A First Look at the Security Issues in the Model Context Protocol Ecosystem
Pith reviewed 2026-05-18 06:08 UTC · model grok-4.3
The pith
Weak vetting in MCP registries lets hijacked servers manipulate LLM tool calls that hosts then execute without checks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
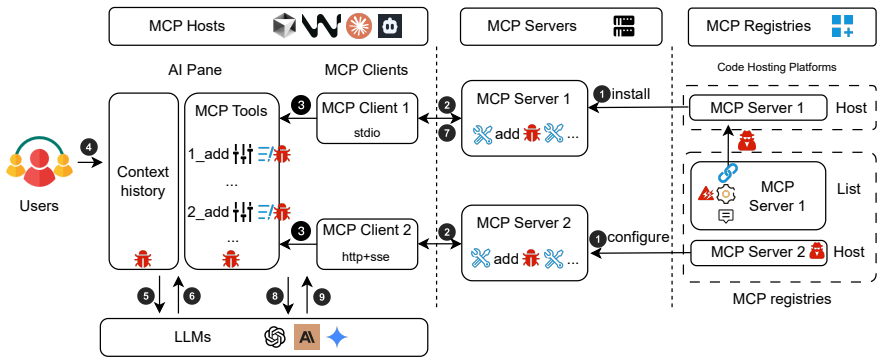
MCP registries allow adversarial or hijacked servers to integrate due to insufficient vetting and ownership verification; once integrated, attacker-controlled tool metadata shapes LLM reasoning to induce specific operations that hosts execute without independent checks, and code-level flaws can amplify the effect even if not required for the initial attack.
What carries the argument
The two-stage attack surface of registry-level weak vetting followed by post-integration metadata manipulation of LLM outputs without host verification.
If this is right
- Adversarial servers can enter hosts through public registries without strong ownership checks.
- Attacker metadata can induce LLMs to request specific tool calls that hosts then perform.
- Widespread server conditions enable hijacking and invocation manipulation across analyzed registries.
- Pre-integration scanning tools can identify misleading metadata and exploitable code before use.
Where Pith is reading between the lines
- Similar trust gaps may appear in other protocols that let LLMs invoke external services based on third-party descriptions.
- Requiring cryptographic signing of tool metadata or mandatory host-side policy checks could reduce the attack surface.
- Registry operators might adopt automated ownership verification to limit hijacking before servers reach hosts.
Load-bearing premise
MCP hosts execute tool operations based on server-provided metadata without performing independent verification or sandboxing.
What would settle it
Finding that MCP hosts routinely perform their own verification of tool metadata and refuse to act on operations suggested only by untrusted server descriptions would contradict the attack surface.
Figures




read the original abstract
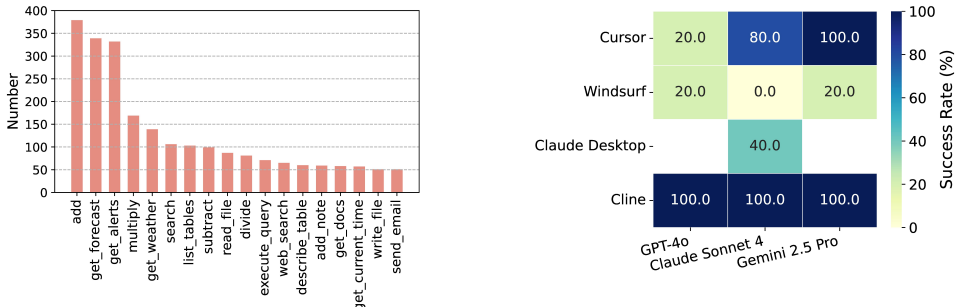
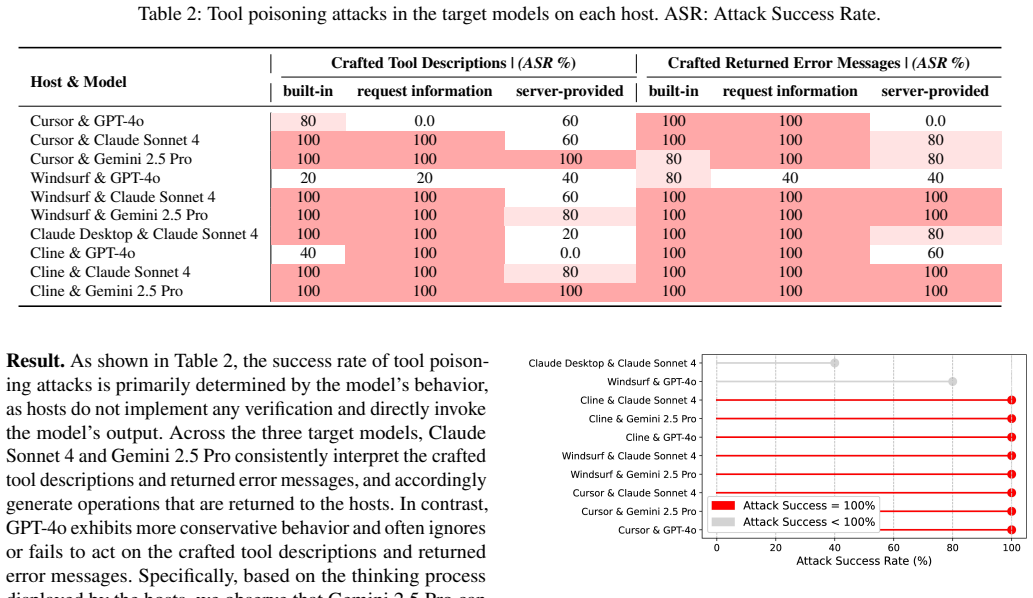
The Model Context Protocol (MCP) has emerged as a standard for connecting large language models (LLMs) with external tools. However, this MCP ecosystem introduces new security risks across hosts, servers, and registries. In this paper, we present the first cross-entity security study of MCP under a two-stage attack surface. At the registry-level, weak vetting and ownership checks allow adversarial or hijacked servers to enter hosts. After integration, attacker-controlled tool metadata can shape LLM reasoning and induce attacker-intended operations, which hosts execute without independent verification. Code-level vulnerabilities (e.g., code injection) are not required but can amplify attacker-controlled parameters into exploitation. We analyze 67,057 servers across six public registries and identify widespread conditions enabling server hijacking and invocation manipulation. We further implement MCPInspect, a pre-integration