Debate: Anonymization for Bias-Reduced Multi-Agent Reasoning
Pith reviewed 2026-05-18 08:47 UTC · model grok-4.3
The pith
Removing identity markers from prompts equalizes weights in multi-agent LLM debates and cuts identity-driven bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
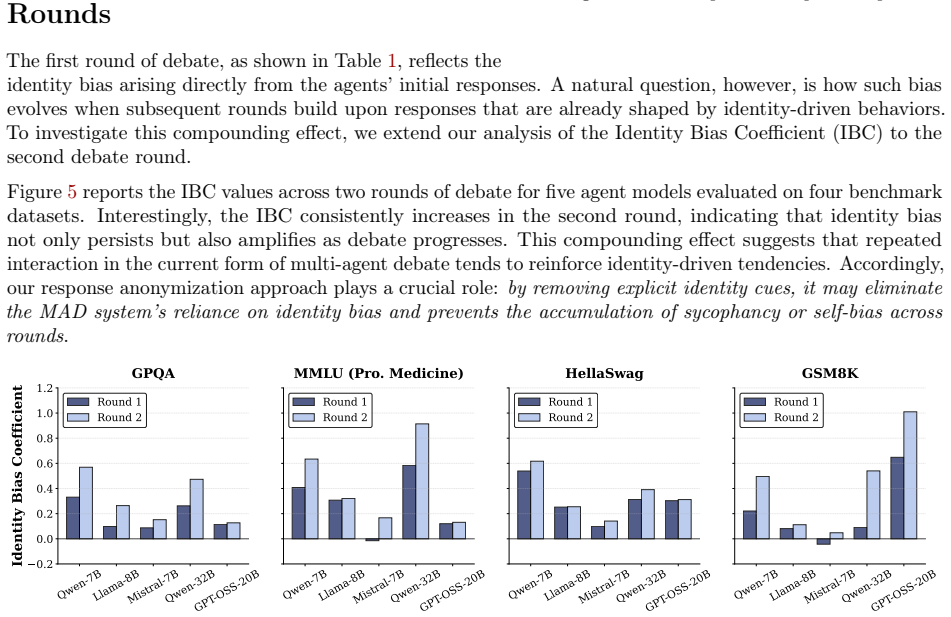
Multi-agent debate improves LLM reasoning by letting agents exchange and aggregate opinions, yet agents exhibit identity-driven sycophancy and self-bias that skew outcomes. The authors formalize debate dynamics as an identity-weighted Bayesian update process. They introduce response anonymization, in which identity markers are removed from prompts so that agents cannot tell which output is their own versus a peer's; this enforces equal weights on agent identity and thereby reduces bias. They also define the Identity Bias Coefficient to measure an agent's tendency to follow its peer versus itself. Empirical results confirm that identity bias is widespread, with sycophancy occurring more often
What carries the argument
Response anonymization: removing identity markers from prompts so agents cannot distinguish self from peer and must assign equal weights to all contributions.
If this is right
- Anonymization reduces both sycophancy and self-bias in multi-agent debate settings.
- The Identity Bias Coefficient provides a quantitative way to track and compare bias levels across models and prompts.
- Multi-agent systems become more trustworthy when reasoning rests on content rather than agent identity.
- Sycophancy appears as the dominant form of identity bias, suggesting targeted mitigation may be needed beyond simple anonymization.
Where Pith is reading between the lines
- The same anonymization step could be tested in other multi-agent workflows such as collaborative planning or tool-use chains.
- If identity cues drive bias here, similar hidden-identity techniques might improve fairness in single-model self-critique loops.
- Combining anonymization with content-only aggregation rules might produce additive gains that the current experiments do not yet measure.
Load-bearing premise
Debate dynamics can be accurately modeled as an identity-weighted Bayesian update, and stripping identity markers will stop agents from using any identity information at all.
What would settle it
An experiment in which agents still display measurable preference for certain responses after all explicit identity markers are removed, or in which the observed bias pattern deviates sharply from the predictions of the identity-weighted update model.
