EvoTest: Evolutionary Test-Time Learning for Self-Improving Agentic Systems
Pith reviewed 2026-05-18 07:43 UTC · model grok-4.3
The pith
EvoTest improves agent performance across repeated game episodes by evolving the full system configuration from each transcript without fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
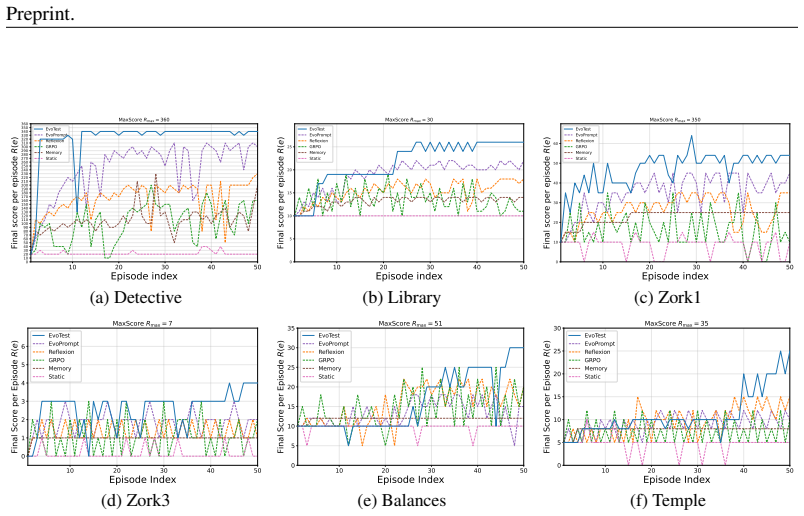
EvoTest is a test-time evolutionary framework in which an Evolver Agent analyzes raw episode transcripts to generate revised configurations that rewrite prompts, update memory with effective state-action pairs, tune hyperparameters, and learn tool-use routines; these changes are applied to the Actor Agent for the subsequent episode, producing consistent performance gains on the J-TTL benchmark and enabling wins in two games where reflection, memory, and online fine-tuning baselines achieve none.
What carries the argument
The Evolver Agent that extracts patterns from episode transcripts to propose configuration revisions rewriting prompts, logging effective actions, tuning hyperparameters, and learning tool routines.
If this is right
- Agents achieve consistent performance increases across episodes without any gradient-based fine-tuning.
- EvoTest is the only method that wins the Detective and Library games while all baselines fail to win any.
- The approach outperforms reflection-based methods, memory-only systems, and more complex online fine-tuning techniques on the benchmark.
- The entire agentic system, including prompts, memory content, hyperparameters, and tool-use routines, can be revised after every episode based on observed outcomes.
Where Pith is reading between the lines
- The same transcript-driven revision loop could be tested on non-game sequential tasks such as web navigation or code debugging to check whether configuration evolution transfers beyond text adventures.
- Longer sequences of episodes might reveal whether performance continues to rise or eventually plateaus once the configuration space is exhausted.
- This method suggests a path for agents to adapt in deployed settings where retraining is costly or impossible, by treating the configuration itself as the learnable object.
- Similar self-revision mechanisms might reduce dependence on careful initial prompt engineering if the evolver can discover effective setups from experience alone.
Load-bearing premise
An LLM acting as the Evolver Agent can reliably identify useful patterns in raw episode transcripts and generate configuration revisions that produce measurable performance gains without external validation or additional training data.
What would settle it
Running EvoTest on the J-TTL games for several episodes and observing no increase in scores or win rates relative to a fixed-configuration baseline, or finding that proposed revisions do not correlate with better subsequent play.
Figures






read the original abstract
A fundamental limitation of current AI agents is their inability to learn complex skills on the fly at test time, often behaving like "clever but clueless interns" in novel environments. This severely limits their practical utility. To systematically measure and drive progress on this challenge, we first introduce the Jericho Test-Time Learning (J-TTL) benchmark. J-TTL is a new evaluation setup where an agent must play the same game for several consecutive episodes, attempting to improve its performance from one episode to the next. On J-TTL, we find that existing adaptation methods like reflection, memory, or reinforcement learning struggle. To address the challenges posed by our benchmark, we present EvoTest, an evolutionary test-time learning framework that improves an agent without any fine-tuning or gradients-by evolving the entire agentic system after every episode. EvoTest has two roles: the Actor Agent, which plays the game, and the Evolver Agent, which analyzes the episode transcript to propose a revised configuration for the next run. This configuration rewrites the prompt, updates memory by logging effective state-action choices, tunes hyperparameters, and learns the tool-use routines. On our J-TTL benchmark, EvoTest consistently increases performance, outperforming not only reflection and memory-only baselines but also more complex online fine-tuning methods. Notably, our method is the only one capable of winning two games (Detective and Library), while all baselines fail to win any.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Jericho Test-Time Learning (J-TTL) benchmark, in which an agent must improve its performance across consecutive episodes of the same text-based game without fine-tuning. It proposes EvoTest, a framework consisting of an Actor Agent that plays the game and an Evolver Agent that analyzes raw episode transcripts to generate revised configurations (prompt rewrites, memory updates, hyperparameter changes, and tool routines). The central empirical claim is that EvoTest produces consistent performance gains on J-TTL, outperforming reflection, memory-only, and online fine-tuning baselines, and is the only method able to win the Detective and Library games while all baselines fail to win any.
