Assessing Coherency and Consistency of Code Execution Reasoning by Large Language Models
Pith reviewed 2026-05-18 05:55 UTC · model grok-4.3
The pith
Large language models simulate program execution coherently in 81 percent of HumanEval cases yet reason inconsistently across paths, mostly at random or weak levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
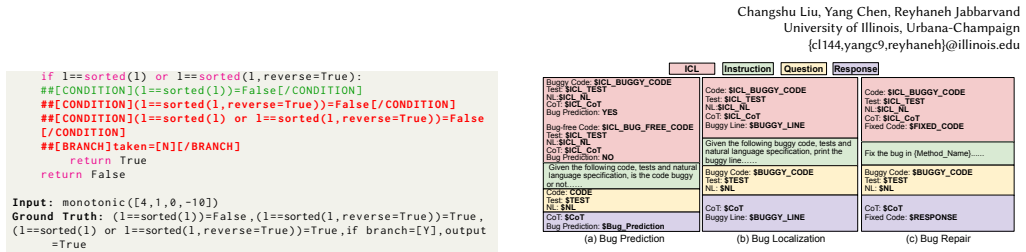
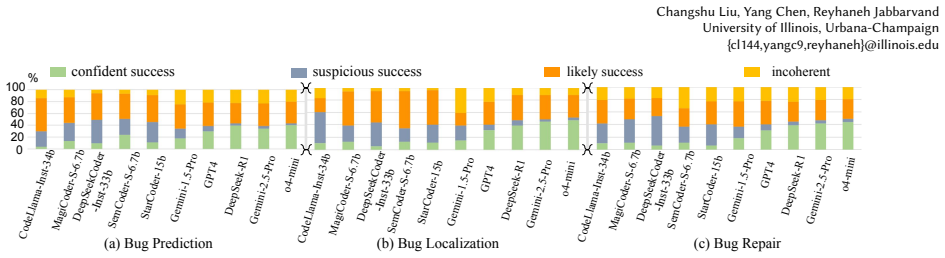
CES shows that LLMs produce coherent execution simulations on HumanEval 81.42 percent of the time, split almost evenly between correct and incorrect final predictions. Frontier models such as GPT-4 and DeepSeek-R1 display the highest rates of incoherence, largely from natural-language shortcuts. Across repeated tests the models' reasoning falls into random consistency 48.87 percent of the time and weak consistency 45.37 percent of the time. The same pattern appears when CES is applied to bug prediction, localization, and repair: success rarely reflects genuine execution reasoning and instead traces to pattern matching or data leakage, creating a generalizability risk for unseen bugs.
What carries the argument
CES, the Code Execution Simulation task, which measures coherence as compliance with commonsense execution logic independent of output correctness and consistency via a spectrum of strong, weak, and random performance across prime-path-coverage variants.
If this is right
- LLMs rarely draw on execution reasoning when performing bug prediction, localization, or repair and rely instead on pattern matching.
- Without genuine execution reasoning, LLM performance on programming tasks that involve unseen bugs or different contexts is likely to remain brittle.
- CES supplies a practical method to check whether reported success on code-related tasks stems from shortcuts rather than reasoning.
- Inconsistency across path variants helps explain why LLMs continue to struggle with tasks that require path-sensitive program analysis.
Where Pith is reading between the lines
- Improving consistency on path-coverage variants may require training regimes that explicitly reward step-by-step simulation rather than final-answer accuracy.
- Hybrid systems that pair LLMs with symbolic or dynamic execution engines could compensate for the observed randomness and weakness.
- The same coherence-consistency lens might be applied to other sequential reasoning domains such as planning or protocol verification.
Load-bearing premise
The coherence metric and prime-path-coverage consistency spectrum truly separate genuine execution reasoning from pattern matching or data leakage.
What would settle it
New, previously unseen programs with controlled prime-path variations where models scoring high on CES coherence and strong consistency either succeed or fail at path-sensitive tasks in direct proportion to those scores.