Figures





read the original abstract
Multi-agent debate (MAD) aims to improve large language model (LLM) reasoning by letting multiple agents exchange answers and then aggregate their opinions. Yet recent studies reveal that agents are not neutral: they are prone to identity-driven sycophancy and self-bias, uncritically adopting a peer's view or stubbornly adhering to their own prior output, undermining the reliability of debate. In this work, we present the first principled framework that joins sycophancy and self-bias to mitigate and quantify identity bias in MAD. First, we formalize the debate dynamics as an identity-weighted Bayesian update process. Second, we propose response anonymization: by removing identity markers from prompts, agents cannot distinguish "self" from "peer", which forces equal weights on agent identity, thereby reducing bias and improving trustworthiness. Third, we define the Identity Bias Coefficient (IBC), a principled bias metric that measures an agent's tendency to follow its peer versus itself. Empirical studies across multiple models and benchmarks confirm that identity bias is widespread, with sycophancy far more common than self-bias. Our findings highlight the need to ensure that MAD systems reason based on content rather than identity. Code is released in https://github.com/deeplearning-wisc/MAD-identity-bias.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to provide the first principled framework for mitigating and quantifying identity bias in multi-agent debate (MAD) for LLMs. It formalizes debate dynamics as an identity-weighted Bayesian update process, proposes response anonymization by removing identity markers from prompts to prevent agents from distinguishing self from peer and thereby force equal weights, defines the Identity Bias Coefficient (IBC) as a metric for an agent's tendency to follow its peer versus itself, and reports empirical studies across models and benchmarks showing that identity bias is widespread (with sycophancy more common than self-bias) and that anonymization reduces bias and improves trustworthiness. Code is released publicly.
Significance. If the results hold, this work contributes a mechanistic approach to reducing identity-driven sycophancy and self-bias in MAD systems, which could enhance the reliability of LLM-based reasoning. The public code release supports reproducibility and allows independent verification. The emphasis on content-based rather than identity-based reasoning addresses a practical limitation in current multi-agent setups.
major comments (3)
- [Formalization section] The formalization of debate as an identity-weighted Bayesian update process introduces free parameters ('identity weights'); it is unclear from the description whether these are set independently or fitted within the same framework that later defines the IBC, which could make the model assumptions load-bearing for the bias-reduction claim.
- [Response anonymization proposal] The central claim for response anonymization—that removing explicit identity markers forces equal weights because agents cannot distinguish self from peer—does not address implicit channels such as stylistic fingerprints, semantic content consistency, or retained generation history within the context window. If these remain active, anonymization may not actually equalize the weights as assumed.
- [IBC definition] The Identity Bias Coefficient (IBC) is defined directly from the identity-weighted Bayesian update process introduced in the paper; this risks circularity, as the metric may reduce to parameters or weights assumed within the same model rather than providing an independent, externally validated measure of bias.
minor comments (2)
- [Abstract] The abstract states that empirical studies confirm the findings but provides no quantitative details on effect sizes, specific benchmarks, or controls; adding these would strengthen the presentation.
- [Empirical studies] It would improve clarity to include a table or figure summarizing IBC values before and after anonymization across models.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our paper. We address each of the major comments point by point below, providing clarifications and indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Formalization section] The formalization of debate as an identity-weighted Bayesian update process introduces free parameters ('identity weights'); it is unclear from the description whether these are set independently or fitted within the same framework that later defines the IBC, which could make the model assumptions load-bearing for the bias-reduction claim.