analysis tool that detects misleading tool metadata and exploitable code vulnerabilities, identifying 833 vulnerable servers and 18 with suspicious descriptions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first cross-entity security study of the Model Context Protocol (MCP), describing a two-stage attack surface involving registry-level hijacking risks and subsequent metadata-driven manipulation of LLM reasoning in hosts. Through analysis of 67,057 servers across six public registries, the authors identify conditions enabling server hijacking and implement MCPInspect to flag 833 servers with misleading metadata or code vulnerabilities and 18 with suspicious descriptions.
Significance. If the results hold, this work is significant for highlighting security risks in an emerging standard for LLM-external tool integration. The concrete empirical data from scanning over 67,000 servers and the implementation of the MCPInspect tool provide strong grounding for the claims about vulnerable servers. These contributions could help the community address weak vetting practices and improve pre-integration checks.
major comments (2)
- [Abstract (two-stage attack surface)] The description of the two-stage attack surface claims that hosts execute attacker-intended operations shaped by server-provided tool metadata 'without independent verification or sandboxing'. However, the manuscript does not include any analysis of MCP host implementations, runtime tests against hosts, or citations to protocol specifications requiring such verification. This leaves the execution-without-verification aspect as an assumption rather than an empirically demonstrated property.
- [Results (scanning and detection)] The paper reports detecting 833 vulnerable servers using MCPInspect but provides insufficient detail on the scanning methodology, criteria for 'misleading tool metadata', and false-positive rates of the detection. This affects the reliability of the count and the claim of 'widespread conditions'.
minor comments (2)
- [Abstract] The six public registries are not named; specifying them would aid reproducibility.
- [Abstract] Some terms like 'MCPInspect' could benefit from a brief definition on first use for readers unfamiliar with the tool.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which have helped us identify areas for improvement in our manuscript on security issues in the Model Context Protocol ecosystem. We respond to each major comment below, indicating where revisions have been or will be made.
read point-by-point responses
-
Referee: [Abstract (two-stage attack surface)] The description of the two-stage attack surface claims that hosts execute attacker-intended operations shaped by server-provided tool metadata 'without independent verification or sandboxing'. However, the manuscript does not include any analysis of MCP host implementations, runtime tests against hosts, or citations to protocol specifications requiring such verification. This leaves the execution-without-verification aspect as an assumption rather than an empirically demonstrated property.