Figures









read the original abstract
This paper proposes CES, a task to evaluate the abilities of LLMs in simulating program execution and using that reasoning in programming tasks. Besides measuring the correctness of variable predictions during execution simulation, CES introduces the notion of coherence to determine whether the simulation complies with commonsense execution logic, even if the predicted values along the simulations are incorrect. This enables CES to rule out suspiciously correct output predictions due to reasoning shortcuts, hallucinations, or potential data leakage. CES also introduces a novel metric to measure reasoning consistency across tests with the same or different prime path coverage in a spectrum: strong, weak, and random. Evaluating 16 LLMs (including three reasoning LLMs) using CES indicates 81.42% coherent execution simulation on HumanEval, 46.92% and 53.08% of which result in correct and incorrect output predictions. Frontier LLMs such as GPT-4 and DeepSeek-R1 have the most incoherent execution reasoning, mostly due to natural language shortcuts. Despite relatively coherent execution simulation, LLMs' reasoning performance across different tests is inconsistent, mostly random (48.87%) or weak (45.37%), potentially explaining their weakness in programming tasks that require path-sensitive program analysis to succeed. We also compare CES with bug prediction/localization/repair, which intuitively requires control- and data-flow awareness. We observe that LLMs barely incorporate execution reasoning into their analysis for bug-related tasks, and their success is primarily due to inherent abilities in pattern matching or natural language shortcuts, if not data leakage. Without reasoning, there is a threat to the generalizability of LLMs in dealing with unseen bugs or patterns in different contexts. CES can be used to vet the suspicious success of LLMs in these tasks systematically.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper proposes CES, a task to evaluate LLMs' abilities in simulating program execution. It introduces a coherence metric to assess compliance with commonsense execution logic independent of output correctness, aiming to rule out reasoning shortcuts or data leakage. Additionally, it defines a consistency metric classifying reasoning as strong, weak, or random based on prime path coverage across tests. The evaluation of 16 LLMs on HumanEval reports 81.42% coherent execution simulations, of which 46.92% lead to correct and 53.08% to incorrect outputs. Frontier models show more incoherence due to natural language shortcuts. Reasoning is found to be mostly random (48.87%) or weak (45.37%). On bug-related tasks, LLMs' success is attributed to pattern matching rather than execution reasoning.
Significance. Should the coherence and consistency metrics prove robust, this work would offer valuable insights into the limitations of LLMs in path-sensitive program analysis and a systematic approach to identifying when their successes in code tasks stem from genuine reasoning versus superficial patterns. The quantitative results on multiple models and tasks highlight potential threats to generalizability in unseen scenarios.
major comments (3)
- [§3.2] §3.2: The definition and operationalization of the coherence metric lack sufficient detail. It is not specified how 'compliance with commonsense execution logic' is evaluated in practice (e.g., manual review, LLM-as-a-judge, or rule-based), nor are there controls to prevent crediting plausible-sounding but semantically invalid execution traces. This directly impacts the reliability of the headline 81.42% coherence figure on HumanEval.
- [§4.1] §4.1: The procedure for extracting prime paths and determining coverage is not described. Without details on the algorithm or implementation used to identify these paths, the classification of reasoning consistency into strong, weak, and random (with reported rates of 48.87% random and 45.37% weak) cannot be independently verified or reproduced.
- [§5.2] §5.2: The conclusion that LLMs barely incorporate execution reasoning into bug prediction, localization, and repair tasks, relying instead on pattern matching, requires more concrete evidence. Specific examples of traces or quantitative comparisons using the CES metrics on these tasks would strengthen this claim.
minor comments (3)
- [Abstract] Abstract: The phrasing '46.92% and 53.08% of which result in correct and incorrect output predictions' is ambiguous; it should explicitly state that these percentages are relative to the coherent simulations.
- [Introduction] Introduction: Add discussion of related work on evaluating LLM reasoning in code, such as execution-based benchmarks or studies on hallucination in code generation.
- [Conclusion] Conclusion: The paper could benefit from a clearer statement on the limitations of CES, particularly regarding scalability to larger programs.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which highlight important areas for improving the clarity and reproducibility of our work on the CES framework. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions or findings.
read point-by-point responses
-
Referee: [§3.2] §3.2: The definition and operationalization of the coherence metric lack sufficient detail. It is not specified how 'compliance with commonsense execution logic' is evaluated in practice (e.g., manual review, LLM-as-a-judge, or rule-based), nor are there controls to prevent crediting plausible-sounding but semantically invalid execution traces. This directly impacts the reliability of the headline 81.42% coherence figure on HumanEval.