Authors: The identity weights in our formalization are conceptual parameters representing the relative influence of self versus peer identity in the Bayesian update. They are not fitted or estimated from data in conjunction with the IBC; instead, the IBC is an empirical metric calculated from observed agent behaviors in experiments where we compare responses with and without identity information. The model is used to motivate the anonymization approach by showing how equalizing weights reduces bias. We will revise the formalization section to explicitly clarify that these weights are not data-fitted parameters but serve as a theoretical lens, and that IBC is independently measured. revision: partial
-
Referee: [Response anonymization proposal] The central claim for response anonymization—that removing explicit identity markers forces equal weights because agents cannot distinguish self from peer—does not address implicit channels such as stylistic fingerprints, semantic content consistency, or retained generation history within the context window. If these remain active, anonymization may not actually equalize the weights as assumed.
Authors: We agree that implicit cues could potentially allow agents to infer identity even after removing explicit markers. Our current approach focuses on explicit identity markers as the primary channel, and our experiments across multiple models show consistent bias reduction with anonymization. To address this concern, we will add a new subsection in the discussion to acknowledge the limitations of explicit anonymization and discuss potential implicit biases, along with suggestions for future enhancements like content normalization. revision: yes
-
Referee: [IBC definition] The Identity Bias Coefficient (IBC) is defined directly from the identity-weighted Bayesian update process introduced in the paper; this risks circularity, as the metric may reduce to parameters or weights assumed within the same model rather than providing an independent, externally validated measure of bias.
Authors: While the IBC is motivated by the formal model, its computation is based on empirical observations of how much an agent's final answer deviates from its initial response when presented with peer input, with and without identity cues. This behavioral measurement provides an external validation independent of the assumed weights. The reduction in IBC under anonymization is directly observed in the data, supporting the claim without circularity. We do not believe a revision is necessary here, but we can add a sentence emphasizing the empirical nature of the IBC calculation. revision: partial
Circularity Check
Anonymization effect follows directly from identity-weighted formalization by construction
specific steps
-
self definitional
[Abstract, second step]
"Second, we propose response anonymization: by removing identity markers from prompts, agents cannot distinguish 'self' from 'peer', which forces equal weights on agent identity, thereby reducing bias and improving trustworthiness."
The identity-weighted Bayesian update process is defined by the authors to assign weights according to whether agents can distinguish self from peer via markers. Removing markers therefore equalizes weights by the definition of the formalization itself; the claimed bias reduction is a direct modeling consequence rather than a separate prediction or first-principles result.
full rationale
The paper introduces its own identity-weighted Bayesian update model, then states that removing markers forces equal weights within that model. This step is load-bearing for the central claim but reduces to the modeling assumption rather than an independent derivation. No other steps exhibit circularity; the empirical validation on benchmarks provides external content, and IBC appears as a derived metric rather than a fitted prediction renamed as result. Self-citation is absent from the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- identity weights
axioms (1)
- domain assumption Multi-agent debate dynamics can be modeled as an identity-weighted Bayesian update process.
invented entities (1)
-
Identity Bias Coefficient (IBC)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formalize the debate dynamics as an identity-weighted Bayesian update process... Definition 2. (Identity-driven Bayesian Belief Update... αi,t = αi,t−1 + ci,t
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1... Δi := Conformityi − Obstinacyi = ... (belief difference) + (wj − wi) (identity bias)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
Peer Identity Bias in Multi-Agent LLM Evaluation: An Empirical Study Using the TRUST Democratic Discourse Analysis Pipeline
Single-channel anonymization hides identity bias via cancellation effects, but full-pipeline anonymization reveals that homogeneous ensembles amplify sycophancy while heterogeneous ones reduce it, with one model showi...
-
Epistemic Blinding: An Inference-Time Protocol for Auditing Prior Contamination in LLM-Assisted Analysis
Epistemic blinding is an inference-time protocol that anonymizes entity identifiers to measure and audit how much LLM outputs in agentic systems draw from parametric knowledge versus provided data.
-
The Reasoning Trap: An Information-Theoretic Bound on Closed-System Multi-Step LLM Reasoning
Closed-system multi-step LLM reasoning is subject to an information-theoretic bound where mutual information with evidence decreases, preserving accuracy while eroding faithfulness, with EGSR recovering it on SciFact ...