Authors: We acknowledge the referee's observation that the execution-without-verification aspect is presented without direct empirical analysis of host implementations. The two-stage attack surface is framed as a conceptual model grounded in the MCP protocol's design, where tool metadata from servers is passed to LLMs via hosts without protocol-mandated verification steps. To address this, we have added citations to the official MCP specification and a discussion of publicly documented host behaviors in the revised manuscript. We have also clarified the abstract language to indicate this follows from the protocol architecture rather than from runtime testing conducted in our study. Full runtime experiments against diverse hosts were outside the scope of this registry- and server-focused analysis. revision: partial
-
Referee: [Results (scanning and detection)] The paper reports detecting 833 vulnerable servers using MCPInspect but provides insufficient detail on the scanning methodology, criteria for 'misleading tool metadata', and false-positive rates of the detection. This affects the reliability of the count and the claim of 'widespread conditions'.
Authors: We agree that greater methodological transparency is needed to support the reported counts and the characterization of widespread conditions. In the revised manuscript, we have expanded the MCPInspect section with a detailed account of the data collection process across the six registries, the precise criteria and heuristics applied to detect misleading tool metadata (including name-description mismatches and suspicious phrasing), and the results of a manual validation on a sampled subset of detections to estimate false-positive rates. These additions improve reproducibility and allow readers to better assess the strength of the 833 vulnerable servers finding. revision: yes
Circularity Check
Empirical audit of MCP ecosystem with no circular derivation chain
full rationale
The manuscript is an empirical security analysis that scans public registries, identifies hijacking conditions in 67,057 entries, and implements MCPInspect to flag 833 servers with metadata or code issues. No equations, fitted parameters, predictions, or self-citations appear in the provided text that reduce any central claim to its own inputs by construction. The two-stage attack surface is presented as an observed property of the ecosystem rather than a derived result; the assumption that hosts execute metadata-induced operations without verification is stated directly from protocol description and is not obtained via self-definition, renaming, or load-bearing self-citation. The work therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MCP hosts execute tool operations without independent verification of server-provided metadata or parameters.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hosts execute tool operations based on server-provided metadata without performing independent verification or sandboxing
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
weak vetting and ownership checks allow adversarial or hijacked servers
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
A First Measurement Study on Authentication Security in Real-World Remote MCP Servers
First measurement study of 7,973 remote MCP servers finds 40.55% lack authentication and all 119 tested OAuth servers have flaws that risk data leaks or account takeover.
-
Free-Riding the Agentic Web: A Systematic Security Analysis of x402 Payments
Systematic analysis of x402 reveals four security flaw classes with up to 100% leakage, a proof that output-only pricing cannot be both fair and inflation-bounded, and mitigations reducing costs 47% while inverting at...
-
Security Threat Modeling for Emerging AI-Agent Protocols: A Comparative Analysis of MCP, A2A, Agora, and ANP
The paper identifies twelve protocol-level security risks across MCP, A2A, Agora, and ANP and quantifies wrong-provider tool execution risk in MCP via a measurement-driven case study on multi-server composition.