Authors: We agree that additional detail on the operationalization of the coherence metric is warranted to support the reliability of the reported results. We will revise §3.2 to explicitly describe the evaluation process, specifying the combination of rule-based checks for adherence to commonsense execution semantics (such as statement sequencing and control flow handling) with targeted manual review for ambiguous cases. We will also document the controls employed, including cross-validation against interpreter-derived traces on sampled instances, to prevent crediting semantically invalid but plausible traces. These additions will directly bolster the 81.42% coherence figure. revision: yes
-
Referee: [§4.1] §4.1: The procedure for extracting prime paths and determining coverage is not described. Without details on the algorithm or implementation used to identify these paths, the classification of reasoning consistency into strong, weak, and random (with reported rates of 48.87% random and 45.37% weak) cannot be independently verified or reproduced.
Authors: We concur that the absence of a detailed description of the prime path extraction and coverage procedure limits independent verification. We will expand §4.1 (and add an appendix if needed) to include a complete account of the algorithm, based on standard control-flow graph analysis for prime path coverage, along with implementation specifics such as the libraries and steps used to compute coverage across tests. This will enable reproduction of the consistency classifications into strong, weak, and random categories and the associated rates. revision: yes
-
Referee: [§5.2] §5.2: The conclusion that LLMs barely incorporate execution reasoning into bug prediction, localization, and repair tasks, requires more concrete evidence. Specific examples of traces or quantitative comparisons using the CES metrics on these tasks would strengthen this claim.
Authors: We appreciate this feedback and agree that concrete evidence would strengthen the interpretation. We will revise §5.2 to incorporate specific examples of LLM reasoning traces from bug-related tasks and quantitative comparisons that apply the CES coherence and consistency metrics directly to performance on bug prediction, localization, and repair. These additions will provide clearer support for the conclusion that success stems primarily from pattern matching rather than execution reasoning. revision: yes
Circularity Check
No circularity: empirical metrics applied to off-the-shelf models on standard benchmarks
full rationale
The paper defines CES coherence (compliance with commonsense execution logic independent of output correctness) and a prime-path-coverage consistency spectrum (strong/weak/random) as new evaluation constructs, then reports empirical percentages from running 16 LLMs on HumanEval and bug-related tasks. No equations, fitted parameters, or self-citations are used to derive the headline results; the 81.42% coherence figure and the 48.87%/45.37% inconsistency breakdown are direct measurements rather than reductions of the inputs by construction. The central claims rest on the operationalization of the metrics themselves, which the paper treats as external to any prior result from the same authors. This is a standard empirical evaluation paper whose derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be prompted to produce step-by-step variable predictions that simulate program execution
invented entities (2)
-
Coherence metric
no independent evidence
-
Consistency spectrum (strong, weak, random)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CES introduces coherence rules (Formulas 2-4) and consistency spectrum (Definitions 4-5) based on prime-path coverage to evaluate LLM execution simulation on HumanEval.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
No mention of recognition cost, golden-ratio identities, or 8-tick structure anywhere in the evaluation or metrics.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
The Path Not Taken: Duality in Reasoning about Program Execution
DexBench introduces paired forward and backward reasoning tasks to measure LLMs' dynamic understanding of program execution more discriminatively than prior benchmarks.
-
Evaluating LLMs Code Reasoning Under Real-World Context
R2Eval is a new benchmark with 135 real-world code reasoning problems from Python projects that preserves complex data structures for more realistic LLM evaluation.
-
Evaluating Code Reasoning Abilities of Large Language Models Under Real-World Settings
A new dataset and nine-metric majority-vote procedure show that existing code-reasoning benchmarks are dominated by lower-complexity problems that do not reflect real-world code.