-
Fairness in Multi-Agent Systems for Software Engineering: An SDLC-Oriented Rapid Review
A rapid review of fairness in LLM-enabled multi-agent systems for the software development lifecycle concludes that the field lacks standardized evaluations, broad coverage, and effective governance, leaving it unprep...
Reference graph
Works this paper leans on
-
[1]
Chateval: Towards better llm-based evaluators through multi-agent debate
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[2]
Improving factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. InInternational Conference on Machine Learning, pages 11733–11763. PMLR, 2024
work page 2024
-
[3]
Xiaohe Bo, Zeyu Zhang, Quanyu Dai, Xueyang Feng, Lei Wang, Rui Li, Xu Chen, and Ji-Rong Wen. Reflective multi-agent collaboration based on large language models.Advances in Neural Information Processing Systems, 37:138595–138631, 2024
work page 2024
-
[4]
Improving multi-agent debate with sparse communication topology
Yunxuan Li, Yibing Du, Jiageng Zhang, Le Hou, Peter Grabowski, Yeqing Li, and Eugene Ie. Improving multi-agent debate with sparse communication topology. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 7281–7294, 2024
work page 2024
-
[5]
Jin Li, Keyu Wang, Shu Yang, Zhuoran Zhang, and Di Wang. When truth is overridden: Uncovering the internal origins of sycophancy in large language models.arXiv preprint arXiv:2508.02087, 2025
-
[6]
Syceval: Evaluating llm sycophancy.arXiv preprint arXiv:2502.08177, 2025
Aaron Fanous, Jacob Goldberg, Ank A Agarwal, Joanna Lin, Anson Zhou, Roxana Daneshjou, and Sanmi Koyejo. Syceval: Evaluating llm sycophancy.arXiv preprint arXiv:2502.08177, 2025
-
[7]
Joshua Liu, Aarav Jain, Soham Takuri, Srihan Vege, Aslihan Akalin, Kevin Zhu, Sean O’Brien, and Vasu Sharma. Truth decay: Quantifying multi-turn sycophancy in language models.arXiv preprint arXiv:2503.11656, 2025
-
[8]
Reasoning isn’t enough: Examining truth- bias and sycophancy in llms
Emilio Barkett, Olivia Long, and Madhavendra Thakur. Reasoning isn’t enough: Examining truth-bias and sycophancy in llms.arXiv preprint arXiv:2506.21561, 2025
-
[9]
Sycophancy in large language models: Causes and mitigations
Lars Malmqvist. Sycophancy in large language models: Causes and mitigations. InIntelligent Computing- Proceedings of the Computing Conference, pages 61–74. Springer, 2025
work page 2025
-
[10]
Jiseung Hong, Grace Byun, Seungone Kim, and Kai Shu. Measuring sycophancy of language models in multi-turn dialogues.arXiv preprint arXiv:2505.23840, 2025
-
[11]
URLhttps://arxiv.org/abs/2508.06709.2508.06709
Evangelia Spiliopoulou, Riccardo Fogliato, Hanna Burnsky, Tamer Soliman, Jie Ma, Graham Horwood, and Miguel Ballesteros. Play favorites: A statistical method to measure self-bias in llm-as-a-judge.arXiv preprint arXiv:2508.06709, 2025
- [12]
-
[13]
Walter Laurito, Benjamin Davis, Peli Grietzer, Tomáš Gavenčiak, Ada Böhm, and Jan Kulveit. Ai–ai bias: Large language models favor communications generated by large language models.Proceedings of the National Academy of Sciences, 122(31):e2415697122, 2025
work page 2025
- [14]
-
[15]
Silencer: From discovery to mitigation of self-bias in llm-as-benchmark-generator
Peiwen Yuan, Yiwei Li, Shaoxiong Feng, Xinglin Wang, Yueqi Zhang, Jiayi Shi, Chuyi Tan, Boyuan Pan, Yao Hu, and Kan Li. Silencer: From discovery to mitigation of self-bias in llm-as-benchmark-generator. arXiv preprint arXiv:2505.20738, 2025
-
[16]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Medagents: Large language models as collaborators for zero-shot medical reasoning
Xiangru Tang, Anni Zou, Zhuosheng Zhang, Ziming Li, Yilun Zhao, Xingyao Zhang, Arman Cohan, and Mark Gerstein. Medagents: Large language models as collaborators for zero-shot medical reasoning. In Findings of the Association for Computational Linguistics ACL 2024, pages 599–621, 2024. 11
work page 2024
-