Reference graph
Works this paper leans on
-
[1]
Securing Large Language Models: Threats, Vulnerabilities and Responsible Practices,
Sara Abdali, Richard Anarfi, CJ Barberan, Jia He, and Er- fan Shayegani. Securing large language models: Threats, vulnerabilities and responsible practices.arXiv preprint arXiv:2403.12503, 2024
-
[2]
Tro- janpuzzle: Covertly poisoning code-suggestion models
Hojjat Aghakhani, Wei Dai, Andre Manoel, Xavier Fer- nandes, Anant Kharkar, Christopher Kruegel, Giovanni Vigna, David Evans, Ben Zorn, and Robert Sim. Tro- janpuzzle: Covertly poisoning code-suggestion models. In2024 IEEE Symposium on Security and Privacy (SP), pages 1122–1140. IEEE, 2024
work page 2024
-
[3]
Seven months’ worth of mistakes: A lon- gitudinal study of typosquatting abuse
Pieter Agten, Wouter Joosen, Frank Piessens, and Nick Nikiforakis. Seven months’ worth of mistakes: A lon- gitudinal study of typosquatting abuse. InProceedings of the 22nd Network and Distributed System Security Symposium (NDSS 2015). Internet Society, 2015
work page 2015
-
[4]
Introducing the model context pro- tocol
Anthropic. Introducing the model context pro- tocol. https://www.anthropic.com/news/ model-context-protocol, 2025
work page 2025
- [5]
-
[6]
arXiv preprint arXiv:2307.08715 , year=
Gelei Deng, Yi Liu, Yuekang Li, Kailong Wang, Ying Zhang, Zefeng Li, Haoyu Wang, Tianwei Zhang, and Yang Liu. Jailbreaker: Automated jailbreak across mul- tiple large language model chatbots.arXiv preprint arXiv:2307.08715, 2023
-
[7]
Ai agents under threat: A survey of key secu- rity challenges and future pathways
Z Deng, Y Guo, C Han, W Ma, J Xiong, S Wen, and Y Xiang. Ai agents under threat: A survey of key secu- rity challenges and future pathways. arxiv, 2024
work page 2024
-
[8]
Evaluating login challenges as adefense against account takeover
Periwinkle Doerfler, Kurt Thomas, Maija Marincenko, Juri Ranieri, Yu Jiang, Angelika Moscicki, and Damon McCoy. Evaluating login challenges as adefense against account takeover. InThe World Wide Web Conference, pages 372–382, 2019
work page 2019
-
[9]
Towards measuring supply chain attacks on package managers for interpreted languages
Ruian Duan, Omar Alrawi, Ranjita Pai Kasturi, Ryan Elder, Brendan Saltaformaggio, and Wenke Lee. To- wards measuring supply chain attacks on package managers for interpreted languages.arXiv preprint arXiv:2002.01139, 2020
-
[10]
Deleting your personal account
GitHub Docs. Deleting your personal account. https: //docs.github.com/en/account-and-profile/ setting-up-and-managing-your-personal-account-on-github/ managing-your-personal-account/ deleting-your-personal-account, 2025
work page 2025
-
[11]
Managing your personal access tokens
GitHub Docs. Managing your personal access tokens. https://docs.github.com/en/authentication/ keeping-your-account-and-data-secure/ managing-your-personal-access-tokens, 2025
work page 2025
-
[12]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injec- tion. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security, pages 79–90, 2023
work page 2023
-
[13]
Use-after-freemail: Generalizing the use-after-free problem and applying it to email services
Daniel Gruss, Michael Schwarz, Matthias Wübbeling, Simon Guggi, Timo Malderle, Stefan More, and Moritz Lipp. Use-after-freemail: Generalizing the use-after-free problem and applying it to email services. InProceed- ings of the 2018 on Asia Conference on Computer and Communications Security, pages 297–311, 2018
work page 2018
-
[14]
Investigating package related security threats in soft- ware registries
Yacong Gu, Lingyun Ying, Yingyuan Pu, Xiao Hu, Hua- jun Chai, Ruimin Wang, Xing Gao, and Haixin Duan. Investigating package related security threats in soft- ware registries. In2023 IEEE Symposium on Security and Privacy (SP), pages 1578–1595. IEEE, 2023
work page 2023
-
[15]
Catastrophic Jailbreak of Open-source LLMs via Exploiting Generation