Significance. If the reported gains are shown to be causally attributable to the Evolver revisions rather than additional episodes or stochastic variance, the work would offer a practical gradient-free approach to test-time adaptation for LLM agents and a useful new benchmark for measuring self-improvement. The evolutionary framing and the claim of unique wins on two games would be noteworthy contributions to agentic systems research.
major comments (2)
- The abstract and results presentation assert that EvoTest 'consistently increases performance' and is 'the only one capable of winning two games (Detective and Library)', yet supply no quantitative scores, number of runs, variance measures, or statistical tests. This absence leaves the central empirical claim without visible supporting evidence and is load-bearing for any conclusion about superiority over baselines.
- The experimental design does not include a control condition that holds the Actor Agent fixed while varying only the source of configuration revisions (Evolver-generated vs. random vs. null). Because the Actor is itself an LLM with stochastic outputs, observed wins on Detective and Library could arise from repeated play rather than the evolutionary step; this control is required to establish that the Evolver's pattern extraction causally drives the gains.
minor comments (2)
- Clarify the exact number of episodes per game and the precise definition of a 'win' in the J-TTL benchmark description.
- Add explicit pseudocode or a diagram for the interaction loop between Actor and Evolver to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of empirical rigor in our work on EvoTest and the J-TTL benchmark. We address each major comment point by point below, agreeing where revisions are needed to strengthen the presentation and causal claims.
read point-by-point responses
-
Referee: The abstract and results presentation assert that EvoTest 'consistently increases performance' and is 'the only one capable of winning two games (Detective and Library)', yet supply no quantitative scores, number of runs, variance measures, or statistical tests. This absence leaves the central empirical claim without visible supporting evidence and is load-bearing for any conclusion about superiority over baselines.
Authors: We agree that the abstract as written summarizes findings at a high level without embedding specific numbers, which can make the strength of the evidence less immediately apparent. The full results section presents performance trajectories, win rates, and comparisons across methods on each J-TTL game, including the reported wins on Detective and Library. To improve visibility and address the concern directly, we will revise the abstract to include key quantitative highlights such as average scores or win counts over runs, explicitly state the number of independent runs performed, and reference variance measures. We will also ensure the results section includes any applicable statistical tests comparing EvoTest to baselines. These changes will make the supporting evidence for the central claims explicit. revision: yes
-
Referee: The experimental design does not include a control condition that holds the Actor Agent fixed while varying only the source of configuration revisions (Evolver-generated vs. random vs. null). Because the Actor is itself an LLM with stochastic outputs, observed wins on Detective and Library could arise from repeated play rather than the evolutionary step; this control is required to establish that the Evolver's pattern extraction causally drives the gains.
Authors: This comment correctly identifies a gap in isolating the causal role of the Evolver. While our baselines (reflection, memory-only, and online fine-tuning) already involve multiple episodes without the full evolutionary revision process, they do not specifically test random or null revisions as a direct control. To strengthen the causal interpretation, we will add an ablation study in the revised manuscript that holds the Actor Agent, episode count, and game fixed while applying either random configuration changes or no changes. This will help rule out explanations based solely on repeated play or LLM stochasticity and better attribute gains to the Evolver's pattern extraction and revisions. revision: yes
Circularity Check
No significant circularity; empirical claims rest on benchmark comparisons
full rationale
The paper introduces the J-TTL benchmark and EvoTest framework consisting of an Actor Agent and Evolver Agent that revises configurations after each episode. All reported results are empirical performance measurements on a small set of games, with direct comparisons to reflection, memory, and online fine-tuning baselines. No mathematical derivation, first-principles prediction, or equation chain is presented that reduces to fitted parameters or self-referential definitions. The central claim (outperformance and sole wins on Detective and Library) is supported by experimental outcomes rather than any analytical reduction, rendering the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EvoTest has two roles: the Actor Agent, which plays the game, and the Evolver Agent, which analyzes the episode transcript to propose a revised configuration for the next run. This configuration rewrites the prompt, updates memory by logging effective state-action choices, tunes hyperparameters, and learns the tool-use routines.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery theorems unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The J-TTL benchmark protocol consists of a session of K consecutive episodes played in a single game... θ(e+1) = U(θ(e), τ(e))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Context Training with Active Information Seeking
Adding active search tools to LLM context optimization works only when combined with a multi-candidate search-based training procedure that prunes contexts, delivering gains across low-resource translation, health, an...