[18]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst Conference on Language Modeling, 2024
work page 2024
-
[19]
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, et al. Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[20]
Qineng Wang, Zihao Wang, Ying Su, Hanghang Tong, and Yangqiu Song. Rethinking the bounds of llm reasoning: Are multi-agent discussions the key? In62nd Annual Meeting of the Association for Computational Linguistics, ACL 2024, pages 6106–6131. Association for Computational Linguistics (ACL), 2024
work page 2024
-
[21]
Guibin Zhang, Yanwei Yue, Zhixun Li, Sukwon Yun, Guancheng Wan, Kun Wang, Dawei Cheng, Jeffrey Xu Yu, and Tianlong Chen. Cut the crap: An economical communication pipeline for llm-based multi-agent systems.arXiv preprint arXiv:2410.02506, 2024
-
[22]
Andrew Estornell and Yang Liu. Multi-llm debate: Framework, principals, and interventions.Advances in Neural Information Processing Systems, 37:28938–28964, 2024
work page 2024
-
[23]
Hyeong Kyu Choi, Xiaojin Zhu, and Sharon Li. Debate or vote: Which yields better decisions in multi-agent large language models? InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[24]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024
work page 2024
-
[28]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[29]
Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. Aligning ai with shared human values.Proceedings of the International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[30]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
work page 2019
-
[31]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
Tongxuan Liu, Xingyu Wang, Weizhe Huang, Wenjiang Xu, Yuting Zeng, Lei Jiang, Hailong Yang, and Jing Li. Groupdebate: Enhancing the efficiency of multi-agent debate using group discussion.arXiv preprint arXiv:2409.14051, 2024. 12
-
[33]
Dynamic llm-agent network: An llm-agent collaboration framework with agent team optimization
Zijun Liu, Yanzhe Zhang, Peng Li, Yang Liu, and Diyi Yang. Dynamic llm-agent network: An llm-agent collaboration framework with agent team optimization. InCOLM, 2024
work page 2024
-
[34]
Let models speak ciphers: Multiagent debate through embeddings
Chau Pham, Boyi Liu, Yingxiang Yang, Zhengyu Chen, Tianyi Liu, Jianbo Yuan, Bryan A Plummer, Zhaoran Wang, and Hongxia Yang. Let models speak ciphers: Multiagent debate through embeddings. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[35]
Reconcile: Round-table conference improves reasoning via consensus among diverse llms
Justin Chen, Swarnadeep Saha, and Mohit Bansal. Reconcile: Round-table conference improves reasoning via consensus among diverse llms. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7066–7085, 2024
work page 2024
-
[36]
Encouraging divergent thinking in large language models through multi-agent debate
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. Encouraging divergent thinking in large language models through multi-agent debate. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17889–17904, 2024
work page 2024
-
[37]
Zhenhailong Wang, Shaoguang Mao, Wenshan Wu, Tao Ge, Furu Wei, and Heng Ji. Unleashing the emergent cognitive synergy in large language models: A task-solving agent through multi-persona self- collaboration. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Vol...
work page 2024
-
[38]
Breaking mental set to improve reasoning through diverse multi-agent debate
Yexiang Liu, Jie Cao, Zekun Li, Ran He, and Tieniu Tan. Breaking mental set to improve reasoning through diverse multi-agent debate. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[39]
Optima: Optimizing effectiveness and efficiency for llm-based multi-agent system
Weize Chen, Jiarui Yuan, Chen Qian, Cheng Yang, Zhiyuan Liu, and Maosong Sun. Optima: Optimizing effectiveness and efficiency for llm-based multi-agent system.arXiv preprint arXiv:2410.08115, 2024
-
[40]
Why Do Multi-Agent LLM Systems Fail?
Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, et al. Why do multi-agent llm systems fail?arXiv preprint arXiv:2503.13657, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
If multi-agent debate is the answer, what is the question.arXiv preprint arXiv:2502.08788,
Hangfan Zhang, Zhiyao Cui, Xinrun Wang, Qiaosheng Zhang, Zhen Wang, Dinghao Wu, and Shuyue Hu. If multi-agent debate is the answer, what is the question?arXiv preprint arXiv:2502.08788, 2025
-
[42]
Large language models cannot self-correct reasoning yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[43]
Should we be going mad? a look at multi-agent debate strategies for llms
Andries Petrus Smit, Nathan Grinsztajn, Paul Duckworth, Thomas D Barrett, and Arnu Pretorius. Should we be going mad? a look at multi-agent debate strategies for llms. InInternational Conference on Machine Learning, pages 45883–45905. PMLR, 2024
work page 2024
-
[44]
Examining inter-consistency of large language models collaboration: An in-depth analysis via debate
Kai Xiong, Xiao Ding, Yixin Cao, Ting Liu, and Bing Qin. Examining inter-consistency of large language models collaboration: An in-depth analysis via debate. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 7572–7590, 2023
work page 2023
-
[45]
Voting or consensus? decision-making in multi-agent debate.arXiv e-prints, pages arXiv–2502, 2025
Lars Benedikt Kaesberg, Jonas Becker, Jan Philip Wahle, Terry Ruas, and Bela Gipp. Voting or consensus? decision-making in multi-agent debate.arXiv e-prints, pages arXiv–2502, 2025
work page 2025
-
[46]
Towards understanding sycophancy in language models
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R Johnston, et al. Towards understanding sycophancy in language models. In12th International Conference on Learning Representations, ICLR 2024, 2024
work page 2024
-
[47]
Simple synthetic data reduces sycophancy in large language models
Jerry Wei, Da Huang, Yifeng Lu, Denny Zhou, and Quoc V Le. Simple synthetic data reduces sycophancy in large language models.arXiv preprint arXiv:2308.03958, 2023. 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Aswin Rrv, Nemika Tyagi, Md Nayem Uddin, Neeraj Varshney, and Chitta Baral. Chaos with keywords: Exposing large language models sycophancy to misleading keywords and evaluating defense strategies. InFindings of the Association for Computational Linguistics ACL 2024, pages 12717–12733, 2024
work page 2024
-
[49]
Mitigating sycophancy in large language models via direct preference optimization
Azal Ahmad Khan, Sayan Alam, Xinran Wang, Ahmad Faraz Khan, Debanga Raj Neog, and Ali Anwar. Mitigating sycophancy in large language models via direct preference optimization. In2024 IEEE International Conference on Big Data (BigData), pages 1664–1671. IEEE, 2024
work page 2024
-
[50]
From yes-men to truth-tellers: Addressing sycophancy in large language models with pinpoint tuning
Wei Chen, Zhen Huang, Liang Xie, Binbin Lin, Houqiang Li, Le Lu, Xinmei Tian, Deng Cai, Yonggang Zhang, Wenxiao Wang, et al. From yes-men to truth-tellers: Addressing sycophancy in large language models with pinpoint tuning. InInternational Conference on Machine Learning, pages 6950–6972. PMLR, 2024
work page 2024
-
[51]
Kaiwei Zhang, Qi Jia, Zijian Chen, Wei Sun, Xiangyang Zhu, Chunyi Li, Dandan Zhu, and Guangtao Zhai. Sycophancy under pressure: Evaluating and mitigating sycophantic bias via adversarial dialogues in scientific qa.arXiv preprint arXiv:2508.13743, 2025
-
[52]
Self-Preference Bias in LLM-as-a-Judge