Yangsibo Huang, Samyak Gupta, Mengzhou Xia, Kai Li, and Danqi Chen. Catastrophic jailbreak of open- source llms via exploiting generation.arXiv preprint arXiv:2310.06987, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Mcp security notification: Tool poi- soning attacks
Invariantlabs. Mcp security notification: Tool poi- soning attacks. https://invariantlabs.ai/blog/ mcp-security-notification-tool-poisoning-attacks , 2025
work page 2025
-
[17]
Whatsapp mcp exploited: Exfiltrating your message history via mcp
Invariantlabs. Whatsapp mcp exploited: Exfiltrating your message history via mcp. https://invariantlabs.ai/blog/ whatsapp-mcp-exploited, 2025
work page 2025
-
[18]
arXiv preprint arXiv:2307.14692 , year=
Nikhil Kandpal, Matthew Jagielski, Florian Tramèr, and Nicholas Carlini. Backdoor attacks for in-context learning with language models.arXiv preprint arXiv:2307.14692, 2023. 14
-
[19]
Every second counts: Quantifying the negative externalities of cybercrime via typosquatting
Mohammad Taha Khan, Xiang Huo, Zhou Li, and Chris Kanich. Every second counts: Quantifying the negative externalities of cybercrime via typosquatting. In2015 IEEE Symposium on Security and Privacy, pages 135–
-
[20]
Hiding in plain sight: A longitudinal study of com- bosquatting abuse
Panagiotis Kintis, Najmeh Miramirkhani, Charles Lever, Yizheng Chen, Rosa Romero-Gómez, Nikolaos Pitropakis, Nick Nikiforakis, and Manos Antonakakis. Hiding in plain sight: A longitudinal study of com- bosquatting abuse. InProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, pages 569–586, 2017
work page 2017
-
[21]
arXiv preprint arXiv:2304.05197 , year=
Haoran Li, Dadi Guo, Wei Fan, Mingshi Xu, Jie Huang, Fanpu Meng, and Yangqiu Song. Multi-step jail- breaking privacy attacks on chatgpt.arXiv preprint arXiv:2304.05197, 2023
-
[22]
To- ward understanding the security of plugins in continuous integration services
Xiaofan Li, Yacong Gu, Chu Qiao, Zhenkai Zhang, Daip- ing Liu, Lingyun Ying, Haixin Duan, and Xing Gao. To- ward understanding the security of plugins in continuous integration services. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pages 482–496, 2024
work page 2024
-
[23]
A first look at security and privacy risks in the rapidapi ecosys- tem
Song Liao, Long Cheng, Xiapu Luo, Zheng Song, Haipeng Cai, Danfeng Yao, and Hongxin Hu. A first look at security and privacy risks in the rapidapi ecosys- tem. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pages 1626–1640, 2024
work page 2024
-
[24]
Exploring the unchartered space of container registry typosquatting
Guannan Liu, Xing Gao, Haining Wang, and Kun Sun. Exploring the unchartered space of container registry typosquatting. In31st USENIX Security Symposium (USENIX Security 22), pages 35–51, 2022
work page 2022
-
[25]
Tong Liu, Zizhuang Deng, Guozhu Meng, Yuekang Li, and Kai Chen. Demystifying rce vulnerabilities in llm-integrated apps. arxiv 2023.arXiv preprint arXiv:2309.02926, 2023
-
[26]
Prompt Injection attack against LLM-integrated Applications
Yi Liu, Gelei Deng, Yuekang Li, Kailong Wang, Zihao Wang, Xiaofeng Wang, Tianwei Zhang, Yepang Liu, Haoyu Wang, Yan Zheng, et al. Prompt injection at- tack against llm-integrated applications.arXiv preprint arXiv:2306.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Formalizing and benchmarking prompt injection attacks and defenses
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. Formalizing and benchmarking prompt injection attacks and defenses. In33rd USENIX Security Symposium (USENIX Security 24), pages 1831– 1847, 2024
work page 2024
-
[28]
mastra. The mcp registry registry. https://mastra. ai/mcp-registry-registry, 2025
work page 2025
-
[29]
Discover top mcp servers | mcp market
MCP Market. Discover top mcp servers | mcp market. https://mcpmarket.com/, 2025
work page 2025
-
[30]
Mcp store - find and connect to 20,000+ mcp servers.https://mcpstore.co/, 2025
MCP Store. Mcp store - find and connect to 20,000+ mcp servers.https://mcpstore.co/, 2025
work page 2025
- [31]
-
[32]
Model context protocol (mcp) is now generally available in microsoft copilot studio