-
SkillOpt: Executive Strategy for Self-Evolving Agent Skills
SkillOpt introduces a validation-gated text-space optimizer for agent skills that outperforms human, one-shot, and prior optimization baselines across 52 model-benchmark-harness combinations.
-
Context Training with Active Information Seeking
Active information seeking via search tools, when combined with multi-candidate context pruning during training, produces consistent gains on translation, health, and reasoning tasks over naive tool addition or no-too...
Reference graph
Works this paper leans on
-
[1]
At each stept, it queries the backbone LLM
Acting Phase:In each episode, the Actor Agent takesTsteps. At each stept, it queries the backbone LLM. CostAct = TX t=1 CostLLM(Ct, La)≈T·Cost LLM( ¯C, La)(6) where ¯Cis the average context length. This cost is dominated byTforward passes through the actor model
-
[2]
The input is the full episode transcript (τL)
Evolution Phase:After the episode, the Evolver Agent performs a single, large query to generate new configurations. The input is the full episode transcript (τL). CostEvolve =Cost LLM(τL, Lconfig)(7) whereL config is the length of the generated configuration text. The UCB update step isO(m), which is negligible compared to the LLM call. The total cost for...
-
[3]
Acting Phase (RL):The cost is identical to other methods: Cost Act =T·Cost LLM( ¯C, La)
-
[4]
Weight-Update Phase (RL):This phase involves backpropagation to update the model weights. The computational cost of a training step for a transformer model is approximately proportional to the number of parameters and the total sequence length processed. For an entire episode trajectory of lengthT, this cost is: CostUpdate ≈ O(P actor ·T)(9) This cost ref...
-
[5]
A guiding prompt (the agent’s high-level strategy)
-
[6]
Memory updates (structured data for a success/failure database)
-
[7]
Hyperparameters (like temperature, for decision-making)
-
[8]
Tool-use routines (Python code for state abstraction and rules for memory access). You will receive the previous guiding prompt and the full game history. Generate a new, complete configuration by following the four parts below. The LLM agent used the following guiding prompt (which may not be accurate; rewrite it if needed): "{cur_prompt}" Here is the hi...
-
[9]
Create a "Walkthrough" or "Essential Actions" section. Identify all useful actions from the history that led to score increases or were strictly necessary for game progression. Synthesize these into a clear, step-by-step plan. Be precise with action phrasing (e.g., "unlock door with key" instead of "use key")
-
[10]
Create an "Actions to Avoid" section. Identify actions that led to getting stuck, caused loops, produced repeated errors, or were clearly unproductive. List these as negative constraints or "guardrails."
-
[11]
If the agent has not yet won, create a final "Exploration Plan" section. Brainstorm possible next steps. List rooms or objects that have been seen but not fully interacted with. Suggest a systematic approach for the agent to follow once the known walkthrough is complete (e.g., "visit every room, systematically use LOOK, EXAMINE, SEARCH, and try actions li...
-
[12]
In lobby: talk to reference librarian first { west to Ground-Floor Stacks, ASK LIBRARIAN ABOUT GRAHAM NELSON and then ASK LIBRARIAN ABOUT RARE
-
[13]
Return to lobby and GIVE ID CARD TO ATTENDANT; you receive the Rare-Books KEY
-
[14]
Reach second-floor stacks (north, up, south) and UNLOCK RARE BOOKS DOOR WITH KEY, OPEN DOOR, ENTER
-
[15]
TAKE BIOGRAPHY OF GRAHAM NELSON
-
[16]
Leave the room, CLOSE RARE BOOKS DOOR, then LOCK RARE BOOKS DOOR WITH KEY
-
[17]
east of 2F stacks. { The \Private
Back in lobby GIVE KEY TO ATTENDANT; he returns your ID card. Avoid • Wandering in the dusty card-catalogue corner { it contains no useful data. • Trying to leave the library while still holding the key or while the rare-books door is open/unlocked: this triggers alarms and extra trips. • Vague commands such as \talk to attendant"; instead use verbs ASK o...