Koki Wataoka, Tsubasa Takahashi, and Ryokan Ri. Self-preference bias in llm-as-a-judge.arXiv preprint arXiv:2410.21819, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Arjun Panickssery, Samuel Bowman, and Shi Feng. Llm evaluators recognize and favor their own generations.Advances in Neural Information Processing Systems, 37:68772–68802, 2024
work page 2024
-
[54]
Self-recognition in language models
Tim Davidson, Viacheslav Surkov, Veniamin Veselovsky, Giuseppe Russo, Robert West, and Çağlar G"ulçehre. Self-recognition in language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 12032–12059, 2024
work page 2024
-
[55]
Pride and prejudice: Llm amplifies self-bias in self-refinement
Wenda Xu, Guanglei Zhu, Xuandong Zhao, Liangming Pan, Lei Li, and William Wang. Pride and prejudice: Llm amplifies self-bias in self-refinement. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15474–15492, 2024
work page 2024
-
[56]
Mahak Agarwal and Divyam Khanna. When persuasion overrides truth in multi-agent llm debates: Introducing a confidence-weighted persuasion override rate (cw-por).arXiv preprint arXiv:2504.00374, 2025
-
[57]
Priya Pitre, Naren Ramakrishnan, and Xuan Wang. Consensagent: Towards efficient and effective consensus in multi-agent llm interactions through sycophancy mitigation. InFindings of the Association for Computational Linguistics: ACL 2025, pages 22112–22133, 2025
work page 2025
-
[58]
Large language model based multi-agents: a survey of progress and challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi-agents: a survey of progress and challenges. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pages 8048–8057, 2024
work page 2024
-
[59]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D Nguyen. Multi-agent collaboration mechanisms: A survey of llms.arXiv preprint arXiv:2501.06322, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Beyond Self-Talk: A Communication-Centric Survey of LLM-Based Multi-Agent S ystems
Bingyu Yan, Xiaoming Zhang, Litian Zhang, Lian Zhang, Ziyi Zhou, Dezhuang Miao, and Chaozhuo Li. Beyond self-talk: A communication-centric survey of llm-based multi-agent systems.arXiv preprint arXiv:2502.14321, 2025
work page internal anchor Pith review arXiv 2025
-
[61]
Xinyi Li, Sai Wang, Siqi Zeng, Yu Wu, and Yi Yang. A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges.Vicinagearth, 1(1):9, 2024
work page 2024
-
[62]
Ruosen Li, Teerth Patel, and Xinya Du. Prd: Peer rank and discussion improve large language model based evaluations.Transactions on Machine Learning Research, 2024
work page 2024
-
[63]
Exploring and controlling diversity in llm-agent conversation, 2025
KuanChao Chu, Yi-Pei Chen, and Hideki Nakayama. Exploring and controlling diversity in llm-agent conversation.arXiv preprint arXiv:2412.21102, 2024. 14
-
[64]
Acc-debate: An actor-critic approach to multi-agent debate
Andrew Estornell, Jean-Francois Ton, Yuanshun Yao, and Yang Liu. Acc-debate: An actor-critic approach to multi-agent debate. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[65]
Yunpu Zhao, Rui Zhang, Junbin Xiao, Changxin Ke, Ruibo Hou, Yifan Hao, Qi Guo, and Yunji Chen. Towards analyzing and mitigating sycophancy in large vision-language models.arXiv preprint arXiv:2408.11261, 2024
-
[66]
Causally motivated sycophancy mitigation for large language models
Haoxi Li, Xueyang Tang, Jie Zhang, Song Guo, Sikai Bai, Peiran Dong, and Yue Yu. Causally motivated sycophancy mitigation for large language models. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[67]
Accounting for sycophancy in language model uncertainty estimation
Anthony Sicilia, Mert Inan, and Malihe Alikhani. Accounting for sycophancy in language model uncertainty estimation. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 7851–7866, 2025
work page 2025
-
[68]