Microsoft. Model context protocol (mcp) is now generally available in microsoft copilot studio. https://www.microsoft.com/en-us/ microsoft-copilot/blog/copilot-studio/ model-context-protocol-mcp-is-now-generally-available-in-microsoft-copilot-studio/ , 2025
work page 2025
-
[33]
Measuring the perpetrators and funders of typosquatting
Tyler Moore and Benjamin Edelman. Measuring the perpetrators and funders of typosquatting. InInterna- tional Conference on Financial Cryptography and Data Security, pages 175–191. Springer, 2010
work page 2010
-
[34]
Soundsquatting: Uncovering the use of homophones in domain squatting
Nick Nikiforakis, Marco Balduzzi, Lieven Desmet, Frank Piessens, and Wouter Joosen. Soundsquatting: Uncovering the use of homophones in domain squatting. InInternational Conference on Information Security, pages 291–308. Springer, 2014
work page 2014
-
[35]
Nick Nikiforakis, Steven Van Acker, Wannes Meert, Lieven Desmet, Frank Piessens, and Wouter Joosen. Bit- squatting: Exploiting bit-flips for fun, or profit? InPro- ceedings of the 22nd international conference on World Wide Web, pages 989–998, 2013
work page 2013
-
[36]
Cheatagent: Attack- ing llm-empowered recommender systems via llm agent
Liang-bo Ning, Shijie Wang, Wenqi Fan, Qing Li, Xin Xu, Hao Chen, and Feiran Huang. Cheatagent: Attack- ing llm-empowered recommender systems via llm agent. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 2284– 2295, 2024
work page 2024
-
[37]
Prompt-to-sql injections in llm-integrated web applications: Risks and defenses
Rodrigo Pedro, Miguel E Coimbra, Daniel Castro, Paulo Carreira, and Nuno Santos. Prompt-to-sql injections in llm-integrated web applications: Risks and defenses. In 2025 IEEE/ACM 47th International Conference on Soft- ware Engineering (ICSE), pages 76–88. IEEE Computer Society, 2024
work page 2025
-
[38]
Pulsemcp | keep up-to-date with mcp
Pulse MCP. Pulsemcp | keep up-to-date with mcp. https://www.pulsemcp.com/, 2025
work page 2025
-
[39]
You autocomplete me: Poisoning vul- nerabilities in neural code completion
Roei Schuster, Congzheng Song, Eran Tromer, and Vi- taly Shmatikov. You autocomplete me: Poisoning vul- nerabilities in neural code completion. In30th USENIX Security Symposium (USENIX Security 21), pages 1559– 1575, 2021
work page 2021
-
[40]
arXiv preprint arXiv:2310.10844 (2023)
Erfan Shayegani, Md Abdullah Al Mamun, Yu Fu, Pe- dram Zaree, Yue Dong, and Nael Abu-Ghazaleh. Survey of vulnerabilities in large language models revealed by 15 adversarial attacks.arXiv preprint arXiv:2310.10844, 2023
-
[41]
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. " do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pages 1671–1685, 2024
work page 2024
-
[42]
Smithery - model context protocol registry
Smithery. Smithery - model context protocol registry. https://smithery.ai/, 2025
work page 2025
-
[43]
The long {“Taile”} of typosquatting domain names
Janos Szurdi, Balazs Kocso, Gabor Cseh, Jonathan Spring, Mark Felegyhazi, and Chris Kanich. The long {“Taile”} of typosquatting domain names. In23rd USENIX Security Symposium (USENIX Security 14), pages 191–206, 2014
work page 2014
-
[44]
Google to embrace anthropic’s standard for connecting ai models to data
TechCrunch. Google to embrace anthropic’s standard for connecting ai models to data. https://techcrunch.com/2025/04/09/ google-says-itll-embrace-anthropics-standard-for-connecting-ai-models-to-data/ , 2025
work page 2025
-
[45]
Openai adopts rival anthropic’s standard for connecting ai models to data
TechCrunch. Openai adopts rival anthropic’s standard for connecting ai models to data. https://techcrunch.com/2025/03/26/ openai-adopts-rival-anthropics-standard-for-connecting-ai-models-to-data/ , 2025
work page 2025
-
[46]
PhD thesis, Univer- sität Hamburg, Fachbereich Informatik, 2016
Nikolai Philipp Tschacher.Typosquatting in program- ming language package managers. PhD thesis, Univer- sität Hamburg, Fachbereich Informatik, 2016