Reference graph
Works this paper leans on
-
[1]
2024. HuggingFace Model Hub. https://huggingface.co/docs/hub/en/models- the-hub
work page 2024
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Miltiadis Allamanis, Sheena Panthaplackel, and Pengcheng Yin. [n. d.]. Unsu- pervised Evaluation of Code LLMs with Round-Trip Correctness. InForty-first International Conference on Machine Learning
-
[4]
2017.Introduction to software testing
Paul Ammann and Jeff Offutt. 2017.Introduction to software testing. Cambridge University Press
work page 2017
-
[5]
Anonymous Authors. 2024. CES Artifact Website. https://github.com/ CESCodeReasoning/CES
work page 2024
-
[6]
Anonymous Authors. 2024. CES Artifact Website (Prompt Template). https: //github.com/CESCodeReasoning/CES/blob/main/prompt_template.md
work page 2024
- [7]
-
[8]
Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, et al . 2024. DeepSeek LLM: Scaling Open-Source Language Models with Longtermism.arXiv preprint arXiv:2401.02954(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
work page 2020
-
[10]
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al
-
[11]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [12]
-
[13]
Junkai Chen, Zhiyuan Pan, Xing Hu, Zhenhao Li, Ge Li, and Xin Xia. 2024. Reasoning Runtime Behavior of a Program with LLM: How Far Are We?arXiv e-prints(2024)
work page 2024
-
[14]
Junkai Chen, Zhiyuan Pan, Xing Hu, Zhenhao Li, Ge Li, and Xin Xia. 2024. REval Artifact Website. https://github.com/r-eval/REval
work page 2024
-
[15]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Google DeepMind. 2025. Gemini 2.5 Pro: Our Most Intelligent AI Model. https://blog.google/technology/google-deepmind/gemini-model-thinking- updates-march-2025/. Accessed: 2025-05-28
work page 2025
-
[17]
Rohan Deshpande, Jerry Chen, and Isabelle Lee. 2021. RecT: A Recursive Trans- former Architecture for Generalizable Mathematical Reasoning.. InNeSy. 165– 175
work page 2021
-
[18]
Mengru Ding, Hanmeng Liu, Zhizhang Fu, Jian Song, Wenbo Xie, and Yue Zhang
- [19]
- [20]
-
[21]
Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Sean Welleck, Peter West, Chandra Bhagavatula, Ronan Le Bras, et al. 2023. Faith and fate: Limits of transformers on compositionality.Advances in Neural Information Processing Systems36 (2023), 70293–70332
work page 2023
-
[22]
Alex Gu, Baptiste Rozière, Hugh Leather, Armando Solar-Lezama, Gabriel Syn- naeve, and Sida I Wang. 2024. CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution.arXiv preprint arXiv:2401.03065(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.arXiv preprint arXiv:2501.12948(2025). https://arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [24]
- [25]
- [26]
-
[27]
Changshu Liu and Reyhaneh Jabbarvand. 2025. A Tool for In-depth Analysis of Code Execution Reasoning of Large Language Models.In Companion Pro- ceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, FSE(2025). https://arxiv.org/abs/2501.18482
-
[28]
Changshu Liu, Shizhuo Dylan Zhang, and Reyhaneh Jabbarvand. 2024. Codemind: A framework to challenge large language models for code reasoning.arXiv preprint arXiv:2402.09664(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173
work page 2024
-
[30]
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy- Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. 2024. Starcoder 2 and the stack v2: The next generation.arXiv preprint arXiv:2402.19173(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, and Dongmei Zhang. 2023. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct.arXiv preprint arXiv:2308.09583(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Antonio Valerio Miceli-Barone, Fazl Barez, Ioannis Konstas, and Shay B Cohen
- [33]
- [34]
- [35]
-
[36]
OpenAI. 2025. Introducing o3 and o4-mini. https://openai.com/index/ introducing-o3-and-o4-mini/. Accessed: 2025-05-29
work page 2025
-
[37]
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiao- qing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. 2023. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Antonio Sabbatella, Andrea Ponti, Ilaria Giordani, Antonio Candelieri, and Francesco Archetti. 2024. Prompt Optimization in Large Language Models. Mathematics12, 6 (2024), 929
work page 2024
-
[39]
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. [n. d.]. Detecting Pretraining Data from Large Language Models. InThe Twelfth International Conference on Learning Representations
-
[40]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. 2023. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [41]
-
[42]
Karthik Valmeekam, Alberto Olmo, Sarath Sreedharan, and Subbarao Kambham- pati. 2022. Large Language Models Still Can’t Plan (A Benchmark for LLMs on Planning and Reasoning about Change).arXiv preprint arXiv:2206.10498(2022). Assessing Coherency and Consistency of Code Execution Reasoning by Large Language Models
- [43]
-
[44]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reason- ing in large language models.Advances in Neural Information Processing Systems 35 (2022), 24824–24837
work page 2022
- [45]
- [46]
-
[47]
Jiacheng Ye, Zhiyong Wu, Jiangtao Feng, Tao Yu, and Lingpeng Kong. 2023. Compositional exemplars for in-context learning. InInternational Conference on Machine Learning. PMLR, 39818–39833
work page 2023
- [48]
-
[49]
Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al . 2023. Siren’s song in the AI ocean: a survey on hallucination in large language models.arXiv preprint arXiv:2309.01219(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.