Jiarui Liu, Yueqi Song, Yunze Xiao, Mingqian Zheng, Lindia Tjuatja, Jana Schaich Borg, Mona Diab, and Maarten Sap. Synthetic socratic debates: Examining persona effects on moral decision and persuasion dynamics.arXiv preprint arXiv:2506.12657, 2025
-
[69]
Nimet Beyza Bozdag, Shuhaib Mehri, Gokhan Tur, and Dilek Hakkani-Tür. Persuade me if you can: A framework for evaluating persuasion effectiveness and susceptibility among large language models.arXiv preprint arXiv:2503.01829, 2025
work page internal anchor Pith review arXiv 2025
-
[70]
The future of cognitive strategy-enhanced persuasive dialogue agents: new perspectives and trends
Mengqi Chen, Bin Guo, Hao Wang, Haoyu Li, Qian Zhao, Jingqi Liu, Yasan Ding, Yan Pan, and Zhiwen Yu. The future of cognitive strategy-enhanced persuasive dialogue agents: new perspectives and trends. Frontiers of Computer Science, 19(5):195315, 2025
work page 2025
-
[71]
Vivaan Sandwar, Bhav Jain, Rishan Thangaraj, Ishaan Garg, Michael Lam, and Kevin Zhu. Town hall debate prompting: Enhancing logical reasoning in llms through multi-persona interaction.arXiv preprint arXiv:2502.15725, 2025
-
[72]
Debate-to-write: A persona-driven multi-agent framework for diverse argument generation
Zhe Hu, Hou Pong Chan, Jing Li, and Yu Yin. Debate-to-write: A persona-driven multi-agent framework for diverse argument generation. InProceedings of the 31st International Conference on Computational Linguistics, pages 4689–4703, 2025
work page 2025
-
[73]
Justice or prejudice? quantifying biases in llm-as-a-judge
Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, et al. Justice or prejudice? quantifying biases in llm-as-a-judge. In International Conference on Learning Representations, 2025. 15 Appendix Table of Contents A Qualitative Examples 16 B Experimental Details 23 B.1 Dataset Details . ....
work page 2025
-
[76]
The physical examination reveals dry mucous membranes and a slightly distended abdomen. Considering the symptoms and the diet of the infant, we can start eliminating options: - (C) Magnesium deficiency is unlikely to be the cause of persistent watery diarrhea in this infant, ... - (D) Regional enteritis (also known as Crohn’s disease) is a chronic inflamm...
-
[79]
**Developmental stage **: At 7 months, infants often start to be introduced to a wide variety of solid foods, which can ... Given this information, we can rule out the options: - **(D) Regional enteritis **: Also known as Crohn’s disease, this is a chronic inflammatory bowel disease ... - **(C) Magnesium deficiency **: While magnesium is essential for the...
-
[82]
The physical examination reveals dry mucous membranes and a slightly distended abdomen. Considering the symptoms and the diet of the infant, we can start eliminating options: - (C) Magnesium deficiency is unlikely to be the cause of persistent watery diarrhea in this infant, as magnesium deficiency typically presents with different symptoms such as muscle...
-
[83]
The patient is a 7-month-old infant who has been experiencing persistent watery diarrhea after a recent episode of enteritis and dehydration
-
[84]
The infant is being fed cow-milk formula and strained fruits and vegetables
-
[85]
The physical examination reveals dry mucous membranes and a slightly distended abdomen. Considering the symptoms and the diet of the infant, we can start eliminating options: - (C) Magnesium deficiency is unlikely to be the cause of persistent watery diarrhea in this infant, ... - (D) Regional enteritis (also known as Crohn’s disease) is a chronic inflamm...
-
[86]
**Clinical presentation **: The infant has persistent watery diarrhea, dehydration, dry mucous membranes, and a slightly distended abdomen
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.