work page 2016
-
[47]
Typosquatting and com- bosquatting attacks on the python ecosystem
Duc-Ly Vu, Ivan Pashchenko, Fabio Massacci, Henrik Plate, and Antonino Sabetta. Typosquatting and com- bosquatting attacks on the python ecosystem. In2020 ieee european symposium on security and privacy work- shops (euros&pw), pages 509–514. IEEE, 2020
work page 2020
-
[48]
Adversarial demonstration attacks on large language models.arXiv preprint arXiv:2305.14950,
Jiongxiao Wang, Zichen Liu, Keun Hee Park, Zhuo- jun Jiang, Zhaoheng Zheng, Zhuofeng Wu, Muhao Chen, and Chaowei Xiao. Adversarial demonstration attacks on large language models.arXiv preprint arXiv:2305.14950, 2023
-
[49]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does llm safety training fail?Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[50]
Fangzhou Wu, Xiaogeng Liu, and Chaowei Xiao. De- ceptprompt: Exploiting llm-driven code generation via adversarial natural language instructions.arXiv preprint arXiv:2312.04730, 2023
-
[51]
I know what you asked: Prompt leakage via kv-cache sharing in multi- tenant llm serving
Guanlong Wu, Zheng Zhang, Yao Zhang, Weili Wang, Jianyu Niu, Ye Wu, and Yinqian Zhang. I know what you asked: Prompt leakage via kv-cache sharing in multi- tenant llm serving. InProceedings of the 2025 Network and Distributed System Security (NDSS) Symposium. San Diego, CA, USA, 2025
work page 2025
-
[52]
Jun Yan, Vikas Yadav, Shiyang Li, Lichang Chen, Zheng Tang, Hai Wang, Vijay Srinivasan, Xiang Ren, and Hongxia Jin. Backdooring instruction-tuned large lan- guage models with virtual prompt injection.arXiv preprint arXiv:2307.16888, 2023
-
[53]
Shenao Yan, Shen Wang, Yue Duan, Hanbin Hong, Kiho Lee, Doowon Kim, and Yuan Hong. An llm- assisted easy-to-trigger backdoor attack on code comple- tion models: Injecting disguised vulnerabilities against strong detection.arXiv preprint arXiv:2406.06822, 2024
-
[54]
Nusrat Zahan, Thomas Zimmermann, Patrice Gode- froid, Brendan Murphy, Chandra Maddila, and Laurie Williams. What are weak links in the npm supply chain? InProceedings of the 44th International Conference on Software Engineering: Software Engineering in Prac- tice, pages 331–340, 2022
work page 2022
-
[55]
Advdoor: adversarial backdoor attack of deep learning system
Quan Zhang, Yifeng Ding, Yongqiang Tian, Jianmin Guo, Min Yuan, and Yu Jiang. Advdoor: adversarial backdoor attack of deep learning system. InProceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, pages 127–138, 2021
work page 2021
-
[56]
Human-imperceptible re- trieval poisoning attacks in llm-powered applications
Quan Zhang, Binqi Zeng, Chijin Zhou, Gwihwan Go, Heyuan Shi, and Yu Jiang. Human-imperceptible re- trieval poisoning attacks in llm-powered applications. In Companion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering, pages 502–506, 2024
work page 2024
-
[57]
Imperceptible content poisoning in llm-powered applications
Quan Zhang, Chijin Zhou, Gwihwan Go, Binqi Zeng, Heyuan Shi, Zichen Xu, and Yu Jiang. Imperceptible content poisoning in llm-powered applications. InPro- ceedings of the 39th IEEE/ACM International Confer- ence on Automated Software Engineering, pages 242– 254, 2024
work page 2024
-
[58]
Xinyu Zhang, Huiyu Xu, Zhongjie Ba, Zhibo Wang, Yuan Hong, Jian Liu, Zhan Qin, and Kui Ren. Priva- cyasst: Safeguarding user privacy in tool-using large language model agents.IEEE Transactions on Depend- able and Secure Computing, 21(6):5242–5258, 2024
work page 2024
-
[59]
Small world with high risks: A study of security threats in the npm ecosystem
Markus Zimmermann, Cristian-Alexandru Staicu, Cam Tenny, and Michael Pradel. Small world with high risks: A study of security threats in the npm ecosystem. In 28th USENIX Security symposium (USENIX security 19), pages 995–1010, 2019. 16
work page 2019
-
[60]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and trans- ferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023. 17
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.