-
[18]
From the Lobby • ask attendant about book→he sends you to Reference
-
[19]
West to Ground-floor Stacks (Reference Desk) • ask librarian about Graham Nelson • ask librarian about rare→she tells you key is at Circulation
-
[20]
Return to Lobby • give id card to attendant→you receive key to rare books room (+5)
-
[21]
Reach the heavy wooden door (N→U→S) • unlock door with key • open door • enter • take biography (+5)
-
[22]
Before leaving the second floor • close rare books door • lock door with key
-
[23]
Back in the Lobby • give key to attendant→attendant returns your ID
-
[24]
Still in the Lobby • ask attendant to check out biography (or \check out biography" / \borrow biography") • east→leave the building without the alarm Actions that wasted time or caused trouble { avoid these: • Re-examining the dusty card-catalog drawers (they contain unreadable parchment). • \talk attendant" { the correct form is \ask attendant about ..."...
-
[25]
Gain entry to Rare-Books • ASK ATTENDANT ABOUT GRAHAM • WEST to Ground-Floor Stacks • ASK LIBRARIAN ABOUT GRAHAM • ASK LIBRARIAN ABOUT KEY • EAST to Lobby • ASK ATTENDANT ABOUT KEY • GIVE ID CARD TO ATTENDANT→receive Rare-Books key (+5)
-
[26]
Retrieve the Graham Nelson biography • WEST { NORTH { UP { SOUTH to 2F Stacks • UNLOCK DOOR WITH KEY; OPEN DOOR; ENTER • TAKE BIOGRAPHY(+5) • Return to 2F Stacks, CLOSE DOOR, LOCK DOOR WITH KEY • NORTH { DOWN { SOUTH { EAST to Lobby • GIVE KEY TO ATTENDANT(ID card returned)
-
[27]
Empty the Computer Lab and grab the encyclopedia • WEST { NORTH { UP { SOUTH { EAST to Computer Lab • ASK TECHNICIAN ABOUT GATES→technician leaves(+2) • EXAMINE PRINTERS→automatically take Encyclopedia Frobozzica(+5)
-
[28]
Please the Reference Librarian • WEST { NORTH { DOWN { SOUTH { EAST to Ground-Floor Stacks • GIVE ENCYCLOPEDIA TO LIBRARIAN(+2) Confirmed score so far: 19 points ACTIONS TO AVOID • Getting stuck in the \which do you mean, the howto manual or the security gates?" loop { when it appears, simply type HOWTO MANUAL once and continue. • Trying to open / push / ...
-
[29]
Borrow the Rare-Books key (+5) • In the Lobby: GIVE ID CARD TO ATTENDANT
-
[30]
Confirm the book’s location • WEST to Ground-Floor Stacks • ASK LIBRARIAN ABOUT GRAHAM
-
[31]
Retrieve the Graham Nelson biography (+5) • WEST { NORTH { UP { SOUTH to 2F Stacks • UNLOCK DOOR WITH KEY ; OPEN DOOR ; ENTER • TAKE BIOGRAPHY • NORTH (leave) ; CLOSE DOOR ; LOCK DOOR WITH KEY
-
[32]
Return the key • NORTH { DOWN { SOUTH { EAST to Lobby • GIVE KEY TO ATTENDANT (get ID card back)
-
[33]
Clear the Computer Lab (+2 + 5) • WEST { NORTH { UP { SOUTH { EAST to Computer Lab • ASK TECHNICIAN ABOUT GATES (+2) • EXAMINE PRINTERS (auto-take Encyclopedia Frobozzica, +5)
-
[34]
Donate the Encyclopedia (+2) • WEST { DOWN { SOUTH { EAST { WEST to Ground-Floor Stacks • GIVE ENCYCLOPEDIA TO LIBRARIAN
-
[35]
door in Lobby • Duplicating Services room after explosion • Stairwell paintings (\grue
Extra find in 2F Stacks (+5) • NORTH { UP { SOUTH to 2F Stacks • SEARCH SHELVES (get \Debt of Honor") Confirmed score so far: 24 points. Avoid: • Interacting with the security gates (causes an endless clarification loop). • Repeatedly fiddling with the paintings/canvas until new clues appear. • Non-standard verbs (USE, TYPE, TALK TO, etc.). • Trying to le...
-
[36]
<< Chief’s office >> ... You can see a piece of white paper
STATE: "<< Chief’s office >> ... You can see a piece of white paper..." ACTION: "read paper" REWARD: +10 points
-
[37]
<< closet >> ... there is a gun on the floor
STATE: "<< closet >> ... there is a gun on the floor..." ACTION: "get pistol" REWARD: +10 points
-
[38]
<< living room >> ... you see a battered piece of wood
STATE: "<< living room >> ... you see a battered piece of wood..." ACTION: "get wood" REWARD: +10 points Based on these observations, the Evolver programmatically updates thesuccess memory.json file. This file stores a mapping from a hash of the state’s descriptive text to the action that proved successful. The resulting database entries would look like t...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.